FPGA的串口 ram TFT传图实验
串口接收图片数据,传到RAM里面,然后通过读取RAM传到TFT上显示
下面一张是我画的框图,一张是网上截图的差不多的,都是一个意思。
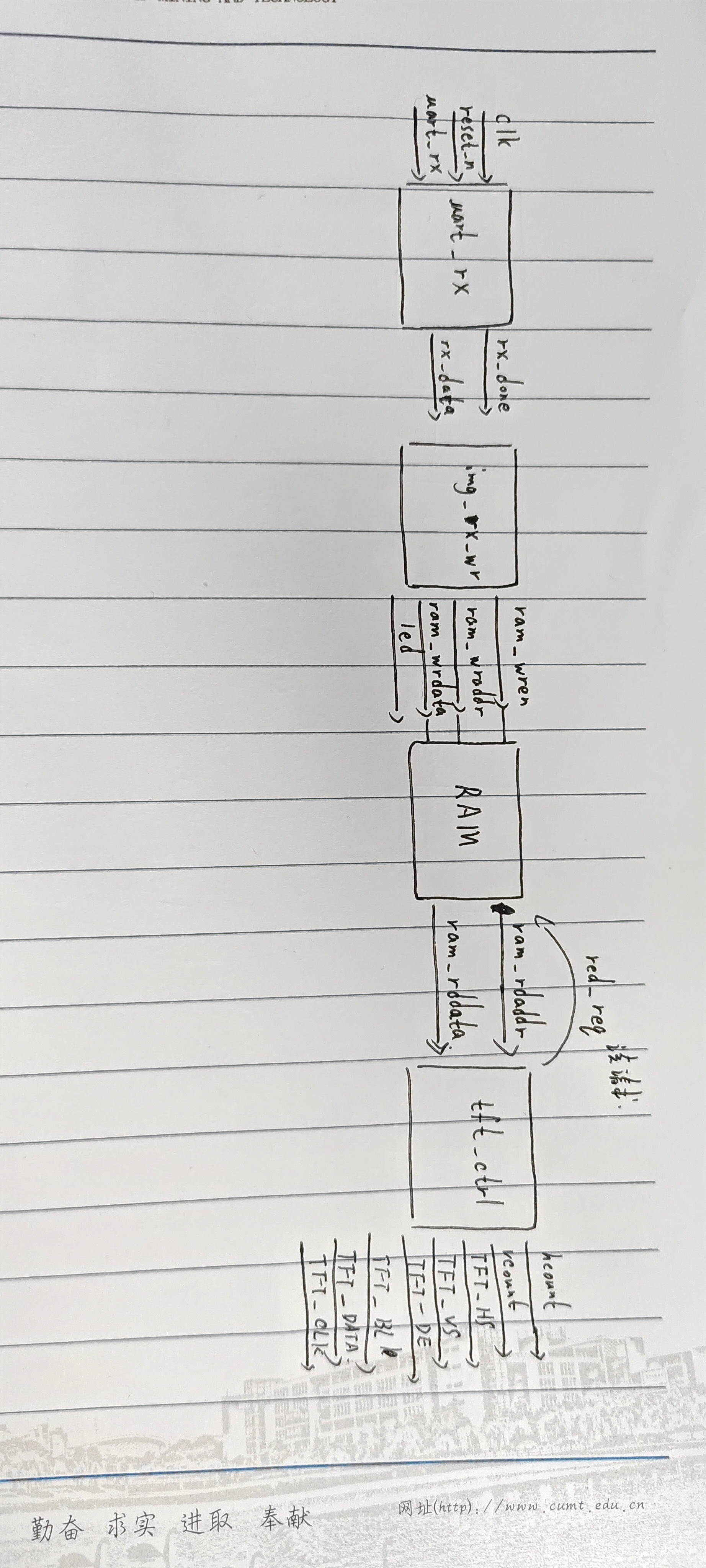
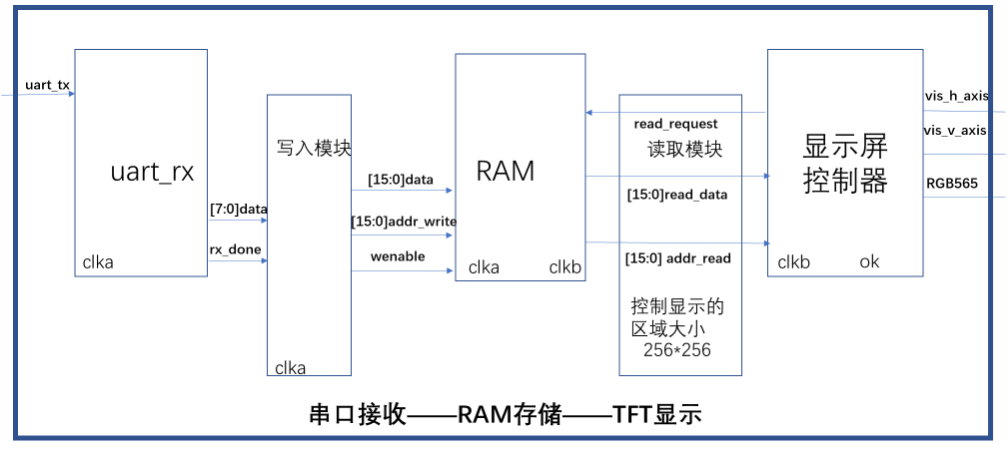
顶层文件
module uart_ram_tft(
clk,
reset_n,
uart_rx,
tft_data_out, //实际输出的信号值
tft_hs, //行使能
tft_vs, //列使能
tft_black, //背光led高电平
tft_de,
tft_clk,
led
);
input clk;
input reset_n;
input uart_rx;
output [15:0] tft_data_out; //实际输出的信号值
output tft_hs; //行使能
output tft_vs; //列使能
output tft_black; //背光led高电平
output tft_de;
output tft_clk;
output led;
wire rx_done;
wire [7:0] rx_data;
wire ram_wren ;
wire [15:0] ram_wraddr;
wire [15:0] ram_wrdata;
reg [15:0] ram_rdaddr; //读地址
wire clk_106m;
wire [15:0] ram_rddata;
wire [11:0] hcount,vcount;
wire ram_data_en;
wire [15:0] tft_data_in;
wire locked;
clk_wiz_0 instance_name(
// Clock out ports
.clk_out1(clk_106m), // output clk_out1
// Status and control signals
.reset(!reset_n), // input reset
.locked(locked), // output locked
// Clock in ports
.clk_in1(clk)
); // input clk_in1
uart_byte_rx uart_byte_rx_inst(
.clk(clk),
.reset_n(reset_n),
.uart_rx(uart_rx),
.rx_done(rx_done),
.rx_data(rx_data)
);
img_rx_wr img_rx_wr_inst (
.clk (clk ),
.reset_n (reset_n ),
.rx_data (rx_data ),
.rx_done (rx_done ),
.ram_wren (ram_wren ),
.ram_wraddr (ram_wraddr),
.ram_wrdata (ram_wrdata),
.led (led )
);
blk_mem_gen_0 your_instance_name (
.clka(clk), // input wire clka
.ena(1), // input wire ena
.wea(ram_wren), // input wire [0 : 0] wea
.addra(ram_wraddr), // input wire [15 : 0] addra
.dina(ram_wrdata), // input wire [15 : 0] dina
.clkb(clk_106m), // input wire clkb
.enb(1), // input wire enb
.addrb(ram_rdaddr), // input wire [15 : 0] addrb
.doutb(ram_rddata) // output wire [15 : 0] doutb
);
tft_ctrl tft_ctrl_inst(
.clk_106m(clk_106m), //1904*932*60hz = 106,471,680HZ = 106.5Mhz 时钟IP核只能到这个点
.reset_n(reset_n),
//vga
.data_req(data_req),
.tft_data_in(tft_data_in), //想要输入的信号值
.tft_data_out(tft_data_out), //实际输出的信号值
.hs_count(hcount), //行计数
.vs_count(vcount), //列计数
.tft_hs(tft_hs), //行使能
.tft_vs(tft_vs), //列使能
.tft_de(tft_de), //数据使能信号
.tft_black(tft_black), //背光高电平led
.tft_clk(tft_clk)
);
wire data_req;
//ram当中存储的图像是256*256的像素矩阵
always @(posedge clk_106m or negedge reset_n)
if(!reset_n)
ram_rdaddr <= 0;
else if(ram_data_en)
ram_rdaddr <= ram_rdaddr + 1'd1;
assign ram_data_en = data_req && (hcount >= 272 && hcount < 528) && (vcount >= 112 && vcount < 368);
assign tft_data_in = ram_data_en? ram_rddata:0;
endmodule顶层模块例化中,时钟IP核需要产生33.3M的时钟,RAM简单双端口,A端口写入,B端口读出。

在例化RAM的时候,我就在想这个B端口的读地址,按道理应该是input,因为是外界TFT读出RAM里面的数据地址和数据,而对于RAM来说,就是input
所以上面我的框图中的B端口的地址方向应该箭头朝向RAM
而在TFT_CTRL的端口里面,没有对读地址的例化,所以在顶层文件里面对读地址进行赋值分析。
//ram当中存储的图像是256*256的像素矩阵
always @(posedge clk_106m or negedge reset_n)
if(!reset_n)
ram_rdaddr <= 0;
else if(ram_data_en)
ram_rdaddr <= ram_rdaddr + 1'd1;
assign ram_data_en = data_req && (hcount >= 272 && hcount < 528) && (vcount >= 112 && vcount < 368);
assign tft_data_in = ram_data_en? ram_rddata:0;这边是通过ram_data_en数据,满足TFT请求,且在TFT的中央选取256*256的区域显示图像。
这是实际的显示图像的区域,在这个区域使能,然后开始读地址,累加地址。
且通过实际图像显示使能,开始将RAM的数据赋值给tft的预输入。
通过这几步完成读取RAM数据并显示。
tft控制(修改了时序)
module tft_ctrl(
clk_106m, //1904*932*60hz = 106,471,680HZ = 106.5Mhz 时钟IP核只能到这个点
//这边其实是33M,上面的106M是我给1440*900的VGA显示器适配的
//时钟IP核输出33.3M
reset_n,
//vga
data_req, //读数据请求,这个是VGA这边的,请求RAM那边,时序不一样,需要打拍
tft_data_in, //想要输入的信号值
tft_data_out, //实际输出的信号值
hs_count, //行计数
vs_count, //列计数
tft_hs, //行使能
tft_vs, //列使能
tft_de, //数据使能信号
tft_black, //背光高电平led
tft_clk
);
input clk_106m;
input reset_n;
input [15:0] tft_data_in; //8位 R G B
output reg data_req;
output reg [15:0] tft_data_out;
output reg [11:0] hs_count; //实际图像区域的像素计数
output reg [11:0] vs_count;
output tft_hs;
output tft_vs;
output tft_de;
output tft_clk;
output tft_black;
// hs_whole = 1904;
// hs_front_porch = 80;
// hs_sync_pulse = 152;
// hs_real_data = 1440
// hs_back_porch = 232
// parameter hs_whole = 1904;
// parameter hs_data_begin = 384; //hs_sync_porch + hs_back_porch
// parameter hs_sync_pulse = 152;
// parameter hs_data_end = 1824; //hs_data_begin + hs_real_data
// parameter vs_whole = 932;
// parameter vs_data_begin = 31; //hs_sync_porch + hs_back_porch
// parameter vs_sync_pulse = 3;
// parameter vs_data_end = 931; //hs_data_begin + hs_real_data
parameter hs_whole = 1056;
parameter hs_data_begin = 216;
parameter hs_sync_pulse = 128;
parameter hs_data_end = 1016;
parameter vs_whole = 525;
parameter vs_data_begin = 27;
parameter vs_sync_pulse = 2;
parameter vs_data_end = 515;
reg [11:0] hs_count_r; //行列像素计数
reg [11:0] vs_count_r;
//行计数到最大值清零
always @(posedge clk_106m or negedge reset_n)
if(!reset_n)
hs_count_r <= 0;
else if(hs_count_r == hs_whole - 1)
hs_count_r <= 0;
else
hs_count_r <= hs_count_r + 1'd1;
//列计数到行计数一行结束,到最大值清零
always @(posedge clk_106m or negedge reset_n)
if(!reset_n)
vs_count_r <= 0;
else if(hs_count_r == hs_whole - 1) begin
if(vs_count_r == vs_whole - 1)
vs_count_r <= 0;
else
vs_count_r <= vs_count_r + 1'd1;
end
else
vs_count_r <= vs_count_r;
//读数据请求
always @(posedge clk_106m)
data_req <= ((hs_count_r >= hs_data_begin) && (hs_count_r < hs_data_end )
&& (vs_count_r >= vs_data_begin) && (vs_count_r < vs_data_end)) ? 1'b1:1'b0;
reg tft_de_s0;
reg tft_de_s1;
always @(posedge clk_106m) begin
tft_de_s0 <= data_req;
tft_de_s1 <= tft_de_s0;
end
assign tft_de = tft_de_s1;
always @(posedge clk_106m) begin
hs_count = (data_req)?(hs_count_r - hs_data_begin):12'd0;
vs_count = (data_req)?(vs_count_r - vs_data_begin):vs_count;
//列的实际图像的计数,保持,不然仿真会记一个数,变0一次
end
always @(posedge clk_106m) begin
tft_data_out = (data_req)?tft_data_in:16'h0000;
end
reg tft_hs_s0;
reg tft_hs_s1;
always @(posedge clk_106m) begin
tft_hs_s0 <= (hs_count_r <= hs_sync_pulse)?1'b0:1'b1;
tft_hs_s1 <= tft_hs_s0;
end
assign tft_hs = tft_hs_s1;
reg tft_vs_s0;
reg tft_vs_s1;
always @(posedge clk_106m) begin
tft_vs_s0 <= (vs_count_r <= vs_sync_pulse)?1'b0:1'b1;
tft_vs_s1 <= tft_vs_s0;
end
assign tft_vs = tft_vs_s1;
// assign tft_hs = (hs_count_r <= hs_sync_pulse)?1'b0:1'b1;
// assign tft_vs = (vs_count_r <= vs_sync_pulse)?1'b0:1'b1;
// assign tft_data_out = (tft_de)?tft_data_in:24'h000000;
// assign hs_count = (tft_de)?(hs_count_r - hs_data_begin):12'd0; //实际的显示图像计数
// assign vs_count = (tft_de)?(vs_count_r - vs_data_begin):12'd0;
assign tft_clk=clk_106m;
assign tft_black = 1;
endmodule这边tft_ctrl的代码修改了一点时序,将一些阻塞赋值的换成了非阻塞赋值,因为TFT这边的数据请求,用的TFT这边的时钟是33M的,而RAM这边用的50M时钟,两边是异步信号
所以需要打拍,打两拍,这个已经很熟悉了。
always @(posedge clk_106m)
data_req <= ((hs_count_r >= hs_data_begin) && (hs_count_r < hs_data_end )
&& (vs_count_r >= vs_data_begin) && (vs_count_r < vs_data_end)) ? 1'b1:1'b0;
这个data_req就是请求,在TFT显示的图像实际输出位置,发起请求。
tft_hs和tft_vs的行列使能,也需要打拍。


本文来自博客园,作者:祈愿树下,转载请注明原文链接:https://www.cnblogs.com/cjl520/p/18089033

 浙公网安备 33010602011771号
浙公网安备 33010602011771号