通俗易懂,C#如何安全、高效地玩转任何种类的内存之Span。 给萌新的Flexbox简易入门教程 浅谈Quartz定时任务调度 浅谈JavaScript之Event(上篇) 探索JavaScript数组奥秘 【详解JavaScript系列】JavaScript之函数(一) C# Oracle.ManagedDataAccess 批量更新表数据 VS2015常用快捷键总结
通俗易懂,C#如何安全、高效地玩转任何种类的内存之Span。
前言
作为.net程序员,使用过指针,写过不安全代码吗?
为什么要使用指针,什么时候需要使用它?
如果能很好地回答这两个问题,那么就能很好地理解今天了主题了。C#构建了一个托管世界,在这个世界里,只要不写不安全代码,不操作指针,那么就能获得.Net至关重要的安全保障,即什么都不用担心;那如果我们需要操作的数据不在托管内存中,而是来自于非托管内存,比如位于本机内存或者堆栈上,该如何编写代码支持来自任意区域的内存呢?这个时候就需要写不安全代码,使用指针了;而如何安全、高效地操作任何类型的内存,一直都是C#的痛点,今天我们就来谈谈这个话题,讲清楚 What、How 和 Why ,让你知其然,更知其所以然,以后有人问你这个问题,就让他看这篇文章吧,呵呵。
what - 痛点是什么?
回答这个问题前,先总结一下如何用C#操作任何类型的内存:
-
托管内存(managed memory )
var mangedMemory = new Student();很熟悉吧,只需使用
new操作符就分配了一块托管堆内存,而且还不用手工释放它,因为它是由垃圾收集器(GC)管理的,GC会智能地决定何时释放它,这就是所谓的托管内存。默认情况下,GC通过复制内存的方式分代管理小对象(size < 85000 bytes),而专门为大对象(size >= 85000 bytes)开辟大对象堆(LOH),管理大对象时,并不会复制它,而是将其放入一个列表,提供较慢的分配和释放,而且很容易产生内存碎片。 -
栈内存(stack memory )
unsafe{ var stackMemory = stackalloc byte[100]; }很简单,使用
stackalloc关键字非常快速地就分配好了一块栈内存,也不用手工释放,它会随着当前作用域而释放,比如方法执行结束时,就自动释放了。栈内存的容量非常小( ARM、x86 和 x64 计算机,默认堆栈大小为 1 MB),当你使用栈内存的容量大于1M时,就会报StackOverflowException异常 ,这通常是致命的,不能被处理,而且会立即干掉整个应用程序,所以栈内存一般用于需要小内存,但是又不得不快速执行的大量短操作,比如微软使用栈内存来快速地记录ETW事件日志。 -
本机内存(native memory )
IntPtr nativeMemory0 = default(IntPtr), nativeMemory1 = default(IntPtr); try { unsafe { nativeMemory0 = Marshal.AllocHGlobal(256); nativeMemory1 = Marshal.AllocCoTaskMem(256); } } finally { Marshal.FreeHGlobal(nativeMemory0); Marshal.FreeCoTaskMem(nativeMemory1); }通过调用方法
Marshal.AllocHGlobal或Marshal.AllocCoTaskMem来分配非托管堆内存,非托管就是垃圾回收器(GC)不可见的意思,并且还需要手工调用方法Marshal.FreeHGlobalorMarshal.FreeCoTaskMem释放它,千万不能忘记,不然就产生内存碎片了。
抛砖引玉 - 痛点
首先我们设计一个解析完整或部分字符串为整数的API,如下:
public interface IntParser
{
// allows us to parse the whole string.
int Parse(string managedMemory);
// allows us to parse part of the string.
int Parse(string managedMemory, int startIndex, int length);
// allows us to parse characters stored on the unmanaged heap / stack.
unsafe int Parse(char* pointerToUnmanagedMemory, int length);
// allows us to parse part of the characters stored on the unmanaged heap / stack.
unsafe int Parse(char* pointerToUnmanagedMemory, int startIndex, int length);
}从上面可以看到,为了支持解析来自任何内存区域的字符串,一共写了4个重载方法。
接下来在来设计一个支持复制任何内存块的API,如下:
public interface MemoryblockCopier
{
void Copy<T>(T[] source, T[] destination);
void Copy<T>(T[] source, int sourceStartIndex, T[] destination, int destinationStartIndex, int elementsCount);
unsafe void Copy<T>(void* source, void* destination, int elementsCount);
unsafe void Copy<T>(void* source, int sourceStartIndex, void* destination, int destinationStartIndex, int elementsCount);
unsafe void Copy<T>(void* source, int sourceLength, T[] destination);
unsafe void Copy<T>(void* source, int sourceStartIndex, T[] destination, int destinationStartIndex, int elementsCount);
}脑袋蒙圈没,以前C#操纵各种内存就是这么复杂、麻烦。通过上面的总结如何用C#操作任何类型的内存,相信大多数同学都能够很好地理解这两个类的设计,但我心里是没底的,因为使用了不安全代码和指针,这些操作是危险的、不可控的,根本无法获得.net至关重要的安全保障,并且可能还会有难以预估的问题,比如堆栈溢出、内存碎片、栈撕裂等等,微软的工程师们早就意识到了这个痛点,所以span诞生了,它就是这个痛点的解决方案。
how - span如何解决这个痛点?
先来看看,如何使用span操作各种类型的内存(伪代码):
-
托管内存(managed memory )
var managedMemory = new byte[100]; Span<byte> span = managedMemory; -
栈内存(stack memory )
var stackedMemory = stackalloc byte[100]; var span = new Span<byte>(stackedMemory, 100); -
本机内存(native memory )
var nativeMemory = Marshal.AllocHGlobal(100); var nativeSpan = new Span<byte>(nativeMemory.ToPointer(), 100);
span就像黑洞一样,能够吸收来自于内存任意区域的数据,实际上,现在,在.Net的世界里,Span就是所有类型内存的抽象化身,表示一段连续的内存,它的API设计和性能就像数组一样,所以我们完全可以像使用数组一样地操作各种内存,真的是太方便了。
现在重构上面的两个设计,如下:
public interface IntParser
{
int Parse(Span<char> managedMemory);
int Parse(Span<char>, int startIndex, int length);
}
public interface MemoryblockCopier
{
void Copy<T>(Span<T> source, Span<T> destination);
void Copy<T>(Span<T> source, int sourceStartIndex, Span<T> destination, int destinationStartIndex, int elementsCount);
}上面的方法根本不关心它操作的是哪种类型的内存,我们可以自由地从托管内存切换到本机代码,再切换到堆栈上,真正的享受玩转内存的乐趣。
why - 为什么span能解决这个痛点?
浅析span的工作机制
先来窥视一下源码:

我已经圈出的三个字段:偏移量、索引、长度(使用过ArraySegment<byte> 的同学可能已经大致理解到设计的精髓了),这就是它的主要设计,当我们访问span表示的整体或部分内存时,内部的索引器会按照下面的算法运算指针(伪代码):
ref T this[int index]
{
get => ref ((ref reference + byteOffset) + index * sizeOf(T));
}整个变化的过程,如图所示:

上面的动画非常清楚了吧,旧span整合它的引用和偏移成新的span的引用,整个过程并没有复制内存,而是直接返回引用,因此性能非常高,因为新span获得并更新了引用,所以垃圾回收器(GC)知道如何处理新的span,从而获得了.Net至关重要的安全保障,而这些都是span内部默默完成的,开发人员根本不用担心,非托管世界依然美好。
正是由于span的高性能,目前很多基础设施都开始支持span,甚至使用span进行重构,比如:System.String.Substring方法,我们都知道此方法是非常消耗性能的,首先会创建一个新的字符串,然后在复制原始字符串的字符集给它,而使用span可以实现Non-Allocating、Zero-coping,下面是我做的一个基准测试:

使用String.SubString和Span.Slice分别截取长度为10和1000的字符串的前一半,从指标Mean可以看出方法SubString的耗时随着字符串长度呈线性增长,而Slice几乎保持不变;从指标Allocated Memory/Op可以看出,方法Slice并没有被分配新的内存,实践出真知,可以预见Span未来将会成为.Net下编写高性能应用程序的重要积木,应用前景也会非常地广,微服务、物联网都是它发光发热的好地方。
总结
看完本篇博客,应该对Span的What、Why、How了如指掌了,那么我的目的就达到了,不懂的同学可以多读几遍,下一篇,我将会畅谈Span的应用场景、优缺点,让大家能够安全高效地使用好它,大家也可以在评论留言自己的应用场景,我会在写下一篇博客时多多参考。
最后
如果有什么疑问和见解,欢迎评论区交流。
如果你觉得本篇文章对您有帮助的话,感谢您的【推荐】。
如果你对高性能编程感兴趣的话可以关注我,我会定期的在博客分享我的学习心得。
欢迎转载,请在明显位置给出出处及链接。
延伸阅读
https://github.com/dotnet/corefxlab/blob/master/docs/specs/span.md
https://msdn.microsoft.com/en-us/magazine/mt814808
https://github.com/dotnet/BenchmarkDotNet/pull/492
给萌新的Flexbox简易入门教程
转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。
原文出处:https://www.sitepoint.com/flexbox-css-flexible-box-layout/

近几年,CSS领域出现了一些复杂的专用布局工具,用以代替原有的诸如使用表格、浮动和绝对定位之类的各种变通方案。Flexbox,或者说是弹性盒子布局模块(Flexible Box Layout Module)是这些新布局工具中的第一个,接着是CSS网格布局模块(CSS Grid Layout Module)。我们会在本文给出一个易于理解的flexbox入门介绍。
随着CSS网格布局的引入,你可能会问flexbox布局是否真的还有必要。虽然它们所能做的事情有一些重叠,但其各自在CSS布局中有着非常特别的目的。一般来说,flexbox在一维场景(比如,一串类似的元素)下有最佳应用,而网格是二维场景下理想的布局方案(例如整个页面的元素)。
即便如此,flexbox仍可以用于整个页面的布局,这样它能为那些还不支持网格布局的浏览器提供合适的兼容处理。(必须承认,网格布局正在大多数现代浏览器中快速得到支持,不过对flexbox的支持仍然更为广泛,所以如果你想让你的布局在稍微老旧的浏览器中也生效,使用flexbox作为网格布局的降级方案是很容易的)。
使用Flexbox的好处
flexbox的一些好处是:
- 页面元素能被任意方向地放置(靠左、靠右、从上往下甚至从下往上)
- 布局内容的可视顺序能够被反转或重排
- 元素大小能“弹性”适应可用空间,并根据容器或者兄弟元素进行相应地对齐
- 能轻松实现等列宽布局(与每一列里面的内容无关)
为了阐述其多样的属性和可能性,让我们假设下面有这样的布局用例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
<div class="example"> <header> header content here </header> <main class="main"> <nav> nav content here </nav> <div class="content"> main content here </div> <aside> aside content here </aside> </main> <footer> footer content here </footer></div> |
首先,是把元素一起放进.main里,比如,<nav>和<aside>。如果没有flexbox,我们可能会把三个元素全部进行浮动,但想让它按理想的方式工作显得并不直观。而且,按传统的方式做这件事会出现一个众所周知的问题:每一列仅仅和它的内容一样高。因此,你可能需要把三个元素都设置为统一的高度,或者使用某种黑科技。
让flexbox来救场吧。
让我们Flex
flexbox的要点是出现在display属性上的flex值,它需要被设置在容器元素上。如此设置会让它的子元素变成“弹性项目(flex item)”。这些弹性项目拥有一些易于使用的默认属性。比如,它们被紧挨着放置,那些没有特别指明宽度的元素自动占满了剩余的空间。
因此,如果你给.main设置了display:flex,它的子元素.content就被自动挤在<nav>和<aside>之间。不需要再多余的计算,多么方便是吧?作为附加奖赏,所有三个元素神奇地拥有了相同的高度。
|
1
2
3
|
.main { display: flex;} |
请查看下面的例子,包含了所有的细节:flexbox-demo-1。
项的顺序:Flebox的order属性
另外一个flexbox的能力,是能够轻松改变元素的显示顺序。让我们假设你为一个客户制作了上面的布局,而她现在想要.content出现在<nav>之前。
通常,你需要深入到HTML源码中去,在那里改变元素的顺序。而有了Flexbox,你可以完全使用CSS完成这项任务。只需把.content的order属性设置为-1,那么这一列就会出现在前面,这本例就是最左边。
|
1
2
3
4
5
6
7
|
.main { display: flex;}.content { order: -1;} |
本例中,你不需要改变其他列的order。例子在flexbox-demo-2。
如果你倾向于显式地为每一列指定order,你可以将.content的order设为1,把<nav>的order设为2,把<aside>的设为3。
HTML源码独立于CSS的Flexbox样式
但你的客户并不满足。她想让<footer>成为页面的第一个元素,显示在<header>之前。那好,同样的,flexbox是你的朋友(虽然像在此例中,可能你得跟你的客户好好谈谈,而不是跟随指示)。因为你不仅要重排列内部元素,还要重排外部的,display:flex规则将被设置在<div class="example">之上。注意这里是如何在页面中嵌套使用flex容器来达到你想要的效果的。
因为<header>,<main class="main">和<footer>相互堆叠着,你需要首先设置一个垂直上下文,它能够通过设置flex-direction:column来快速完成。还有,<footer>的order被设置为-1,如此一来它就出现在页面的最上头。就这么简单。
|
1
2
3
4
5
6
7
8
|
.example { display: flex; flex-direction: column;}footer { order: -1;} |
所以,如果你想把一行元素修改为一列,或者相反,你可以使用flex-direction属性,并设置它相应地为column或row(row是默认值)。
完整的例子在flexbox-demo-3。
然而,强大的能力也到来了更多的责任:谨记,一些用户可能会使用键盘来导航你的基于flexbox的网站,如果你HTML源码中元素的顺序和屏幕上显示的有所出入,那么无障碍访问的能力就成为需要认真对待的问题。如果想了解得更多,请不要错过HTML源码顺序 vs CSS显示顺序,网站无障碍访问和易用性的专家Adrian Roselli针对这个问题给出了深入讨论。
如何在Flexbox中对齐子项
Flexbox能非常直观地处理子项的水平对齐和垂直对齐。
你可以使用align-items对flex容器中的所有子项设置统一的对齐。如果你想给个别元素设置不同的对齐方式,使用align-self。元素的对齐方式跟它所在父容器的flex-direction有关。如果它的值是row(意味着元素水平排列),对齐方式是指在垂直轴上。如果flex-direction被设置为column(意味着元素垂直排列),对齐方式就是指在水平轴上。
例如,你让一些元素在容器中分别有不同的对齐方式,你需要:
- 设置每个元素的align-self属性为合适的值。可能的值有:center,stretch(元素撑满它的容器),flex-start,flex-end和baseline(元素被放置在父容器的baseline上)
- 把容器元素设置为display:flex
- 最后,注意父容器的flex-direction属性,因为它关系到子元素的对齐方式。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
.example { display: flex; flex-direction: column;}.red { align-self: center;}.blue { align-self: flex-start;}.pink { align-self: flex-end;} |
试试在下面的例子中,把父容器的flex-direction在row和column之间切换,看看它们引起的实时变化。
如果想要容器中所有的元素有统一的对齐方式,你可以在容器上使用align-items。可以的值有center,flex-start,flex-end,stretch(默认值:子项被拉伸以适应它们的容器)和baseline(子项被放置在父容器的baseline上)。
|
1
2
3
4
|
.example { display: flex; align-items: center;} |
像往常一样,试着把父容器的flex-direction在row和column之间切换,看看它们如何影响着你设置align-items值时所发生的作用。
在Flexbox里两端对齐
另一个控制对齐的属性是justify-content,当你想让多个元素等分空间时非常有用。
可接受的值有:center,flex-start,flex-end, space-between(元素利用主轴之间的空间而排布)和space-around(元素利用主轴之前、之间和之后的空间而排布)。
例如,在之前你一直使用的简单HTML模板里,你可以在<main>里找到三个元素:<nav>,.content和<aside>。之前,它们都被挤在页面的左边。如果你想让它们之间有一些空间,但是不让第一个元素的左边有空间,也不想让最后一个元素的右边有空间,你可以把.main(即它们的父容器)里的justify-content设置为space-between。
|
1
2
3
4
|
.main { display: flex; justify-content: space-between;} |
也试一下设置为space-around,观察不同的结果。例子在flexbox-demo-6。
在上面的例子中,我同样把<header>中的文字水平和垂直对齐了,分别是把justify-content(水平居中)和align-items(垂直居中)都设置为center。
|
1
2
3
4
5
6
|
header { height: 100vh; display: flex; justify-content: center; align-items: center;} |
Flexbox中弹性子项的大小
使用flex属性,你能够对照flex容器中其他元素来控制弹性子项的大小。
这个属性是以下独立属性的简写:
- flex-grow:一个数字,指明元素如何相对其他flex项来拉伸
- flex-shrink:一个数字,指明元素如何相对其他flex项来收缩
- flex-basis:元素的长度。可接受的值有:auto,inherit或者一个数字后面紧跟着%,px,em或其他长度单位。
例如,想得到三个等宽的列,只需给每一列设置flex:1,其他什么都不用做:
|
1
2
3
|
nav, aside, .content { flex: 1;} |
如果你需要.content占据<nav>和<aside>的两倍宽,那么就把.content设为flex:2,让其他两个为1。
那仅仅是对flex属性最简单的应用。同样可以设置flex-grow,flex-shrink和flex-basis这些值,不过那超出本文的话题范围了。
进一步的资源
如果你准备好继续前进,并想学着精通flexbox的更多东西,请查看下面的资源:
- Flexbox SitePoint上Guy Routledge制作的一个付费课程
- Building Mega Menus with Flexbox
- How 3 Modern Tools are Using Flexbox Grids
- Make Forms Fun with Flexbox.
总结
如你所见,如果我们想控制元素在网页中的布局,flexbox可以让我们的生活更加轻松。它非常稳固和可靠,让以前那些我们每天使用的诸如使 让容器坍缩之类的奇技淫巧,成为了过去。
像我们说的,如今,在针对整个页面进行布局时,CSS网格是更好的方案,但我们仍然值得去了解flexbox能做的那些事情。flexbox的最佳应用场景,体现在对元素的一维排列上,但如果有需要,它也能在稍老旧的浏览器中,为CSS网格布局提供方便的替代方案。
推荐
本文是由葡萄城技术开发团队发布,转载请注明出处:葡萄城官网
了解开放易用的 Web 生成平台,请前往活字格Web应用生成平台
了解可嵌入您系统的在线 Excel,请前往SpreadJS纯前端表格控件
浅谈Quartz定时任务调度
一 开发概述
对于具有一定规模的大多数企业来说,存在着这样一种需求:存在某个或某些任务,需要系统定期,自动地执行,然而,对大多数企业来说,该技术的实现,却是他们面临的一大难点和挑战。
对于大部分企业来说,实现如上功能,挑战在哪里?
挑战一:如何做一个自动服务的系统?
是从0到1开发(费时费力花钱,还不一定开发成功,即使开发成功,也未必好用),还是购买第三方服务(花钱)。
挑战二:如何实现复杂的“定期规则”?
对于简单的定期规则,可以借助于windows自带的执行计划来执行,但若是复杂的定期规则,windows执行计划未必可行,然而,Quartz的cron却很好地解决了该问题,
(可以说,cron在表达时间规则方面,无所不能),除此之外,Quartz能很好地配合windows执行计划,实现系统的定期,自动执行任务。
 对于大部分企业来说,实现如上功能,挑战在哪里?
对于大部分企业来说,实现如上功能,挑战在哪里?通过如上概述,我们知道Quartz能很好地解决该问题,那么,什么是Quartz呢?
简言之,Quartz就是一种任务调度计划。
- 它是由OpenSymphony提供的、开源的、java编写的强大任务调度框架
- 几乎可以集成到任何规模的运用程序中,如简单的控制台程序,复杂的大规模分布式电子商务系统
- 可用于创建简单的或复杂的计划任务
- 包含很多企业级功能,如支持JTA和集群等
本篇文章,主要从Quartz框架核心组件,Quartz基本运行原理,Quartz核心概念和Quartz基本功能实现(代码)等方面来介绍Quartz。
二 Quartz
当要深入研究一个技术时,研究它的体系结构和内部运行原理,不失为一种较好的方式。同理,我们在研究Quartz时,也采用类似的方法,
下图为Quartz的大致结构图。

(一)Quartz关键组件
Quartz比较关键的两个核心组件分别为Job和Trigger
- job--表示任务是什么
- trigger--表示何时触发任务

(二)Quartz几个关键概念
1.IJob
IJob表示一个接口,该接口只有一个方法签名
|
1
2
3
4
|
public interface IJob { void Execute(JobExecutionContext context); } |
在Quartz中,所有的job任务,必须实现该接口
|
1
2
3
4
5
6
7
|
public class MyJob : IJob { public void Execute(JobExecutionContext context) { Console.WriteLine("Quartz基本功能测试。"); } } |
2.JobDetail
JobDetail,顾名思义,就是表示关于每个Job的相关信息,它主要包括两个核心组件,即Job Task和JobData Map
3.Trigger
Trigger,表示触发器,根据配置规则来触发执行计划调度job,它主要包括两个核心组件,即SimpleTrigger和CronTrigger
4.IJobStore
IJobStore,表述任务存储器,主要存储job和trigger相关信息。
5.ISchedulerFactory
ISchedulerFactory,表示任务计划工厂,用来管理任务计划IScheduler。
6.IScheduler
IScheduler,表述任务计划,它相当于一个容器,具体job和job相关trigger就能够被注入其中,从而实现任务计划调度。其主要常用的方法:
- Start --启动执行计划
- Shutdowm --关闭执行计划
接口Code:


namespace Quartz
{
public interface IScheduler
{
bool IsStarted { get; }
string SchedulerName { get; }
string SchedulerInstanceId { get; }
bool InStandbyMode { get; }
bool IsShutdown { get; }
IJobFactory JobFactory { set; }
string[] JobGroupNames { get; }
string[] TriggerGroupNames { get; }
SchedulerContext Context { get; }
IList GlobalJobListeners { get; }
string[] CalendarNames { get; }
IList GlobalTriggerListeners { get; }
ISet TriggerListenerNames { get; }
ISet JobListenerNames { get; }
IList SchedulerListeners { get; }
void AddCalendar(string calName, ICalendar calendar, bool replace, bool updateTriggers);
void AddGlobalJobListener(IJobListener jobListener);
void AddGlobalTriggerListener(ITriggerListener triggerListener);
void AddJob(JobDetail jobDetail, bool replace);
void AddJobListener(IJobListener jobListener);
void AddSchedulerListener(ISchedulerListener schedulerListener);
void AddTriggerListener(ITriggerListener triggerListener);
bool DeleteCalendar(string calName);
bool DeleteJob(string jobName, string groupName);
ICalendar GetCalendar(string calName);
string[] GetCalendarNames();
IList GetCurrentlyExecutingJobs();
IJobListener GetGlobalJobListener(string name);
ITriggerListener GetGlobalTriggerListener(string name);
JobDetail GetJobDetail(string jobName, string jobGroup);
IJobListener GetJobListener(string name);
string[] GetJobNames(string groupName);
SchedulerMetaData GetMetaData();
ISet GetPausedTriggerGroups();
Trigger GetTrigger(string triggerName, string triggerGroup);
ITriggerListener GetTriggerListener(string name);
string[] GetTriggerNames(string groupName);
Trigger[] GetTriggersOfJob(string jobName, string groupName);
TriggerState GetTriggerState(string triggerName, string triggerGroup);
bool Interrupt(string jobName, string groupName);
bool IsJobGroupPaused(string groupName);
bool IsTriggerGroupPaused(string groupName);
void PauseAll();
void PauseJob(string jobName, string groupName);
void PauseJobGroup(string groupName);
void PauseTrigger(string triggerName, string groupName);
void PauseTriggerGroup(string groupName);
bool RemoveGlobalJobListener(IJobListener jobListener);
bool RemoveGlobalJobListener(string name);
bool RemoveGlobalTriggerListener(ITriggerListener triggerListener);
bool RemoveGlobalTriggerListener(string name);
bool RemoveJobListener(string name);
bool RemoveSchedulerListener(ISchedulerListener schedulerListener);
bool RemoveTriggerListener(string name);
DateTime? RescheduleJob(string triggerName, string groupName, Trigger newTrigger);
void ResumeAll();
void ResumeJob(string jobName, string groupName);
void ResumeJobGroup(string groupName);
void ResumeTrigger(string triggerName, string groupName);
void ResumeTriggerGroup(string groupName);
DateTime ScheduleJob(Trigger trigger);
DateTime ScheduleJob(JobDetail jobDetail, Trigger trigger);
void Shutdown(bool waitForJobsToComplete);
void Shutdown();
void Standby();
void Start();
void StartDelayed(TimeSpan delay);
void TriggerJob(string jobName, string groupName);
void TriggerJob(string jobName, string groupName, JobDataMap data);
void TriggerJobWithVolatileTrigger(string jobName, string groupName);
void TriggerJobWithVolatileTrigger(string jobName, string groupName, JobDataMap data);
bool UnscheduleJob(string triggerName, string groupName);
}
}
(三)核心UML图
1.命名空间
不同版本的Quartz命名空间有所区别,但差别不大,如下为版本1.0.3命名空间

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
using Quartz;using Quartz.Core;using Quartz.Impl;using Quartz.Impl.AdoJobStore;using Quartz.Impl.AdoJobStore.Common;using Quartz.Impl.Calendar;using Quartz.Impl.Matchers;using Quartz.Impl.Triggers;using Quartz.Listener;using Quartz.Logging;using Quartz.Logging.LogProviders;using Quartz.Simpl;using Quartz.Spi;using Quartz.Util;using Quartz.Xml;using Quartz.Xml.JobSchedulingData20;using System; |
2.关键组件继承关系
在Quartz中,许多组件是可以通过配置来促使作业执行的,如线程程序(Tread Procedure)决定如何执行计划任务线程(Quartz Scheduler Thread)

三 代码
本示例,我们将使用.net 控制台程序,基于VS2017来使用Quartz建立一个任务:
任务要求:要求在控制台每隔2秒输出:Quartz基本功能测试。
1.首先使用Nuget下载Quartz
本示例使用的Quartz版本为1.0.3
2.按照如下步骤操作

代码:
第一阶段:创建实现IJob接口的MyJob类
|
1
2
3
4
5
6
7
|
public class MyJob : IJob{ public void Execute(JobExecutionContext context) { Console.WriteLine("Quartz基本功能测试。"); }} |
第二阶段:按规则调用Quartz组件
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
static void Main(string[] args) { //每个2秒执行一次 string cronParam = "*/2 * * * * ?"; //创建计划任务抽象工厂 ISchedulerFactory sf = new StdSchedulerFactory(); //创建计划任务 IScheduler sched = sf.GetScheduler(); //创建job JobDetail job = new JobDetail("myJob","group", typeof(MyJob)); //创建触发器 Trigger trigger = new CronTrigger("myTrigger","group",cronParam); //将job和trigger注入到计划任务中 sched.ScheduleJob(job, trigger); //启动计划任务 sched.Start(); //关闭计划任务 //sched.Shutdown(); Console.Read(); } |
3.测试结果

四 参考文献
【01】http://www.quartz-scheduler.org/
【02】https://www.ibm.com/developerworks/library/j-quartz/index.html
【03】https://www.w3cschool.cn/quartz_doc/
浅谈JavaScript之Event(上篇)
一 简述JavaScript及其在浏览器中的地位
(一) 浏览器主要构成
虽然不同浏览器之间存在差异(如Google Chrome,Firefox,Safari和IE等),但单从浏览器构成来说,大同小异,大致可归结为如下几类:
1.User Interface(用户界面):所谓用户界面,就是通过浏览器渲染出来,让用户可见的界面,如地址栏,书签菜单栏等;
2.Browser Engine(浏览器引擎):主要操作呈现的引擎界面;
3.Rendering Engine(渲染引擎):负责渲染响应请求内容,如负责解析HTML和CSS;
4.Networking(网络):负责网络呼叫处理,如http请求;
5.JS Interpreter(JavaScript 解释器):负责解析和执行javascript代码;
6.UI Back(UI后端):用于绘制组合框和窗口等基本组建;
7.Data Persistence(数据持久):通常用来持久化存储少量数据,如cookie等;
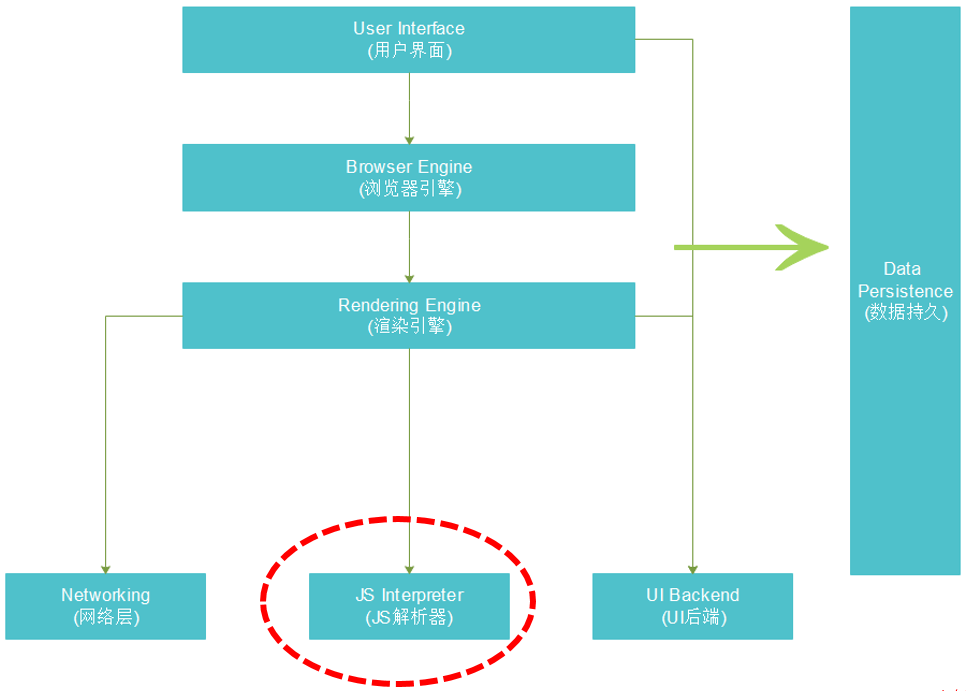
(二)JavaScript在浏览器中的地位
如上图,javascript处于浏览器中的核心位置,负责解释和执行js脚本,内置于浏览器中,通过浏览器提供的API来访问。
(三)JavaScript构成
关于javascript的构成,大致可归结为三个部分:ECMAScript,DOM和BOM。
1.ECMAScript是对js的约束和规范,如基本语法结构;
2.DOM就是文档对象模型,是交互的资源,如html文档;
3.BOM主要是对浏览器本身描述,如浏览器名称,版本号等;

(四)JavaScript基本执行原理
这里不深入谈及javascript的深层次执行原理,只是大致描述一下,关于更深层次的,在后续文章推出,与大家分享。
JS的执行原理,用一句话来归结之:单线程异步。下图很好地表述该过程。
所有的执行函数统一放在队列中进行排队。
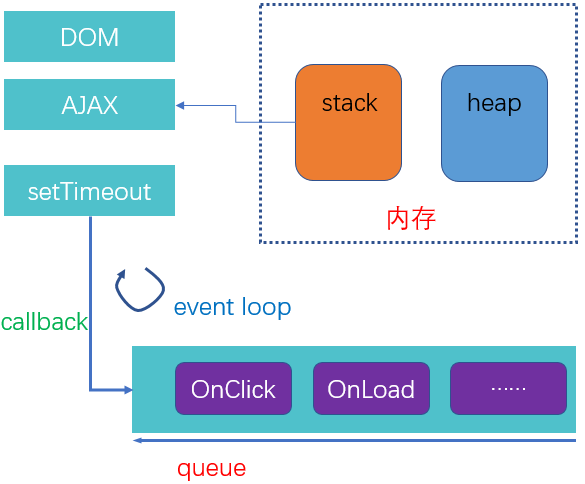
二 事件流
所谓事件流,也可理解为事件的轨迹。一般地,将事件流分为三个阶段:捕获阶段,目标阶段和冒泡阶段。

下图为三个阶段的大致流程图。
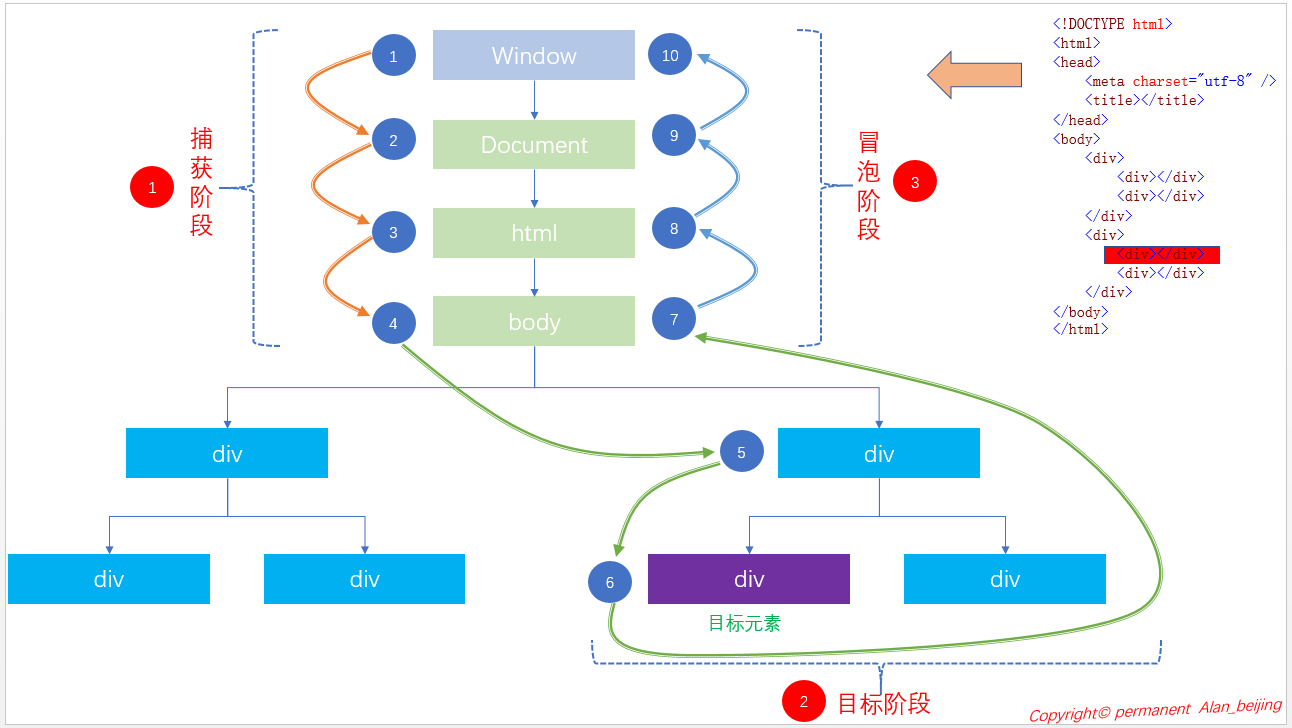
(一)捕获阶段
捕获阶段处于事件流的第一阶段,该阶段的主要作用是捕获截取事件。在DOM中,该阶段始于Document,结束于body(当然,在现在的很
多高版本浏览器中,该过程结束于目标元素,只不过不执行目标元素而已,这也体现了目标元素具有双重范围)。
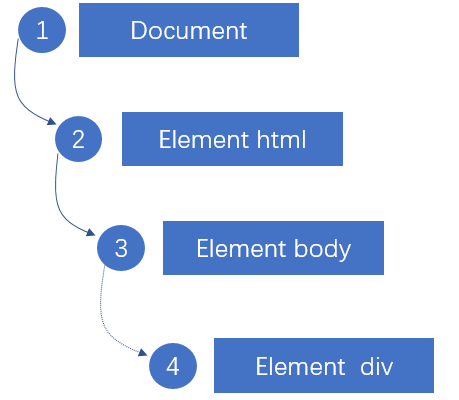
(二)目标阶段
目标阶段处于事件流的第二阶段,该阶段的主要作用是执行绑定事件。一般地,该阶段具有双重范围,即捕获阶段的结束,冒泡阶段的开始;
(三)冒泡阶段
冒泡阶段处于事件流的第三阶段,该阶段的主要作用是将目标元素绑定事件执行的结果返回给浏览器,处理不同浏览器之间的差异,主要在该阶段完成。
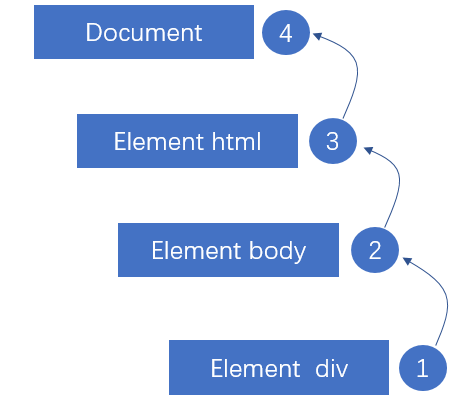
(四)三阶段在Dom中的完整流程
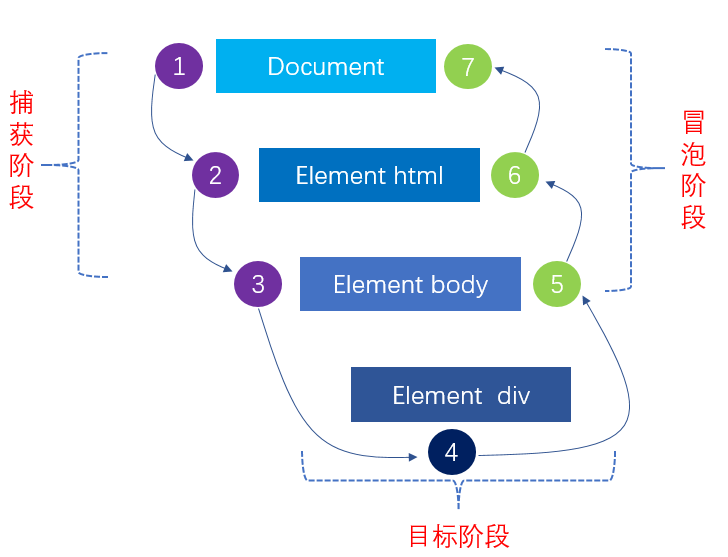
三 事件处理程序
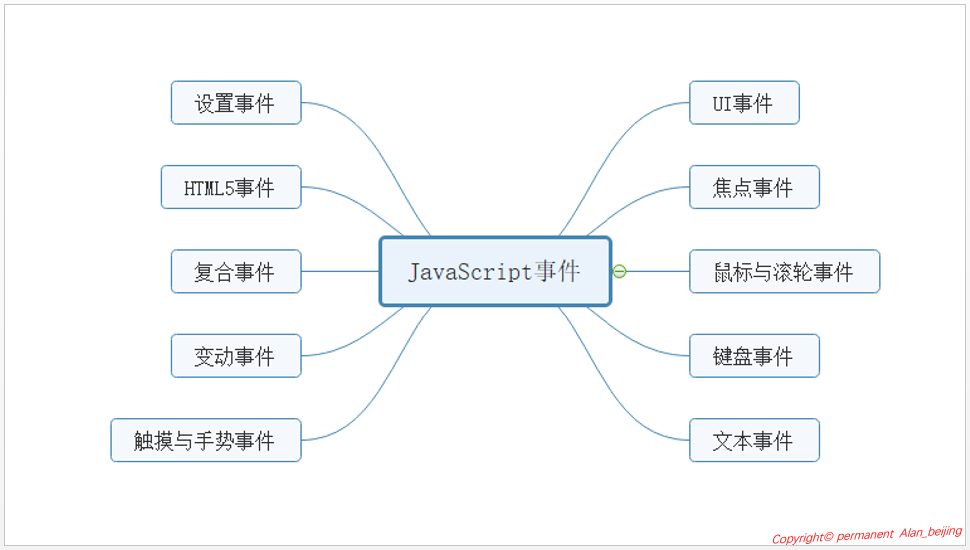
js事件处理程序按照种类来划分,大致可分为五大类:HTML事件处理程序,DOM0级事件处理程序,DOM2级事件处理程序,IE事件处理程序和跨浏览器事件处理程序。
尤其是DOM0,DOM2和IE事件处理程序,利用它们之间的差异化有效地解决浏览器差异问题,从而实现跨浏览器的兼容性问题。

(一)html事件处理程序
所谓html事件处理程序,就是在dom结构中嵌套js代码。在html中,元素支持的所有事件,都可以使用与相应事件处理程序同名的html特性来指定,这个特性的值应该是能执行的js代码。
如点击事件。
<body>
<!--html事件处理程序-->
<input type="button" value="请点击" onclick="alert('测试html事件处理程序!!')"/>
</body>
当然,一般不采用如上方法,常规的做法是,将js代码定义在目标元素外部。因此,与如上相同功能的定义为:
目标元素
<body>
<!--html事件处理程序-->
<input type="button" value="请点击" onclick="HtmlEventHandlerProc()"/>
</body>
外部js
<script>
function HtmlEventHandlerProc() {
alert('测试html事件处理程序!!');
}
</script>
Tip:
1.事件处理程序中的代码,能够访问全局作用域中的任何变量;
2.每个function()存在一个局部变量,即事件对象event,通过event变量,可以直接访问事件对象。
<body> <input type="button" value="请点击" onclick="alert(event.type)"/> </body>
执行结果

3.在函数内部,this值等于事件的目标元素。
<body>
<input type="button" value="请点击" onclick="alert(this.value)"/>
</body>
执行结果

this具有扩展作用域的功能,其功能相当于
function myfunction() {
with (document) {
with (this) {
//add your logic
}
}
}
如果当前元素是一个表单元素,则作用域还会包含访问表单元素(父元素)的入口。
function myfunction() {
with (document) {
with (this.form) {
with (this) {
//add your logic
}
}
}
}
这样做,有什么本质意义呢?当然是想让事件处理程序更快捷访问表单其他字段(无需引用表单元素就能访问)
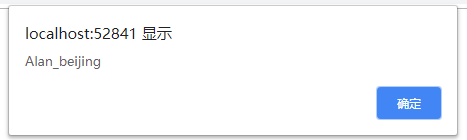
<form>
<input type="text" name="userName" value="Alan_beijing" />
<input type="button" value="测试表单元素" onclick="alert(userName.value)" />
</form>
执行结果
4.html事件处理程序存在哪些缺点?
缺点一:时差问题
缺点二:扩展的作用域链在不同浏览器中会导致不同结果
缺点三:html代码与js代码高度耦合
(二)DOM0级事件处理程序
DOM0级事件很好地解决了html和js代码强耦合的问题。
1.为元素绑定事件
|
1
2
3
4
|
var btn = document.getElementById('myBtn');btn.onclick = function () { alert('Clicked');} |
2.为元素解除事件
btn.onclick = null;
(三)DOM2级事件处理程序
DOM2级事件定义了两个方法来为目标元素绑定事件处理程序(addEventListener())和解除事件处理程序(removeEventListener()),所有节点中都包含这两个方法,并且他们都接收三个参数:
要处理的事件名,事件处理程序和一个布尔值(true表示是在捕获阶段进行,false表示在冒泡阶段进行)
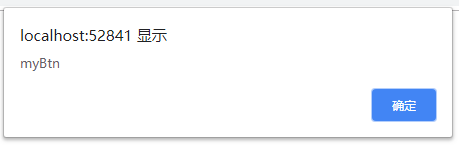
1.为事件添加click事件处理程序(冒泡阶段进行)
var btn = document.getElementById("myBtn");
btn.addEventListener("click", function () {
alert(this.id);
}, false);
执行结果:
2.添加多个事件处理程序
var btn = document.getElementById("myBtn");
btn.addEventListener("click", function () {
alert(this.id);
}, false);
btn.addEventListener("click", function myfunction() {
alert("添加的第二个事件处理程序");
}, false);
执行结果:
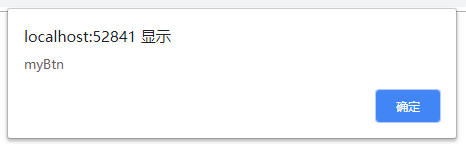

3 移除事件处理程序
通过addEventListener()添加的事件处理陈旭只能使用removeEventListener()来移除,移除时,传入的参数与添加的程序时使用的参数相同
(这意味着匿名函数不能通过removeEventListener()来删除)
匿名函数不能删除
var btn = document.getElementById("myBtn");
btn.addEventListener("click", function () {
alert(this.id);
}, false);
//不能删除,因为是匿名函数
btn.removeEventListener("click", function () {
alert(this.id);
}, false);
非匿名函数能删除
var btn = document.getElementById("myBtn");
var handler = function () {
alert(this.id);
};
btn.addEventListener("click", handler, false);
//删除事件处理程序
btn.removeEventListener("click", handler, false);
(四)IE事件处理程序
IE提供了两个方法来绑定和卸载事件处理程序,attachEvent()和detachEvent(),这两个方法均接收两个参数,即事件处理程序名称和事件处理程
序函数,并且在冒泡阶段添加(IE8及更早版本只支持冒泡)
1.为目标按钮添加绑定事件
var btn = document.getElementById("myBtn");
btn.attachEvent("onclick", function () {
alert("IE事件处理程序!!");
});
2.为目标按钮添加绑定事件
多个执行绑定事件的结果是倒过来的。
var btn = document.getElementById("myBtn");
btn.attachEvent("onclick", function () {
alert("IE事件处理程序1!!");
});
btn.attachEvent("onclick", function () {
alert("IE事件处理程序2!!");
});
3.为目标元素移除事件处理程序
注意:匿名事件处理程序是不能够移除的
var btn = document.getElementById("myBtn");
var handler = function () {
alert("IE事件处理程序");
};
//绑定事件
btn.attach("onclick", handler);
//移除事件
btn.detachEvent("onclick", handler);
(五)跨浏览器事件处理程序
在跨浏览器中,无非就是三种选择:DOM0级选择(不常用,基本被废弃),DOM2级选择和IE选择(不常用,IE8及以下版本)。
//定义EventUtil
var EventUtil = {
addHandler: function (element, type, handler) {
if (element.addEventListener) {
element.addEventListener(type, handler, false);
} else if (element.attachEvent) {
element.attachEvent("on" + type, handler);
}
},
removeHandler: function (element, type, handler) {
if (element.removeEventListener) {
element.removeEventListener(type, handler, false);
} else if (element.detachEvent) {
element.detachEvent("on" + type, handler);
} else {
element["on" + type] = null;
}
}
}
//调用
var btn = document.getElementById("myBtn");
var handler = function () {
alert("事件处理程序跨浏览器!!");
};
//绑定事件处理程序
EventUtil.addHandler(btn, "click", handler);
//移除事件处理程序
EventUtil.removeHandler(btn, "click", handler);
四 事件类型
内容相对比较简单,这里就暂且列举主要内容,若有需要,会在下篇文章论述。
五 事件对象及其事件委托
介于文章篇幅有限,暂且列举主要内容,代码部分将在下篇文章论述。

探索JavaScript数组奥秘
一 概述
JavaScript数组同后端语言一样,具有它自己的数据结构,归根结底,这种数据结构,本质就是一种集合。
在后端语言中(如java,.net等),数组是这样定义的:数组是用来存储相同数据类型的集合。这个定义,“相同数据类型”6个字限制了数据只能存储相同的数据类型,如int[]数组只能存储数字,而不能存储字符串,如下定义方式,是错误的,因为string
不属于整型
int[] arr = { 10, 20,"string" };
然而,在JavaScript中,数组的定义却是非常宽松的,这也决定了其能存储一切数据的特点。JavaScript数组具有如下特点
特点1:存储相同基本数据类型的数据;
特点2:存储不同基本数据类型的数据;
特点3:存储对象
这三个特点,我们可归结为一句话:JavaScript存储一切对象,而不像后端语言那样,只能存储相同数据类型。除此之外,JavaScript数组还提供了很多丰富的操作方法。如下为常用的操作方法。
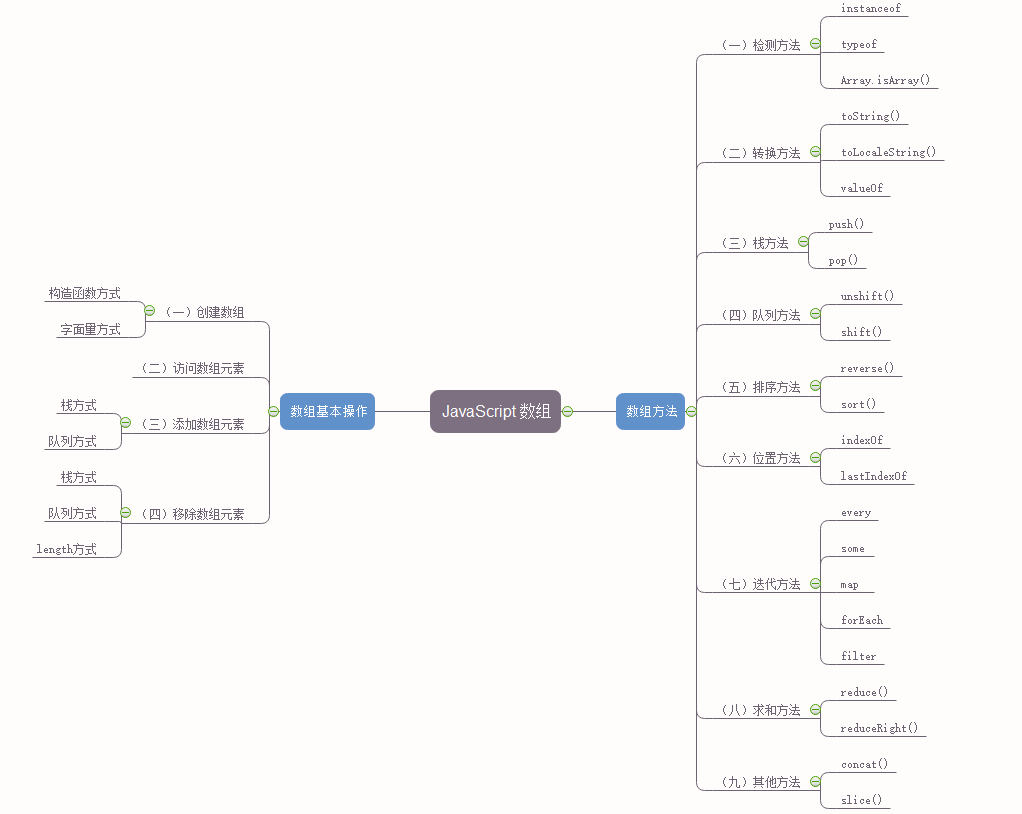
本篇文章将主要结合代码来论述JavaScript数组。
二 对数组的基本操作
(一)创建数组
第一种方式:构造函数方式
//第一种创建数组的方式:构造函数方式
var colors = new Array();//未知数组长度
//var colors = new Array(4);//已知数组长度
//var colors = new Array('green', 'yellow', 'white', 'red');//创建数组同时,给数组赋值
//var colors = Array();//在创建时,可以省略new关键字
第二种方式:字面量方式
//第二种创建数组方式:使用数组字面量
var colors = ['green', 'yellow', 'white', 'red'];
var name = [];//创建空数组
(二)访问数组
访问数组,通过数组的下标来访问
//创建数组
var colors = ['green', 'yellow', 'white', 'red'];
//输出索引值
for (var i = 0; i < colors.length; i++) {
alert(colors[i]);//green,yellow,white,red
}
提示:for...in...访问数组属性(索引),而不是数组属性值
//创建数组
var colors = ['green', 'yellow', 'white', 'red'];
//输出数组索引
for (var propAttr in colors) {
alert(propAttr);//0,1,2,3
}
(三)为数组添加元素
第一种方式:栈方式(后进先出,从数组尾部加入数据)
//创建数组
var colors = ['green', 'yellow', 'white', 'red'];
//第一种方式:栈方式
colors.push("orange");
for (var i = 0; i < colors.length; i++) {
alert(colors[i]);//green,yellow,white,red,orange
}
第二种方式:队列方式(先进先出,从数组头部加入数据)
var colors = ['green', 'yellow', 'white', 'red'];
colors.unshift('orange');
for (var i = 0; i < colors.length; i++) {
alert(colors[i]);//orange,green,yellow,white,red
}
(四)移除数组元素
第一种方式:栈方式(后进先出,从数组尾部移除数据)
//创建数组
var colors = ['green', 'yellow', 'white', 'red'];
//从尾部弹出数据
colors.pop();
for (var i = 0; i < colors.length; i++) {
alert(colors[i]);//green,yellow,white
}
第二种方式:队列方式(先进先出,从数据头部移除数据)
//创建数组
var colors = ['green', 'yellow', 'white', 'red'];
//从头部移除数据
colors.shift();
for (var i = 0; i < colors.length; i++) {
alert(colors[i]);//yellow,white,red
}
第三种方式:length方式(借助length属性可访问性来操作)
//创建数组
var colors = ['green', 'yellow', 'white', 'red'];
//从尾部移除数据,与pop()一样
colors.length = 3;
for (var i = 0; i < colors.length; i++) {
alert(colors[i]);//green,yellow,white
}
三 数组方法
(一)检测方法
数组检测方式,可通过typeof,instranceof和Array.isArray()来检测。
(二)转换方法
所有对象都具有toLocaleString(),toString()和valueOf()三个方法,数组也如此。
1.toString()
toString()将数据的每个属性值转化为对应的字符串,然后再输出转换后的字符串值。
var colors = ['red','green','yellow'];
alert(colors.toString());//red,green,yellow
而下列代码与如上代码是一样的,因为alert()接收的是字符串,所以会在后台调用toString()方法
var colors = ['red','green','yellow'];
alert(colors);//red,green,yellow
2.valueOf()
valueOf()方法同toString()方法一样,也是返回数组的字符串
var colors = ['red', 'green', 'yellow'];
alert(colors.valueOf());//red,green,yellow
3.toLocaleString()
toLocaleString()返回数组的字符串形式。
var colors = ['red', 'green', 'yellow'];
alert(colors.toLocaleString());//red,green,yellow
4 三者之间关系
关系1:当不显示指出调用哪个方法时(toString(),toLocaleString()和valueOf()),默认调用每个属性的toString();
关系2:当显示地指出调用哪个方法时,就调用每个属性的该方法;
关系3:关于valueOf问题,暂留
var person1 = {
toString: function () {
return "Alan";
},
toLocaleString: function () {
return "Alan_beijing";
},
valueOf: function () {
return "valueOf1";
}
};
var person2 = {
toString: function () {
return "Alan1";
},
toLocaleString: function () {
return "Alan_beijing1";
}
}
var people = [person1, person2];
alert(people.toString());//Alan,Alan1
alert(people.toLocaleString());//Alan_beijing,Alan_beijing1
alert(people.valueOf());//Alan,Alan1
alert(people);//Alan,Alan1
(三)栈方法
栈是一种数据结构,其算法为:LIFO(Last input First out)后进先出,其两个核心方法为push()和pop();
1.push()
push()表示将数据压入栈中,且放在栈的最后位置,即从栈的尾部压入数据。对于数组,则在数组的尾部加入数据,操作的顺序为:先把数组length+1,再压入数据。
var arr = [10, 20, 30];
arr.push('新加入的数据');
alert(arr.toString());//10,20,30,新加入的数据
2.pop()
push()表示将数据从栈中弹出,且从栈的最后位置弹出。对于数组,则在数组的尾部弹出数据,操作的顺序为:先弹出数据,再数组length-1
var arr = [10, 20, 30];
arr.pop();
alert(arr.toString());//10,20
(四)队列
队列是一种数据结构,其算法为:FIFO(First input First out)后进先出,其两个核心方法为unshift()()和shift();
1.unshift()
unshift()表示从队列头部加入数据。对于数组,则从数组索引最小位置加入数据,操作顺序为:先将数length+1,再将当前数组属性值往后移动1个位置,最后将新数据添加到索引0处。
var arr = [10, 20, 30];
arr.unshift(40);
alert(arr.toString());//40,10,20,30
2.shift()
shift()表示从队列头部移除数据。对于数组,则从数组索引最小位置移除数据。
var arr = [20, 30];
arr.shift();
alert(arr.toString());//30
(五)排序方法
在js数组中,两个重要的重排序方法:reverse()和sort()
1.reverse()
reverse(),顾名思义,逆序方法。
var arr = [1,2,3,4,5];
alert(arr.reverse());//5,4,3,2,1
2.sort()
sort()是比较灵活的排序方法了,支持自定义排序规则,默认排序为升序
默认为升序
var arr = [3, 1, 2, 5, 4];
alert(arr.sort());//1,2,3,4,5
自定义排序规则
var arr = [3, 1, 2, 5, 4];
alert(arr.sort(Compare));//1,2,3,4,5
//自定义排序规则:正序
function Compare(value1, value2) {
if (value1 > value2) {
return 1;
} else if (value1 < value2) {
return -1;
} else {
return 0;
}
}
(六)位置方法
js数组提供了两个位置方法:indexof()和lastIndexOf()
indexOf()表示首次满足条件的位置;而lastIndexOf()则表示最后满足条件的位置
var arr = [20, 30,20,40,10];
alert(arr.indexOf(20)); //0
alert(arr.lastIndexOf(20));//2
(七)迭代方法
ECMAScript5提供了5个迭代方法:every(),filter(),forEach(),map()和some()
这个五个方法,均接收2个参数。
1.every()
对数组中的每项运行给定函数,如果该函数对每一项都返回ture,则返回true,否则返回false.
//every
var num = [1, 2, 3, 4, 5, 4, 3, 2, 1];
var everyResult = num.every(function (item, index,array) {
return item>2
});
alert(everyResult);//fasle
2.some
对数组中的每项运行给定函数,如果该函数对任意一项返回ture,则返回true,否则返回false
//some
var num = [1, 2, 3, 4, 5, 4, 3, 2, 1];
var someResult = num.some(function (item, index, array) {
return item > 2;
});
alert(someResult);//true
3.filter
对数组中的每项运行给定函数,返回该函数会返回true的项组成的数组
//filter
var num = [1, 2, 3, 4, 5, 4, 3, 2, 1];
var filterResult = num.filter(function (item, index, array) {
return item > 2;
});
alert(filterResult);//3,4,5,4,3
4.map
对数组中的每项运行给定函数,返回每次函数调用的结果组成的数组
//map
var num = [1, 2, 3, 4, 5, 4, 3, 2, 1];
var mapResult = num.map(function (item, index, array) {
return item * 2;
});
alert(mapResult);//2,4,6,8,10,8,6,4,2
5.forEach
对数组中的每项运行给定函数。注意,该方法没返回值
//forEach
num.forEach(function (item, index, array) {
//执行想要执行的操作
});
(八)求和方法
ECMAScript提供了2个缩减方法:reduce()和reduceRight()
reduce和reduceRight,相当于.net的斐波拉列数列,计算算法为:f(n)=f(n-1)+f(n-2);
1.reduce
reduce计算数组时,按照从左到右的顺序
var values = [1, 2, 3, 4, 5];
var sum = values.reduce(function (prev, cur, index, array) {
return prev + cur;
});
alert(sum);//15
2.reduceRight
reduceTight计算数组时,从右到左顺序
var values = [1, 2, 3, 4, 5];
var sum1 = values.reduceRight(function (prev, cur, index, array) {
return prev + cur;
});
alert(sum1);//15
(九)其他方法
ECMAScript为数组操作提供了很多方法,如concat()和slice()
1.concat()
concat()方法是将两个对象合并,从而生成新对象,合并同时,不会改变原来对象的值,只是做简单的拷贝
var color1 = ['red', 'green', 'yellow'];
var color2 = ['white', 'blue'];
//添加数组
var concatColor = color1.concat(color2);
alert(concatColor);//red,green,yellow,white,blue
//添加单个值
var concatSingelColor = color1.concat('orange');
alert(concatSingelColor);//red,green,yellow,orange
//不添加值,只是简单copy
var concatColor1 = color1.concat();
alert(concatColor1);//red,green,yellow
2.slice
slice()方法用于从目标数据中截取新数据,不会改变被截取对象的值。
var color1 = ['red', 'green', 'yellow'];
//不传递参数:表示截取整个数组
var color2 = color1.slice();
alert(color2);//red,green,yellow
//传递一个参数:表示从该位置处开始截取数据,直到数组最后一个数
var color3 = color1.slice(1);
alert(color3);//green,yellow
//传递2个参数:第一个参数表示从该位置开始截取,第二个参数减1表示所截数据的最后位置
var color4 = color1.slice(1, color1.length);
alert(color4);//green,yellow
【详解JavaScript系列】JavaScript之函数(一)
在编程语言中,无论是面向过程的C,兼备面过程和对象的c++,还是面向对象的编程语言,如java,.net,php等,函数均扮演着重要的角色。当然,在面向对象编程语言JavaScript中(严格来说,JS属于弱面向对象编程语言),函数(function)更扮演着极其重要的角色和占有极其重要的地位。在本篇文章中,不论述什么是JS,JS解决什么问题等之类问题,而是重点阐述JS中的函数(function)。
一 JavaScript函数
(一)何为函数
关于函数的定义,我们先从两个角度来思考:数学角度和编程语言角度。
1.数学角度:在数学领域,关于“函数”二字,再熟悉不过,如三角函数,反三角函数,幂函数,对数函数,指数函数,微积分函数等;
2.编程角度:在编程领域,大家最熟悉且最先接触的应该是"Main函数"了,除此外,如日期函数(Date),数学函数(Math)等,当然除了内置函数外,还包括用户自定义函数;
综合1,2点,可以将函数定义如下:
函数是解决某类问题的集合,是某类问题的高度抽象,它具有一定的通用性和复用性。
(二)定义函数
在Javascript中,存在三种经典的函数定义方式:函数声明式,函数表达式和函数构造式
1.函数声明式
1 //定义两个数相加函数
2 function AddNum(num1, num2) {
3 return num1 + num2;
4 }
注意:函数声明式,不能用匿名函数,如下方式定义错误的
1 function (num1, num2) {
2 return num1 + num2;
3 }
2.函数表达式
1 //定义两个数相加函数
2 var AddFun=function AddNum(num1, num2) {
3 return num1 + num2;
4 }
注意:函数表达式一般用匿名函数,因为调用时,不用函数名,因此,如上调用也可写成如下:
1 var AddFun = function(num1, num2) {
2 return num1 + num2;
3 }
3.函数构造式
1 var sum = new Function('num1', 'num2', 'return num1 + num2')
2 console.log(sum(10,20));//30
(三)函数调用
在JavaScript中,函数的调用采用“函数名(参数)”的格式来进行调用。
需要注意的是,JavaScript函数调用与后端语言函数调用(如java,.net等)存在细微差别,即JavaScript没有函数重载,参数的参数个数,由实参决定,而不是由形参决定。
1.声明式调用
调用方式一:一般调用
1 //定义两个数相加函数
2 function AddNum(num1, num2) {
3 return num1 + num2;
4 }
5
6
7 console.log(Add(10,20));//30
调用方式二:自调用
1 (function AddNum(num1, num2) {
2 console.log(num1 + num2);
3 })(10,20);//30
注意:自调用一般用匿名函数,因为在调用时,不需要函数名,因此,也可写成如下方式:
1 (function (num1, num2) {
2 return num1 + num2;
3 })(10, 20);//30
2.表达式调用
1 //定义两个数相加函数
2 var AddFun = function (num1, num2){
3 return num1 + num2;
4 }
5
6 console.log(AddFun(10, 20));//30
二 函数变量
在JavaScript编程语言中,变量的定义是通过var关键字来定义的(若变量不通过var定义,则为全局变量,但不推荐这么做),与其他编程语言一样,变量也分为两大类,即局部变量和全局变量。
(1)局部变量:作用域为其所在的函数;
(2)全局变量:作用域为整个过程;
(3)变量作用域:JS中的变量作用域是通过this指针,从当前的作用域开始,从当前作用域由内向外查找,直到找到位置,这里分为几个逻辑:
a.从当前作用域由内向外查找,若找到,就停止查找,否则,继续查找,直到查到window全局作用域为止;
b.当内部作用域变量名与外部作用域变量名相同时,内部作用域的覆盖外部作用域。
我们来看一个例子:
1 var dateTime='2018-09-16';
2 function GetUserInfo(){
3 var age=120;
4 var name="Alan_beijing";
5 function Say(){
6 var name="老王";
7 var address="shanghai";
8 console.log(address+"-"+name+"-"+age+"-"+dateTime);//shanghai-老王-2018-06-05
9 }
10 return Say();
11 }
12
13
14 GetUserInfo();//shanghai-老王-120-2018-09-16
来分析一下变量及其作用域:
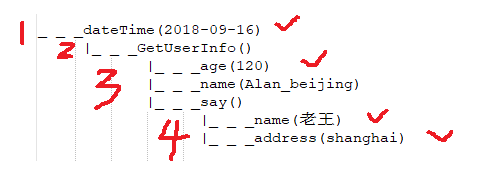
如上图,有4个作用域,当函数执行如下语句时,发生如下过程:
1 console.log(address+"-"+name+"-"+age+"-"+dateTime);
a.js当前this环境作用域为4作用域;
b.this指针寻找变量:addresss,name,age,dateTime,从当前作用域向外作用域逐层寻找,直到寻找到变量为止,若寻找到最外层作用域任然没找到,则会出错,提示该变量未声明;
c.当内外层变量相同时,内层变量覆盖外层变量,如4作用域的name覆盖3作用域的name;
三 函数声明式定义存在的问题
在js中,存在声明提前问题,看看如下例子。
1 var globleName="Alan_beijing";
2 function Say(){
3 console.log(localName); // undefined,不报错,是因为变量声明提前
4 var localName="Alan";
5 console.log(localName);// Alan
6 }
看过如上代码,你可能会问,函数执行到console.log(localName); 时,应该报错,因为localName未定义。
如果在后端语言,如java,.net中,可能会报错,但是在js中,却不会,不报错的原因是:在js中存在声明提前。
如上代码相当于如下代码:
1 var globleName="Alan_beijing";
2 function Say(){
3 var localName;
4 console.log(localName);
5 localName="Alan";
6 console.log(localName);
7 }
四 函数几大关键点
1.匿名函数
匿名函数,顾名思义,就是没名字的的函数,我们来看看如下两个例子:
函数表达式
1 //定义两个数相加函数
2 var AddFun=function (num1, num2) {
3 return num1 + num2;
4 }
立即执行函数
(function AddNum(num1, num2) {
console.log(num1 + num2);
})(10,20);//30
从如上,不难看出,匿名函数主要用域函数表达式和立即执行函数。
2.闭包
闭包的根源在于变量的作用域问题。
我们先来考虑这样一个问题,假设在面向对象编程语言中,某个方法的变量被定义为私有变量,其他函数要获取访问该变量,.net怎么处理?
方法一:构造函数
方法二:单例模式
同样地,在js中,同样存在外部函数调用内部函数变量问题,js运用的技术就叫做闭包。
所谓闭包,就是将不可访问的变量作为函数返回值的形式返回来,从而实现函数外部访问函数内部变量目的。
1 //闭包
2 function GetName() {
3 var name = "Alan_beijing";
4 var age = function () {
5 var age = 30;
6 return age;
7 }
8 return name + age;
9 }
3.js多态问题(重载问题)
在面向对象编程语言,如.net中,实现多态的方式大致有如下:
a.接口
b.抽象类
c.虚方法
d.方法重载
然而,在js中,没有面向对象之说(OO),那么js是如何实现多态的呢?根据方法实际传递的参数来决定。
1 //重载
2 function SetUserInfo(userName, age, address, tel, sex) {
3 console.log(arguments.length);//4
4 }
5
6 SetUserInfo('Alan_beijing',44,'china-shanghai','xxxx');
从如上可以看出,传递多少个参数,就接收多个参数,如果在现象对象编程语言中实现该功能,至少需要写一堆代码,这也是体现js强大之一。
4.递归
来看看一个递归阶乘函数
1 //递归
2 function factorial(num) {
3 if (num < 1) {
4 return 1;
5 } else {
6 return num * arguments.callee(num-1);
7 }
8 }
如果是.net,我们一般会这样写
1 //递归
2 function factorial(num) {
3 if (num < 1) {
4 return 1;
5 } else {
6 return num * factorial(num-1);
7 }
8 }
然而,这样写,却会存在异常情况
1 var factorial1 = factorial; 2 factorial = null;//将factorial变量设置为null 3 console.log(factorial1(4));//出错
5.原型和原型链
面向对象编程语言的显著特征之一是面向对象,然而,在js中,没有对象,那么js是如何面向对象的功能的呢(封装,继承,多态)?当然是通过原型和原型链来实现的。
C# Oracle.ManagedDataAccess 批量更新表数据
这是我第一次发表博客。以前经常到博客园查找相关技术和代码,今天在写一段小程序时出现了问题,
但在网上没能找到理想的解决方法。故注册了博客园,想与新手分享(因为本人也不是什么高手)。
vb.net和C#操作Oracle数据库已经用了N多年了。由于是做工程自动化项目的,业主只对软件的功能和
界面是否友好来判定成果的好坏。所以一直都是采用直接OracleCommand.ExecuteNonQuery(sqlString,conn)
的方式很直白的Insert、update和delete数据库表的。由于工程项目并没有很高的实时性,所以......
最近手头没太多事情,就在博客园逛逛。看到了ODP.NET,发现了自己有点落伍了,于是照猫画虎的练练。
在Insert时顺风顺水的,但Update时出现了“ORA-01722: 无效数字”。各种找问题,网上查资料无果。
测试表只有两个字段,varchar2和number。问题代码如下:
using Oracle.ManagedDataAccess.Client;
private void UpdateTable()
{
int valueStart = (int)NudStartValue.Value;
int valueCount = (int)NudValueCount.Value;
int returnValue = 0;
int[] columnValue = new int[valueCount];
string[] columnStr = new string[valueCount];
string sql = string.Empty;
OracleParameter[] parameters = new OracleParameter[]
{
new OracleParameter(":sname", OracleDbType.Varchar2),
new OracleParameter(":svalue",OracleDbType.Int32)
};
parameters[0].Direction = ParameterDirection.Input;
parameters[1].Direction = ParameterDirection.Input;
for ( int i = 0 ; i < valueCount ; i++ )
{
columnStr[i] = "No:" + ( i + valueStart ).ToString();
columnValue[i] = i + valueStart + 100;
}
parameters[0].Value = columnStr;
parameters[1].Value = columnValue;
sql = "update DIST_TEST set SVALUE=:svalue where SNAME=:sname";
returnValue = db.RunUpdateSQL(sql, parameters, valueCount);
MessageBox.Show(returnValue.ToString());
}
public int RunUpdateSQL(string sqlStr,OracleParameter[] parameters,int paraCount)
{
int returnValue = 0;
try
{
Open();
OracleCommand cmd = new OracleCommand()
{
Connection = Conn,
ArrayBindCount=paraCount,
CommandText=sqlStr,
CommandTimeout=240
};
cmd.Parameters.AddRange(parameters);
returnValue=cmd.ExecuteNonQuery();
cmd.Dispose();
}
catch(Exception ex)
{
Console.WriteLine(ex.ToString());
}
return returnValue;
}
解决方法:将parameters的元素按sqlStr的顺序更改一下OK了。
private void UpdateTable()
{
int valueStart = (int)NudStartValue.Value;
int valueCount = (int)NudValueCount.Value;
int returnValue = 0;
int[] columnValue = new int[valueCount];
string[] columnStr = new string[valueCount];
string sql = string.Empty;
OracleParameter[] parameters = new OracleParameter[]
{
new OracleParameter(":svalue",OracleDbType.Int32),
new OracleParameter(":sname", OracleDbType.Varchar2)
};
parameters[0].Direction = ParameterDirection.Input;
parameters[1].Direction = ParameterDirection.Input;
for ( int i = 0 ; i < valueCount ; i++ )
{
columnStr[i] = "No:" + ( i + valueStart ).ToString();
columnValue[i] = i + valueStart + 100;
}
parameters[0].Value = columnValue;
parameters[1].Value = columnStr;
sql = "update DIST_TEST set SVALUE=:svalue where SNAME=:sname";
returnValue = db.RunUpdateSQL(sql, parameters, valueCount);
MessageBox.Show(returnValue.ToString());
}
注意上面的代码,第一个出现的是:svalue,第二个出现的是:sname。OracleParameter[]按这个顺序添加就OK了。
其实现在问题是解决了,但还没能理解,:sname和:svalue是对应的parameter.value的,为何一定要按照update语句中
变量的顺序呢。希望高手提示一下,多谢!
希望能帮到遇到同样问题的童鞋们。
VS2015常用快捷键总结
生成解决方案 F6,生成项目Shift+F6
调试执行F5,终止调试执行Shift+F5
执行调试Ctrl+F5
查找下一个F3,查找上一个Shift+F3
附加到进程Ctrl+Alt+P,逐过程F10,逐语句执行F11
切换断点F9(添加或取消断点)
运行至光标处Ctrl+F10
跳出当前方法Shift+F11
新建解决方案:Ctrl+Shift+N
打开解决方案:Ctrl+Shift+O
保存文件Ctrl+S,保存所有文件Ctrl+Shift+S
查看解决方案窗口Ctrl+W,Ctrl+S
查看属性窗口Ctrl+W,Ctrl+P
错误列表显示Ctrl+W,Ctrl+E
输出列表显示Ctrl+W,Ctrl+O
书签窗口Ctrl+W,B
切换书签Ctrl+B,T
切换到下一个书签Ctrl+B,N
切换到上一个书签Ctrl+B,P
清除书签Ctrl+B,C
活动窗口切换Ctrl+Tab
浏览器窗口Ctrl+W,W
断点窗口Ctrl+D,B
即使窗口Ctrl+D,I
工具箱Ctrl+W,Ctrl+X
全屏切换Shift+Alt+Enter,向后导航Ctrl+-,向前导航Ctrl+Shift+-
项目中添加类Shift+Alt+C
项目中添加新项Ctrl+Shift+A
项目中添加现有项Shift+Alt+A
查找Ctrl+F,在文件中查找Ctrl+Shift+F
渐进式搜索Ctrl+I,反式渐进式搜索Ctrl+Shift+I
替换Ctrl+H,在文件中替换Ctrl+Shift+H
转到行号Ctrl+G
剪切板循环Ctrl+Shift+V 注:在剪贴板中可以循环保存20项,您可以任意的调用你剪切过的内容,只要不断的按Ctrl+Shift+V键直到找到需要的那一项
游标移动一个单词 Ctrl+左右箭头
滚动代码屏幕,但不移动光标位置Ctrl+上下箭头
删除当前行Ctrl+Shift+L
隐藏或展开当前嵌套的折叠状态 Ctrl+M,M
所有隐藏或展开嵌套Ctrl+M,L
折叠到定义Ctrl+M,O
切换显示空白Ctrl+E,S
选择矩形文本Shift+Alt+方向键
全变为大写:Ctrl+Shift+U 全变为小写Ctrl+U
强制智能感知 Ctrl+J
查看方法参数信息Ctrl+Shift+空格
查看当前代码快速信息Ctrl+K,I
注释选中行Ctrl+K,C或Ctrl+E,C
取消注释行Ctrl+K,U或者Ctrl+E,U
插入代码段Ctrl+K,X
插入外侧代码段Ctrl+K,S
转到定义F12
生成方法存根,光标定位在调用的方法上,按Shift+Alt+F10
显示查看实现接口方法,光标定位在类要实现的接口上,按Shift+Alt+F10
查看所有引用,Ctrl+K,R
查看调用层次Ctrl+K,T
除上述这些常用的快捷键外,如果开发人员想查看系统快捷或扩展自己的快捷键,可以打开vs-【工具】-【选项】
在窗口中选中【环境】-【键盘】
搜索想要添加的快捷键功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号