通俗易懂,C#如何安全、高效地玩转任何种类的内存之Span的脾气秉性(二)。 异步委托 微信小程序支付证书及SSL证书使用 SqlServer无备份下误删数据恢复 把list集合的内容写入到Xml中,通过XmlDocument方式写入Xml文件中 通过XDocument方式把List写入Xml文件
通俗易懂,C#如何安全、高效地玩转任何种类的内存之Span的脾气秉性(二)。
前言
读完上篇《通俗易懂,C#如何安全、高效地玩转任何种类的内存之Span的本质(一)。》,相信大家对span的本质应该非常清楚了。含着金钥匙出生的它,从小就被寄予厚望要成为.NET下编写高性能应用程序的重要积木,而且很多老前辈为了接纳它,都纷纷做出了改变,比如String、Int、Array。现在,它长大了,已经成为.NET下发挥关键作用的新值类型和一流成员。
那我们又该如何接纳它呢?
一句话,熟悉它的脾气秉性,让好钢用到刀刃上。
脾气秉性 - 特点
Slow vs Fast Span
上篇博客介绍了span的本质,主要涉及到三个字段,如下:
public struct Span<T> {
internal IntPtr _byteOffset; // 偏移量
internal object _reference;// 引用,可以看作当前对象的索引
internal int _length;// 长度
}当我们访问span表示的整体或部分内存时,内部的索引器通过计算(ref reference + byteOffset) + index * sizeOf(T)来正确直接地返回实际储存位置的引用,而不是通过复制内存来返回相对位置的副本,从而达到高性能,但是,现在我要告诉你,这种span被叫做slow span,为什么呢?因为C#7.2的新特性ref T支持在签名中直接返回引用(相当于直接整合了这个过程),这样就无需通过计算来确定指针开头及其起始偏移,从而真正拥有和访问数组一样高的效率,如下:
public struct Span<T> {
internal ref T _reference;// 引用,本身已整合_byteOffset、_reference两者。
internal int _length;// 长度
}这种只包含两个字段的span就叫Fast span。
在所有的.NET平台,Slow Span都是可得到的,但是目前只有.NET Core 2.X原生支持Fast span。
为了让大家更直观地了解这两种Span,下面来做两组基准测试
-
不同运行时下Span进行10万次Get、Set的基准测试
![]()
上图非常清楚了吧,从Mean(均值)指标可以看出差异还是比较大的(约60%),net framework时代追求生产力,而core时代追求高性能,所以还是早转core吧,并且新版本core还会进一步优化span,差距将会越来越大。
-
Span vs Array的基准测试
不同运行时下,对Span和Array进行10万次Get、Set操作
![]()
从上图Mean(均值)指标可以得出:
- slow span,即运行时原生不支持,在性能上,它的Get、Set操作和数组差异50%左右。
- fast span,即运行时原生支持,在性能上,它的Get、Set操作和数组相当。


看了上面测试,可能有的同学就会问了用Array就行了,如果总是操作整个数组,这是合适的,但如果想操作数组的一部分数据呢?按照以前的做法每次复制一份相对位置的副本给调用方,这就非常消耗性能的,那么如何支持对完整或部分数组的操作保持同样高的性能呢?答案就是span,没有之一。span不仅能用于访问数组和分离数组子集,还可引用来自内存任意区域的数据,比如本机代码、栈内存、托管内存。
Stack-Only
分配一块栈内存是非常快速的,也无需手工释放,它会随着当前作用域而释放,比如方法执行结束时,就自动释放了,所以需要快取快用快放。Span虽然支持所有类型的内存,但决定安全、高效地操作各种内存的下限自然取决于最严苛的内存类型,即栈内存,好比木桶能装多少水,取决于最短的那块木板。此外,上一篇博客的动画非常清晰地演示了span的本质,每次都是通过整合内部指针为新的引用返回,而.NET运行时跟踪这些内部指针的成本非常高昂,所以将span约束为仅存在于栈上,从而隐式地限制了可以存在的内部指针数量。
备注:栈内存的容量非常小, ARM、x86 和 x64 计算机,默认堆栈大小为 1 MB。CLR和编译器会自动检测Stack-Only约束。
所以span必须是值类型,它不能被储存到堆上。
违背Stack-Only的应用场景
-
Span不能作为类的字段。
class Impossible { Span<byte> field; } -
Span不能实现任何接口
先来看一段C#(伪代码):
struct StructType<T> : IEnumerable<T> { } class SpanStructTypeSample { static void Test() { var value = new StructType<int>(); Parse(value); } static void Parse(IEnumerable<int> collection) { } }使用ILDasm查看生成的IL代码:
.method public hidebysig static void Test() cil managed // 调用Test方法 { // Code size 22 (0x16) .maxstack 1 .locals init (valuetype SpanTest.StructType`1<int32> V_0) IL_0000: nop IL_0001: ldloca.s V_0 IL_0003: initobj valuetype SpanTest.StructType`1<int32> IL_0009: ldloc.0 IL_000a: box valuetype SpanTest.StructType`1<int32> // 装箱,意味着被储存到托管堆上。 IL_000f: call void SpanTest.SpanStructTypeSample::Parse(class [System.Runtime]System.Collections.Generic.IEnumerable`1<int32>) IL_0014: nop IL_0015: ret } // end of method SpanStructTypeSample::Test上面的代码很明确,首先让自定义的值类型实现接口IEnumerable,然后作为参数传递给Parse,最后分析IL代码发现参数被装箱了,意味着将被储存到托管堆上,如果将来C#能专门定义只用于struct的接口,那么就能扩展Stack-Only结构到此应用场景了,一起期待吧。
-
Span不能作为异步方法的参数
首先
async和await是非常棒的语法糖,不仅仅大大地简化了编写异步代码的难度,而且还带来了代码的优雅度。同样,先来看一段C#代码:
public async Task TestAsync(Span<byte> data) { }这样的用法也是禁止的,编译时就会报错
Parameter or local type Span<byte> cannot be declared in async method.。因为本质上,async&await的内部是通过AsyncMethodBuilder来创建一个异步的状态机,某一时刻可能会将方法参数储存到托管堆上。 -
Span不能作为泛型类型的参数
同样,先来看一段C#代码:
Func<Span<byte>> valueProvider = () => new Span<byte>(new byte[256]); object value = valueProvider.Invoke(); // 装箱这样的用法也是禁止的,编译时会报错
The type Span<byte>may not be used as a type argument.。同理,span<byte>可以表示内存任意区域,而实际使用时肯定需要类型化对象,无法避免装箱。那么微软为什么不引入一种新的泛型约束:stackonly,而是决定禁止span作为泛型参数,因为这需要编译器检查所有的代码,可能还需要理解代码逻辑(因为有的类型需要运行时才能确定),不然是无法保证stackonly约束的,呵呵,目前看来是不现实的,不知人工智能能否解决这个问题。
Stack Tearing
阐述这个特点前,先简单说说计算机的字大小。
-
计算机的字大小
表示计算机中CPU的字长,32位CPU字长为32位,即4字节;64位CPU字长为64位,即8字节。CPU的字长决定了每次能够原子更新的连续内存块的大小。
栈撕裂其实是多线程下的数据同步问题,当结构数据大于当前处理器的字大小时,都会面临这个问题。如前所述,span内部包含多个字段,这就意味着,一些处理器可能无法保证原子更新span的_reference和_length 字段,也就是说,多线程下_reference和_length可能来自于两个不同的span。
internal class Buffer
{
Span<byte> _memory = new byte[1024];
public void Resize(int newSize)
{
_memory = new byte[newSize]; // 因为这里无法保证原子更新
}
public byte this[int index] => _memory[index]; // 所以这里可能的部分更新
}其实有两种办法可以解决这个问题:
- 直接处理 - 加锁,即强制同步访问。
- 间接处理 - 私有化字段,即不给外面观察到部分更新的机会。
如果这样,就无法保证像数组一样的高性能,因此不能给字段加锁,也不能限制访问(没意义),另外对Span的访问和写入都是直接操作的内存,如果_reference和_length出现不同步的情况,还会导致内存安全问题。
这也是为什么span只能存在于栈上,即指针、数据、长度全都存于栈上,而不是引用存在堆,数据存在栈,因为span<T>不需要暂留,必须快取快用快放,否则就不要使用span。
备注:对于需要暂留到堆上的场景,它的解决方案是
Memory<T>,大家可以继续关注。
.NET库的集成
为了支持轻松高效地处理 {ReadOnly}Span ,微软向.NET添加了数百个新成员和类型。目前大多是基于数组、字符串和基元类型的方法的重载 ,除此之外,还包括一些专注于特定处理方面的全新类型,比如:System.IO.Pipelines。
下面是一些比较常用的扩展:
-
基元类型(伪代码)
short.Parse(ReadOnlySpan<char> s); int.Parse(ReadOnlySpan<char> s); long.Parse(ReadOnlySpan<char> s); DateTime.Parse(ReadOnlySpan<char> s); TimeSpan.Parse(ReadOnlySpan<char> input); Guid.Parse(ReadOnlySpan<char> input); -
字符串
public static ReadOnlySpan<char> AsSpan(this string text, int start, int length); public static ReadOnlySpan<char> AsSpan(this string text, int start); public static ReadOnlySpan<char> AsSpan(this string text); public static String Create<TState>(int length, TState state, SpanAction<char, TState> action); -
数组
public static Span<T> AsSpan<T>(this T[] array, int start); public static Span<T> AsSpan<T>(this T[] array); public static Span<T> AsSpan<T>(this ArraySegment<T> segment, int start, int length); public static Span<T> AsSpan<T>(this ArraySegment<T> segment, int start); public static Span<T> AsSpan<T>(this T[] array, int start, int length); -
Guid
public static bool TryParse(ReadOnlySpan<char> input, out Guid result); public bool TryFormat(Span<char> destination, out int charsWritten, ReadOnlySpan<char> format = default (ReadOnlySpan<char>));
最后使用上面的API演示一个官网的例子,解析字符串"123,456"中的数字:
以前的写法:
var input = "123,456";
var commaPos = input.IndexOf(',');
var first = int.Parse(input.Substring(0, commaPos));// yes-Allocating, yes-Coping
var second = int.Parse(input.Substring(commaPos + 1));// yes-Allocating, yes-Coping现在的写法:
var input = "123,456";
var inputSpan = input.AsSpan();
var commaPos = input.IndexOf(',');
var first = int.Parse(inputSpan.Slice(0, commaPos));// no-Allocating, no-Coping
var second = int.Parse(inputSpan.Slice(commaPos + 1));// no-Allocating, no-Coping当然还是有许多这样的方法,比如System.Random、System.Net.Socket、Utf8Formatter、Utf8Parser等,明白了它的脾气秉性,对于具体的应用场景大家可以先自行查阅资料,相信认真读完上篇、本篇的同学已经具备用好这把尖刀的能力了。
总结
综上所诉,通过限制Span只能驻留到栈上,完美解决了以下的问题:
- 更高效地内存访问,快取快用快放的天然保障。
- 更高效地GC跟踪。
- 并发内存安全。
备注:正是由于Stack-Only这个特点,在底层数据访问、转换以及同步处理方面,Span性能非常出色。
此外,本篇还在上篇的基础上,详细讲解span的脾气秉性,以及每种特点下的非法应用场景,一切都是为了大家能够在.NET 程序中高效安全地访问内存,希望大家能有所收获。下一篇可能会讲span的加强,也可能会讲它在数据转换以及同步处理方面的应用,比如:Data Pipelines、Discontinuous Buffers、Buffer Pooling等,也可能会讲Memory<T>,感兴趣请继续关注。
简介
委托(Delegate):就是类似于C/C++中的函数指针,由于C#中没有指针,使该语言存在着对某种方法的引用,该引用在运行时改变。被说成是:“委托可以把方法当作参数在另一个方法中传递和调用”,“委托是方法的快捷方式”等等,我的简单理解就是创建两个相同的函数,想用使用A函数,可以借助委托函数B进行调用。关键字为delegate。
想要深入理解委托,可以学习一下这篇文章深入理解委托
在winForm开发过程中经常用到线程,又是会遇到在多线程中访问线程外的空间。,比如:设置textbox的Text属性等等。如果直接设置程序必 定会报出:从不是创建控件的线程访问它,这个异常。
通常我们可以采用两种方法来解决。
一是通过设置control的属性。
二是通过delegate,而通 过delegate也有两种方式,一种是常用的方式,另一种就是匿名方式。
委托
.NET中对invoke和begininvoke的官方定义:
control.invoke(参数delegate)方法:在拥有此控件的基础窗口句柄的线程上执行指定的委托。
control.begininvoke(参数delegate)方法:在创建控件的基础句柄所在线程上异步执行指定委托。
从而得知:invoke表是同步、begininvoke表示异步
下面举例一个委托使用的例子:
delegate void SafeSetText(string strMsg);
private void SetText(string strMsg)
{
if(textbox1.InvokeRequired)
{
SafeSetText objSet=new SafeSetText(SetText);
textbox1.Invoke(objSet,new object[]{strMsg});
}
else
{
textbox1.Text=strMsg;
}
}异步委托
.NET Framework 允许您异步调用任何方法。 为此,应定义与您要调用的方法具有相同签名的委托;公共语言运行时会自动使用适当的签名为该委托定义 BeginInvoke 和 EndInvoke 方法。
下面是一个异步委托的例子:
static void Main()
{
//synchronous method call
//TakesAWhile(1 , 3000);
//asynchronous by using a delegate
TakesAWhileDelegate d1 = TakesAWhile;
IAsyncResult ar = d1.BeginInvoke(1, 3000, null ,null);
while(!ar.IsCompleted)
{
//doing something else in the main thread
Console.Write(".");
Thread.Sleep(50);
}
int result = d1.EndInvoke(ar);
Console.WriteLine("Result:{0}",result);
}TakesAWhile为需要委托函数,
TakesAWhileDelegate 为委托函数,
BeginInvoke 方法启动异步调用。
BeginInvoke方法返回一个 IAsyncResult,用来监视异步调用的进度,
EndInvoke 方法检索异步调用的结果。
IAsyncResult 类型公开以下成员:
AsyncState :获取用户定义的对象,它限定或包含关于异步操作的信息
AsyncWaitHandle :获取用于等待异步操作完成的 WaitHandle
CompletedSynchronously :获取一个值,该值指示异步操作是否同步完成
IsCompleted :获取一个值,该值指示异步操作是否已完成
总结
该文章对委托和异步委托做了一个介绍与区别说明,不是很深入,后期再补。
微信小程序支付证书及SSL证书使用
小程序使用微信支付包括:电脑管理控制台导入证书->修改代码为搜索证书->授权IIS使用证书->设置TSL加密级别为1.2
描述:
1、通常调用微信生成订单接口的时候,使用的证书都是直接路径指向就行了,但是这种方法在IIS是不适用的
2、IIS网站绑定SSL证书之后,证书加密级别默认为1.0,而小程序要求1.2以上
下面介绍具体步骤详情:
一、导入证书
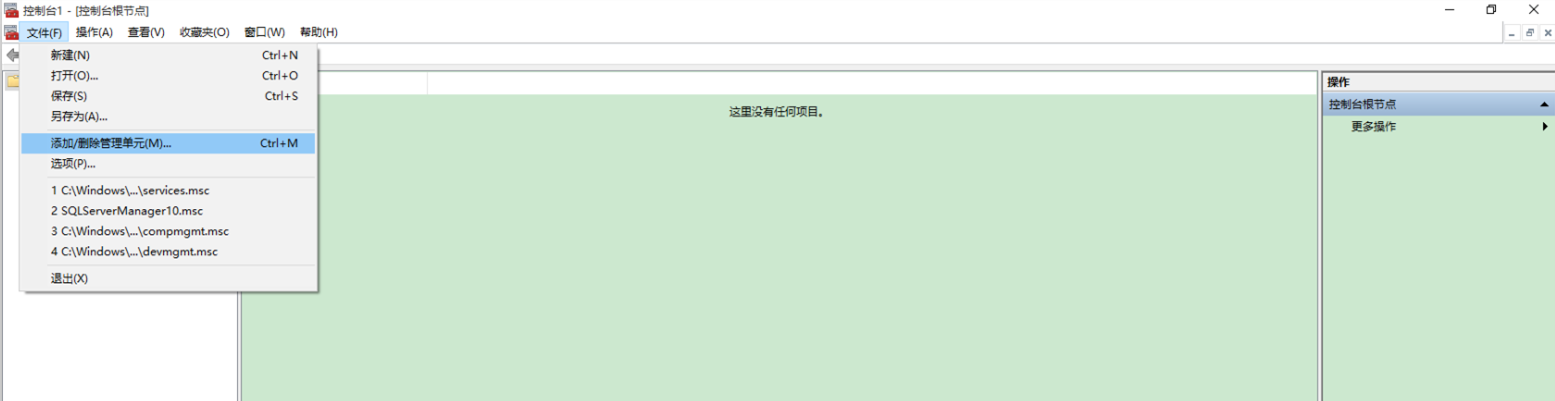
1、运行->mmc,打开管理控制台,文件->添加/删除管理单元
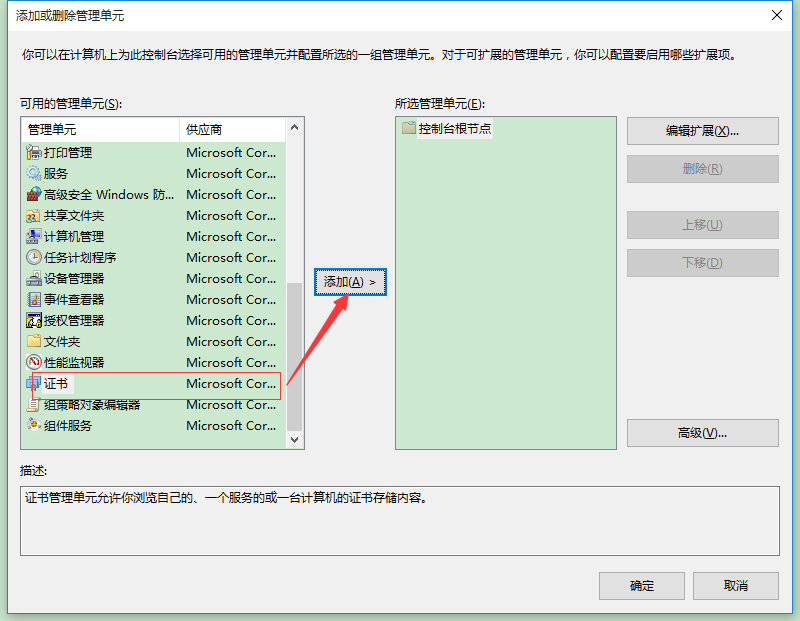
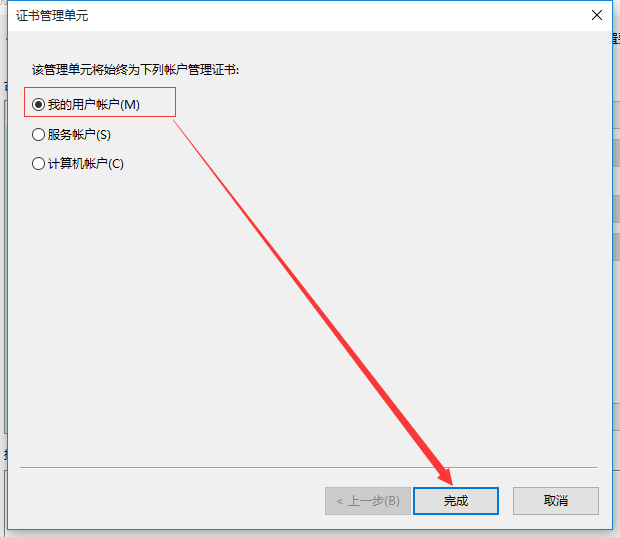
2、在可用的管理单元中选择证书,然后点击添加
3、回到控制台,展开证书-当前用户->个人->证书,然后导入证书
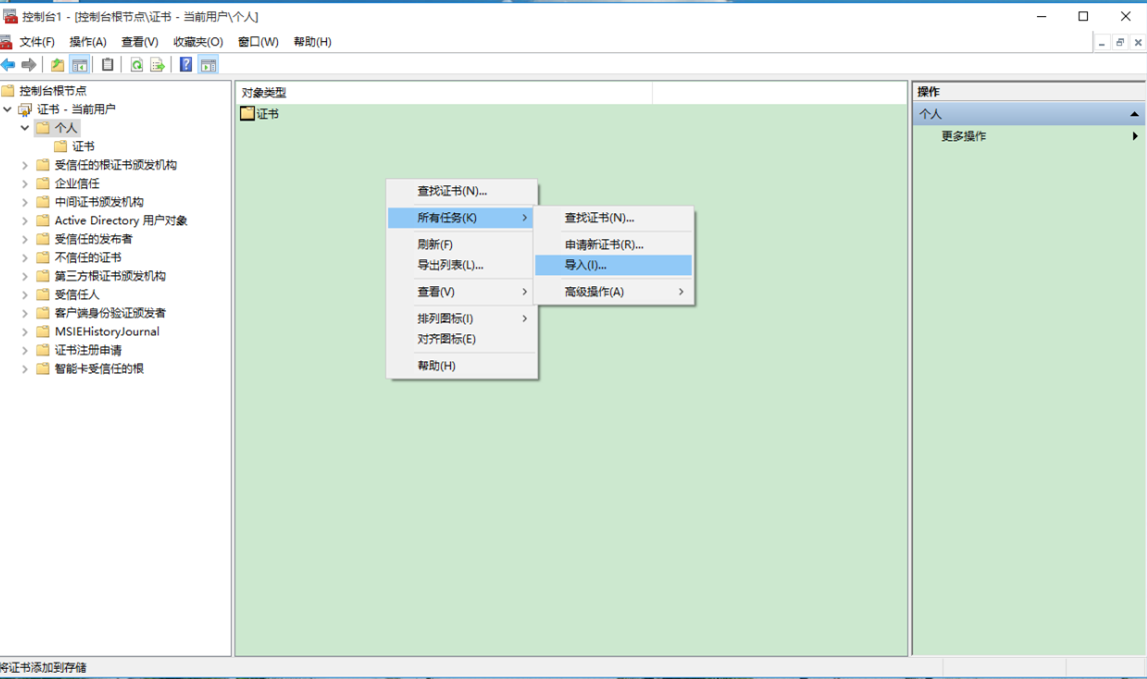
按照步骤导入证书,微信支付证书初始密码为商户号
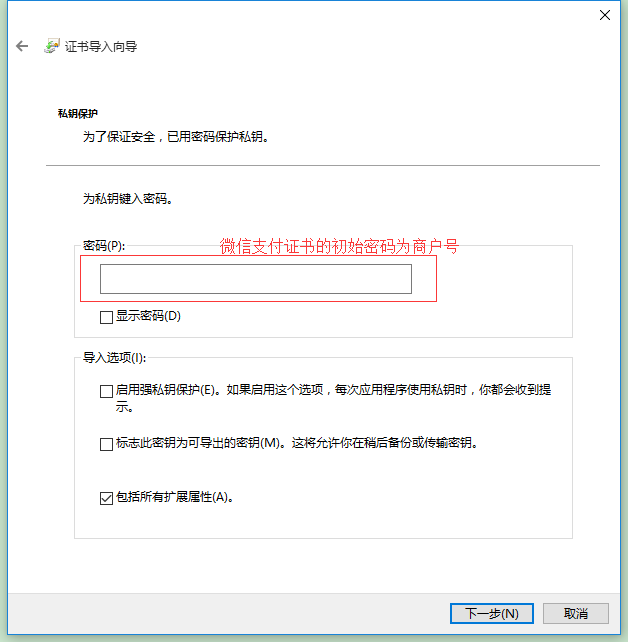
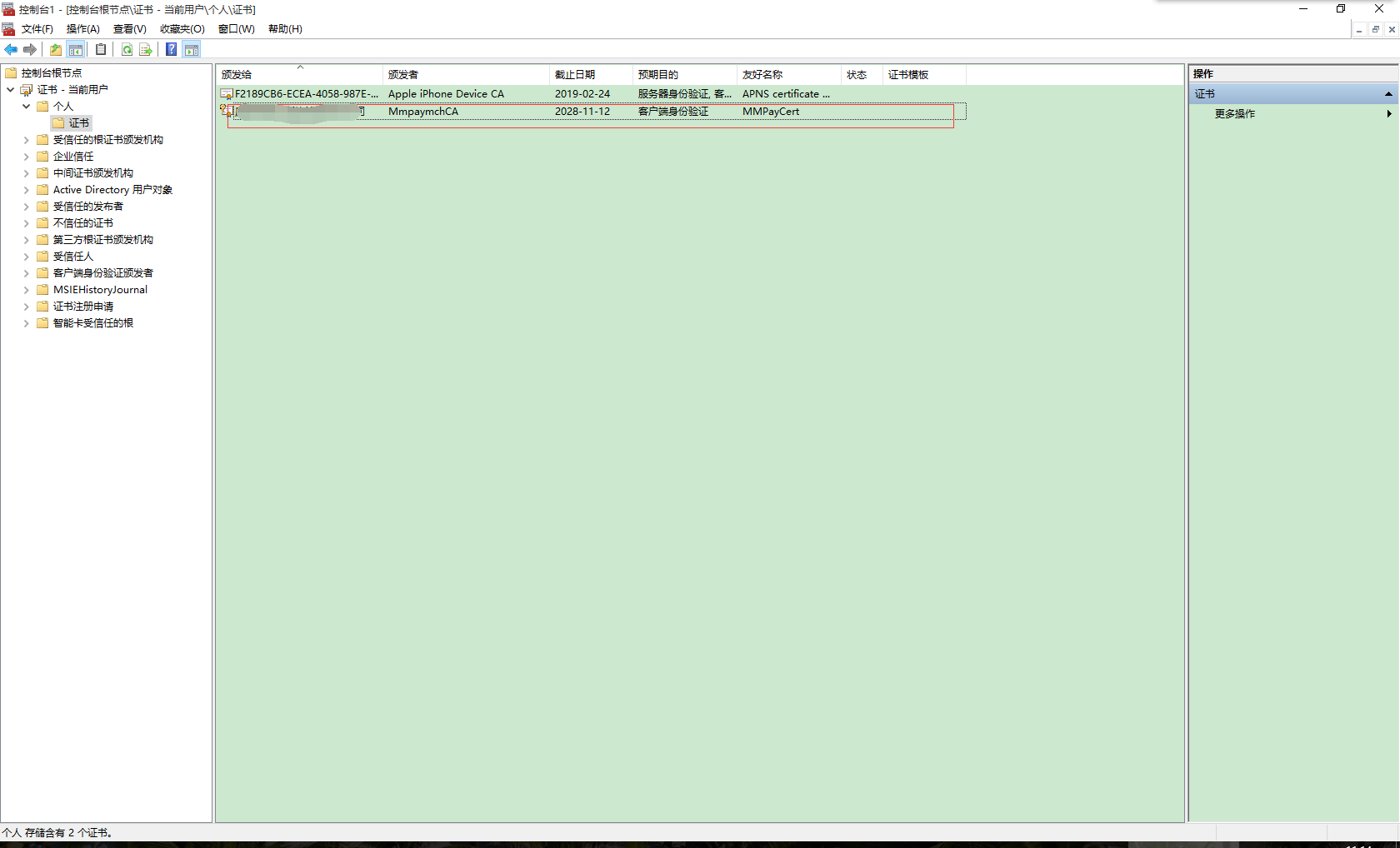
4、证书导入完成后,就会出现在证书列表上
二、修改代码
修改统一下单代码,改变搜索证书

1 X509Store certStore = new X509Store(StoreName.My, StoreLocation.LocalMachine); 2 certStore.Open(OpenFlags.ReadOnly); 3 X509Certificate2Collection certCollection = certStore.Certificates.Find(X509FindType.FindBySubjectName, "你的证书名称", false);
注:匹配模式为模糊搜索
三、授权IIS使用证书,本章测试为IIS7.5,IIS6以下请参考其它文章
1、下载安装winhttpcertcfg.msi
2、cmd->cd C:\Program Files (x86)\Windows Resource Kits\Tools,执行命令:winhttpcertcfg -g -c LOCAL_MACHINE\MY -s "厦门康意达餐饮管理有限公司" -a "EVERYONE"
以上步骤完成之后,就在IIS可以使用微信支付证书了
四、修改TSL证书加密级别
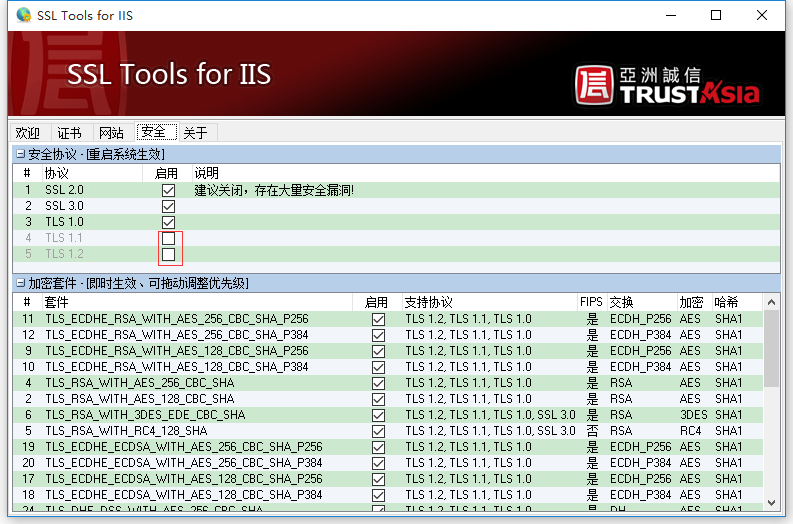
1、下载SSLTools.exe,提取码:iz5n
2、运行SSLTools.exe文件(注:电脑可能会提示病毒,在杀毒软件上添加信任就行了,确认无毒)
3、选择启用TSL1.1、TSL1.2
4、重启电脑
至此,所以配置操作步骤已完成
SqlServer无备份下误删数据恢复
系统已上线,给客户修改bug的时候,使用delete语句删表数据,没想到库没切换成测试库。误删了正式库的数据,而且一次备份都没有做过,玩大了
不扯了,进入主题
网上很多方法,都是针对至少有一次备份的情况下进行数据恢复的,没有备份就基本上只能找数据恢复公司了。本章将通过日志来恢复误删的数据,若是日志文件都没有了,那就真的玩大了
步骤:
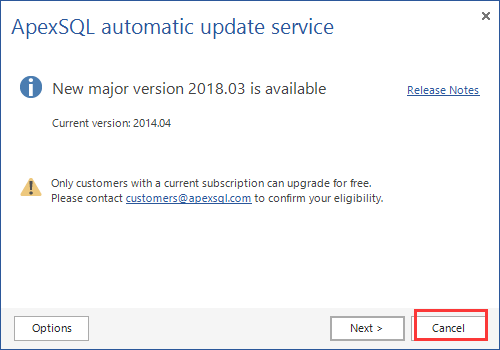
1、下载恢复工具,提取码:u1dv。注:本人使用的库是2008r2,网上说此工具只能支持到2012版本。本章并未进行测试
2、解压进入ApexSQLLog2014文件夹,运行ApexSQLLog.exe文件
3、输入数据库连接信息,选择指定数据库

4、等待加载日志文件,点击下一步

5、选择误操作时间

6、选择操作方式,这边测试的是delete

7、选择要误操作的表

选择好后,直接点击Next
8、选择open results in grid
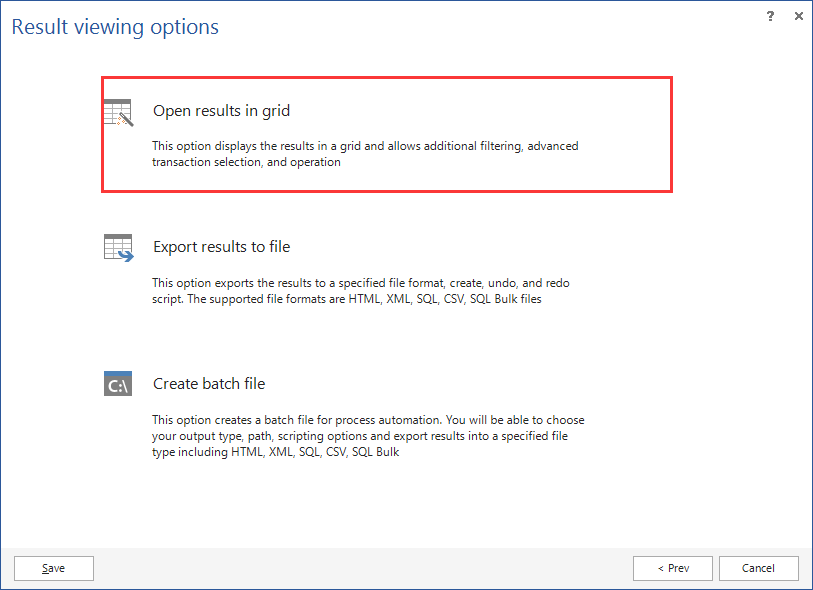
9、等待加载出误操作的日志信息列表
10、选择要恢复的数据,点击Create undo script
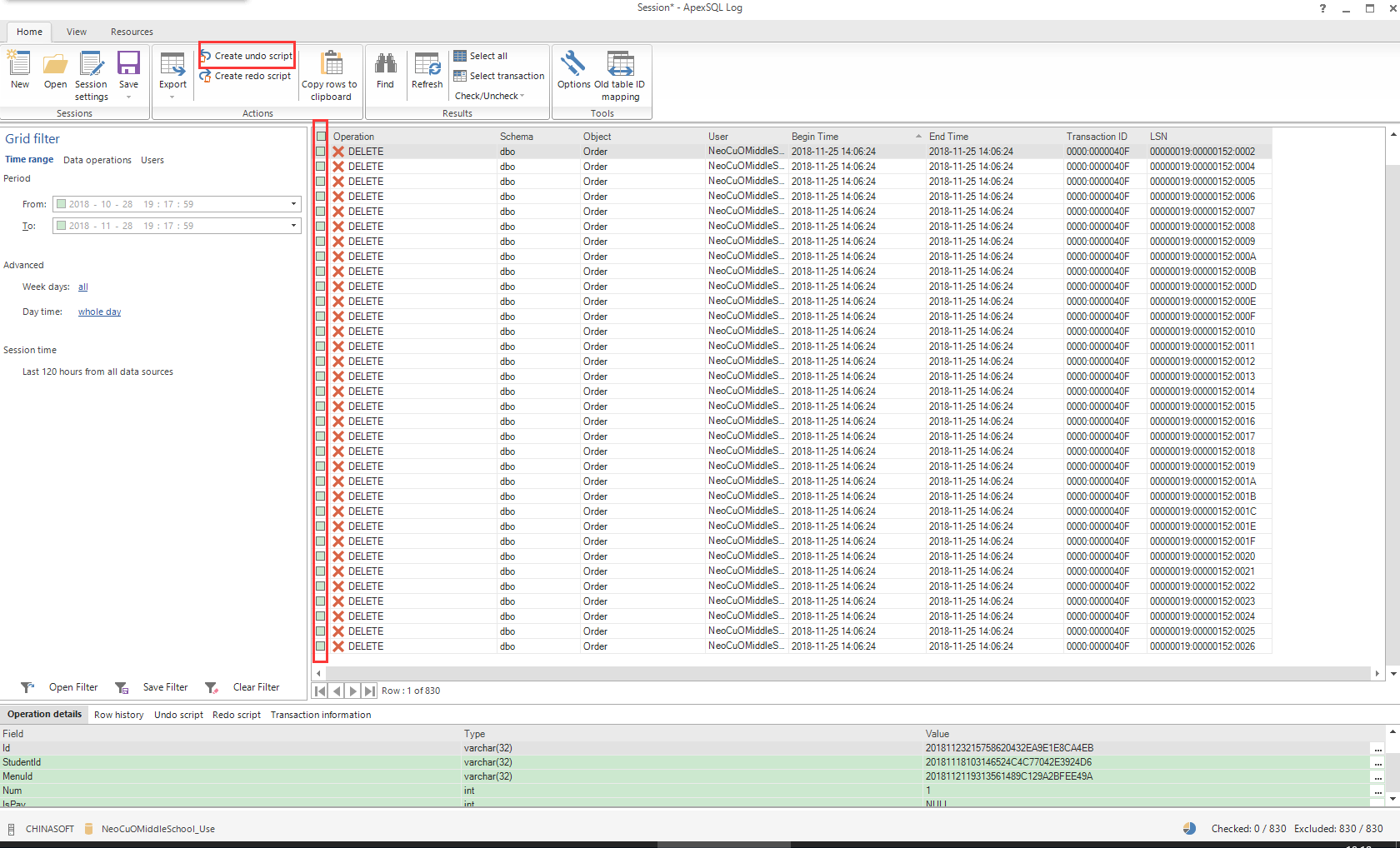
9、生成的脚本文件就是误删的数据了
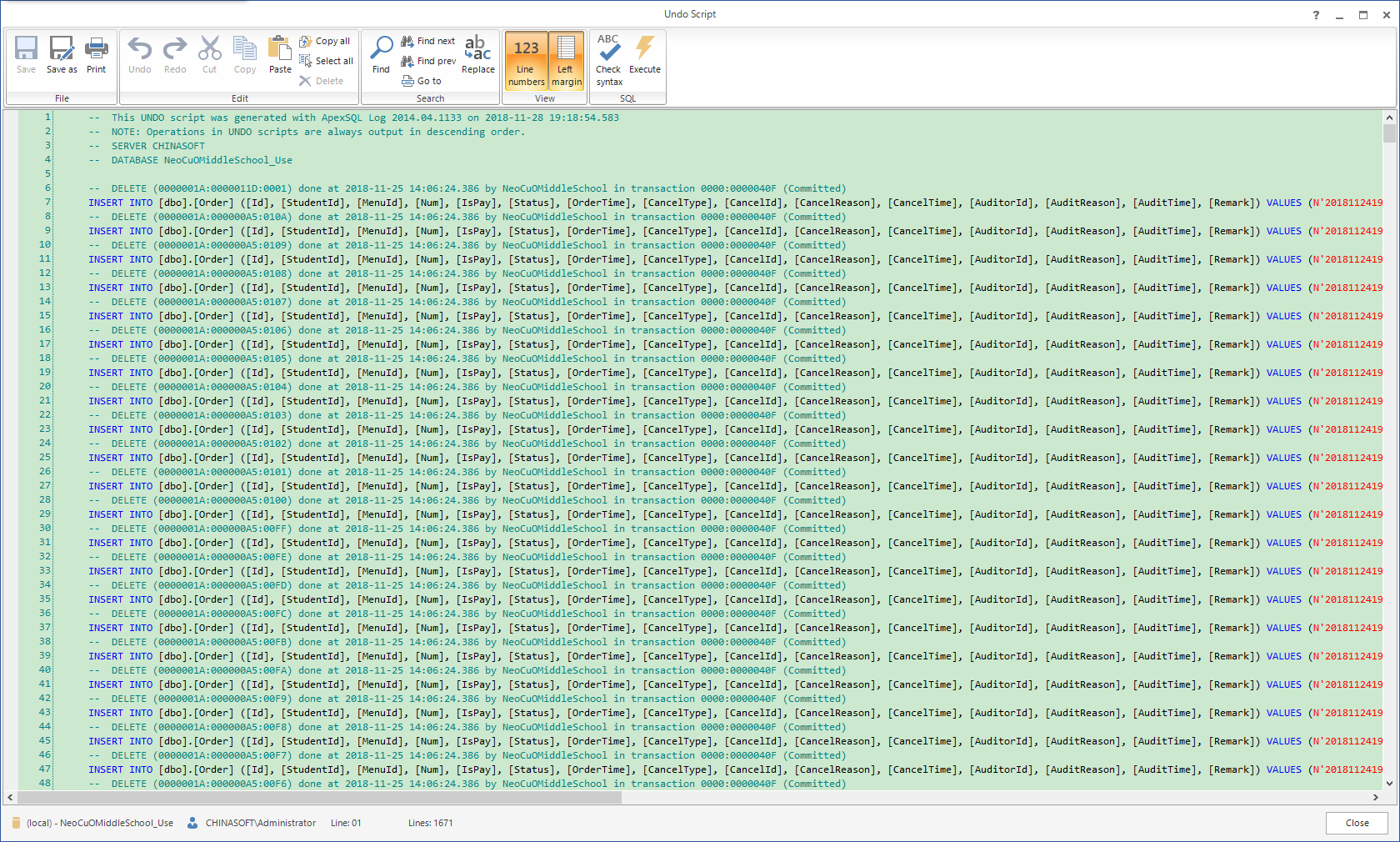
至此找回误删数据的所有步骤已经完成
把list集合的内容写入到Xml中,通过XmlDocument方式写入Xml文件中
List<Person> list = new List<Person>
{
new Person{Name="张三",Age=20,Email="zs@zhansan.com"},
new Person{Name="李四",Age=30,Email="ls@lisi.com"},
new Person{Name="王五",Age=22,Email="ww@wangwu.com"},
new Person{Name="赵柳",Age=20,Email="xl@zhaoliou.com"},
new Person{Name="玄武",Age=20,Email="xw@xuanwu.com"},
new Person{Name="白虎",Age=20,Email="bh@baihu.com"},
};
//实例化XMLDocument对象
XmlDocument xmldoc = new XmlDocument();
//增加一个Xml文档声明
XmlDeclaration xmldeclaration = xmldoc.CreateXmlDeclaration("1.0", "utf-8", null);
//创建Xml文档根节点
XmlElement xmlelement = xmldoc.CreateElement("List");
//添加到Xml文档中
xmldoc.AppendChild(xmlelement);
//循环添加
for (int i = 0; i < list.Count; i++)
{
//创建根节点下的子节点
XmlElement xmlperson = xmldoc.CreateElement("Person");
//创建子节点的属性ID
XmlAttribute xmlattribute = xmldoc.CreateAttribute("id");
//给属性值赋值
xmlattribute.Value = (i + 1).ToString();
//添加到子节点中
xmlperson.Attributes.Append(xmlattribute);
//添加Name节点
XmlElement xmlName = xmldoc.CreateElement("Name");
//给Name文本赋值
xmlName.InnerText = list[i].Name;
//添加到Person节点下
xmlperson.AppendChild(xmlName);
//以下节点类似
XmlElement xmlAge = xmldoc.CreateElement("Age");
xmlAge.InnerText = list[i].Age.ToString();
xmlperson.AppendChild(xmlAge);
XmlElement xmlEmail = xmldoc.CreateElement("Email");
xmlEmail.InnerText = list[i].Email;
xmlperson.AppendChild(xmlEmail);
xmlelement.AppendChild(xmlperson);
}
//创建文件保存在Xml文件夹中
string fileName = Server.MapPath("/Xml/List.xml");
xmldoc.Save(fileName);
通过XDocument方式把List写入Xml文件
List<Person> list=new List<Person>{
new Person(){Name="张三",Age=50,Address="重庆市沙坪坝区"},
new Person(){Name="李四",Age=20,Address="西科公寓"},
new Person(){Name="王麻子",Age=50,Address="重庆市沙坪坝区"},
new Person(){Name="陈二狗",Age=20,Address="西科公寓"}
};
//实例化一XDocument对象
XDocument xdoc=new XDocument();
//为文档增加一文档声明
XDeclaration xdecl =new XDeclaration("1.0","utf-8",null);
//创建一个根节点
XElement xelement=new XElement("List");
//把根节点添加到文档中
xdox.Add(xelement);
for(int i=0;i<list.Count;i++){
//为根节点下添加子节点
XElement xperson=new XElement("Person");
//为节点添加属性
xperson.SetAttributeValue("id",(i+1).ToString());
//给子节点添加文本节点
xperson.SetElementValue("Name",list[i].Name);
xperson.SetElementValue("Age",list[i].Age.ToString());
xperson.SetElementValue("Address",list[i].Address);
//添加到根节点下
xelement.Add(xperson);
}
//创建一个在Xml文件夹下的List.xml文件
string fileName=Server.MapPath("/Xml/List.xml");
//保存Xml文件
xdoc.Save(fileName);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号