前后端分手大师——MVVM 模式 从输入cnblogs.com到博客园首页完全展示发生了什么
前后端分手大师——MVVM 模式
简而言之
之前对 MVVM 模式一直只是模模糊糊的认识,正所谓没有实践就没有发言权,通过这两年对 Vue 框架的深入学习和项目实践,终于可以装B了有了拨开云雾见月明的感觉。
Model–View–ViewModel(MVVM) 是一个软件架构设计模式,由微软 WPF 和 Silverlight 的架构师 Ken Cooper 和 Ted Peters 开发,是一种简化用户界面的事件驱动编程方式。由 John Gossman(同样也是 WPF 和 Silverlight 的架构师)于2005年在他的博客上发表。
MVVM 源自于经典的 Model–View–Controller(MVC)模式(期间还演化出了 Model-View-Presenter(MVP)模式,可忽略不计)。MVVM 的出现促进了 GUI 前端开发与后端业务逻辑的分离,极大地提高了前端开发效率。MVVM 的核心是 ViewModel 层,它就像是一个中转站(value converter),负责转换 Model 中的数据对象来让数据变得更容易管理和使用,该层向上与视图层进行双向数据绑定,向下与 Model 层通过接口请求进行数据交互,起呈上启下作用。如下图所示:
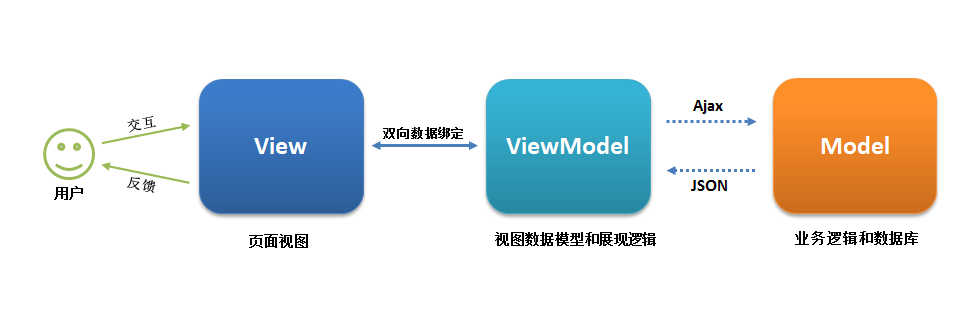
MVVM模式
MVVM 已经相当成熟了,主要运用但不仅仅在网络应用程序开发中。KnockoutJS 是最早实现 MVVM 模式的前端框架之一,当下流行的 MVVM 框架有 Vue,Angular 等。
组成部分
简单画了一张图来说明 MVVM 的各个组成部分:
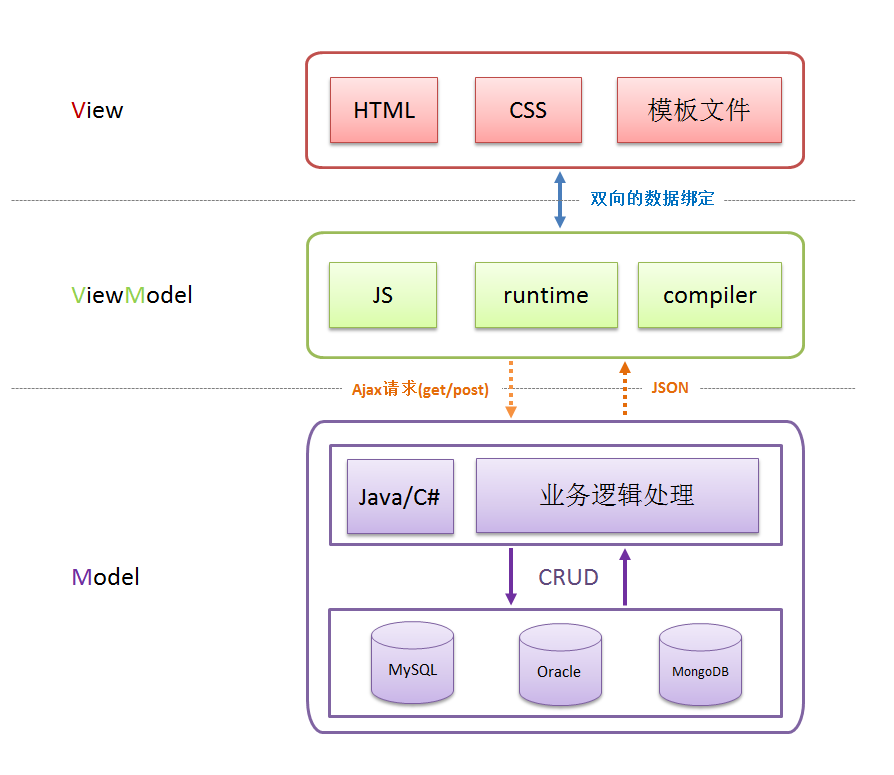
MVVM分层示意图
分层设计一直是软件架构的主流设计思想之一,MVVM 也不例外。
# View 层
View 是视图层,也就是用户界面。前端主要由 HTML 和 CSS 来构建,为了更方便地展现 ViewModel 或者 Model 层的数据,已经产生了各种各样的前后端模板语言,比如 FreeMarker、Marko、Pug、Jinja2等等,各大 MVVM 框架如 KnockoutJS,Vue,Angular 等也都有自己用来构建用户界面的内置模板语言。
# Model 层
Model 是指数据模型,泛指后端进行的各种业务逻辑处理和数据操控,主要围绕数据库系统展开。后端的处理通常会非常复杂:

前后端对比
后端:我们这里的业务逻辑和数据处理会非常复杂!
前端:关我屁事!
后端业务处理再复杂跟我们前端也没有半毛钱关系,只要后端保证对外接口足够简单就行了,我请求api,你把数据返出来,咱俩就这点关系,其他都扯淡。
# ViewModel 层
ViewModel 是由前端开发人员组织生成和维护的视图数据层。在这一层,前端开发者对从后端获取的 Model 数据进行转换处理,做二次封装,以生成符合 View 层使用预期的视图数据模型。需要注意的是 ViewModel 所封装出来的数据模型包括视图的状态和行为两部分,而 Model 层的数据模型是只包含状态的,比如页面的这一块展示什么,那一块展示什么这些都属于视图状态(展示),而页面加载进来时发生什么,点击这一块发生什么,这一块滚动时发生什么这些都属于视图行为(交互),视图状态和行为都封装在了 ViewModel 里。这样的封装使得 ViewModel 可以完整地去描述 View 层。由于实现了双向绑定,ViewModel 的内容会实时展现在 View 层,这是激动人心的,因为前端开发者再也不必低效又麻烦地通过操纵 DOM 去更新视图,MVVM 框架已经把最脏最累的一块做好了,我们开发者只需要处理和维护 ViewModel,更新数据视图就会自动得到相应更新,真正实现数据驱动开发。看到了吧,View 层展现的不是 Model 层的数据,而是 ViewModel 的数据,由 ViewModel 负责与 Model 层交互,这就完全解耦了 View 层和 Model 层,这个解耦是至关重要的,它是前后端分离方案实施的重要一环。
没有什么是一个栗子不能解决的
扯了这么多,并没有什么卵用。千言万语不如一个栗子来的干脆,下面用一个 Vue 实例来说明 MVVM 的具体表现。
Vue 的 View 模板:
<div id="app">
<p>{{message}}</p>
<button v-on:click="showMessage()">Click me</button>
</div>
Vue 的 ViewModel 层(下面是伪代码):
var app = new Vue({
el: '#app',
data: { // 用于描述视图状态(有基于 Model 层数据定义的,也有纯前端定义)
message: 'Hello Vue!', // 纯前端定义
server: {}, // 存放基于 Model 层数据的二次封装数据
},
methods: { // 用于描述视图行为(完全前端定义)
showMessage(){
let vm = this;
alert(vm.message);
}
},
created(){
let vm = this;
// Ajax 获取 Model 层的数据
ajax({
url: '/your/server/data/api',
success(res){
// TODO 对获取到的 Model 数据进行转换处理,做二次封装
vm.server = res;
}
});
}
})
服务端的 Model 层(省略业务逻辑处理,只描述对外接口):
{
"url": "/your/server/data/api",
"res": {
"success": true,
"name": "IoveC",
"domain": "www.cnblogs.com"
}
}
这就是完整的 MVVM 编程模式。
代码执行之后双向绑定的效果如下:

Vue实现的响应的数据绑定
嘿嘿,前后端可以成功分手了,以后再也不用关心后端个锤子开发进度\暴怒脸,复杂实现,blabla...,尽情享用前端如丝般顺滑的开发快感吧:)
从输入cnblogs.com到博客园首页完全展示发生了什么
之前面试时候经常被问及这个问题,支支吾吾回答没有底气,仔细研究了一下,发现里面学问还真不少。
从输入 cnblogs.com 到博客园首页完全展现这个过程可以大致分为 网络通信 和 页面渲染 两个步骤。
网络通信走的五层因特网协议栈(OSI标准是七层模型,但实际实现通常是五层)。画了一张图:

五层因特网协议栈
DNS 解析成 IP 地址
DNS属于应用层协议。客户端会先检查本地是否有对应的 ip 地址,如果有就返回,否则就会请求上级 DNS 服务器,知道找到或到根节点。这一过程可能会非常耗时,使用 dns-prefetch 可使浏览器在空闲时提前将这些域名转化为 ip 地址,真正请求资源时就避免了这个过程的时间。例如京东首页的处理:

京东首页dns-prefetch处理
发送 http 请求
HTTP也是应用层协议。HTTP(HyperText Transport Protocol)定义了一个基于请求/响应模式的、无状态的、应用层的协议,用于从万维网服务器传输超文本到本地浏览器。绝大多数的Web开发,都是构建在HTTP协议之上的Web应用。客户端组织并发送 http 请求报文,包含 method、url、host、cookie 等信息,下面是访问博客园首页时 http 请求报文的样子:
GET https://www.cnblogs.com/ HTTP/1.1
Host: www.cnblogs.com
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36
Upgrade-Insecure-Requests: 1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: __gads=ID=b62b1e22b7de2e02:T=1493954370:S=ALNI_MYRebVRavER2PJmwdeFwpl33ACNoQ;
If-Modified-Since: Mon, 27 Nov 2017 12:21:04 GMT
请求头里的每个字段都有各自的作用,具体含义可查阅 http 协议相关文章。
TCP 传输报文
TCP 将 http 长报文划分为短报文,通过“三次握手”与服务器建立连接,进行可靠传输。“三次握手”建立连接的过程和打电话极像:
客户端:喂,我要和 Server 通话
服务端:你好,我是 Server,你是 Client 吗
客户端:没错,我是 Client
连接建立成功,接下来就可以正式传送数据了。
数据传完之后断开tcp连接还要通过“四次挥手”,大概意思如下:
客户端:Server 小宝贝,我话说完了,你挂电话吧
服务端:我不挂,我不挂,你先挂,你不挂我也不挂
---------------- Client 一阵无语 --------------
服务端:你挂了吗
客户端:行,那我先挂了
至此完成了一次完整的资源请求响应。
需要注意的是,浏览器对同一域名下并发的tcp连接数是有限制的,2个到10个不等。为了解决这个资源加载瓶颈,有几种流行的优化方案:
# 资源打包,合并请求
比如页面样式全部打包在一个 css 文件内,页面逻辑全部打包在一个 js 文件内,图片拼合成雪碧图,这样可有效减少页面的资源请求数量。webpack 是时下最流行的模块打包工具之一,它可以将页面内所有资源(包括js,css,图片,字体等等)都打包进一个 js 文件,不明觉厉。
# 域名拆分,资源分散存储
当浏览器向服务器请求一个静态资源时,会先发送该域名下的 cookies,服务器对于这些 cookie 根本不会做任何处理,因此它们只是在毫无意义的消耗带宽,所以应该确保对于静态内容的请求是无 cookie 的请求(也就是所谓的 cookie-free)。将站点的 js、css、图片等静态文件放在一个专门的域名下访问,由于该域名与主站域名不同,所以浏览器就不会把主域名下的 cookies 传给该域,从而减少网络开销,特别是细碎静态文件特别多的情况下效果显著。
另一方面,由于浏览器是基于域名的并发连接数限制,而不是页面。因此将资源部署在不同的域名下可以使页面的总并发连接数得到线性提升。
# Connection: keep-alive,复用已建立的连接
在 http 早期,每个 http 请求都要打开一个 tcp 连接,请求完就关闭这个连接,导致每个请求都要来一遍“三次握手”和“四次挥手”,从而磨磨唧唧多出来大量无谓的等待时间。就好比出去吃饭,等饭等半个小时,端上来十分钟吃完了,结账排队又等了半个小时,要是刚进来就吃现成的吃完就跑那多爽啊。keep-alive 干的就是这件事,当第一个请求数据传输完毕之后,服务器说“客户端你不要关闭这个连接,直接换下个请求,我不想再握你的破手了”。这样下个请求就直接传输数据而不用先走“三次握手”的流程了。这好比你又去吃饭,吃你最喜欢的红烧肉,饭店在今天第一个客人点红烧肉的时候就炒了一大锅红烧肉,你点餐的时候直接吃现成的就行了,吃完直接跑,哈哈美滋滋。
# 控制缓存
将静态资源强制缓存在客户端,通过添加文件指纹等方式使客户端只请求发生了变更的资源,可有效降低静态资源请求数量。具体可参看前端静态资源缓存控制策略。
# 延迟加载,懒加载,按需加载
很多页面浏览量虽然很大,但其实很大比例用户扫完第一屏就直接跳走了,第一屏以下的内容用户根本就不感兴趣。 对于超大流量的网站,这个问题尤其重要。这时可根据用户的行为进行按需加载,用户用到了就去加载,用不到就不去加载。
以上都是从减少建立tcp连接数量的角度去优化页面性能,之后会分享更多前端性能优化方面的实用方法。
IP 寻址
Internet Protocol 是定义网络之间彼此互联规则的协议,主要解决逻辑寻址和网络通用数据传输格式两个问题。
所有连接到因特网上的设备都会被分配一个唯一的 IP 地址,就像网购时填写的收货地址一样。由于一个网络设备的 IP 地址可以更换,但是 MAC 硬件地址(就像身份证号)一般是固定不变的,所以首先使用 ARP 协议来找到目标主机的 MAC 硬件地址。当通信的双方不在同一个局域网时,需要多次中转(路由器)才能找到最终的目标,在中转的过程中还需要通过下一个中转站的 MAC 地址来搜索下一个中转目标。
传输层传来的 TCP 报文会在这一层被 IP 封装成网络通用传输格式——IP数据包,IP 数据包是真正在网络间进行传输的数据基本单元。
通过逻辑寻址定位到前面应用层 DNS 解析出来的 IP 地址的主机网络位置,然后把数据以 IP 数据包的格式发送到那去。
封装成帧
数据链路层负责将 IP 数据包封装成适合在物理网络上传输的帧格式并传输。设计数据链路层的主要目的就是在原始的、有差错的物理传输线路的基础上,采取差错检测、差错控制与流量控制等方法,将有差错的物理线路改进成逻辑上无差错的数据链路,向网络层提供高质量的服务。当采用复用技术时,一条物理链路上可以有多条数据链路。
物理传输
上面这么多层其实都是在为不同的目的对要传输的数据进行封装处理,而物理层则是通过各种传输介质(双绞线,电磁波,光纤等)以信号的形式将上面各层封装好的数据物理传送过去。
至此一个 http 请求漂洋过海终于到达了服务器,接下来就是从物理层到应用层向上传递,将封装的数据一层层剥开,服务器在应用层拿到最原始的请求信息后快速处理完,然后就开始向客户端发送响应信息。这次是以服务器为起点,客户端为终点再走一遍五层协议栈。
服务器的响应消息跋山涉水终于到达了浏览器,接下来就是页面渲染(更具体可参看浏览器内部工作原理)。
页面的渲染工作主要由浏览器的渲染引擎来完成(这里以Chrome为例)。
页面渲染主流程
下面是渲染引擎在取得内容后的基本流程:
解析html构建dom树 -> 解析css构建render树 -> 布局render树 -> 绘制render树
渲染引擎首先开始解析html,并将标签转化为dom树中的dom节点。接着,它解析外部css文件及style标签中的样式信息,这些样式信息以及html标签中的可见性指令将被用来构建另一棵树——render树。render树构建好了之后,将会执行布局过程,该过程将确定render树每个节点在屏幕上的确切坐标。最后是绘制render树,即遍历render树的每个节点并将它们绘制到屏幕上。
偷了一张图片(Chrome和Safari所用内核webkit页面渲染主流程):

webkit页面渲染主流程
为了更好的用户体验,渲染引擎将会尽可能早地将内容绘制在屏幕上,而不会等到所有的html都解析完成后再去构建、布局和绘制render树,它是解析完一部分内容就绘制一部分内容,同时可能还在通过网络下载其余内容(图片,脚本,样式表等)。比如说,浏览器在代码中发现一个 img 标签引用了一张图片,于是就向服务器发出图片请求,此时浏览器不会等到图片下载完,而是会继续解析渲染后面的代码,等到服务器返回图片文件,由于图片占用了一定面积,影响了后面段落的布局,浏览器就会回过头来重新渲染这部分代码。
dom树和render树的关系
render树节点和dom树节点相对应,但这种对应关系不是一对一的,不可见的dom元素不会被插入render树,例如head元素、script元素等。另外,display属性为none的元素也不会在渲染树中出现(visibility属性为hidden的元素将出现在渲染树中,这是因为visibility属性为hidden的元素虽然不可见但保留了元素的占位)。
又偷了一张图:

render树与dom树
布局render树(layout)
当渲染对象被创建并添加到render树后,它们并没有位置和大小,计算这些值的过程称为layout(布局)。
布局的坐标系统相对于根渲染对象(它对应文档的html标签,可用 document.documentElement 拿到),使用top和left坐标。根渲染对象的位置是 (0,0),它的大小是viewport即浏览器窗口的可见部分。布局是一个递归的过程,由根渲染对象开始,然后递归地通过一些或所有的层级节点,为每个需要几何信息的渲染对象进行计算。
为了不因为每个小变化都全部重新布局,浏览器使用一个 dirty bit(页面重写标志位)系统,一个渲染对象发生了变化或是被添加了,就标记它及它的children为dirty——需要layout。
当layout在整棵渲染树触发时,称为全局layout,这可能在下面这些情况下发生:
- 一个全局的样式改变影响所有的渲染对象,比如字号的改变。
- 窗口resize。
layout也可以是增量的,这样只有标志为dirty的渲染对象会重新布局(也将导致一些额外的布局)。增量layout会在渲染对象dirty时异步触发,例如,当网络接收到新的内容并添加到dom树后,新的渲染对象会添加到render树中。
绘制(paint)
绘制阶段,遍历render树并调用渲染对象的paint方法将它们的内容显示在屏幕上。和布局一样,绘制也可以是全局的(绘制完整的树)或增量的。在增量的绘制过程中,一些渲染对象以不影响整棵树的方式改变,改变的渲染对象使其在屏幕上的矩形区域失效(invalidate),这将导致操作系统将其看作dirty区域,并产生一个paint事件,操作系统很巧妙的处理这个过程,并将多个区域合并为一个。
浏览器总是试着以最小的动作响应一个变化,所以一个元素颜色的变化将只导致该元素的重绘,元素位置的变化将导致元素的布局和重绘,添加一个dom节点,也会导致这个元素的布局和重绘。一些主要的变化,比如增加html元素的字号,将会导致缓存失效,从而引起整个render树的布局和重绘。
等到绘制完毕,页面就完全地展现在我们面前了。
看似再简单不过的操作,背后支撑的技术链已经复杂到不可想象。上面只是粗浅的轮廓,其中的每一步深挖进去都是一门大学问。不过咱们前端了解一下就行了,没必要较这个劲,不然就舍本逐末了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号