2.Kafka
Kafka 是什么?主要应用场景有哪些?
Kafka 是一个分布式流式处理平台。
流平台具有三个关键功能:
- 消息队列:发布和订阅消息流,这个功能类似于消息队列,这也是 Kafka 也被归类为消息队列的原因。
- 容错的持久方式存储记录消息流:Kafka 会把消息持久化到磁盘,有效避免了消息丢失的风险。
- 流式处理平台: 在消息发布的时候进行处理,Kafka 提供了一个完整的流式处理类库。
Kafka 主要有两大应用场景:
- 消息队列:建立实时流数据管道,以可靠地在系统或应用程序之间获取数据。
- 数据处理: 构建实时的流数据处理程序来转换或处理数据流。
和其他消息队列相比,Kafka 的优势在哪里?
我们现在经常提到 Kafka 的时候就已经默认它是一个非常优秀的消息队列了,我们也会经常拿它跟 RocketMQ、RabbitMQ 对比。我觉得 Kafka 相比其他消息队列主要的优势如下:
- 极致的性能:基于 Scala 和 Java 语言开发,设计中大量使用了批量处理和异步的思想,最高可以每秒处理千万级别的消息。
- 生态系统兼容性无可匹敌:Kafka 与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域。
队列模型了解吗?Kafka 的消息模型知道吗?
队列模型:早期的消息模型
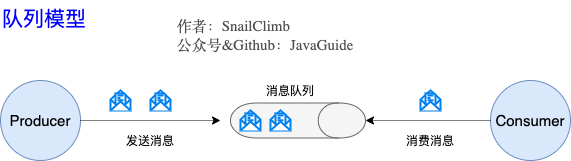
使用队列(Queue)作为消息通信载体,满足生产者与消费者模式,一条消息只能被一个消费者使用,未被消费的消息在队列中保留直到被消费或超时。 比如:我们生产者发送 100 条消息的话,两个消费者来消费一般情况下两个消费者会按照消息发送的顺序各自消费一半(也就是你一个我一个的消费。)
队列模型存在的问题:
假如我们存在这样一种情况:我们需要将生产者产生的消息分发给多个消费者,并且每个消费者都能接收到完整的消息内容。这种情况,队列模型就不好解决了。
很多比较杠精的人就说:我们可以为每个消费者创建一个单独的队列,让生产者发送多份。这是一种非常愚蠢的做法,浪费资源不说,还违背了使用消息队列的目的。
发布-订阅模型:Kafka 消息模型
发布-订阅模型主要是为了解决队列模型存在的问题。
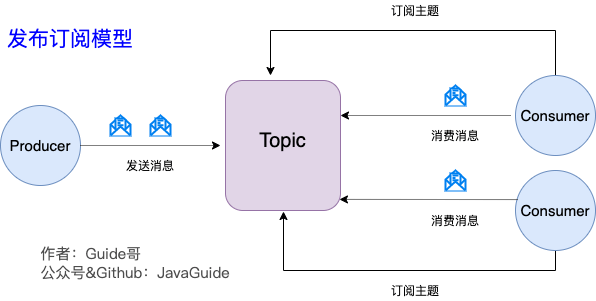
发布订阅模型(Pub-Sub) 使用主题(Topic) 作为消息通信载体,类似于广播模式;发布者发布一条消息,该消息通过主题传递给所有的订阅者,在一条消息广播之后才订阅的用户则是收不到该条消息的。
在发布 - 订阅模型中,如果只有一个订阅者,那它和队列模型就基本是一样的了。Kafka 采用的就是发布 - 订阅模型。
RocketMQ 的消息模型和 Kafka 基本是完全一样的。唯一的区别是 Kafka 中没有队列这个概念,与之对应的是 Partition(分区)。
什么是 Producer、Consumer、Broker、Topic、Partition?
Kafka 将生产者发布的消息发送到 Topic(主题) 中,需要这些消息的消费者可以订阅这些 Topic(主题),如下图所示:
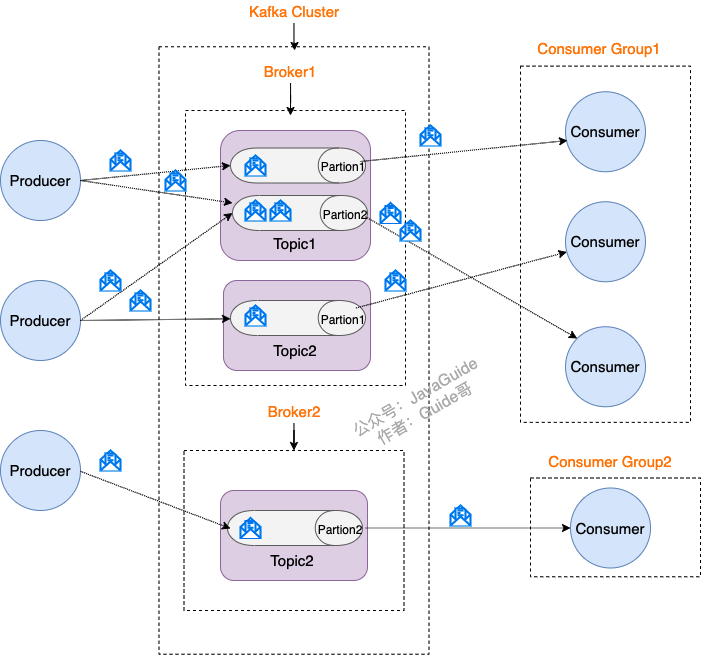
Kafka 比较重要的几个概念:
- Producer(生产者) : 产生消息的一方。
- Consumer(消费者) : 消费消息的一方。
- Broker(代理) : 可以看作是一个独立的 Kafka 实例。多个 Kafka Broker 组成一个 Kafka Cluster。
同时,你一定也注意到每个 Broker 中又包含了 Topic 以及 Partition 这两个重要的概念:
- Topic(主题) : Producer 将消息发送到特定的主题,Consumer 通过订阅特定的 Topic(主题) 来消费消息。
- Partition(分区) : Partition 属于 Topic 的一部分。一个 Topic 可以有多个 Partition ,并且同一 Topic 下的 Partition 可以分布在不同的 Broker 上,这也就表明一个 Topic 可以横跨多个 Broker 。这正如我上面所画的图一样。
划重点:Kafka 中的 Partition(分区) 实际上可以对应成为消息队列中的队列。
Kafka 的多副本机制了解吗?带来了什么好处?
Kafka 为分区(Partition)引入了多副本(Replica)机制。分区(Partition)中的多个副本之间会有一个叫做 leader 的家伙,其他副本称为 follower。我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。
生产者和消费者只与 leader 副本交互。你可以理解为其他副本只是 leader 副本的拷贝,它们的存在只是为了保证消息存储的安全性。当 leader 副本发生故障时会从 follower 中选举出一个 leader,但是 follower 中如果有和 leader 同步程度达不到要求的参加不了 leader 的竞选。
Kafka 的多分区(Partition)以及多副本(Replica)机制有什么好处呢?
- Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力(负载均衡)。
- Partition 可以指定对应的 Replica 数, 这也极大地提高了消息存储的安全性, 提高了容灾能力,不过也相应的增加了所需要的存储空间。
Zookeeper 在 Kafka 中的作用是什么?
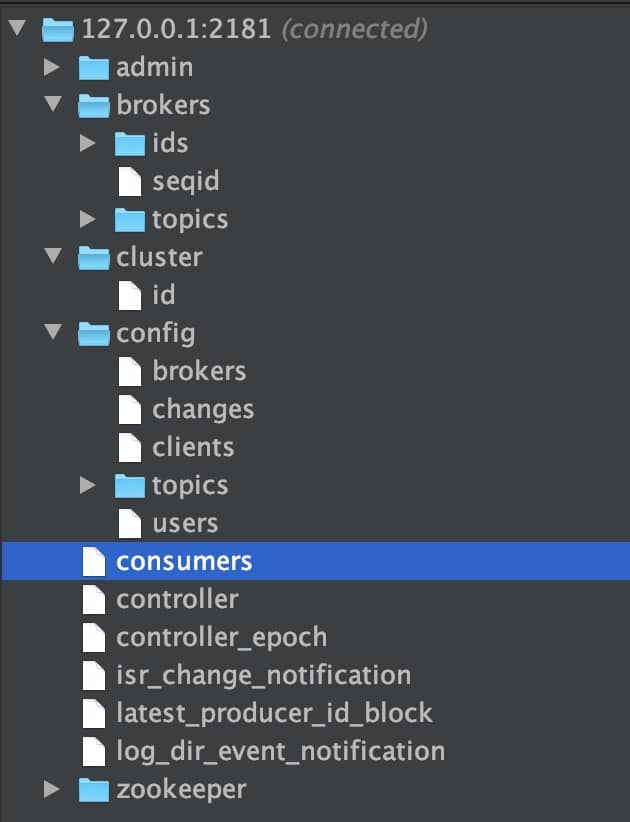
ZooKeeper 主要为 Kafka 提供元数据的管理的功能。
从图中我们可以看出,Zookeeper 主要为 Kafka 做了下面这些事情:
- Broker 注册:在 Zookeeper 上会有一个专门用来进行 Broker 服务器列表记录的节点。每个 Broker 在启动时,都会到 Zookeeper 上进行注册,即到
/brokers/ids下创建属于自己的节点。每个 Broker 就会将自己的 IP 地址和端口等信息记录到该节点中去 - Topic 注册:在 Kafka 中,同一个Topic 的消息会被分成多个分区并将其分布在多个 Broker 上,这些分区信息及与 Broker 的对应关系也都是由 Zookeeper 在维护。比如我创建了一个名字为 my-topic 的主题并且它有两个分区,对应到 zookeeper 中会创建这些文件夹:
/brokers/topics/my-topic/Partitions/0、/brokers/topics/my-topic/Partitions/1 - 负载均衡:上面也说过了 Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力。 对于同一个 Topic 的不同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上。当生产者产生消息后也会尽量投递到不同 Broker 的 Partition 里面。当 Consumer 消费的时候,Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡。
使用 Kafka 能否不引入 Zookeeper?
在 Kafka 2.8 之前,Kafka 最被大家诟病的就是其重度依赖于 Zookeeper。在 Kafka 2.8 之后,引入了基于 Raft 协议的 KRaft 模式,不再依赖 Zookeeper,大大简化了 Kafka 的架构,让你可以以一种轻量级的方式来使用 Kafka。
不过,要提示一下:如果要使用 KRaft 模式的话,建议选择较高版本的 Kafka,因为这个功能还在持续完善优化中。Kafka 3.3.1 版本是第一个将 KRaft(Kafka Raft)共识协议标记为生产就绪的版本。
Kafka 消费顺序、消息丢失和重复消费
(1)Kafka 如何保证消息的消费顺序?
每次添加消息到 Partition(分区) 的时候都会采用尾加法。 Kafka 只能为我们保证 Partition(分区) 中的消息有序。
消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。Kafka 通过偏移量(offset)来保证消息在分区内的顺序性。
有一种很简单的保证消息消费顺序的方法:1 个 Topic 只对应一个 Partition,但是破坏了 Kafka 的设计初衷。
Kafka 中发送 1 条消息的时候,可以指定 topic, partition, key,data(数据) 4 个参数。如果你发送消息的时候指定了 Partition 的话,所有消息都会被发送到指定的 Partition。并且,同一个 key 的消息可以保证只发送到同一个 partition,这个我们可以采用表/对象的 id 来作为 key 。
总结一下,对于如何保证 Kafka 中消息消费的顺序,有了下面两种方法:
1 个 Topic 只对应一个 Partition。
(推荐)发送消息的时候指定 key/Partition。
(2)Kafka 如何保证消息不丢失?
# 生产者丢失消息的情况
生产者(Producer) 调用send方法发送消息之后,消息可能因为网络问题并没有发送过去。
为了确定消息是发送成功,我们要判断消息发送的结果。但是要注意的是 Kafka 生产者(Producer) 使用 send 方法发送消息实际上是异步的操作,我们可以通过 get()方法获取调用结果,但是这样也让它变为了同步操作.
SendResult<String, Object> sendResult = kafkaTemplate.send(topic, o).get(); if (sendResult.getRecordMetadata() != null) { logger.info("生产者成功发送消息到" + sendResult.getProducerRecord().topic() + "-> " + sendRe sult.getProducerRecord().value().toString()); }
可以采用为其添加回调函数的形式,示例代码如下:
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o); future.addCallback(result -> logger.info("生产者成功发送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(), result.getRecordMetadata().partition()), ex -> logger.error("生产者发送消失败,原因:{}", ex.getMessage()));
如果消息发送失败的话,我们检查失败的原因之后重新发送即可!
另外,这里推荐为 Producer 的retries(重试次数)设置一个比较合理的值,一般是 3 ,但是为了保证消息不丢失的话一般会设置比较大一点。设置完成之后,当出现网络问题之后能够自动重试消息发送,避免消息丢失。另外,建议还要设置重试间隔,因为间隔太小的话重试的效果就不明显了,网络波动一次你 3 次一下子就重试完了。
#消费者丢失消息的情况
我们知道消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。偏移量(offset)表示 Consumer 当前消费到的 Partition(分区)的所在的位置。Kafka 通过偏移量(offset)可以保证消息在分区内的顺序性。
当消费者拉取到了分区的某个消息之后,消费者会自动提交了 offset。自动提交的话会有一个问题,当消费者刚拿到这个消息准备进行真正消费的时候,突然挂掉了,消息实际上并没有被消费,但是 offset 却被自动提交了。
解决办法也比较粗暴,我们手动关闭自动提交 offset,每次在真正消费完消息之后再自己手动提交 offset 。 但是,细心的朋友一定会发现,这样会带来消息被重新消费的问题。比如你刚刚消费完消息之后,还没提交 offset,结果自己挂掉了,那么这个消息理论上就会被消费两次。
#Kafka 弄丢了消息
Kafka 为分区(Partition)引入了多副本(Replica)机制。分区(Partition)中的多个副本之间会有一个叫做 leader 的家伙,其他副本称为 follower。我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。生产者和消费者只与 leader 副本交互。你可以理解为其他副本只是 leader 副本的拷贝,它们的存在只是为了保证消息存储的安全性。
试想一种情况:假如 leader 副本所在的 broker 突然挂掉,那么就要从 follower 副本重新选出一个 leader ,但是 leader 的数据还有一些没有被 follower 副本的同步的话,就会造成消息丢失。
设置 acks = all
解决办法就是我们设置 acks = all。acks 是 Kafka 生产者(Producer) 很重要的一个参数。
acks 的默认值即为 1,代表我们的消息被 leader 副本接收之后就算被成功发送。当我们配置 acks = all 表示只有所有 ISR 列表的副本全部收到消息时,生产者才会接收到来自服务器的响应. 这种模式是最高级别的,也是最安全的,可以确保不止一个 Broker 接收到了消息. 该模式的延迟会很高.( 每个Leader会动态维护一个ISR列表,该列表里存储的是和Leader基本同步的Follower。)
设置 replication.factor >= 3
为了保证 leader 副本能有 follower 副本能同步消息,我们一般会为 topic 设置 replication.factor >= 3。这样就可以保证每个 分区(partition) 至少有 3 个副本。虽然造成了数据冗余,但是带来了数据的安全性。
设置 min.insync.replicas > 1
一般情况下我们还需要设置 min.insync.replicas> 1 ,这样配置代表消息至少要被写入到 2 个副本才算是被成功发送。min.insync.replicas 的默认值为 1 ,在实际生产中应尽量避免默认值 1。
但是,为了保证整个 Kafka 服务的高可用性,你需要确保 replication.factor > min.insync.replicas 。为什么呢?设想一下假如两者相等的话,只要是有一个副本挂掉,整个分区就无法正常工作了。这明显违反高可用性!一般推荐设置成 replication.factor = min.insync.replicas + 1。
设置 unclean.leader.election.enable = false
Kafka 0.11.0.0 版本开始 unclean.leader.election.enable 参数的默认值由原来的 true 改为 false
我们最开始也说了我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。多个 follower 副本之间的消息同步情况不一样,当我们配置了 unclean.leader.election.enable = false 的话,当 leader 副本发生故障时就不会从 follower 副本中和 leader 同步程度达不到要求的副本中选择出 leader ,这样降低了消息丢失的可能性。
(3)Kafka 如何保证消息不重复消费?
kafka 出现消息重复消费的原因:
- 服务端侧已经消费的数据没有成功提交 offset(根本原因)。
- Kafka 侧 由于服务端处理业务时间长或者网络链接等等原因让 Kafka 认为服务假死,触发了分区 rebalance。
解决方案:
- 消费消息服务做幂等校验,比如 Redis 的 set、MySQL 的主键等天然的幂等功能。这种方法最有效。
- 将
enable.auto.commit参数设置为 false,关闭自动提交,开发者在代码中手动提交 offset。那么这里会有个问题:什么时候提交 offset 合适?- 处理完消息再提交:依旧有消息重复消费的风险,和自动提交一样
- 拉取到消息即提交:会有消息丢失的风险。允许消息延时的场景,一般会采用这种方式。然后,通过定时任务在业务不繁忙(比如凌晨)的时候做数据兜底。
Kafka 重试机制:
消费失败会怎么样?
在默认配置下,当消费异常会进行重试,重试多次后会跳过当前消息,继续进行后续消息的消费,不会一直卡在当前消息,保证了业务的正常进行。默认会重试多少次?
看源码 FailedRecordTracker 类有个 recovered 函数,返回 Boolean 值判断是否要进行重试,下面是这个函数中判断是否重试的逻辑:
DEFAULT_MAX_FAILURES 的值是 10,currentAttempts 从 0 到 9,所以总共会执行 10 次,每次重试的时间间隔为 0。 如何自定义重试次数以及时间间隔?
默认错误处理器的重试次数以及时间间隔是由 FixedBackOff 控制的,FixedBackOff 是 DefaultErrorHandler 初始化时默认的。所以自定义重试次数以及时间间隔,只需要在 DefaultErrorHandler 初始化的时候传入自定义的 FixedBackOff 即可。重新实现一个 KafkaListenerContainerFactory,调用 setCommonErrorHandler 设置新的自定义的错误处理器就可以实现。
@Bean public KafkaListenerContainerFactory kafkaListenerContainerFactory(ConsumerFactory<String, String> consumerFactory) { ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory(); // 自定义重试时间间隔以及次数 FixedBackOff fixedBackOff = new FixedBackOff(1000, 5); factory.setCommonErrorHandler(new DefaultErrorHandler(fixedBackOff)); factory.setConsumerFactory(consumerFactory); return factory; }
如何在重试失败后进行告警?
自定义重试失败后逻辑,需要手动实现,以下是一个简单的例子,重写 DefaultErrorHandler 的 handleRemaining 函数,加上自定义的告警等操作。
@Slf4j public class DelErrorHandler extends DefaultErrorHandler { public DelErrorHandler(FixedBackOff backOff) { super(null,backOff); } @Override public void handleRemaining(Exception thrownException, List<ConsumerRecord<?, ?>> records, Consumer<?, ?> consumer, MessageListenerContainer container) { super.handleRemaining(thrownException, records, consumer, container); log.info("重试多次失败"); // 自定义操作 } }
DefaultErrorHandler 只是默认的一个错误处理器,Spring Kafka 还提供了 CommonErrorHandler 接口。手动实现 CommonErrorHandler 就可以实现更多的自定义操作,有很高的灵活性。例如根据不同的错误类型,实现不同的重试逻辑以及业务逻辑等
重试失败后的数据如何再次处理?
当达到最大重试次数后,数据会直接被跳过,继续向后进行。当代码修复后,如何重新消费这些重试失败的数据呢?
死信队列(Dead Letter Queue,简称 DLQ) 是消息中间件中的一种特殊队列。它主要用于处理无法被消费者正确处理的消息,通常是因为消息格式错误、处理失败、消费超时等情况导致的消息被"丢弃"或"死亡"的情况。当消息进入队列后,消费者会尝试处理它。如果处理失败,或者超过一定的重试次数仍无法被成功处理,消息可以发送到死信队列中,而不是被永久性地丢弃。在死信队列中,可以进一步分析、处理这些无法正常消费的消息,以便定位问题、修复错误,并采取适当的措施。
@RetryableTopic 是 Spring Kafka 中的一个注解,它用于配置某个 Topic 支持消息重试,更推荐使用这个注解来完成重试。
// 重试 5 次,重试间隔 100 毫秒,最大间隔 1 秒 @RetryableTopic( attempts = "5", backoff = @Backoff(delay = 100, maxDelay = 1000) ) @KafkaListener(topics = {KafkaConst.TEST_TOPIC}, groupId = "apple") private void customer(String message) { log.info("kafka customer:{}", message); Integer n = Integer.parseInt(message); if (n % 5 == 0) { throw new RuntimeException(); } System.out.println(n); }
@DltHandler 处理,也可以使用 @KafkaListener 重新消费。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号