树Hash的一些常用姿势
Preface
树Hash,是一种常用的用于判断树是否同构的算法
所谓两棵树同构,即通过给其中一棵树重新标号后可以和另一棵树完全相同
一般我们在考虑同构的时候都是考虑的有根树,以下也以有根树为例
当然无根树的同构判断也很简单,分别找出两棵树的重心(至多两个),以重心为根跑有根树的树Hash然后看结果是否一致即可
之前网上常见的树Hash的算法都是有概率被卡的,即如果两棵树真的同构则它们的Hash值一定相同,但如果两棵树不同构也有可能得到相同的Hash值
但最近看到一种很牛逼的不会出错的算法——AHU算法,复杂度多个\(\log\),但正确性得到了保证
关于各种方法的取舍,其实就是乱草能不被卡就行,甚至你可以自己发明,同时把多种方法一起使用也是可以的
基于和的Hash
先上个公式:
其中\(f_u\)表示以\(u\)为根的子树对应的Hash值,特殊地,叶节点的Hash值设为\(1\)
\(son(u,i)\)表示\(u\)的所有儿子以\(f\)为关键字排序后,排名第\(i\)的儿子,\(seed\)就是一个初始选定的种子
然后在跑的时候用unsigned long long自然溢出取模即可
当然这种方法反例比较多,比如下面的
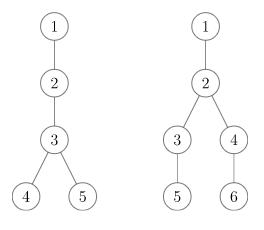
可以算出两棵树的Hash值都是\(60(1+seed)\)
基于异或的Hash
还是先上公式:
里面出现的量和意义和上面类似就不再赘述了,注意\(son_u\)无需再排序
由于异或的性质,如果一个节点下有多棵本质相同的子树,这种哈希值将无法分辨该种子树出现\(1,3,5,\cdots\)次的情况
基于质数作参的Hash
公式如下:
而这里的\(son_u\)也无需排序,同时\(prime_t\)表示第\(t\)个质数
这种做法由于引入了多个参数,其实已经比较难卡了,具体反例我也找不出的说
和与异或混用+shift操作
在实际应用中一般会优先考虑这种方法,兼顾了写代码的简洁度和正确性
我们可以把原来对\(seed\)作乘法的算法变成一次shift,根据某些玄学原理这样可以很大概率地避免冲突
关于shift的代码具体如下:
inline u64 shift(u64 x)
{
x^=x<<13; x^=x>>7; x^=x<<17; return x;
}
因此我们每次把儿子的Hash值往上合并一层的时候进行一次shift,同时同时维护和与异或的信息即可
大概的做法就如上所述,写法可以看这道题的代码
AHU算法
我们考虑给每个点一个序列号,使得所有同构的子树的根节点的序列号相同
考虑以下这种保证绝对正确率的方法:对于一个点\(u\),我们把它的所有儿子的序列号扔进一个vector里,然后把vector排序
不难发现如果我们用这个vector作为序列号的话,是显然不会误判的
但用vector来当序列号可能会出现各种vector的嵌套情况,未免有点太蠢了,因此我们用map把每个vector映射成一个标号即可
乍一看感觉复杂度很爆炸,但由于STL的优秀实现机制(map是用红黑树实现的),因此map <vector<int>,int>插入一个vector的复杂度不会超过这个vector的长度乘\(\log\)
由于每个点只会在map里查找一次,因此总复杂度就是\(O(n\log n)\)的
当然这种算法在遇到无根树的情况会比较麻烦,当有两个重心时需要在两个重心之间的那条边上建一个虚点作根
当然虚点的vector需要特殊处理,往它的vector里塞个\(-1\),来把它和普通的点区分开
大概的做法就如上所述,写法可以看这道题的代码
Postscript
学了这么多年我才发现连这么一个简单算法都不会,还是太菜太菜

 浙公网安备 33010602011771号
浙公网安备 33010602011771号