
深度学习基础知识整理
自动编码器
Auto-encoders是一种人工神经网络,用于学习未标记数据的有效编码。它由两个部分组成:编码器和解码器。编码器将输入数据转换为一种更紧凑的表示形式,而解码器则将该表示形式转换回原始数据。这种方法可以用于降维,去噪,特征提取和生成模型。
自编码器的训练过程是无监督的,因为它不需要标记数据。它的目标是最小化重构误差,即输入数据与解码器输出之间的差异。这可以通过反向传播算法和梯度下降等优化方法来实现。
自编码器有多种变体,包括稀疏自编码器,去噪自编码器,变分自编码器等。这些变体旨在强制学习到的表示具有某些有用的属性,例如稀疏性或噪声鲁棒性。
自动编码器作为一种前馈神经网络,由编码器和解码器两个阶段组成。编码器获取输入x,并通过如下非线性映射将其转换为隐藏表示
其中φ是非线性激活函数,然后解码器通过如下方法将隐藏表示映射回原始表示
对包括θ=[W,b,W′,b′]在内的模型参数进行优化,以最小化
其中
稀疏自编码器
在自编码器中,稀疏性是指编码器的输出中只有少量的非零元素。这可以通过向损失函数添加一个惩罚项来实现,以鼓励编码器生成更少的非零元素。这个惩罚项通常是L1正则化项,它是编码器输出向量中所有元素的绝对值之和。这个技巧被称为“稀疏自编码器”。 稀疏自编码器的目标是学习到一组稀疏的特征,这些特征可以更好地表示输入数据。这种方法可以用于特征提取和降维。相应的优化函数更新为
其中m为隐藏层大小,第二项是隐藏单元上KL发散的总和。第j个隐藏神经元上的KL散度为
其中p为预定义的平均激活目标,
Addition of Denoising
在自编码器中,去噪是指通过自动编码器去除输入数据中的噪声。这可以通过向损失函数添加一个惩罚项来实现,以鼓励编码器生成更少的非零元素。这个惩罚项通常是L1正则化项,它是编码器输出向量中所有元素的绝对值之和。这个技巧被称为“去噪自编码器”。
去噪自编码器的目标是学习到一组稀疏的特征,这些特征可以更好地表示输入数据。这种方法可以用于特征提取和降维。
Stacking Structure
几个降噪自编码器可以堆叠在一起形成深度网络,通过将第l层输出作为输入提供给第(l+1)层来学习高级表示,训练是贪婪地一层一层完成的。
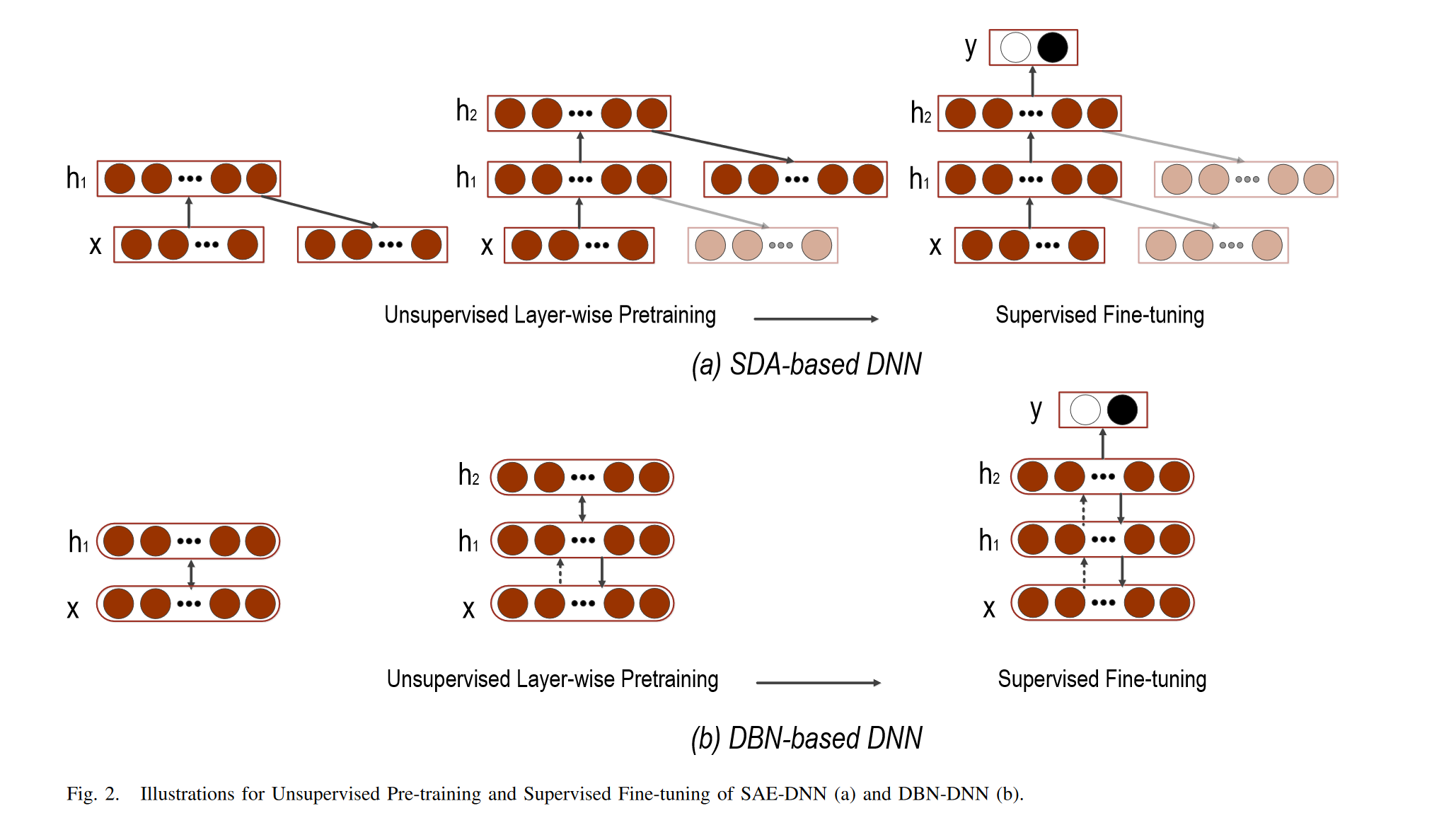
由于自动编码器可以以无监督的方式进行训练,因此自动编码器,特别是堆叠去噪自动编码器(SDA),可以通过初始化深度神经网络(DNN)的权重来训练模型,从而提供有效的预训练解决方案。在SDA的逐层预训练之后,可以将自动编码器的参数设置为DNN的所有隐藏层的初始化。然后,执行有监督的微调以最小化标记的训练数据上的预测误差。通常,在网络顶部添加一个softmax/回归层,以将AE中最后一层的输出映射到目标。与任意随机初始化相比,基于SDA的预训练协议可以使DNN模型具有更好的收敛能力。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2018-01-15 选择排序