

简述C#中IO的应用 RabbitMQ安装笔记 一次线上问题引发的对于C#中相等判断的思考 ef和mysql使用(一) ASP.NET/MVC/Core的HTTP请求流程
简述C#中IO的应用
在.NET Framework 中. System.IO 命名空间主要包含基于文件(和基于内存)的输入输出(I/O)服务的相关基础类库.和其他命名空间一样. System.IO 定义了一系列类、接口、枚举、结构和委托。
它们大多数包含在 mscorlib.dll! 另外有一部分部分 System.IO 命名空间的成员则包含在systcm.dll程序集中。
System.IO命名空间的多数类型主要用于编程操作物理目录和文件,而另一些类型则提供了从字符串缓冲区和内存区域中读写数据的方法。
下面是有关System.IO命名空间的主要成员
| System.IO命名空间的主要成员 | |
| 非抽象I/O类类型 | 作用 |
| BinaryReader和BinaryWriter | 这两个类型能够以二进制值存储和读取基本数据(整型,布尔型,字符串型和其他类型) |
| BufferedStream | 这个类型为字节流提供了临时的存储空间,可以以以后提交 |
| Directory和DirectoryInfo | 这两个类型用来操作计算机的目录结构。Directory 类型主要的功能通过静态方法实现。 DirectoryInfo 类创刚通过一个有效的时象引用来实现类似功能 |
| DriveInfo | 提供计算机驱动器的详细信息 |
| File 和 FlleInfo | 这两个类用来操作计算机上的一组文件。Fi1e类型主要的功能通过静态成员实现。FlleInfo类型则通过一个有效的对象引用来实现类似功能 |
| FileStream | 这个类型实现文件随记访问(比如寻址能力)以字节流来表示教据 |
| FileSystemWatcher | 这个类型监控对指定外部文件的更改 |
| MemoryStream | 这个类型实现对内存(而不是物理文件)中存储的流教据的随机访问 |
| Path | 这个类型对包含文件或目录路径信息的System.Stream类型执行操作。这些操作是与平台无关的 |
| StreamWriter和StreamReader | 这两个类型用来在(从)文件中存储(获取)文本信息。不支持随机文件访问 |
| StringWriter和StringReader | 和StreamWriter/StreamReader类型差不多.这两个类型同样同文本信息打交道,不同的是基层的存储器是字符串缓冲区而不是物理文件 |
Directory(Info)和File(Info) 类型 实现单个文件和计算机目录操作
一般说来, Fllelnfo 和DirectoryInfo 是获取文件或目录细节(如创建时间、读写能力等)更好的方式,因为它们的成员往往会返回强类型的对象。相反,Directory 和File类成员往往会返回简单字符串值而不是强类型对象。不过.这仅仅是一个准则。在很多情况下,你都可以使用 File/FileInfo或Directory/DirectoryInfo 完成相同的工作
Filesystemlnfo 抽象基类
DirectoryInfo 和 FlleInfo 类型实现了许多FilesystemInfo 抽象基类的行为。大部分 FllesystemInfo类成员的作用是用来获取指定文件或目录的一般特性(比如创建时间、各种特性等)。
FilesystemInfo 属性
| FllesystemInfo 属性 | |
| 属性 | 作用 |
| Attributes | 获取或设置与当前文件关联的特性.由 FlleAttrlbutes 枚举表示(例如.是只读、加密、隐藏或压缩文件或目录) |
| CreationTime | 获取或设置当前文件或目录的创建时间 |
| Exists | 用来判断指定文件或目录是否存在的值 |
| Extension | 获取文件的扩展名 |
| FullName | 获取目录或文件的完整路径 |
| LastAccessTime | 获取或设置上次访问当前文件或目录的时间 |
| LastWriteTime | 获取或设置上次写人当前文件或目录的时间 |
| Name | Name 获取当前文件或目录的名称 |
FilesystemInfo 类型还定义了Delete()方法,该操作由派生类型从硬盘中删除指定文件或目录来实现。同样,在获取文件特性前使用Refresh()方法能确保当前文件(或目录)的统计信息是最新的。
使用Directoryinfo类型
DirectoryInfo类包含一组用来创建、移动,删除和枚举所有目录/子目录的成员
| DirectoryInfo类型的主要成员 | |
| 成员 | 操作 |
| Create()和CreateSubdirectory() | 按照路径名建立一个目录(或者一组子目录) |
| Delete() | 删除一个目录和它的所有内容 |
| GetDirectories() | 返回一个表示当前目录中所有子目录的DirectoryInfo对象数组 |
| GetFiles() | 返回Filelnfo对象教组,表示指定目录下的一组文件 |
| MoveTo() | 将一个目录及其内容移动到一个新的路径 |
| Parent | 获取指定路径的父目录 |
| Root | 获取路径的根部分 |
获取DirectoryInfo 的属性代码如下

DirectoryInfo dir1 = new DirectoryInfo("."); //绑定当前的应用程序目录
DirectoryInfo dir2 = new DirectoryInfo(@"D:\360Downloads");//使用存在的目录
//如果试图使用一个不存在的目录.系统会引发System.IO.DirectoryNOtFoundExceptlon 异常。因此,如果指定了一个尚未创建的目录的话,在对目录进行操作前首先需要调用Create()方法。
DirectoryInfo dir3 = new DirectoryInfo(@"D:\360Downloads\dir2");
dir3.Create();
Console.WriteLine("DirectoryInfo 主要成员的实现");
Console.WriteLine("FullName:{0}", dir3.FullName);
Console.WriteLine("Name:{0}", dir3.Name);
Console.WriteLine("Parent:{0}", dir3.Parent);
Console.WriteLine("CreationTime:{0}", dir3.CreationTime);
Console.WriteLine("Attributes:{0}", dir3.Attributes);
Console.WriteLine("Root:{0}", dir3.Root);
使用DirectoryInfo 类型枚举出文件
DirectoryInfo dir = new DirectoryInfo(@"C:\Users\Public\Pictures");
FileInfo[] imageFiles = dir.GetFiles("*.jpg", SearchOption.AllDirectories);
foreach (FileInfo f in imageFiles)
{
Console.WriteLine("********************");
Console.WriteLine("file Name:{0}", f.Name);
Console.WriteLine("file Length:{0}", f.Length);
Console.WriteLine("file CreationTime:{0}", f.CreationTime);
Console.WriteLine("file Attributes:{0}", f.Attributes);
Console.WriteLine("********************");
}
使用DirectoryInfo类型创建子目录
DirectoryInfo dir = new DirectoryInfo(@"D:\360Downloads\dir2");
dir.CreateSubdirectory("MyFolder");
//尽骨不一定要去捕获 CreateSubdirectory()方法的返回值,但是需要知道的是.如果执行成功.它会返回DirectoryInfo类型
DirectoryInfo dir1=dir.CreateSubdirectory(@"MyFolser2\Data");
Console.WriteLine("New Foloser:{0}",dir1);
使用Directory类型
Directory的静态成员实现了由DirectoryInfo定义的实例级成员的大部分功能。 Directory成员返回的是字符串数据而不是强类型的Filelnfo 和 DirectoryInfo对象。
获取此计算机上的逻辑驱动器代码如下:
string[] dives = Directory.GetLogicalDrives();
Console.WriteLine("Here are your drives:");
foreach (string s in dives)
{
Console.WriteLine("------->{0}", s);
}
删除之前建立的目录代码如下
try
{
Directory.Delete(@"D:\360Downloads\dir2\MyFolser2\Data");
}
catch (IOException e)
{
Console.WriteLine(e.Message);
}
使用DriveInfo类类型
System.IO命名空间提供了一个叫做Drivelnfo的类。和Drivelnfo.GetLogicalDrivers()相似.Drlvelnfo.GetDrives()静态方法能获取计算机上驱动器的名字。然而和Drlvelnfo.GetDrives()不同,Drlvelnfo提供了许多其他的细节(比如驱动器类型、可用空间、卷标等)。
得到所有驱动器的信息代码如下
DriveInfo[] myDivers = DriveInfo.GetDrives();
foreach (DriveInfo d in myDivers)
{
Console.WriteLine("Name:{0}", d.Name);
Console.WriteLine("Type:{0}", d.DriveType);
//检查驱动器是否已经安装好
if (d.IsReady)
{
Console.WriteLine("Free space:{0}", d.TotalFreeSpace);
Console.WriteLine("Format space:{0}", d.DriveFormat);
Console.WriteLine("Lable space:{0}", d.VolumeLabel);
}
Console.WriteLine("***************************");
}
使用FileInfo类类型
FlleInfo 类能让我们获得硬盘上现有文件的详细信息(创建时间,大小、文件特性等),并帮助我们创建、复制、移动和删除除文件
删除FileInfo实例绑定的文件
| FileInfo 核心成员 | |
| 成员 | 作用 |
| AppendText() | 创建一个StreamWriter类型(后面会讨论),它用来向文件追加文本 |
| CopyTo() | 将现有文件复制到新文件 |
| Create() | 创建一个新文件并且返回一个FileStream类型(后面会讨论).通过它来和新创建的文件进行交互 |
| CreateText() | 创建一个写入新文本文件的StreamWriter对象 |
| Delete() | 删除FileInfo实例绑定的文件 |
| Directory | 获取父目录的实例 |
| DirectoryName | 获取父目录的完整路径 |
| Length | 获取当前文件的大小 |
| MoveTo() | 将指定文件移到新位置.井提供指定新文件名的选项 |
| Name | 获取文件名 |
| Open() | 用各种读/写访问权限和共享特权打开文件 |
| OpenRead() | 创建只读FileStream对象 |
| OpenText() | 创建从现有文本文件中读取教据的StreamReade(后面会讨论) |
| OpenWrite() | 创建只写FileStream类型 |
注意,大部分FileInfo类的成员返回I/O相关的特定对象(Filestream和StreamWriter),让我们以不同格式从关联文件读或向关联文件写数据。
FileInfo.Create()的用法
|
1
2
3
|
FileInfo f = new FileInfo(@"D:\360Downloads\dir2\Test.txt");FileStream fs = f.Create();fs.Close(); |
需要注意的是,FlleInfo.Create()方法返一个FileStearm对象。FileStream能对基层的文件进行同步/异步的读写操作:需要知道的是,FileInfo.Create()返回的FileStream对象给所有的用户授予完全读写操作权限.
还要注意,在使用了当前FileStream对象之后.要确保关闭句柄来释放流的底层非托管资源。由于FileStream实现了IDisposable,所以我们可以使用C#的using域来让编译器生成释放逻辑
FileInfo f1 = new FileInfo(@"D:\360Downloads\dir2\Test2.txt");
using (FileStream f2=f1.Create())
{
}
FileInfo.Open() 方法
我们能使用FileInfo.Open()方法来打开现有文件.同时也能使用它来创建新文件,它比FileInfo.Create()多了很多细竹.因为open()通常有好几个参数,可以限定所操作的文件的整体结构。一旦调用open()完成后.它返回一个FileStream对象。
FileInfo f = new FileInfo(@"D:\360Downloads\dir2\Test3.txt");
using (FileStream fs = f.Open(FileMode.OpenOrCreate, FileAccess.ReadWrite, FileShare.None))
{
}
* 上面的重载 OPen()方法需要3个参数。
* 第一个参数指定I/O请求的基本方式(比如说新建文件、打开现有文件和追加文件等),它的值由FileMode
* 第二个参数的值由FileAccess枚举定义,用来决定基层流的读写行为
* 第三个参数FileShare指定文件在其他文件处理程序中的共享方式。
FileInfo.OpenRead() 和FileInfo.OpenWrite()
FileInfo.Open()方法能让我们用非常灵活的方式获取文件句柄,FileInfo类同样提供了OpenRead()和OpenWrite()成员。这些方法不需要提供各种枚举值.就能返回一个正确配置的只读或只写的FileStream类型。 OPenRead()和OPenWrite()也都返回一个FileStream对象
FileInfo f = new FileInfo(@"D:\360Downloads\dir2\test.txt");
using (FileStream fs = f.OpenRead())
{
Console.WriteLine("ok");
}
FileInfo f4 = new FileInfo(@"D:\360Downloads\dir2\test4.txt");
using (FileStream fs1 = f4.OpenWrite())
{
}
FileInfo.OpenText()
OpenText()方法返回的是一个StreamReader类型(而不是不是FileStream类型)的实例。
FileInfo f = new FileInfo(@"D:\360Downloads\dir2\Test3.txt");
using (StreamReader reader = f.OpenText())
{
}
FileInfo.CreateText() 和 FileInfo.AppendText()
FileInfo.CreateText() 和 FileInfo.AppendText()都返回的是一个StreamWriter类型
FileInfo f = new FileInfo(@"D:\360Downloads\dir2\Test6.txt");
using (StreamWriter sr = f.CreateText())
{
}
FileInfo f1 = new FileInfo(@"D:\360Downloads\dir2\aa.txt");
using (StreamWriter sr = f1.AppendText())
{
}
使用 File类型
Flle类型的静态成员提供了和FileInfo类型差不多的功能。与FileInfo类似,File类提供了
AppendText(),create ()、 createText ()、 open()、 OPenRead ()、 openWrite()和 OpenText()方法。在大多数情况下,File 和 FileInfo 类型能互换使用。
using (FileStream fs = File.Create(@"D:\360Downloads\dir2\bb.txt"))
{
}
using (FileStream fs = File.Open(@"D:\360Downloads\dir2\bb.txt", FileMode.OpenOrCreate, FileAccess.ReadWrite, FileShare.None))
{
}
using (FileStream fs = File.OpenRead(@"D:\360Downloads\dir2\bb.txt"))
{
}
using (FileStream fs = File.OpenWrite(@"D:\360Downloads\dir2\bb.txt"))
{
}
using (StreamReader sr = File.OpenText(@"D:\360Downloads\dir2\bb.txt"))
{
}
using (StreamWriter sw = File.CreateText(@"D:\360Downloads\dir2\bb.txt"))
{
}
using (StreamWriter sw = File.AppendText(@"D:\360Downloads\dir2\bb.txt"))
{
}
使用File 类型的这些新方法,只用几行代码就可以批量读写数据。更好的是,每一个成员都自动关闭基层文件句柄
File新方法如下
| 方法 | 作用 |
| ReadAllBytes() | 打开指定文件,以字节数组形式返回二进制数据,然后关闭文件 |
| ReadAllLines() | 打开指定文件,以字符串教组形式返回字符教据.然后关闭文件 |
| ReadAllText() | 打开指定文件.以System.String形式返回字符数据.然后关闭文件 |
| WriteAllBytes() | 打开指定文件.写人字节数组.然后关闭文件 |
| WriteAllLines() | 打开指定文件.写人字符串教组,然后关闭文件 |
| WriteAllText() | 打开指定文件.写人字符数据.然后关闭文件 |
举例如下
Console.WriteLine("批量读写数据");
string[] myTasks = { "蒸甜糕", "做糖饼", "腌桂花蜜", "做桂花酿" };
//写入文件
File.WriteAllLines(@"D:\360Downloads\dir2\bb.txt", myTasks);
//重新读取然后输出
foreach (string item in File.ReadAllLines(@"D:\360Downloads\dir2\bb.txt"))
{
Console.WriteLine(item);
}
Stream抽象类
在 I/ O 操作中,流代表了在源文件和目标文件之间传输的一定量的数据。无论使用什么设备(文件、网络连接和打印机等)存储或者显示字节。”流”都能提供一种通用的方式来和字节队列进行交互
“流”的概念不仅仅局限于文件输入/输出. NET类库提供了”流”来访问网络、内存地址和其他一些与流相关的抽象设备
Stream派生类型把数据表现为原始的字节流。因此,使用原始的Stream类型有点模糊。一些从Stream派生的类型支持寻址(指获取和调整当前在流中位置的过程)。
下面有关 抽象Stream成员
| 抽象Stream成员 | |
| 成员 | 作用 |
| CanRead,CanWrite和CanSeek | 检侧当前流是否支持读、寻址和写 |
| Close() | 关闭当前流并释放与之关联的所有资源(如套接字和文件句柄)。在内部,这个方法是Dispose()方法的别名.因此"关闭流"从功能上说等价于"释放流" |
| Flush() | 使用当前的缓冲状态更新基层的数据源或储存库。如果流不实现缓冲.这个方法什么都不做 |
| Length | 返回流的长度,以字节来表示 |
| Position | 检侧在当前流中的位置 |
| Read()和ReadByte() | 从当前流读取字节序列或一个字节。井将此流中的位置偏移读取的字节数 |
| Seek | 设置当前流中的位置 |
| SeekLength() | 设置当前流的长度 |
| Write()和WriteByte() | 向当前流中写人字节序列或一个字节,将此流中的当前位置偏移写人的字节数 |
使用FileStream
Fi1eStream类以合适的方式为基于文件的流提供了抽象Stream成员的实现。这是一个相当原始的流,它只能读取或写人一个字节或者字节数组。其实,我们通常不需要直接和 FileStream类型的成员交互,而是使用各种Stream包装类,它们能更方便地处理文本数据和.NET 类型。
具体使用如下
Console.WriteLine("***FileStream***");
//获取一个FileStream对象
using (FileStream fs = File.Open(@"D:\360Downloads\dir2\cc.txt", FileMode.OpenOrCreate))
{
string msg = "Hello";
//把字符串编码成字节数组
byte[] msgAsByteArray = Encoding.Default.GetBytes(msg);
//写入文件
fs.Write(msgAsByteArray, 0, msgAsByteArray.Length);
//重置流的内部位置
fs.Position = 0;
//从文件读取字节并显示在控制台
Console.WriteLine("**Your Message**");
byte[] bytesFromFile = new byte[msgAsByteArray.Length];
for (int i = 0; i < msgAsByteArray.Length; i++)
{
bytesFromFile[i] = (byte)fs.ReadByte();
Console.WriteLine(bytesFromFile[i]);
}
//解码后字符串
Console.WriteLine("Decoded Messges:");
Console.WriteLine(Encoding.Default.GetString(bytesFromFile));
}
而FileStream的缺点:需要操作原始字节
使用streamwriter和streamreader类型
当需要读写基于字符的数据(比如字符串)的时候. streamWriter 和 streamReader 类就非常有用了。它们都默认使用Unicode字符.当然我们也可以提供一个正确配置的System.Text.Encoding 对象引用用来改变默认配置。
StreaoReader 和相关的 StringReader类型都从 TextReader 抽象类派生
StreaoWriter 和相关的 StringWriter类型都从 TextWriter 抽象类派生
写入文本文件(TextWriter )
下面是关于 TextWriter核心成员
| TextWriter核心成员 | |
| 成员 | 作用 |
| Close() | 关闭当前编写器并释放任何与该编写器关联的系统资源。在这个过程中.缓冲区将被自动清理(这个成员在功能上等同与调用Dispose()方法) |
| Flush() | 清理当的编写器的所有缓冲试.使所有缓冲数据写人基础设备.但是不关闭偏写器 |
| NewLine | 代表派生的编写器类的行结束符字符串。默认行结束符字符串是回车符后接一个换行符(\r\n) |
| Write() | 这个重载的方法将一行写入文本流.不限行结束符 |
| WriteLine() | 这个重载的方法将一行写入文本流,后跟行结束符 |
派生的StreamWriter类提供了对Write(), close ()和Flush()方法的有效实现.而且还定义了
AutoFlush 属性。如果把这个属性设置为 true 的话, StreamWriter 会在每次执行一个写操作后,立即写入数据并清理缓冲区。设置 AutoFlush为 false 能获得更好的性能,这样的话.使用 StreamWriter完成写操作后需要调用 Close()。
写入文本文件代码如下:
Console.WriteLine("****Fun with StreamWriter*****");
using (StreamWriter writer = File.CreateText(@"D:\360Downloads\dir2\re.txt"))
{
writer.WriteLine("鱼是做给大家伙儿吃的,乔初熏发觉这些人都挺爱吃甜口吃食,便打算做个糖醋鲤");
writer.WriteLine("鱼是做给大家伙儿吃的,乔初熏发觉这些人都挺爱吃甜口吃食,便打算做个糖醋鲤");
writer.WriteLine("鱼是做给大家伙儿吃的,乔初熏发觉这些人都挺爱吃甜口吃食,便打算做个糖醋鲤");
for (int i = 0; i < 10; i++)
{
writer.Write(i + " ");
}
}
Console.WriteLine("Created file");
读文本文件(TextReader )
下面是关于 TextReader 核心成员
| TextReader 主要成员 | |
| Peek() | 返回下一个可用字符,而不更改读取器位置。返回-l表示已经到了流的尾部 |
| Read() | 从输人流中读取救据 |
| ReadBlock() | 从当前流中读取最大计数字符,并从索引开始将该数据写人缓冲区 |
| ReadLine() | 从当前流中读取一行字符,并将数据作为字符串返回(返回空字符串代表EOF) |
| ReadToEnd | 读取从当前位置到流结尾的所有字符,并将它们作为一个字符串返回 |
读文本文件代码如下:
Console.WriteLine("***Fun with StreamReader***");
using (StreamReader sr = File.OpenText(@"D:\360Downloads\dir2\re.txt"))
{
string inpt = null;
while ((inpt=sr.ReadLine())!=null)
{
Console.WriteLine(inpt);
}
}
直接创建streamwriter/streamreader类型
Console.WriteLine("直接创建streamwriter/streamreader类型");
using (StreamWriter sw = File.CreateText(@"D:\360Downloads\dir2\chuchu.txt"))
{
string mag = " 不一会儿,大锅里的水烧的滚沸,乔初熏把手洗干净,伸手捏了些羊肉,攒成丸子便往锅里一丢,小桃儿在旁边看着直咋舌:“初熏姐姐,这样会不会太松了。”她见乔初熏手上也不怎么使劲儿,生怕羊肉丸子一进锅便散了。";
sw.WriteLine(mag);
Console.WriteLine("ok");
}
using (StreamReader sr = File.OpenText(@"D:\360Downloads\dir2\chuchu.txt"))
{
string input = null;
while ((input = sr.ReadLine()) != null)
{
Console.WriteLine(input);
}
}
使用stringwriter和stringreader类型
使用 StringWriter 和 stringReader 类型,我们可以将文本信息当做内存中的字符一样来处理。当想为基层缓冲区添加基于字符的信息的时候,它们就非常有用。
Console.WriteLine("Fun StringWriter");
using (StringWriter sw = new StringWriter())
{
sw.WriteLine("乔初熏手上动作不停,一边笑着解释道:“不会。手劲儿太大了反而不好。汆出来的丸子容易发死,吃起来不够鲜嫩.");
Console.WriteLine(sw);
}
因为StringWriter 和 StreamWriter 都从一个基类(TextWriter )派生.它们的写操作逻辑代码或多或少有点相同。但需要知道, StringWriter 还有一个特点.那就是它能通过 GetStringBuilder() 方法来
获取一个System.Text.StringBuilder 对象:
Console.WriteLine("GetStringBuilder");
using (StringWriter sw = new StringWriter())
{
sw.WriteLine("很快,一边蒸锅里的鱼也差不多到火候了。乔初熏拿着勺子搅了搅汤,让小桃儿把鱼端出来。");
Console.WriteLine(sw);
StringBuilder sb = sw.GetStringBuilder();
sb.Insert(0, "Hey");
Console.WriteLine(sb.ToString());
sb.Remove(0, "Hey".Length);
Console.WriteLine(sb.ToString());
}
使用binarywriter和binaryreader
BinaryWriter和binaryreader都从 System.Object 直接派生。这些类可以让我们从基层流中以简洁的二进制格式读取或写人离散数据类型。 BinaryWriter 类型定义了一个多次重载的Write方法,用于把数据类创写入基层的流,除Write()方法, BinaryWriter还提供了另外一些成员让我们能获取或设置从Stream派生的类型,并且提供了随机数据访问
下面有关 BinaryWriter核心成员
| BinaryWriter核心成员 | |
| BaseStream | 这个只读属性提供了BinaryWriter对象使用的基层流的访问 |
| Close() | 这个方法关闭二进制流 |
| Flush() | 这个方法别新二进制流 |
| seek() | 这个方法设置当前流的位置 |
| Write | 这个方法将值写入当前流 |
下面有关 BinaryReaer核心成员
| BinaryReader成员 | |
| BaseStream | 这个只读属性提供了BinaryReder对象使用的基层流的访问 |
| Close() | 这个方法关闭二进制阅读器 |
| PeekChar() | 这个方法返回下一个可用的字符,并且不改变指向当前字节或字符的指针位置 |
| Read() | 读取给定的字节或字符,并把它们存入数组 |
| Readxxx() | BinaryReader类定义了许多 Read()方法来从流中获取下一个类型(ReadBoolean() ReadByte() ReadInt32()) |
下面是有关的代码
Console.WriteLine("*****Fun with Writer 和Reader******");
FileInfo f = new FileInfo(@"D:\360Downloads\dir2\aa.txt");
using (BinaryWriter bw = new BinaryWriter(f.OpenWrite()))
{
Console.WriteLine(bw.BaseStream);
double a = 1234.67;
int i = 3452;
string str = "Hello";
bw.Write(a);
bw.Write(i);
bw.Write(str);
}
Console.WriteLine("Done!");
using (BinaryReader br = new BinaryReader(f.OpenRead()))
{
Console.WriteLine(br.ReadDouble());
Console.WriteLine(br.ReadInt32());
Console.WriteLine(br.ReadString());
}
以编程方式"观察"文件 FileSystemWatcher
Console.WriteLine("****FileSystemWatcher****");
FileSystemWatcher watcher = new FileSystemWatcher();
try
{
watcher.Path = @"D:\360Downloads\dir2";
}
catch (Exception e)
{
Console.WriteLine(e.Message);
}
watcher.NotifyFilter = NotifyFilters.LastAccess | NotifyFilters.LastWrite | NotifyFilters.FileName | NotifyFilters.DirectoryName;
watcher.Filter = "*.txt";
watcher.Changed += new FileSystemEventHandler(OnChanged);
watcher.Created += new FileSystemEventHandler(OnChanged);
watcher.Deleted += new FileSystemEventHandler(OnChanged);
watcher.Renamed += new RenamedEventHandler(OnRenamed);
watcher.EnableRaisingEvents = true;
Console.WriteLine("Press q");
while (Console.ReadLine() != "q")
static void OnChanged(object source, FileSystemEventArgs e)
{
Console.WriteLine("File:{0}{1}", e.FullPath, e.ChangeType);
}
static void OnRenamed(object source, FileSystemEventArgs e)
{
Console.WriteLine("File:{0},OnRenamed:{1}", e.FullPath, e.ChangeType);
}
RabbitMQ安装笔记
前言
项目中某些场景考虑到高并发情况,调研后决定使用RabbitMQ,本来以为很简单,没想到配置环境花费了好多时间,按照网上的方法来,总是有其他问题需要继续查找,特记录此笔记,方便下次部署安装。
本笔记只记录安装过程,不探讨RabbitMQ技术。
准备
使用RabbitMQ,除了要安装RabbitMQ外,还必须安装Erlang,由于RabbitMQ使用Erlang语言编写,所以必须先安装Erlang语言运行环境。
1.Erlang下载:http://www.erlang.org/downloads
2.RabbitMQ下载:http://www.rabbitmq.com/
另外先提一下,Erlang和RabbitMQ安装好需要添加到系统的环境变量中,因为这个花费了我一些时间。
Erlang安装
1.安装
下载完Erlang之后,打开安装包后,一步步安装完成,这里没什么需要注意的地方。
2.设置环境变量
找到Erlang的安装路径打开到bin文件夹下,注意此路径。‘
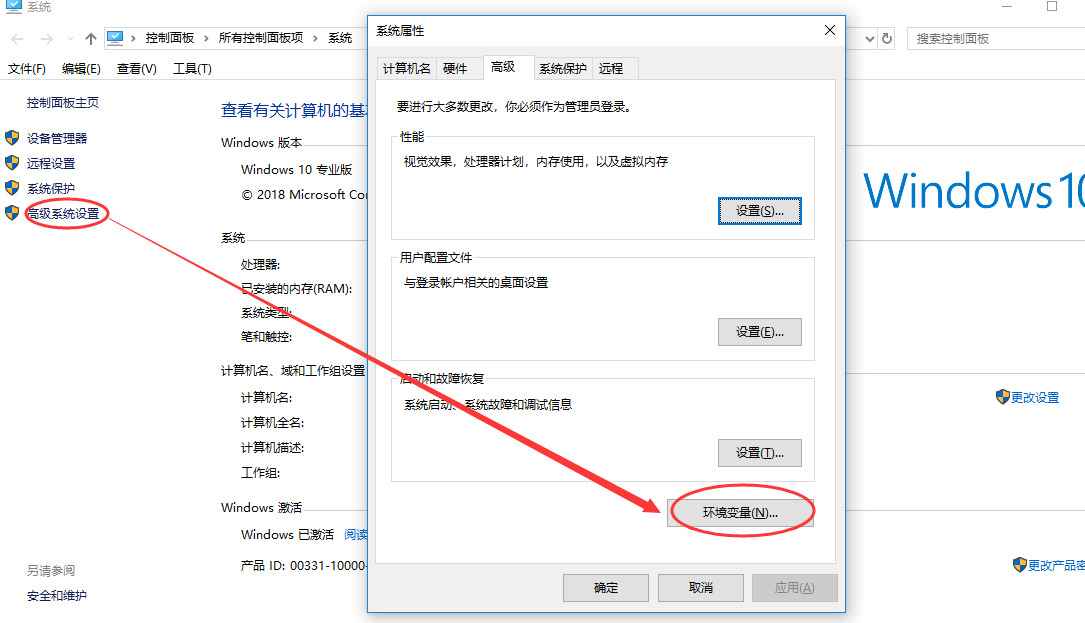
右键我的电脑,选择属性,找到高级系统设置,点开后选择高级里的环境变量。
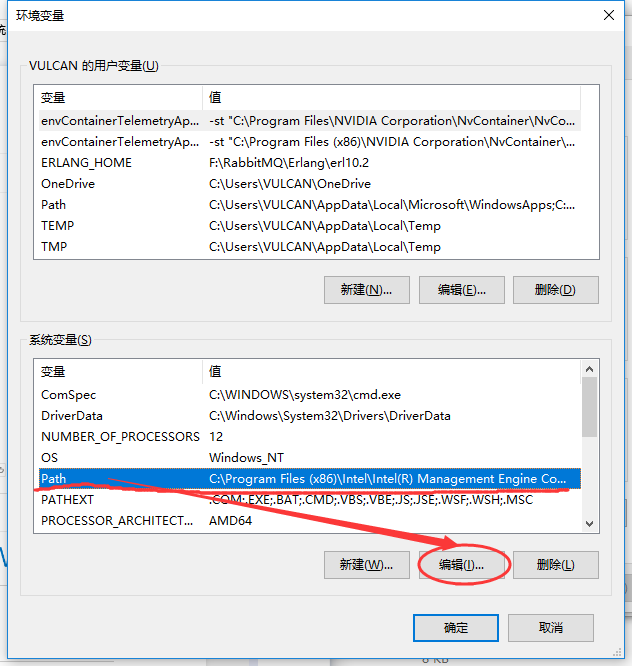
找到系统变量中的Path,点击编辑
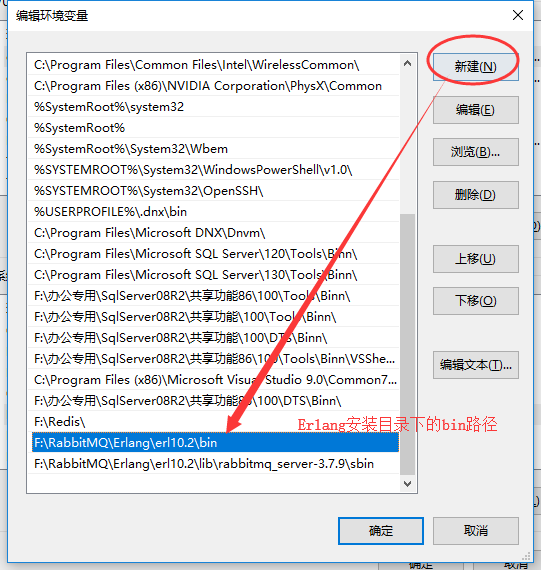
新建环境变量,添加路径,可以直接复制打开的Erlang的bin路径。
3.检查Erlang是否安装成功
打开cmd,输入 erl 后回车,如果能显示版本信息,表明安装成功。
RabbitMQ安装
1.解压下载好的RabbitMQ
2.配置环境变量
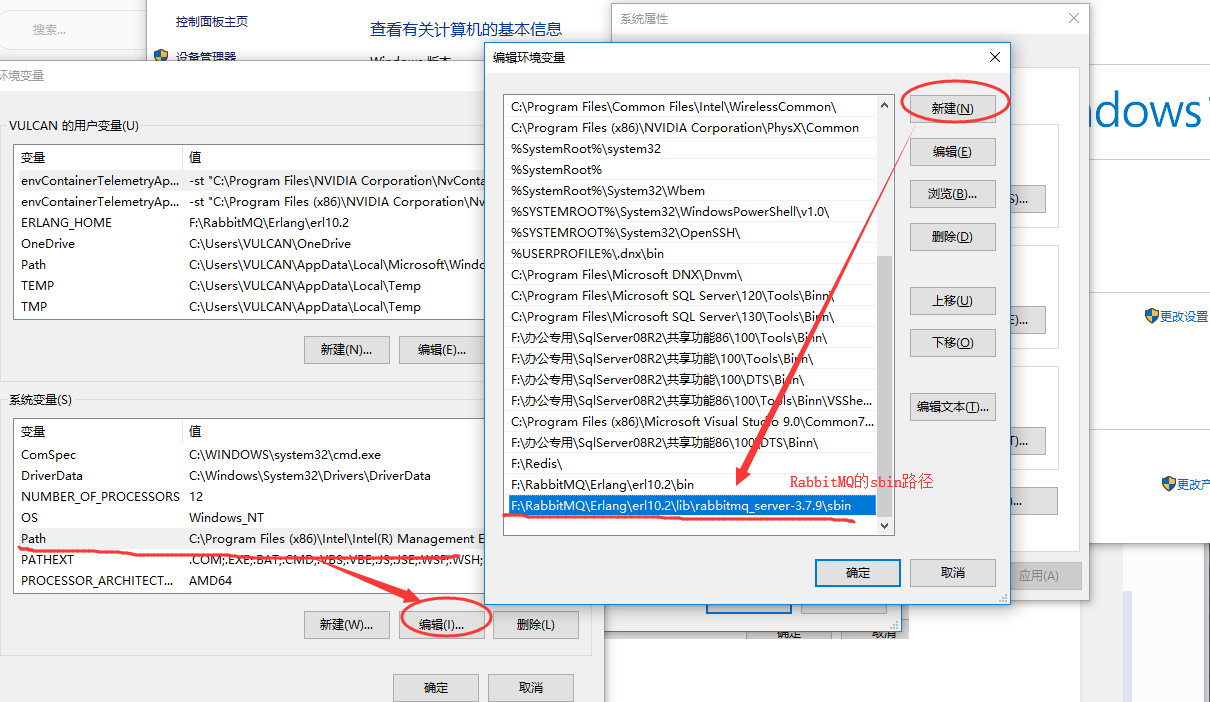
找到RabbitMQ的安装路径打开到sbin文件夹下,注意此路径。
同Erlang的环境变量添加,新建路径,添加到系统变量的Path中
3.CMD中安装、启动服务
使RabbitMQ以Windows Service的方式在后台运行,打开CMD,定位到RabbitMQ的sbin目录下。
执行:
rabbitmq-service install rabbitmq-service enable rabbitmq-service start
注意,CMD需要管理员权限,否则会报错Unable to register service with service manager. Error: Access is denied.
执行完成后,显示如下信息,表示RabbitMQ的服务端已经启动起来了。

然后,可以用rabbitmqctl这个脚本查看和控制RabbitMQ服务端的状态。
查看状态:
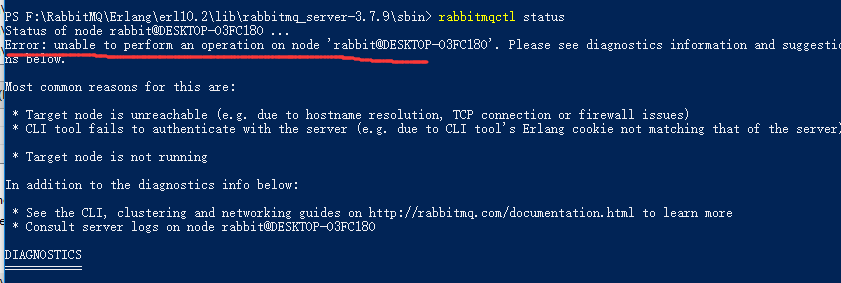
rabbitmqctl status
此时查看一般会出现如下错误:
解决方法如下:
将C:\Users\XXXX\.erlang.cookie 文件拷贝到C:\Windows\System32\config\systemprofile替换掉.erlang.cookie文件。(XXXX为window账户)
重启rabbitMQ服务:CMD中 先输入 net stop RabbitMQ ,然后输入 net start RabbitMQ
net stop RabbitMQ net start RabbitMQ
此后,再次输入
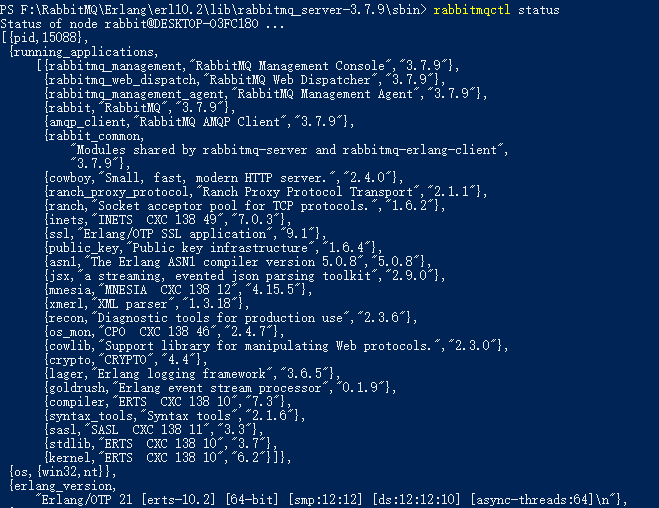
rabbitmqctl status
显示如下信息,RabbitMQ至此已经正确安装完毕。
用户设置与web管理工具插件安装
1.新建用户
使用命令查看用户:
rabbitmqctl list_users

RabbitMQ会为我们创建默认的用户名guest和密码guest,guest默认拥有RabbitMQ的所有权限。
如果我们需要自己创建用户,那么需要执行类似于下面的命令,设置密码,并授予权限,并将其设置为管理员。
1 rabbitmqctl add_user ading 123456 //创建用户ading密码为123456 2 rabbitmqctl set_permissions ading ".*" ".*" ".*" //赋予ading读写所有消息队列的权限 3 rabbitmqctl set_user_tags ading administrator //分配用户组
另,修改用户密码和删除用户方法如下:
1 rabbitmqctl change_password ading 123 2 rabbitmqctl delete_user ading
2.安装web管理工具插件
CMD中输入:
rabbitmq-plugins enable rabbitmq_management
web管理工具的地址是:http://localhost:15672,初始用户名:guest 初始密码:guest
打开浏览器,输入地址:http://127.0.0.1:15672/#/
总结
不懂的技术,如果配置部署麻烦,也请不要烦躁,因为他人都得经历这些。你得知道,那么多人推荐那么多使用,总是有原因的,别因为一点麻烦就放弃一项好的技术。
一次线上问题引发的对于C#中相等判断的思考
线上报来一个问题,说用户的数据丢失了。开发经过紧张的调查。终于找到了原因。
if (newData.GetValue(rowIndex) == oldData.GetValue(rowIndex))
{
..................
}
public object GetValue(string fieldName))
{
...............
return values[filedName]; //这是一个简单类型: int,string
}
问题出在了 if 中的比较上。 values[rowIndex] 中保存的是一个整数,开发认为两个整数比较实用 == 就可以了。
但是 values[rowIndex] 中的整数经过 GetValue返回后被作为 object 对象返回了,这时如果还使用 == 进行比较就会出现不等的情况。
我们来看一个更全面的例子:
static void Main(string[] args)
{
object value1 = new object();
object value2 = new object();
value1 = 2;
value2 = 2;
Console.WriteLine("value1 == value2 {0}", (value1 == value2).ToString());
Console.WriteLine("vvalue1.Equals(value2) {0}", value1.Equals(value2).ToString());
Console.WriteLine("Equals(value1, value2) {0}", Equals(value1, value2).ToString());
Console.WriteLine("ReferenceEquals(value1,value2) {0}", ReferenceEquals(value1,value2).ToString());
}
运行结果
value1 == value2 False
value1.Equals(value2) True
Equals(value1, value2) True
ReferenceEquals(value1,value2) False
如果我们将value1, value2 都定义为数字,但是一个是long,一个是uint.
static void Main(string[] args)
{
long value1 = 2;
int value2 = 2;
Console.WriteLine("value1 == value2 {0}", (value1 == value2).ToString());
Console.WriteLine("value1.Equals(value2) {0}", value1.Equals(value2).ToString());
Console.WriteLine("Equals(value1, value2) {0}", Equals(value1, value2).ToString());
Console.WriteLine("ReferenceEquals(value1,value2) {0}", ReferenceEquals(value1,value2).ToString());
}
看一下运行结果 ,使用 == ,和 value1.Equals 方法比较是相等的。
value1 == value2 True value1.Equals(value2) True Equals(value1, value2) False ReferenceEquals(value1,value2) False
结合上面两个例子,我们定义一个long 变量, 一个unit 变量, 给它们赋值之后,再将这两个变量赋值给两个object 对象。
static void Main(string[] args)
{
object value1 = new object();
object value2 = new object();
long lgval = 2;
int ival = 2;
value1 = lgval;
value2 = ival;
Console.WriteLine("lgval == ival {0}", (lgval == ival).ToString());
Console.WriteLine("value1 == value2 {0}", (value1 == value2).ToString());
Console.WriteLine("value1.Equals(value2) {0}", value1.Equals(value2).ToString());
Console.WriteLine("Equals(value1, value2) {0}", Equals(value1, value2).ToString());
Console.WriteLine("ReferenceEquals(value1,value2) {0}", ReferenceEquals(value1,value2).ToString());
}
可以看到,除去值类型 lgval 和 uval 相等外,其它都是不相等的。
lgval == uval True value1 == value2 False value1.Equals(value2) False Equals(value1, value2) False ReferenceEquals(value1,value2) False
是不是很抓狂? 到底什么情况下相等?什么情况下不等?我们先将上面的结果总结一下。
|
value1 和value2都是Object 对象 含有相同类型的值对象(int) 含有相同的值 |
value1 是long,value2 是 int 含有相同的值 |
value1 和value2都是Object 对象 含有不同类型的值对象(long,int) 含有相同的值 |
|
value1 == value2 |
false | true | false |
value1.Equals(value2) |
true | true | false |
Equals(value1, value2) |
true | false | false |
ReferenceEquals(value1,value2) |
false | false | false |
如果将一个值类型赋值给一个object 对象后,如何判断相等? 微软官方也没有给出一个标准的说法。从测试的角度来看。
两个比较的 object 中的内容如果类型相同,可以使用Equals 来进行比较。
不过我个人还是建议如果是比较值,还是转换为对应的值类型进行比较,这样比较清晰,不容易犯错,大家也不用搞清楚 == 和 Equals 之前的细微差别。
ps: 如果object 的类型是 string , 上面的结果又会有所不同,有兴趣的同学可以自己尝试一下。
ef和mysql使用(一)
ef开发模式有3种:DateBase First(数据库优先)、Model First(模型优先)和Code First(代码优先)。这里我用的是code first 一个简单的例子:
public class BloggingContext : DbContext
{
public BloggingContext() : base("name=testConn")
{ }
public DbSet<Person> Blogs { get; set; }
public DbSet<DepartPerson> Posts { get; set; }
}
class Program
{
static void Main(string[] args)
{//模型改变重新创建数据库
Database.SetInitializer(new DropCreateDatabaseIfModelChanges<BloggingContext>());
using (var db = new BloggingContext())
{
Person blog = new Person()
{
Name = "zhangsan",
Age = "29",
ID = Guid.NewGuid().ToString().Replace("-", "")
};
db.Blogs.Add(blog);
db.SaveChanges();
foreach (var item in db.Blogs)
{
Console.WriteLine("Name:" + item.Name);
}
}
Console.Read();
}
简单介绍一下Database.SetInitializer方法
一:数据库不存在时重新创建数据库
三:模型更改时重新创建数据库
四:从不创建数据库
这对这几种方式,可以通过代码做出改动,然后调试一下观察一下数据库的变化,会理解的更透彻!
ASP.NET/MVC/Core的HTTP请求流程
ASP.NET HTTP管道(Pipeline)模型
1. 先讲一点,再深刻思考
一般我们都在写业务代码,优化页面,优化逻辑之间内徘徊。也许我们懂得HTTP,HTTPS的GET,POST,但是我们大部分人是不知道ASP是如何去解析HTTP,或者IIS是如何去处理页面请求。我们只知道WebForm拉控件,MVC写Controller,Action,却不知道IIS,NetFrameWork帮我们做了很多事情。那接下我们就是要去了解IIS帮我们做了些啥事情。
2. 那啥叫管道(Pipeline)模型
-
初理解Pipeline
-
从一个现象说起,有一家咖啡吧生意特别好,每天来的客人络绎不绝,客人A来到柜台,客人B紧随其后,客人C排在客人B后面,客人D排在客人C后面,客人E排在客人D后面,一直排到店面门外。老板和三个员工首先为客人A准备食物:员工甲拿了一个干净的盘子,然后员工乙在盘子里装上薯条,员工丙再在盘子里放上豌豆,老板最后配上一杯饮料,完成对客人A的服务,送走客人A,下一位客人B开始被服务。然后员工甲又拿了一个干净的盘子,员工乙又装薯条,员工丙又放豌豆,老板又配上了一杯饮料,送走客人B,客人C开始被服务。一直重复下去。
-
从效率方面观察这个现象,当服务客人A时,在员工甲拿了一个盘子后,员工甲一直处于空闲状态,直到送走客人A,客人B被服务。老板自然而然的就会想到如果每个人都不停的干活,就可以服务更多的客人,赚到更多的钱。老板通过不停的尝试想出了一个办法。以客户A,B为例阐述这个方法:员工甲为客户A准备好了盘子后,在员工乙开始为客户A装薯条的同时,员工甲开始为客户B准备托盘。这样员工甲就可以不停的进行生产。整个过程如下图,客户们围着咖啡吧台排队,因为有四个生产者,一个老板加三个员工,所以可以同时服务四个客户。我们将目光转向老板,单位时间从他那里出去的客户数提高了将近四倍,也就是说效率提高将近四倍。
这样子,我们就很好理解了Pipeline了,那其实就是每个人络绎不绝的做自己的事情,但个人事情又是整个流程的一部分,有点像工厂的小妹,只做包鞋底,但是这又是制造鞋的中间流程。一条流水,一条管道,一直处理下去。那每个HTTP请求,到了IIS也是这样子的。
-
- 针对Pipeline模型带来的启示,好处
- 工作流的参考模型
其实就是上面所说一样,pipeline模型与工作流模型,都是链式的,就像一条生产线,各个组件的前后协同。 - 服务framework的参考构建模型
Pipeline模型的一个特点是,在其内部是以组建的模式来实现组合的(虽然这些组建有先后顺序之分),它假如你把侧重点放在它的链式组合上,而不是将侧重点放在上面的工作流上(工作流的关注点是流程的先后顺序),那么完全可以用这种方式来搭建一个复杂的服务,当然这样做的前提是,单个组件的粒度必须尽可能小并且耦合性极低。
那其实就很像现在的微服务了,只不过微服务更大,服务对象是一个应用程序。
- 工作流的参考模型
-
Pipeline模型的缺点
每次它对于一个输入(或者一次请求)都必须从链头开始遍历(參考Http Server处理请求就能明确),这确实存在一定的性能损耗。
3. 讲完Pipeline,我们讲他在IIS上的实现
3.1 Http请求带服务器的时候
-
当服务器接收到一个Http请求的时候,IIS是如何去决定,并处理该请求。答案就是文件的“后缀名”。
服务器获取所请求的页面或文件的后缀名后,那服务器就回去寻找能出来这些后缀的应用程序。若是IIS找不到,并且文件没有受到IIS的保护(保护:App_Code文件夹的文件,不保护:平常的JS文件等),就会直接返回给客户端(浏览器,移动端等)
那么能处理后缀名的程序叫什么呢? ISAPI 应用程序(Internet Server Application Programe Interface,互联网服务器应用程序接口)。它其实是一个接口,起到一个代理的作用,他的主要工作就是将请求的页面(文件)与处理该页面(文件)的后缀的处理程序进行一个映射。让其可以争取的去处理页面(文件)。
那这个应用程序长什么样子呢?- 我们打开IIS(server2003),随意选中一个站点,鼠标右击属性,然后选择“主目录”选项,接着选择“配置”。然后就可以看到下面的画面。

这边我们能看到后缀名与之可执行的文件路径。
接着我们找到“.axpx”的后缀名,打开来看。
我们可以发现".aspx"的后缀名是有aspnet_isapi.dll来处理的,所以IIS将".aspx"页面的请求交给这个dll,就不关心后面是如何处理了。所以我们现在知道了,ASP.NET只是服务器(IIS)的一个组成部分而已,它是一个ISAPI扩展。
-
上面是server2003的情况,现在08以上变成了不是在属性里面了, 他变成了IIS中的“ISAPI筛选器”和“处理程序映射”了。

- 我们点击“ISAPI筛选器”,可以出现发现,筛选器是分FrameWork与位数的,所以有四个。

- 我们进入处理程序映射,找出后缀为“.aspx”的,可以发现有很多个,对应了framework与位数,并且有个处理程序,

3.双击进入,可以看到可以到处理模块的具体路径,以及请求限制。

注意,这边要是限制后,页面(文件)只能以某种特定方式访问。
3.2 宿主环境(Hosting)
从本质上讲,Asp.Net 主要是由一系列的类组成,这些类的主要目的就是将 Http 请求转变为对客户端的响应。HttpRuntime 类是 Asp.Net 的一个主要入口,它有一个称作 ProcessRequest的方法,这个方法以一个 HttpWorkerRequest 类作为参数。HttpRuntime 类几乎包含着关于单个 Http 请求的所有信息:所请求的文件、服务器端变量、QueryString、Http 头信息 等等。Asp.Net 使用这些信息来加载、运行正确的文件,并且将这个请求转换到输出流中,一般来说,也就是 HTML 页面。当然也可是是文件。
当页面(文件)发生变动时,为了能够卸载运行在同一进程中的应用程序,当然卸载也是为了重新新加载,Http请求被分放在相互隔离的应用程序域。也就是“AppDomain”。
那么对于IIS来说,IIS依赖一个叫HTTP.SYS的内置驱动程序来监听外部的HTTP请求,在操作系统启动的时候,IIS会在HTTP.SYS中注册自己的虚拟路径。(注册可以理解为,告诉HTTP.SYS哪些URL可以访问,哪些不可以访问,404就可以怎么来的,就是这么来的。)
如果是可以访问的URL,那么HTTP.SYS会将这个请求扔给IIS工作者进程。(就是我们所熟悉的W3WP.EXE,IIS5.0叫做ASPNET_WP.EXE)。
运行是每个进程都有一个身份标识,以及一系列的可选性能参数,其实就是应用程序池,唯一标识就是应用程序池名称。
基础的知识点都懂了,我们来看下一个大概的HTTP请求的过程
- HTTP.SYS接收Http请求信息。并将信息保存到HttpWorkRequest类中。
- 从相互隔离的AppDomain中加载HttPRuntime。
- 调用HttpRuntime的ProcessRequest方法。
- 程序猿创造世界
- IIS接收返回的数据流,重新返回给HTTP.SSY
- HTTP.SYS将数据返回给客户端(浏览器)

3.3 接下来是重点,理解Pipeline
前面讲了那么多,终于进入到重点,划重点。
首先我们先知道了什么是Pipeline,接着我们知道一个Http的请求过程。然后我们就知道了,原来Http请求到服务器,原来是走这样一条路。
但是我们忽略了,这个过程跟我们程序,跟我们代码怎么衔接起来的。
当Http请求进入 Asp.Net Runtime以后,它的管道由托管模块(Managed Modules)和处理程序(Handlers)组成,并且由管道来处理这个 Http请求。这个就是所谓的ASP的Http管道模型了。

接下来我们看下这个管道模型是怎么流动的。(WebForm)
- 首先进来肯定是HTTPRuntime,然后通过HttpApplicationFactory创建HttpApplication。
- HttpApplication会创建该次Http请求的HttpContext(上下文),那这个对象我们就很熟悉了,里面就包括HttpRequest、HttpResponse、HttpSessionState等。
- 那接下来请求会通过一系列的Module(可以理解为车间,可以做通过的物品做事情),Module可以做一些执行某个实际工作前的事情。因为它会Http请求有完全的控制权。
-
当Http请求完,它会被HttpHandler处理。在这一步,也就是我们实际做的事情了,他可以完成我们.aspx的所有业务。WebForm的每个页面都是继承“Page”,而“Page”继承了“IHttpHandler”接口
public class Page : TemplateControl, IHttpHandler{ // 代码省略 } - HttpHandler处理完后,又会回到Module,这时可以做一些实际工作后的事情。
我们很多事件,是不是有分前与后,就是这个道理。进行事件的前后拦截。 -
我们可以看下,在只有Module与Handler的情况,整个Http的流动走向,大概是这样子

3.4 那讲完WebForm的,我们来讲MVC的
在IIS7之前,如IIS6或IIS5,请求处理管道分为两个:IIS请求处理管道和ASP.NET管道,若客户端请求静态资源则只有IIS管道进行处理,而ASP.NET管道不会处理该请求。从IIS7开始两个管道合二为一,称为集成管道。其实就是我们IIS里会选择到应用程序池的托管模式。
再次了解
-
IIS 6以及IIS 7经典模式
早期的IIS版本中,IIS接收到一个请求时先判断请求类型,如果是静态文件直接由IIS处理;如果是一个ASP.NET请求类型,IIS把请求发送给IIS的扩展接口ASP.NET ISAPI DLL。ISAPI相当于ASP.NET应用的容器,这也是我们之前讲的。 -
IIS 7 集成模式
IIS 7和之前的版本区别比较大,IIS7直接把ASP.NET的运行管道流程集成到了IIS上。- 在IIS7中,ASP.NET请求处理管道Pipeline直接覆盖了IIS本身的管道Pipeline,IIS整个流程按照ASP.ENT管道流程执行,例如BeginRequest、AuthenticateRequest、…、EndRequest。而不是通过插件扩展(ISAPI)形式,不同的内容(jpg、html、php等)通过不同的插件来执行。
- IIS7的优势体现在哪里?开发人员可以实现自定义的HttpModule或者HttpHandler,然后直接集成到IIS上,例如,我可以自定义一个JpgHttpHandler,然后通过IIS的Handler部署方式,把JpgHttpHandler部署到IIS上,处理所有的请求格式为*.jpg的请求。
知道这些我们继续了解MVC的管道模式
废话不多说,直接上图
废话也不多说,直接走下流程(以我的方式理解)
废话有点多
- 首先进入HttpRuntime,在一样通过HttpApplicationFactory创建HttpApplication
- HttpApplication会创建该次Http请求的HttpContext(上下文),那这个对象我们就很熟悉了,里面就包括HttpRequest、HttpResponse、HttpSessionState等。(这些都跟webform是一样的)
- HttpApplication继承IHttpHandler,接着我们开始走Module
- 然后我们进入到使用UrlRoutingModule(路由系统)UrlRoutingModule,从Http请求获取Controller和Action以及路由数据。
- 接着匹配Route规则,获取Route对象,解析对象。
- 请求IRouteHandler(MVCRouteHandler)
- 执行ProcessRequest方法,然后使用ControllerBulider获取ControllerFactory
- 接着就调用到Controller,同样的的方法到达Action,并执行
- 在执行Controller与Action可能会有各种认证,各种特性拦截
- 程序猿创造世界
- 返回ActionResult
- 响应Http
- 客户端接收响应
接下来我们具体了解下细节
-
HttpApplication与HttpModule
HTTP请求由ASP.NET运行时接管之后,HttpRuntime会利用HttpApplicationFactory创建或从HttpApplication对象池(.NET中类似的机制有线程池和字符串拘留池)中取出一个HttpApplication对象,同时ASP.NET会根据配置文件来初始化注册的HttpModule,HttpModule在初始化时会订阅HttpApplication中的事件来实现对HTTP请求的处理。
public class HttpApplication : IComponent, IDisposable, IHttpAsyncHandler, IHttpHandler, IRequestCompletedNotifier, ISyncContext{ public HttpApplication(); public ISite Site { get; set; } public IPrincipal User { get; } ... }很明显我们可以看到HttpApplication继承了IHttpHandler,是跟WebForm的Page是一样的
-
Route
一个HTTP请求会经过至少一个HttpModule的处理。UrlRoutingModule是非常重要的模块,它是路由系统的核心。路由系统的职责是从请求URL中获取controller和action的名称以及其它请求数据。
UrlRoutingModule根据当前请求的URL和RouteTable中已注册的路由模板进行匹配并返回第一个和当前请求相匹配的路有对象Route,然后根据路有对象获取路由数据对象RouteData(ASP.NET MVC中,路由数据必须包含controller和action的名称),再有RouteData获取IRouteHandler最终有IRouteHandler得到IHttpHandler -
HttpHandler
一个HTTP请求最终要进入HttpHanler中进行处理,一次HTTP请求只能被一个HttpHandler进行处理。
-
Controller
IHttpHandler在ProcessRequest方法中对当前请求进行处理,在该方法中通过ControllerBuilder得到IControllerFactory然后通过反射的方式获取Controller的类型。 -
Action
ASP.NET MVC中ControllerBase是所有Controller的基类,在该类型的Execute方法中通过IActionInvoker的InvokeAction方法来执行对Action的调用。在Action执行前会进行模型绑定和模型认证操作。
-
Filters
在ASP.NET MVC5中有常用的过滤器有5个:IAuthenticationFilter、IAuthorizationFilter、IActionFilter、IResultFilter、IExceptionFilter。
在ASP.NET MVC中所有的过滤器最终都会被封装为Filter对象,该对象中FilterScope类型的属性Scope和int类型属性Order用于决定过滤器执行的先后顺序,具体规则如下:
Order和FilterScope的数值越小,过滤器的执行优先级越高;
Order比FilterScope具有更高的优先级,在Order属性值相同时FilterScope才会被考虑//数值越小,执行优先级越高 public enum FilterScope { Action= 30, Controller= 20, First= 0, Global= 10, Last= 100 } -
ActionResult
Action执行完毕之后会返回ActionResult类型对象作为对此次请求进行处理的结果,对于不是ActionResult类型的返回值,ASP.NET MVC会将其转换为ActionResult类型。
总结:那这个就是MVC模式下,一个大概的请求走向,在MVC的模式下,它的管道是啥样子的。
3.5 看完MVC ,我们接着来看最牛的Core,谁叫它可以跨平台呢【傲娇】
既然Core是跨平台的,那么它不依托IIS,现在的IIS就是个摆设,它有独立的Core的SDK,Core的RunTime。我们来一探究竟!
Core是跨平台的,那他是怎么实现的呢,其实他自己本身有自己的Kestrel Server,可以直接对外部提供服务。但是还需要有个反向代理服务器将他保护起来,IIS就是其一,其他平台有其他的方式。
上图:
知识点:IIS 是通过 HTTP 的方式来调用我们的 ASP.NET Core 程序。而部署在IIS中时,并不需要我们手动来启动 ASP.NET Core 的控制台程序,这是因为IIS新增了一个 AspNetCoreModule 模块,它负责 ASP.NET Core 程序的启动与停止,并能监听 ASP.NET Core 程序的状态,在我们的应用程序意外崩溃时重新启动。
-
Hostting(宿主)
IIS通过Http调用Core应用程序,所以我们肯定要创建一个Host来启动Core,WebHost,上面我们也讲到宿主,我们通过宿主在生成一系列的Http的上下文,环境等。整个http请求都在宿主内。-
WebHost的创建
public class Program{
public static void Main(string[] args){
CreateWebHostBuilder(args).Build().Run();
}public static IWebHostBuilder CreateWebHostBuilder(string[] args) => WebHost.CreateDefaultBuilder(args) .UseStartup<Startup>(); }我们可以看到WeHost通过静态本身来调用创建出来的。“CreateDefaultBuilder”用来做一些简单的配置
- 注册 Kestrel 中间件,指定 WebHost 要使用的 Server(HTTP服务器)。
- 设置 Content 根目录,将当前项目的根目录作为 ContentRoot 的目录。
- 读取 appsettinggs.json 配置文件,开发环境下的 UserSecrets 以及环境变量和命令行参数。
- 读取配置文件中的 Logging 节点,对日志系统进行配置。
- 添加 IISIntegration 中间件。
- 设置开发环境下, ServiceProvider 的 ValidateScopes 为 true,避免直接在 Configure 方法中获取 Scope 实例。
接着指定
Startup最终使用Build创建WebHost。紧接着使用Run将程序跑起来。 - WebHost的启动
- 初始化,构建 RequestDelegate
RequestDelegate 是我们的应用程序处理请求,输出响应的整个过程,也就是我们的 ASP.NET Core 请求管道。- 调用 Startup 中的 ConfigureServices 方法
- 初始化 Http Server
Server 是一个HTTP服务器,负责HTTP的监听,接收一组 FeatureCollection 类型的原始请求,并将其包装成 HttpContext 以供我们的应用程序完成响应的处理。 - 创建 IApplicationBuilder
IApplicationBuilder 用于构建应用程序的请求管道,也就是生成 RequestDelegate - 配置 IApplicationBuilder
- 启动 Server,监听请求并响应
- 启动 HostedService
那这边是简单的讲了下WebHost,具体的内容可以看下文章末尾的Core的链接。
- 初始化,构建 RequestDelegate
-
- Middleware(中间件),管道模型的构成
- IApplicationBuilder
首先,IApplicationBuilder 是用来构建请求管道的,而所谓请求管道,本质上就是对 HttpContext 的一系列操作,即通过对 Request 的处理,来生成 Reponse。因此,在 ASP.NET Core 中定义了一个 RequestDelegate 委托,来表示请求管道中的一个步骤,它有如下定义:public delegate Task RequestDelegate(HttpContext context);
而对请求管道的注册是通过Func<RequestDelegate, RequestDelegate>类型的委托(也就是中间件)来实现的。它接收一个 RequestDelegate 类型的参数,并返回一个 RequestDelegate 类型,也就是说前一个中间件的输出会成为下一个中间件的输入,这样把他们串联起来,形成了一个完整的管道。
它有一个内部的 Func<RequestDelegate, RequestDelegate> 类型的集合(用来保存我们注册的中间件)和三个核心方法:
1. UseUse是我们非常熟悉的注册中间件的方法,其实现非常简单,就是将注册的中间件保存到其内部属性 _components 中。
2. Build
在Hosting的启动中,便是通过该 Build 方法创建一个 RequestDelegate 类型的委托,Http Server 通过该委托来完成整个请求的响应
3. Run
在我们注册的中间件中,是通过 Next 委托 来串连起来的,如果在某一个中间件中没有调用 Next 委托,则该中间件将做为管道的终点,因此,我们在最后一个中间件不应该再调用 Next 委托,而 Run 扩展方法,通常用来注册最后一个中间件
4. NewNew方法根据自身来“克隆”了一个新的 ApplicationBuilder 对象,而新的 ApplicationBuilder 可以访问到创建它的对象的Properties属性,但是对自身 Properties 属性的修改,却不到影响到它的创建者,这是通过 CopyOnWriteDictionary 来实现的
所以 Core的管道其实就是Middleware来做的,每个都有前置,后置的处理步骤,中间可以调用其他Middleware。也可以并行走向。

- IApplicationBuilder
ASP.NET Core 请求管道的构建过程,以及一些帮助我们更加方便的来配置请求管道的扩展方法。在 ASP.NET Core 中,至少要有一个中间件来响应请求,而我们的应用程序实际上只是中间件的集合,MVC 也只是其中的一个中间件而已。简单来说,中间件就是一个处理http请求和响应的组件,多个中间件构成了请求处理管道,每个中间件都可以选择处理结束,还是继续传递给管道中的下一个中间件,以此串联形成请求管道。通常,我们注册的每个中间件,每次请求和响应均会被调用,但也可以使用 Map , MapWhen ,UseWhen 等扩展方法对中间件进行过滤。
3.6总结
那我们分析了以往微软的3种形式底下的Web,分别是WebForm,MVC,Core,其中WebForm与MVC雷士,依托于IIS,不同的就是ISAPI的不同。前者的ISAPI以插件形式存在IIS,而后者将其整合成一套。Core跨平台,IIS只是他的一个反向代理服务器,HTTP请求带Core的程序,运行Core。
但是我觉得他们内容是基本不变的,HTTP请求,进来在彼此的AppDomain中创建HttpContext,然后就开始走Pipeline走流程,WebFrom走Page的IHTTPHandler与其相关的IModule,而MVC是Global.asax继承HttpApplication,HttpApplication又继承IHTTPHandler,接下来WebFrom与MVC就各自走各自的Pipeline。Core却不是这样,它的Pipeline采用了Middleware(中间件)的形式。俄罗斯套娃,一步一步走Pipeline。最终都是响应客户端,一个HTTP请求,从开始到结束。

