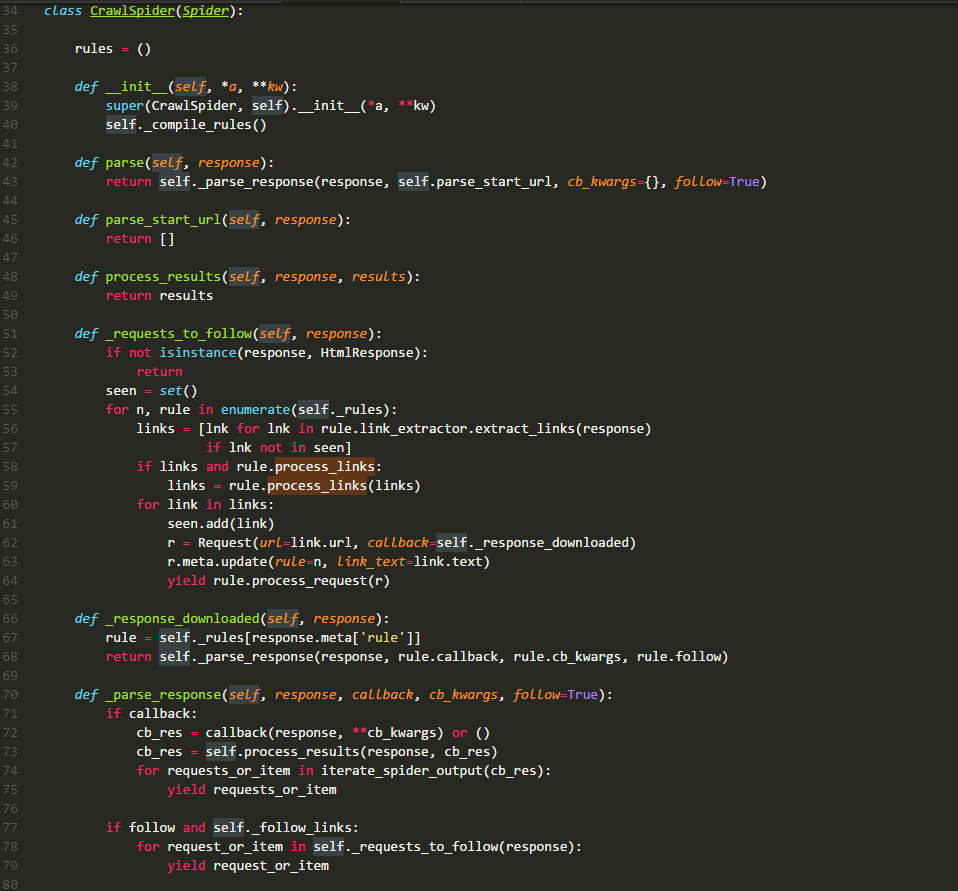
scrapy crawlspider内置方法源码

rules:
有经验的同学都知道它是一个列表,存储的元素时Rule类的实例,其中每一个实例都定义了一种采集站点的行为。如果有多个rule都匹配同一个链接,那么位置下标最小的一个rule将会被使用。
__init__:
在源码中可以看到,它主要就是执行了_compile_rules方法,这边暂时不讲。
parse:
默认回调方法,同上章一样。不过在这里进行了重写,这里直接调用方法_parse_response,并把parse_start_url方法作为处理response的方法。
parse_start_url:
这个方法在源码中只看其定义是没有什么发现的,需要查看其使用环境。它的主要作用就是处理parse返回的response,比如提取出需要的数据等,该方法也需要返回item、request或者他们的可迭代对象。它就是一个回调方法,和rule.callback用法一样。
_requests_to_follow:
阅读源码可以发现,它的作用就是从response中解析出目标url,并将其包装成request请求。该请求的回调方法是_response_downloaded,这里为request的meta值添加了rule参数,该参数的值是这个url对应rule在rules中的下标。
_response_downloaded:
该方法是方法_requests_to_follow的回调方法,作用就是调用_parse_response方法,处理下载器返回的response,设置response的处理方法为rule.callback方法。
_parse_response:
该方法将resposne交给参数callback代表的方法去处理,然后处理callback方法的requests_or_item。再根据rule.follow and spider._follow_links来判断是否继续采集,如果继续那么就将response交给_requests_to_follow方法,根据规则提取相关的链接。spider._follow_links的值是从settings的CRAWLSPIDER_FOLLOW_LINKS值获取到的。
_compile_rules:
这个方法的作用就是将rule中的字符串表示的方法改成实际的方法,方便以后使用。
from_crawler:
这个就不细说了,看看源码就好,两行代码。
整个数据的流向如下图所示:

关于CrawlSpider就先讲到这里,接下来会说说Rule类,该类的源码已经在文章的最上方贴出来了。
link_extractor:
该方法是一个Link Extractor实例,主要定义的就是链接的解析规则。
callback:
该值可以是一个方法,也可以是一个字符串(spider实例中一个方法的名称)。它就是一个回调方法,在上面的流程图中可以看到它所在的位置以及作用。这里要慎用parse做为回调方法,因为这边的parse已经不像spider类中的那样没有具体操作。
cb_kwargs:
这是一个字典,用于给callback方法传递参数,在CrawlSpider源码中可以看到其作用。
follow:
是一个布尔对象,表示是当前response否继续采集。如果callback是None,那么它就默认为True,否则为False。
process_links:
该方法在crawlspider中的_requests_to_follow方法中被调用,它接收一个元素为Link的列表作为参数,返回值也是一个元素为Link的列表。可以用该方法对采集的Link对象进行修改,比如修改Link.url。这里的如果你的目标url是相对的链接,那么scrapy会将其扩展成绝对的。源码就不带大家看了,了解就行。
process_request:
顾名思义,该方法就是处理request的,源码中也给出了一个样例(虽然没有任何作用),想修改request的小伙伴可以自己构造该方法。
Rule是不是很简单呢,可是他的属性link_extractor的花样就比较多了。默认的link解析器是LinkExtractor,也就是LxmlLinkExtractor。在之前的scrapy版本中还有其他的解析器,不过现在已经弃用了。对于该类的介绍官网文档已经有很详细的解释了,我就不再赘述了。
这章介绍的是scrapy中比较重要的一个类,希望本文会对小伙伴们有帮助,如果有疑问,欢迎在下面的评论区中提问。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号