分布式爬虫基于scrapy
1.概念:多台机器上可以执行同一个爬虫程序,实现网站数据的分布爬取。
2.原生的scrapy 是不可以实现分布式爬虫?
a) 调度器无法共享
b) 管道无法共享
3. scrapy-redis 组件:专门为scrapy 开发的一套组件。该组件可以让scrapy 实现分布式
a) 下载:pip install scrapy-redis
4.分布式爬取的流程
a) redis配置文件的配置
i. bind 127.0.0.1 进行注释
ii. project-mode no 关闭保护模式
b) redis 服务器的开启:基于配置配置文件
c) 创建scrapy工程后,创建基于crawlSpider的爬虫文件
d) 导入RedisCrawlSpider类,然后将爬虫文件修改成基于改类的源文件
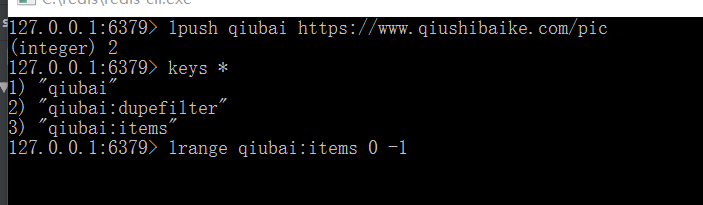
e) 将start_url修改成redis_key = "xxx" (此名字用于redis lpush name value) #name:xxx value:start_url # keys * #查看数据 lrange name:items 0 -1 第一行看到最后一行
 、
、
f) 将项目的管道和调度器配置成基于scrapy-redis组建中
g) 执行爬虫文件:scrapy runspider qiubai.py (运行py文件进入listen状态)
h) 将起始url 放到调度器的队列中: redis-cli : lpush列表的名称(redis-key) 起始url
spider/qiubai.py
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from handle4.items import Handle4Item from scrapy_redis.spiders import RedisCrawlSpider # 注意方法 class QiubaiSpider(RedisCrawlSpider): name = 'qiubai' # allowed_domains = ['www.qiushibaike.com/pic'] # start_urls = ['https://www.qiushibaike.com/pic/'] redis_key = "qiubaispider" link = LinkExtractor(allow=r'www.qiushibaike.com/pic/page/\d+?') rules = ( Rule(link, callback='self.parse_item', follow=True), ) def parse_item(self, response): div_list = response.xpath('//*[@id="content"]/div') for div in div_list: item = Handle4Item() img_url = 'https:' + div.xpath('//div[@class="thumb"]/a/img/@src').extract_first() item["img_url"] = img_url yield item # return i
