分库分表分页
当数据库出现一些读写性能瓶颈时,优先使用增加索引、优化索引结构、读写分离、使用从库等常规优化手段解决,分库分表是最终的优化手段,且在分库分表前要先考虑业务未来三到五年的数据增长需求,防止经常分库分表改变结构带来的代价。
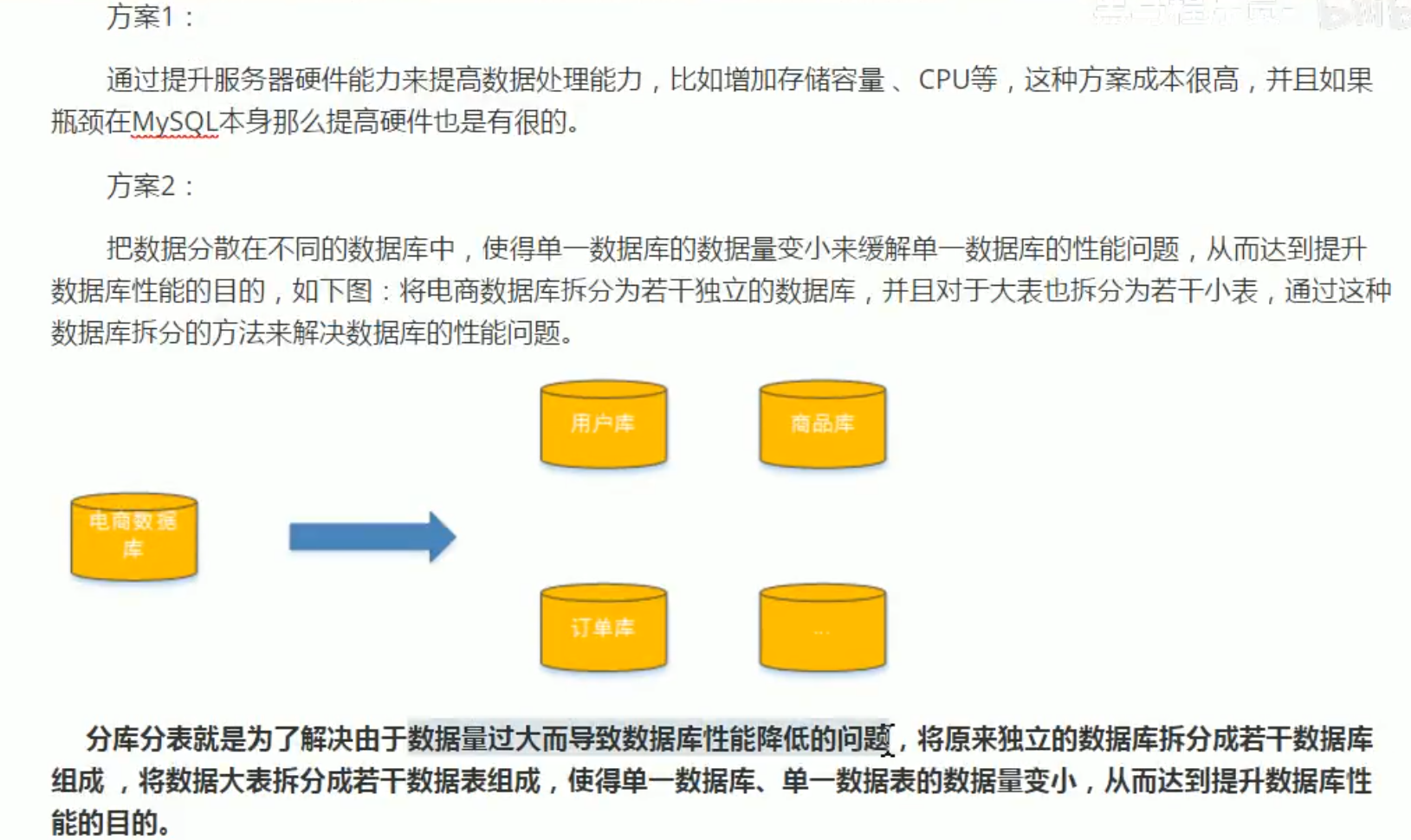
垂直分表
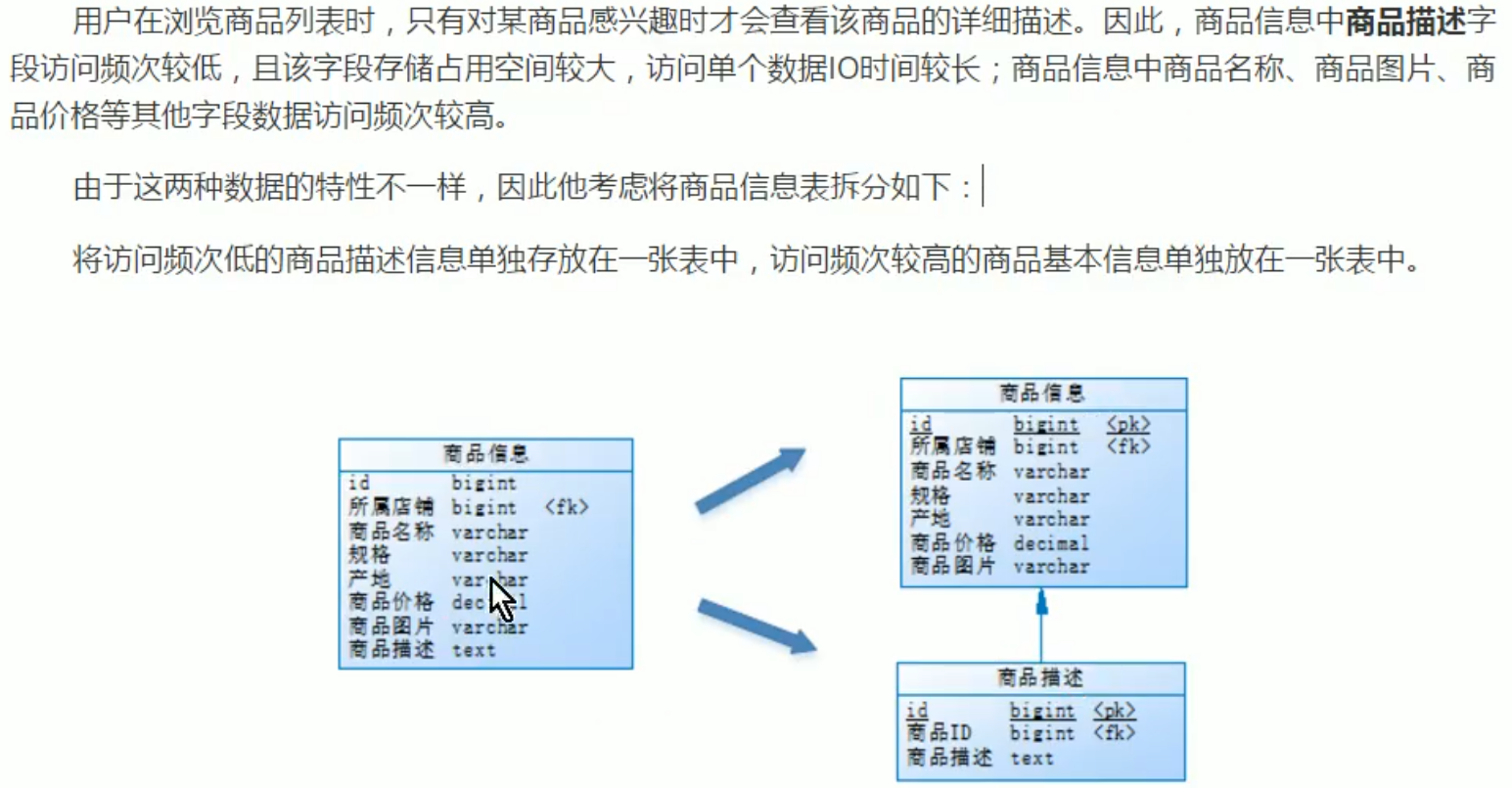

垂直分库
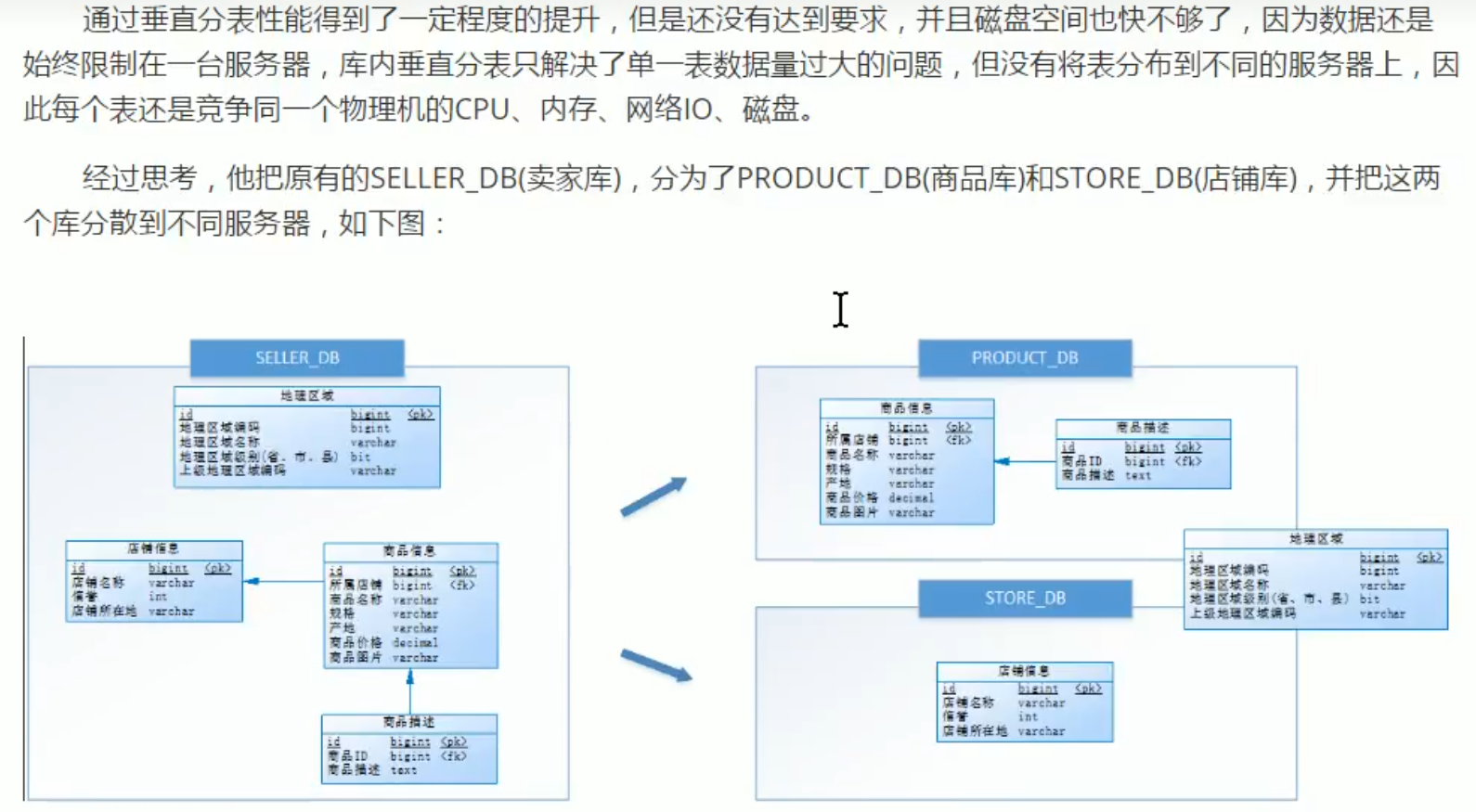

垂直分库,主要还是想让多个服务器共同分担请求压力。
一般叫【专库专用】,比如这个店铺库拆出来之后,就可以相应开发一个店铺管理服务,专门管理店铺库,或者用户管理等,可以将这个和微服务一些概念联系起来。
水平分库

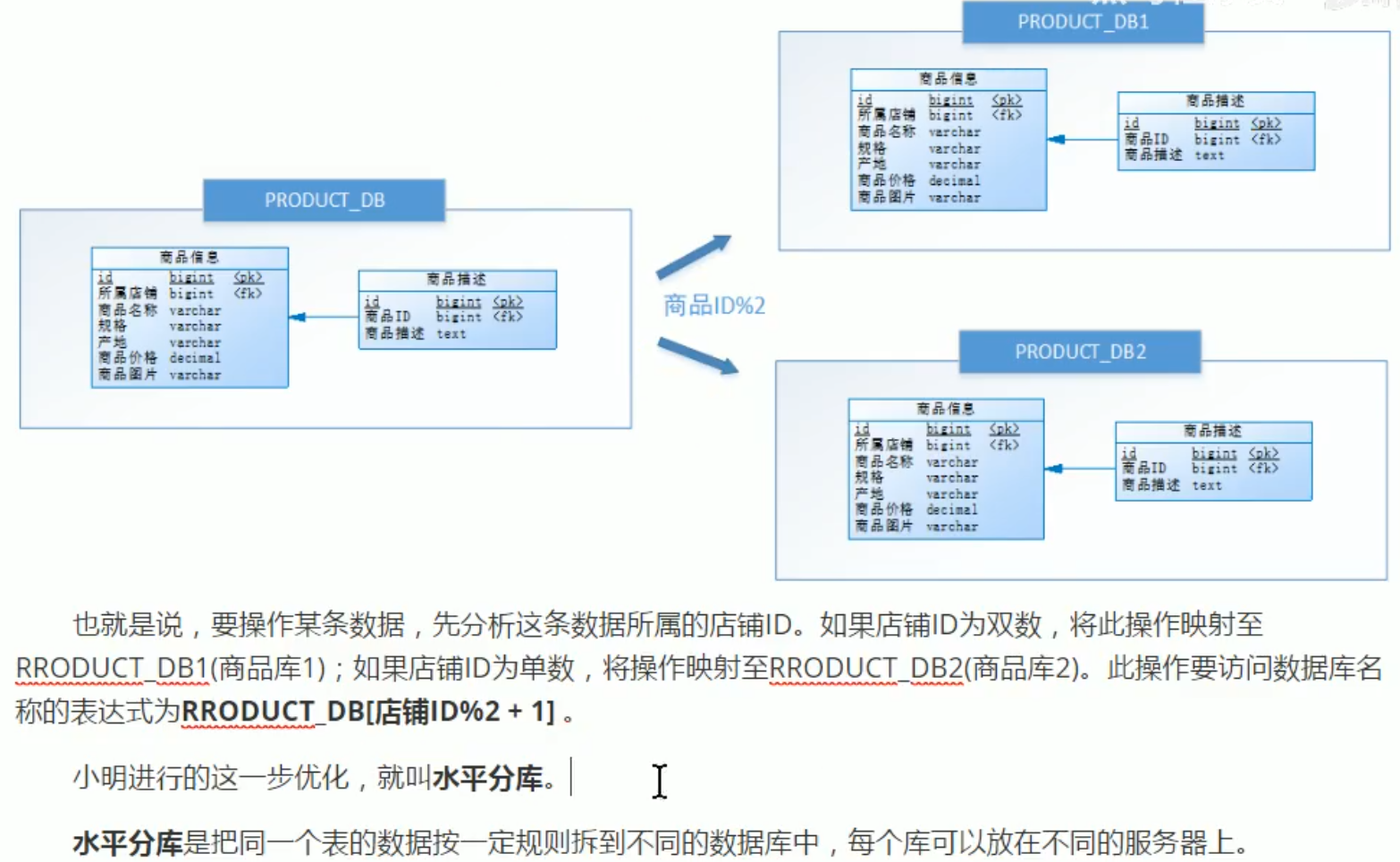

水平分表
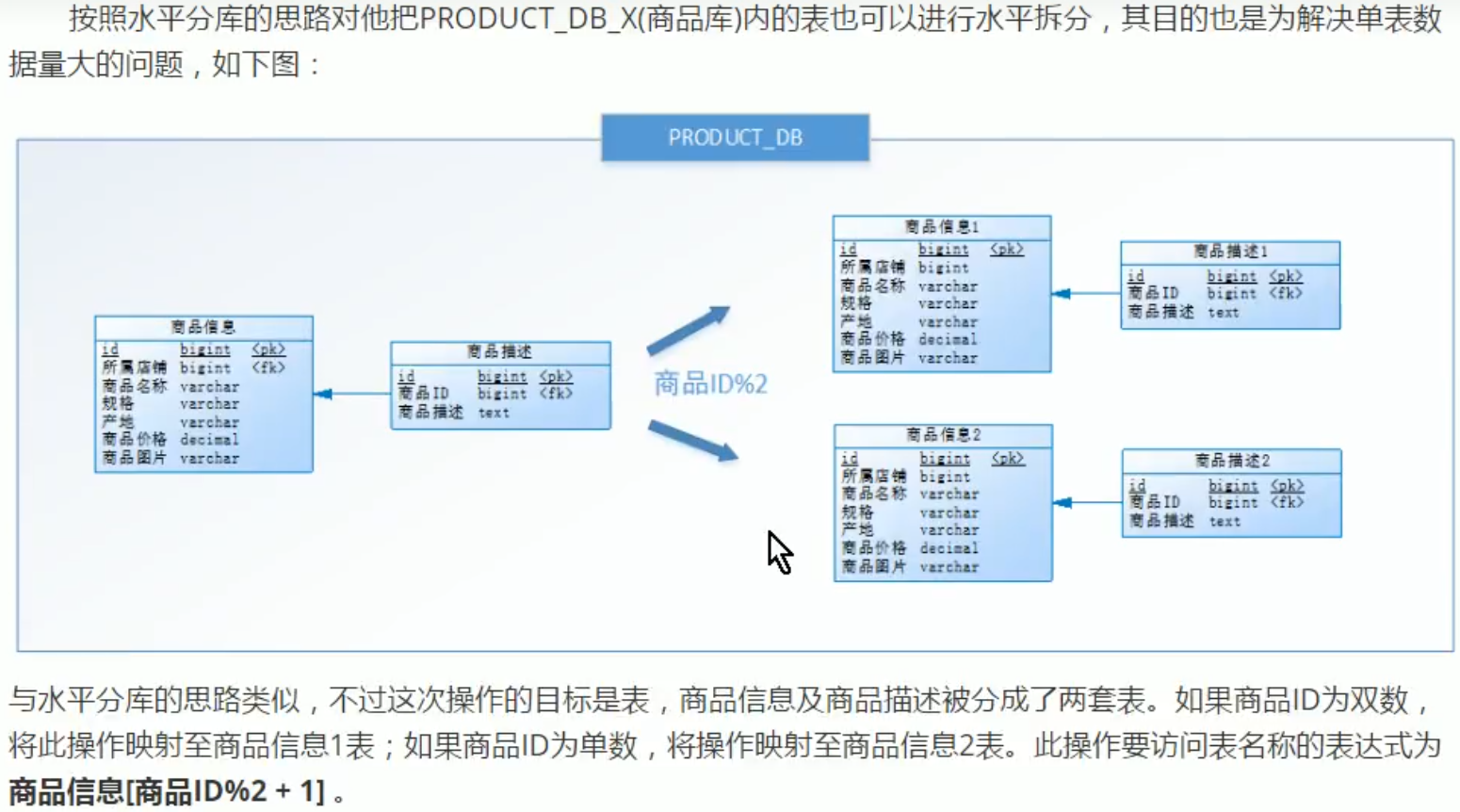

减少锁表几率:
对id为单数的记录操作时,就不影响双数表。
切分规则
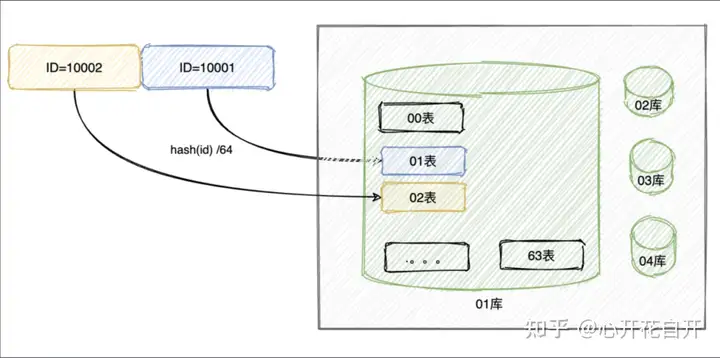
(1)Hash取模
(2)Range划分
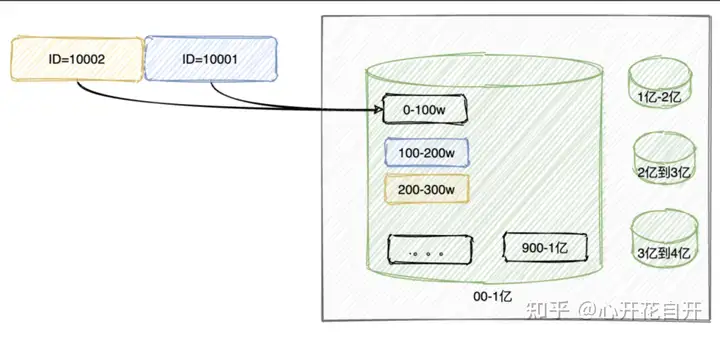
简单说,就是把数据划分范围,挨个存储,存满一个再存另一个。
优点:不需要数据迁移,后续数据即时增长很多也没问题
缺点:数据倾斜严重,比如上图,很长一段时间,都会只用到 1 个库,几个表
(3)一致性Hash
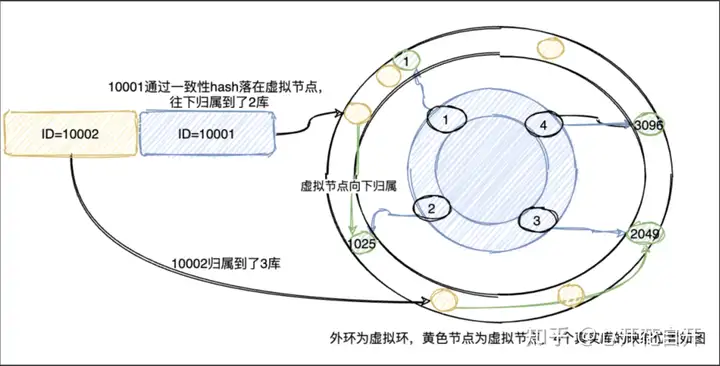
一致性 hash 环的节点一般按 2^32-1 来算,但是一般如果业务 ID 足够均衡,则可以降一些节点,如 4096 等等,4 个库的话,则均衡的分布在图上的位置,而数据通过 hash 计算,对应到外环的虚拟节点,然后归属于真实的库,对于表也可以同样处理。或者,直接把表节点部署在外环上,直接将数据归属于表。
优点:更加均匀,并且在需要扩容时,数据迁移的量级更小,只需要迁移 1/N 的数据即可
缺点:路由算法要复杂,但是对于能得到的好处,这点复杂度就可以忽略了
(4)地理区域划分
比如按照华东,华南,华北这样来区分业务,七牛云应该就是如此。
(5)时间范围划分
按照时间切分,就是将6个月前,甚至一年前的数据切出去放到另外的一张表,因为随着时间流逝,这些表的数据 被查询的概率变小,所以没必要和“热数据”放在一起,这个也是“冷热数据分离”。
维度的选择方法有很多:
按时间分表:这种情况是比较普遍的选择,绝大多数业务表的场景是很少有具体的隔离情况。我们比较简单的选择就是按照时间分表,选择雪花算法,在查询的时候拦截主键,从主键中获取分表key,选择查询的范围。
举一个最常见的例子,比方说电商平台的订单表order,我们根据时间分成order_2010_2020,order_2020_2030,表示时间在2010年到2020年与2020年到2030年的表。在进行插入更新时候,选择当前时间属于的时间区间替换表名并插入,查询的时候则选择主键中的时间部分进行表名的替换再进行改写sql查询。
按id取模分表:适用于区分表的业务属性不大相关的情况,没有明显的特征,只要单纯将数据按一定规格拆分,比方说一百万条数据分成3个表,只需要id对3取余即可。
按某一字段分表:针对表中的某一字段进行分表,举个具体例子,仍然是订单表,订单里存了一个属性叫地区,按地区分表。那么只需要在每次查询的时候带上这个地区即可,同样的根据userid范围分表也是一样的道理。
按不存在于数据库的情况分表:这种情况分几种类型,即分表的字段存在数据库外,有时来自上下文,有时来自实例里的yml配置。这时候需要我们在业务层做强制路由即可实现。
小结:
垂直分表: 可以把一个宽表的字段按访问频次、是否是大字段的原则拆分为多个表,这样既能使业务清晰,还能提升部分性能。拆分后,尽量从业务角度避免联查,否则性能方面将得不偿失
垂直分库: 可以把多个表按业务耦合松紧归类,分别存放在不同的库,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能,同时能提高整体架构的业务清晰度,不同的业务库可根据自身情况定制优化方案。但是它需要解决跨库带来的所有复杂问题
水平分库: 可以把一个表的数据(按数据行)分到多个不同的库,每个库只有这个表的部分数据,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能。它不仅需要解决跨库带来的所有复杂问题,还要解决数据路由的问题
水平分表: 可以把一个表的数据(按数据行)分到多个同一个数据库的多张表中,每个表只有这个表的部分数据,这样做能小幅提升性能,它仅仅作为水平分库的一个补充优化
一般来说,在系统设计阶段就应该根据业务耦合松紧来确定垂直分库,垂直分表方案,在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案。若数据量极大,且持续增长,再考虑水平分库水平分表方案。
拆分目的:
垂直拆分:业务数据解耦
水平拆分:解决容量和性能压力

(1)使用分布式事务中间件解决,具体是通过最终一致性还是强一致性分布式事务,看业务需求。 (2)全局表:也可看做是 "数据字典表",就是系统中所有模块都可能依赖的一些表,为了避免跨库Join查询,可以将 这类表在每个数据库中都保存一份。这些数据通常很少会进行修改,所以也不担心一致性的问题。 字段冗余:利用空间换时间,为了性能而避免join查询。例:订单表保存userId时候,也将userName冗余保存一份,这样查询订单详情时就不需要再去查询"买家user表"了。 数据组装:在系统层面,分两次查询。第一次查询的结果集中找出关联数据id,然后根据id发起第二次请求得到关联数据。最后将获得到的数据进行字段拼装。
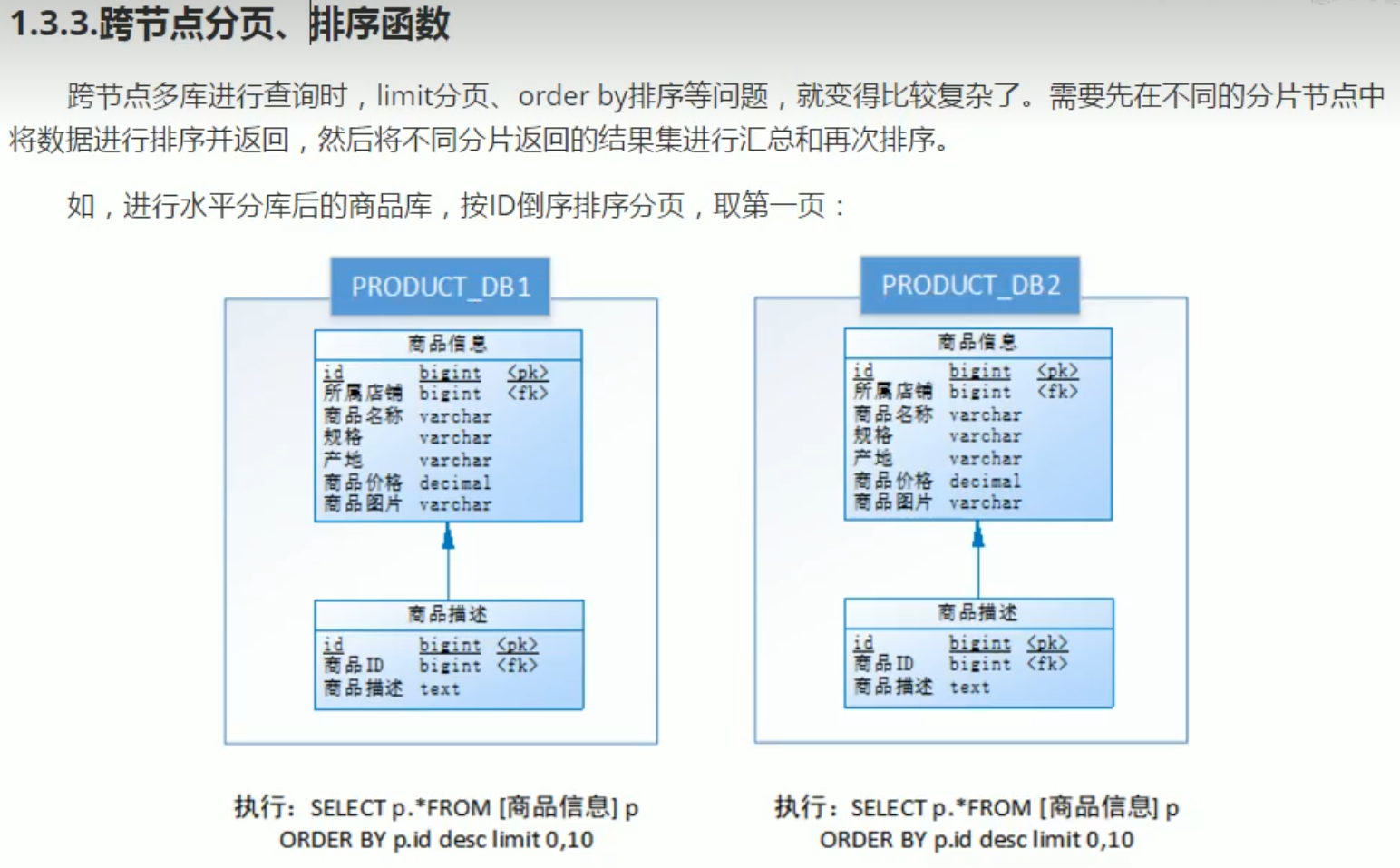
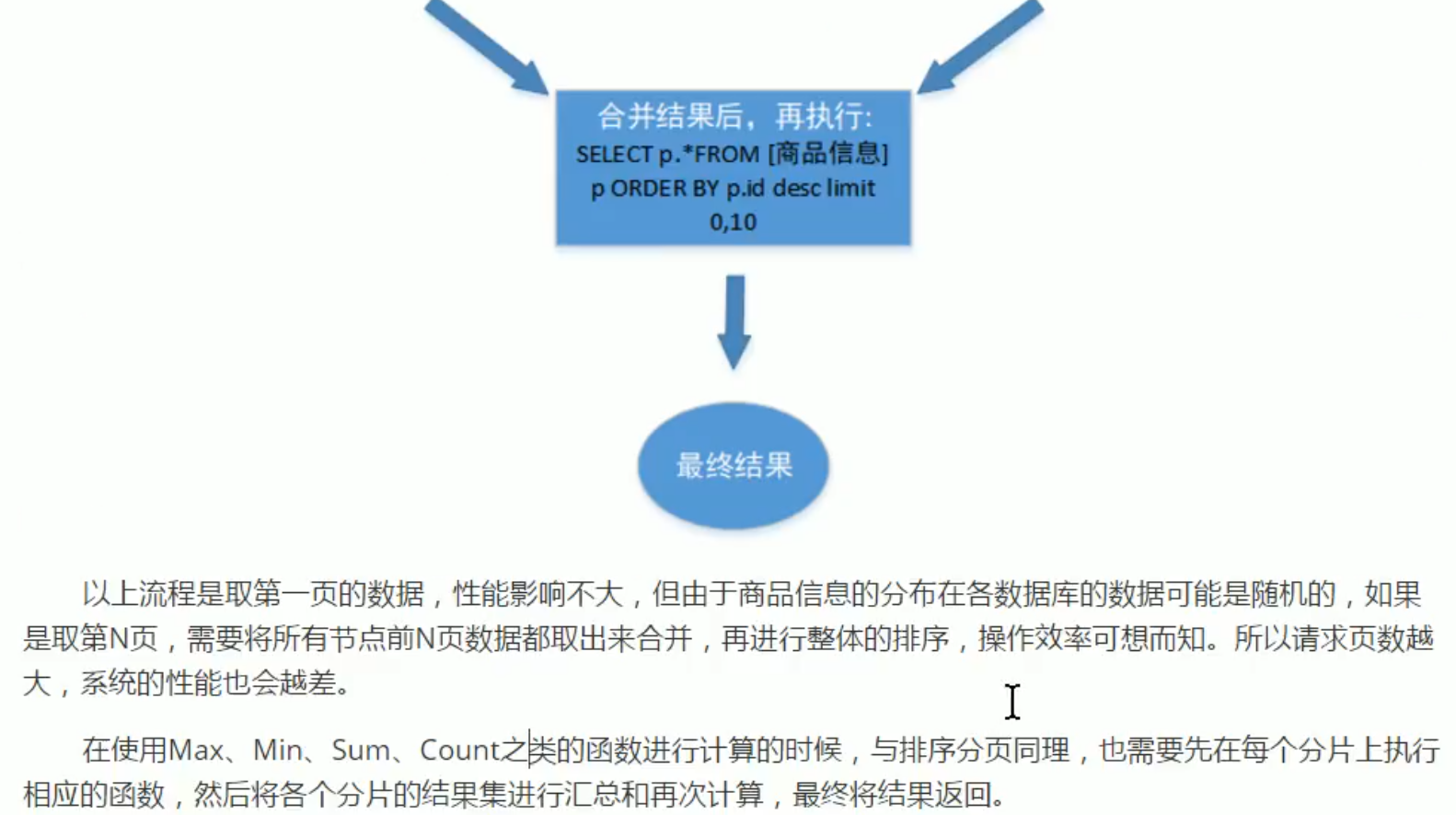
分页需要按照指定字段进行排序,当排序字段就是分片字段时,通过分片规则就比较容易定位到指定的分片;当排序字段非分片字段时,就变得比较复杂了。需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序,最终返回给用户。

可以考虑通过雪花ID来作为数据库的主键 1+41+10+12 (1024机器)

参数表、数据字典表等都是数据量较小,变动少的公共表,属于高频联合查询的依赖表。分库分表后,我们需要将这类表在每个数据库都保存一份,所有对公共表的更新操作都同时发送到所有分库执行。

ShardingSphere-JDBC
当当网写的,定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库

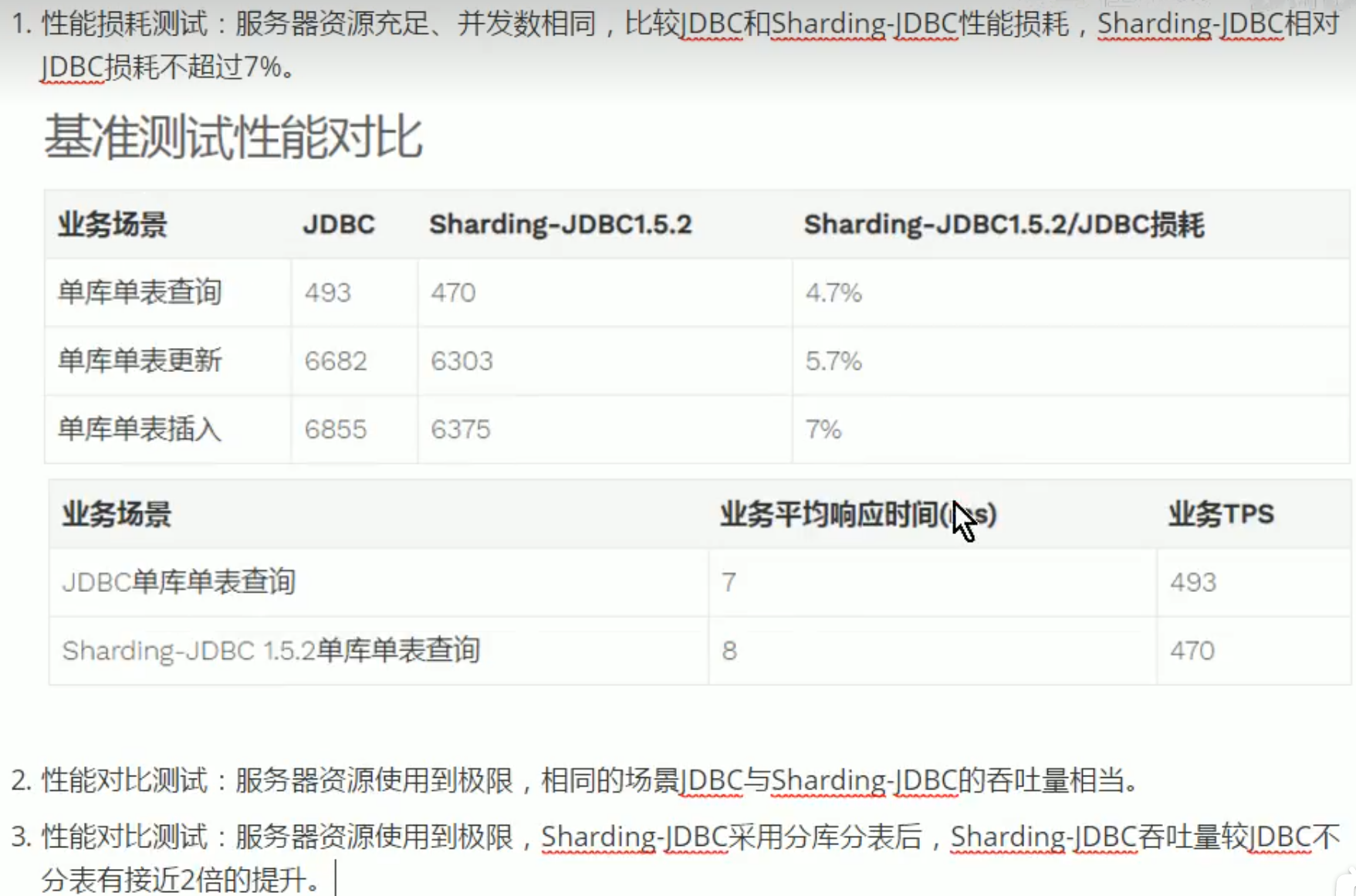
与JDBC性能对比:


程序员写:insert into t_order(price,user_id,status) values(?,?,?) sharding-jdbc重写: (1)根据雪花算法生成主键order_id (2)算出(t_order_$--->{order_id%2+1})具体要插入哪个表,t_order_2 (3)改写为insert into t_order_2(price,user_id,status,order_id) values(?,?,?,?)
(4)将所有真正执行sql的结果进行汇总合并,并返回
分片策略:分片健(order_id)和分片算法===》根据分片策略改写sql
一些概念:
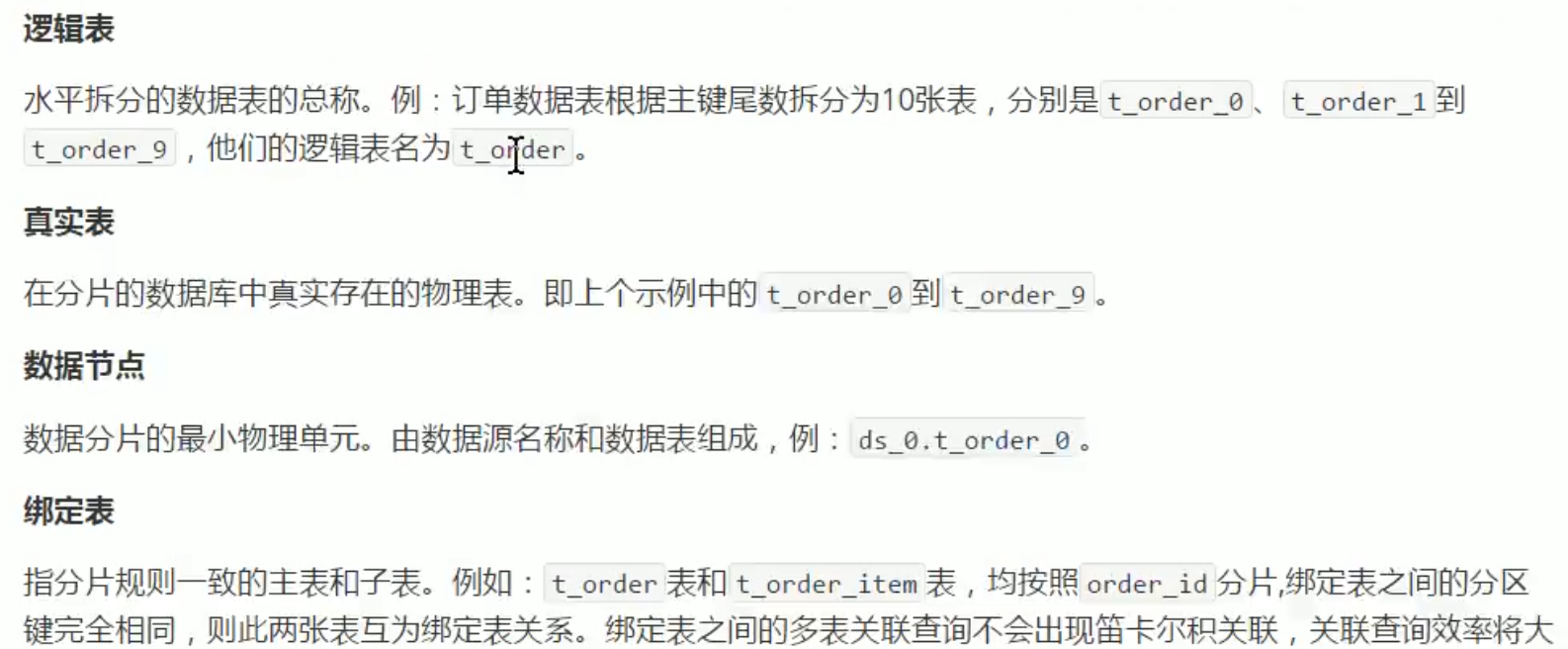
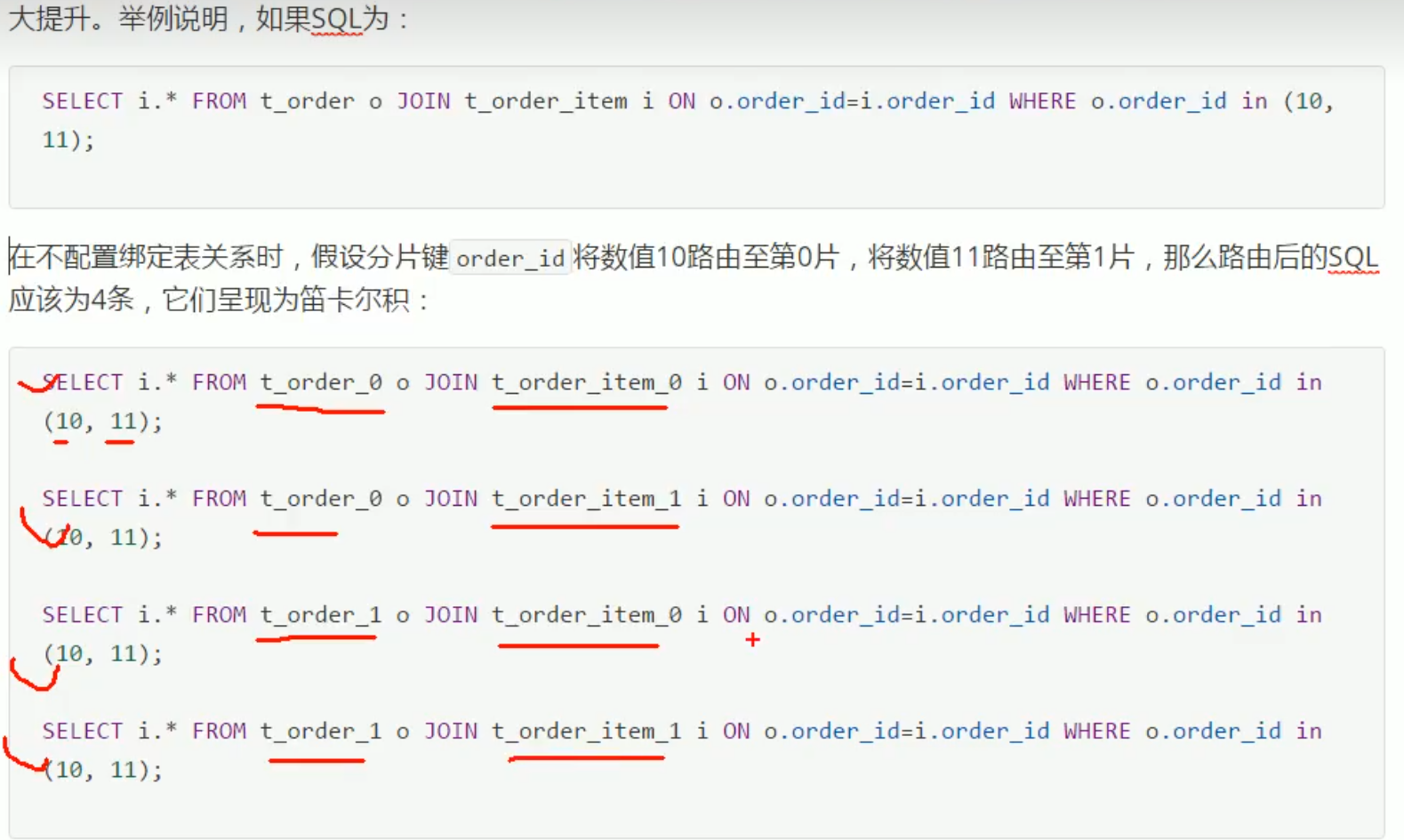
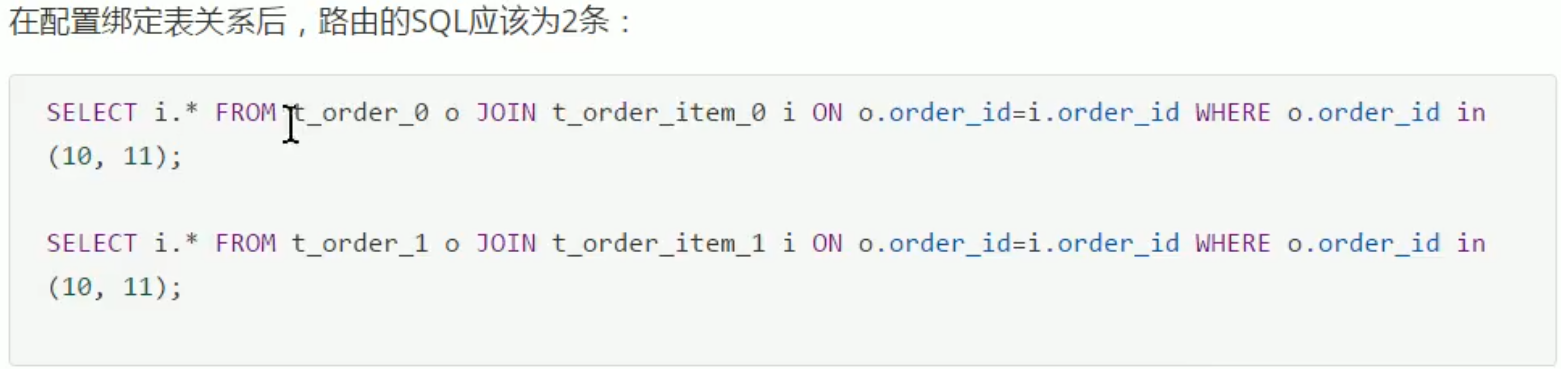
配置绑定表关系后,就知道t_order_0和t_order_item_0在一个数据库,就可以直接查一次获取结果。


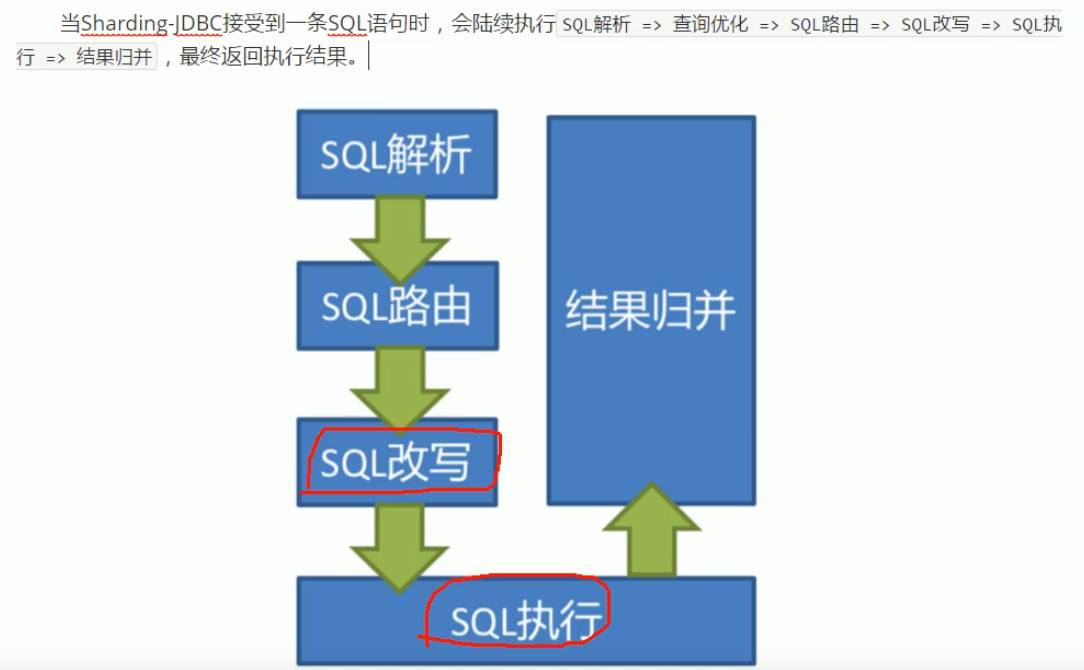
SQL解析:在整个语法树上标记,哪里可以被改写
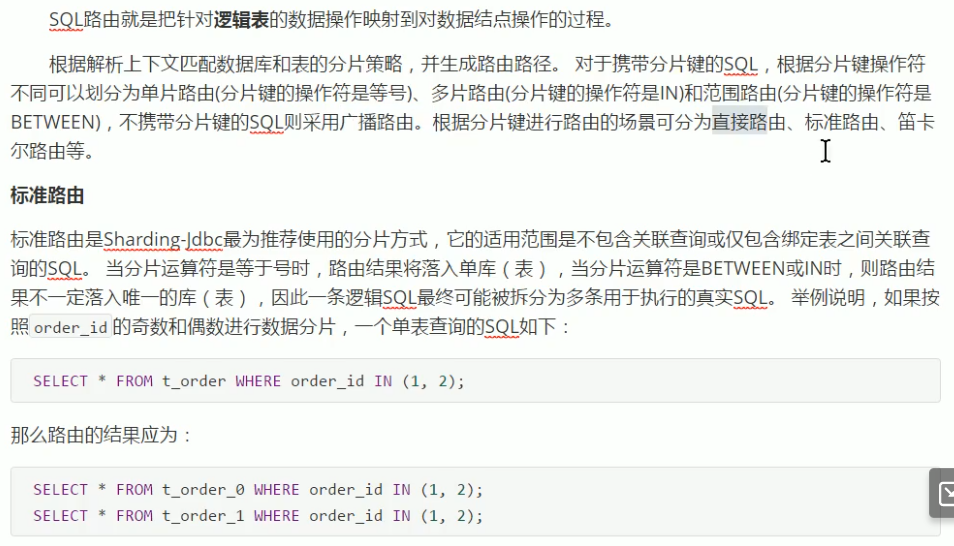
SQL路由:把针对逻辑表的数据操作映射到对数据节点操作的过程(不带分片键的sql广播路由:select * from t_order==>改写查两个表)
SQL改写:把逻辑SQL改成真实SQL
SQL执行:自动化的执行引擎:内存限制模式(SQL执行效率最大化 OLAP面向分析系统中越快越好)、连接限制模式(OLTP面向事务的系统中,需要保证事务,可能只创建唯一数据库连接对200张表串行处理)
SQL结果归并:从多个数据节点获取的多结果数据集,组合起来并进行(遍历、排序、分组、分页、聚合)操作,返回至客户
(内存归并(统一处理)、流式归并、装饰者归并
流式归并

sharding-jdbc总结:

水平分库
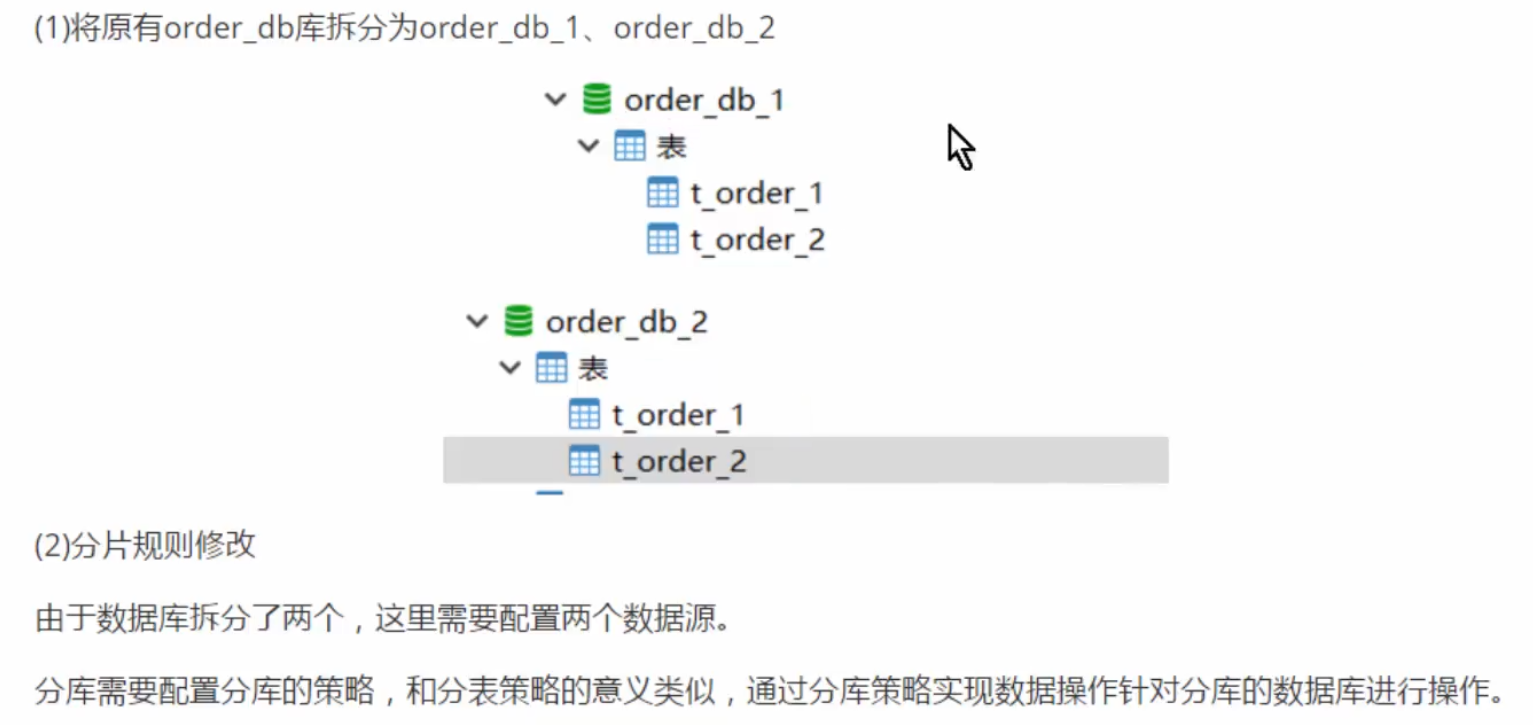

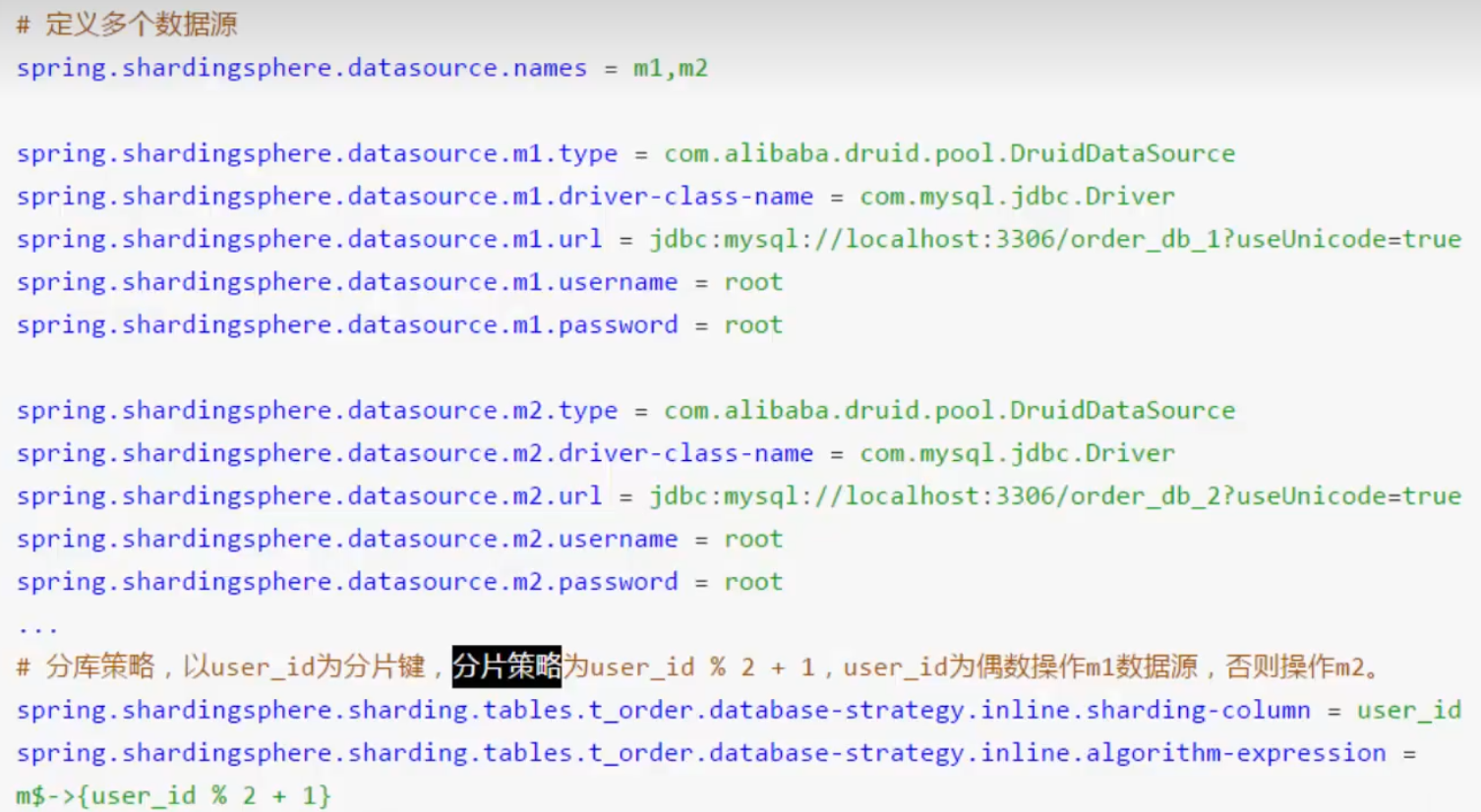
先根据user_id,将数据分至对应库
再根据order_id,将数据分至相应表
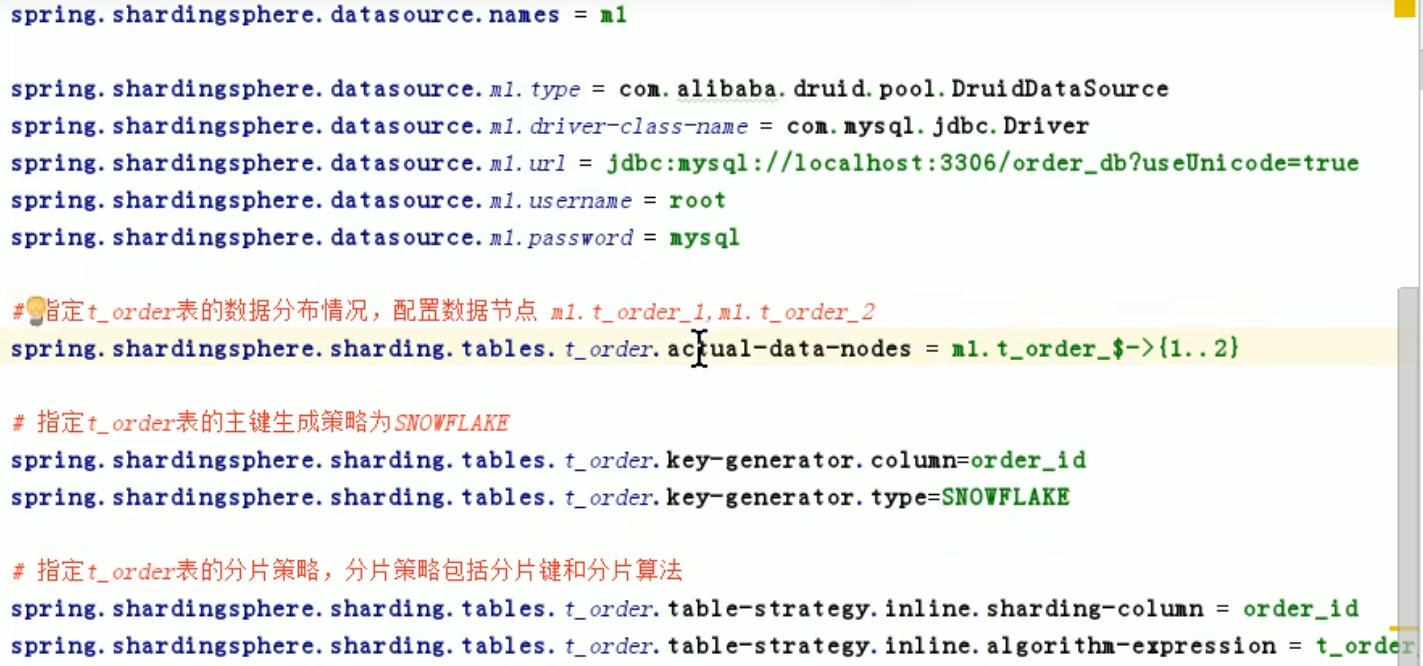
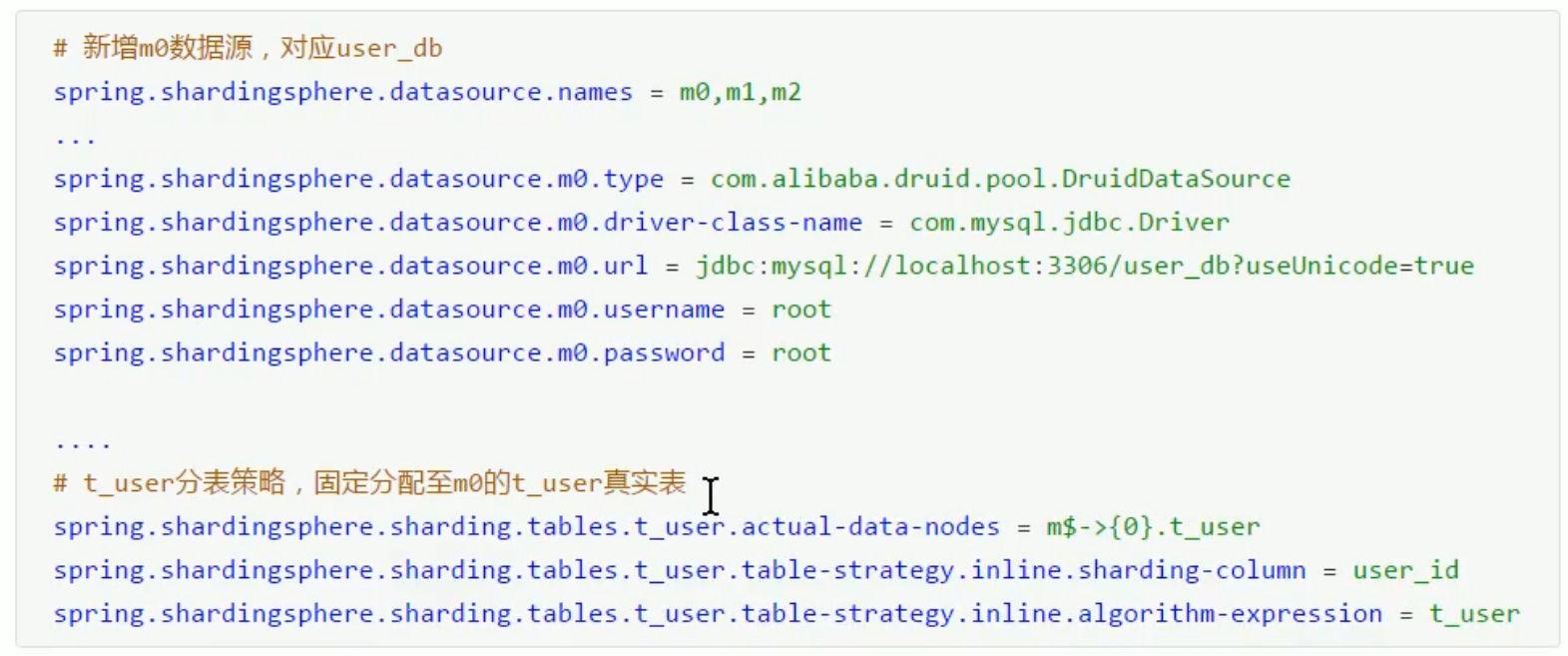
spring.shardingsphere.datasource.names= #数据源名称,多数据源以逗号分隔 spring.shardingsphere.datasource.<data-source-name>.type= #数据库连接池类名称 spring.shardingsphere.datasource.<data-source-name>.driver-class-name= #数据库驱动类名 spring.shardingsphere.datasource.<data-source-name>.url= #数据库url连接 spring.shardingsphere.datasource.<data-source-name>.username= #数据库用户名 spring.shardingsphere.datasource.<data-source-name>.password= #数据库密码 spring.shardingsphere.datasource.<data-source-name>.xxx= #数据库连接池的其它属性 spring.shardingsphere.sharding.tables.<logic-table-name>.actual-data-nodes= #由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点。用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况 #分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一 #用于单分片键的标准分片场景 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.standard.sharding-column= #分片列名称 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.standard.precise-algorithm-class-name= #精确分片算法类名称,用于=和IN。该类需实现PreciseShardingAlgorithm接口并提供无参数的构造器 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.standard.range-algorithm-class-name= #范围分片算法类名称,用于BETWEEN,可选。该类需实现RangeShardingAlgorithm接口并提供无参数的构造器 #用于多分片键的复合分片场景 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.complex.sharding-columns= #分片列名称,多个列以逗号分隔 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.complex.algorithm-class-name= #复合分片算法类名称。该类需实现ComplexKeysShardingAlgorithm接口并提供无参数的构造器 #行表达式分片策略 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.inline.sharding-column= #分片列名称 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.inline.algorithm-expression= #分片算法行表达式,需符合groovy语法 #Hint分片策略 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.hint.algorithm-class-name= #Hint分片算法类名称。该类需实现HintShardingAlgorithm接口并提供无参数的构造器 #分表策略,同分库策略 spring.shardingsphere.sharding.tables.<logic-table-name>.table-strategy.xxx= #省略 spring.shardingsphere.sharding.tables.<logic-table-name>.key-generator.column= #自增列名称,缺省表示不使用自增主键生成器 spring.shardingsphere.sharding.tables.<logic-table-name>.key-generator.type= #自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID/LEAF_SEGMENT spring.shardingsphere.sharding.tables.<logic-table-name>.key-generator.props.<property-name>= #属性配置, 注意:使用SNOWFLAKE算法,需要配置worker.id与max.tolerate.time.difference.milliseconds属性。若使用此算法生成值作分片值,建议配置max.vibration.offset属性 spring.shardingsphere.sharding.binding-tables[0]= #绑定表规则列表 spring.shardingsphere.sharding.binding-tables[1]= #绑定表规则列表 spring.shardingsphere.sharding.binding-tables[x]= #绑定表规则列表 spring.shardingsphere.sharding.broadcast-tables[0]= #广播表规则列表 spring.shardingsphere.sharding.broadcast-tables[1]= #广播表规则列表 spring.shardingsphere.sharding.broadcast-tables[x]= #广播表规则列表 spring.shardingsphere.sharding.default-data-source-name= #未配置分片规则的表将通过默认数据源定位 spring.shardingsphere.sharding.default-database-strategy.xxx= #默认数据库分片策略,同分库策略 spring.shardingsphere.sharding.default-table-strategy.xxx= #默认表分片策略,同分表策略 spring.shardingsphere.sharding.default-key-generator.type= #默认自增列值生成器类型,缺省将使用org.apache.shardingsphere.core.keygen.generator.impl.SnowflakeKeyGenerator。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID/LEAF_SEGMENT spring.shardingsphere.sharding.default-key-generator.props.<property-name>= #自增列值生成器属性配置, 比如SNOWFLAKE算法的worker.id与max.tolerate.time.difference.milliseconds spring.shardingsphere.props.sql.show= #是否开启SQL显示,默认值: false spring.shardingsphere.props.executor.size= #工作线程数量,默认值: CPU核数

垂直分库

(1)建数据库
(2)修改配置(配置数据源、数据节点、分片策略等)
(3)数据操作
读写分离:
提高数据库性能的一种方法,主数据库负责写,从数据库负责读,常用方式有一主一从,一主多从,双主等。
sharding-jdbc提供的是一主多从方式,但是不能帮助实现主从同步(mysql可以自己实现)
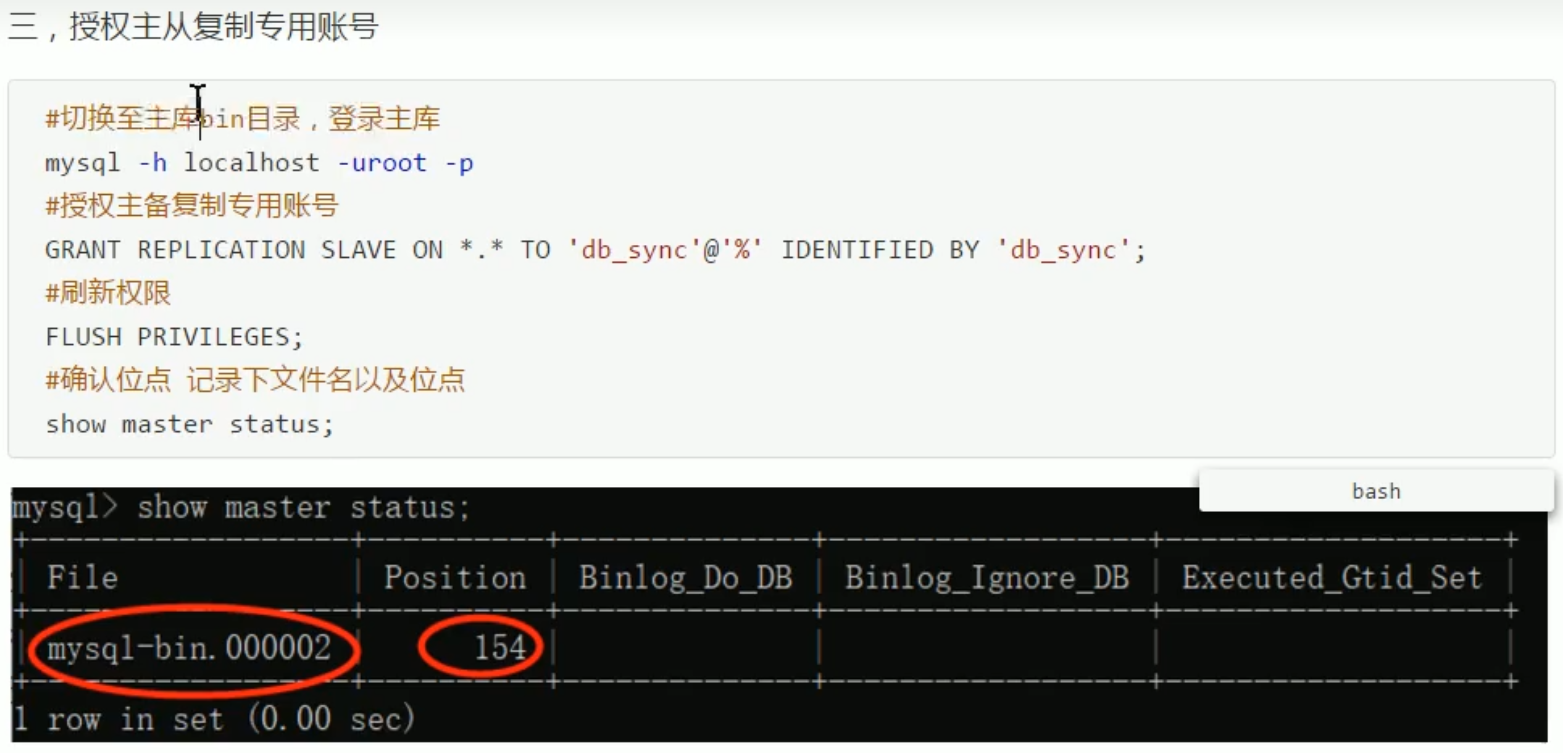
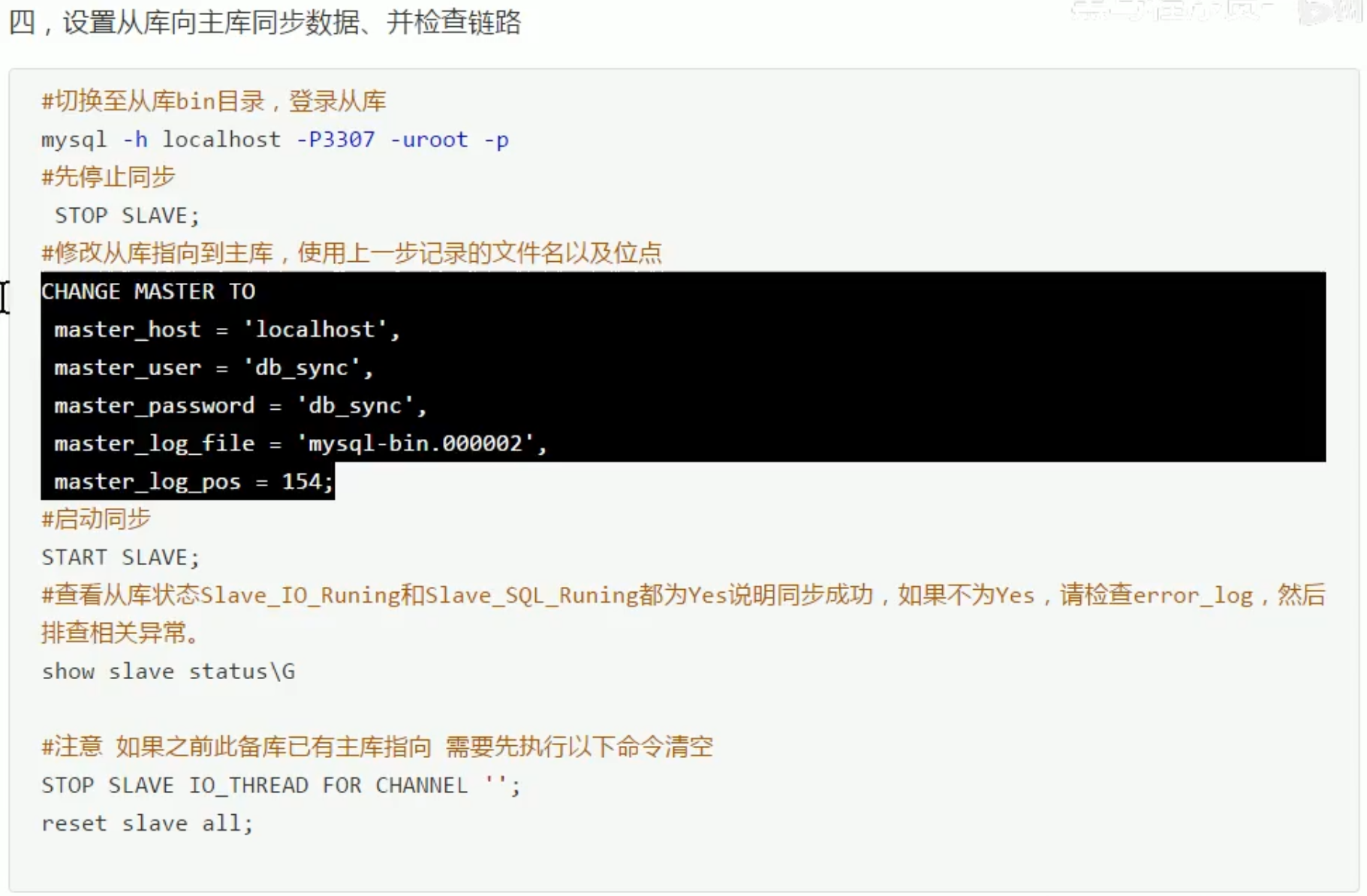
MySQL主从同步:
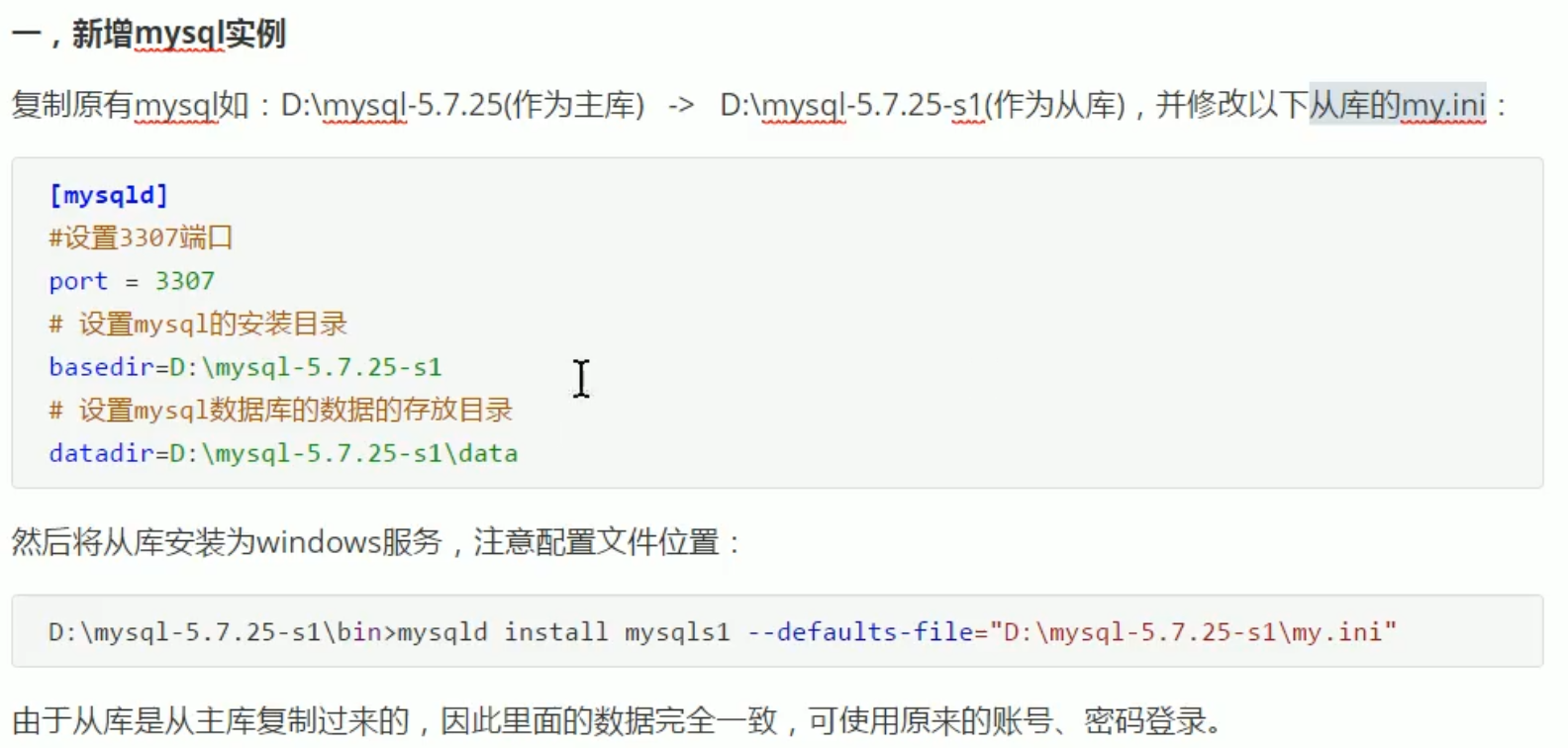

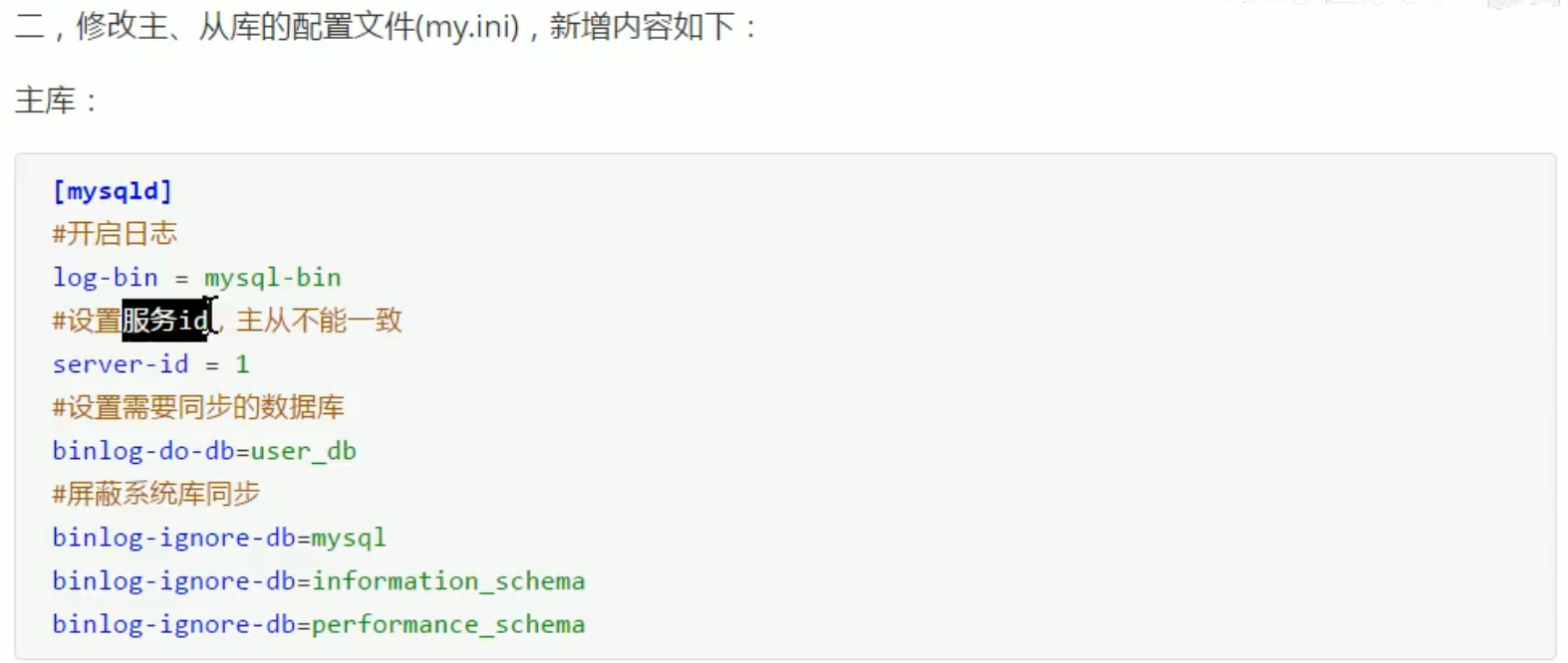
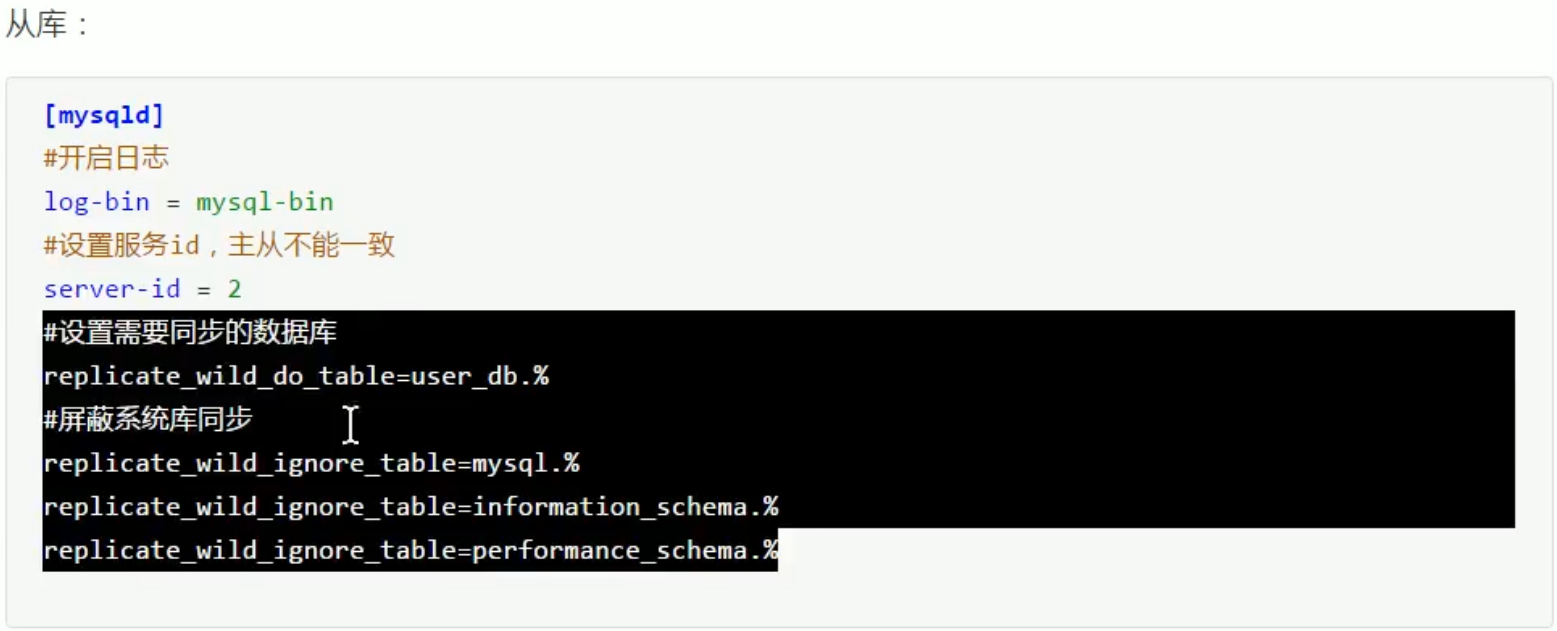
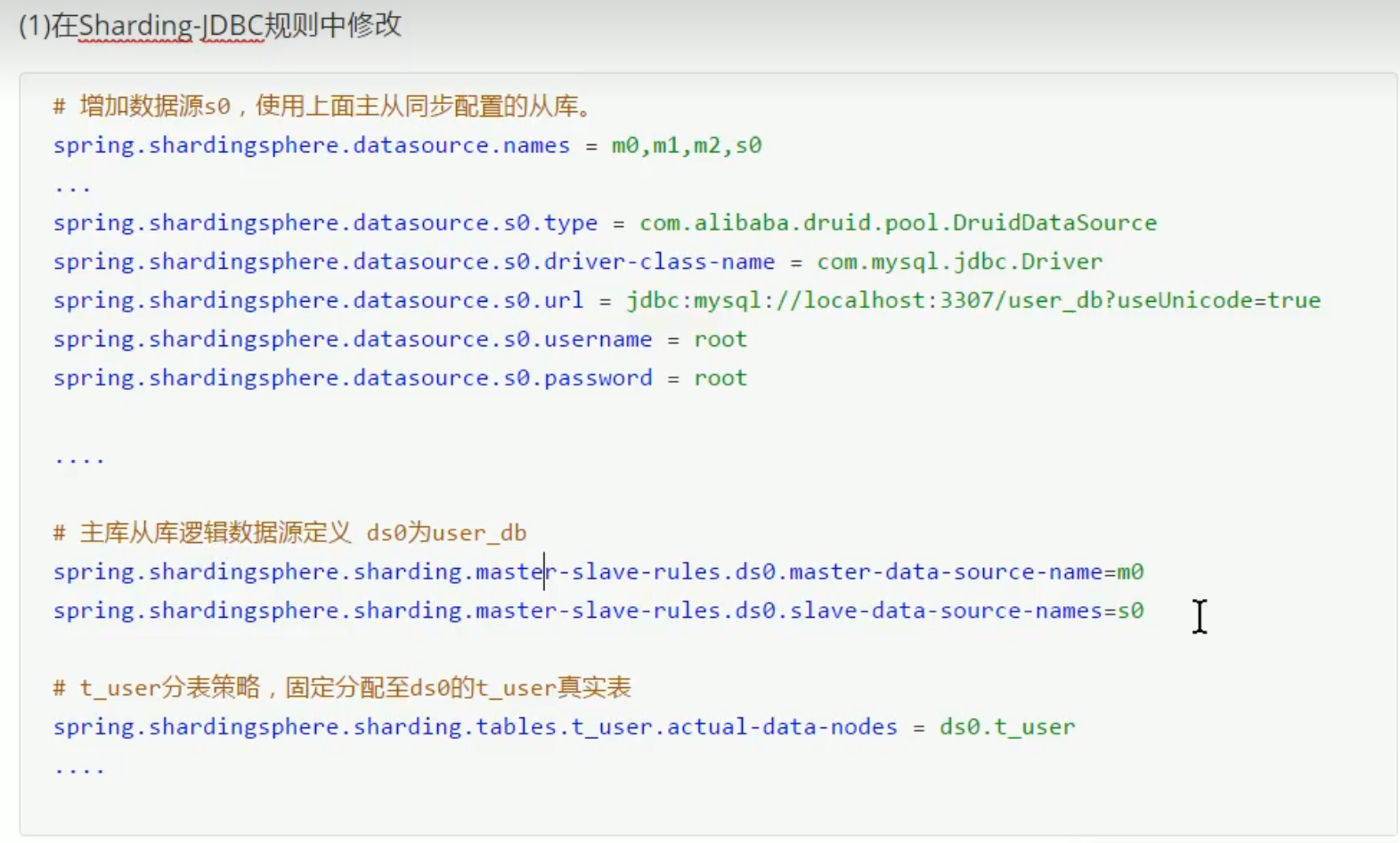
实现sharding-jdbc读写分离:
分库分表后的分页查询:
分库分表有没有什么比较推荐的方案?
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
ShardingSphere 项目(包括 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar)是当当捐入 Apache 的,目前主要由京东数科的一些巨佬维护。
ShardingSphere 绝对可以说是当前分库分表的首选!ShardingSphere 的功能完善,除了支持读写分离和分库分表,还提供分布式事务、数据库治理、影子库、数据加密和脱敏等功能。
ShardingSphere 提供的功能如下:
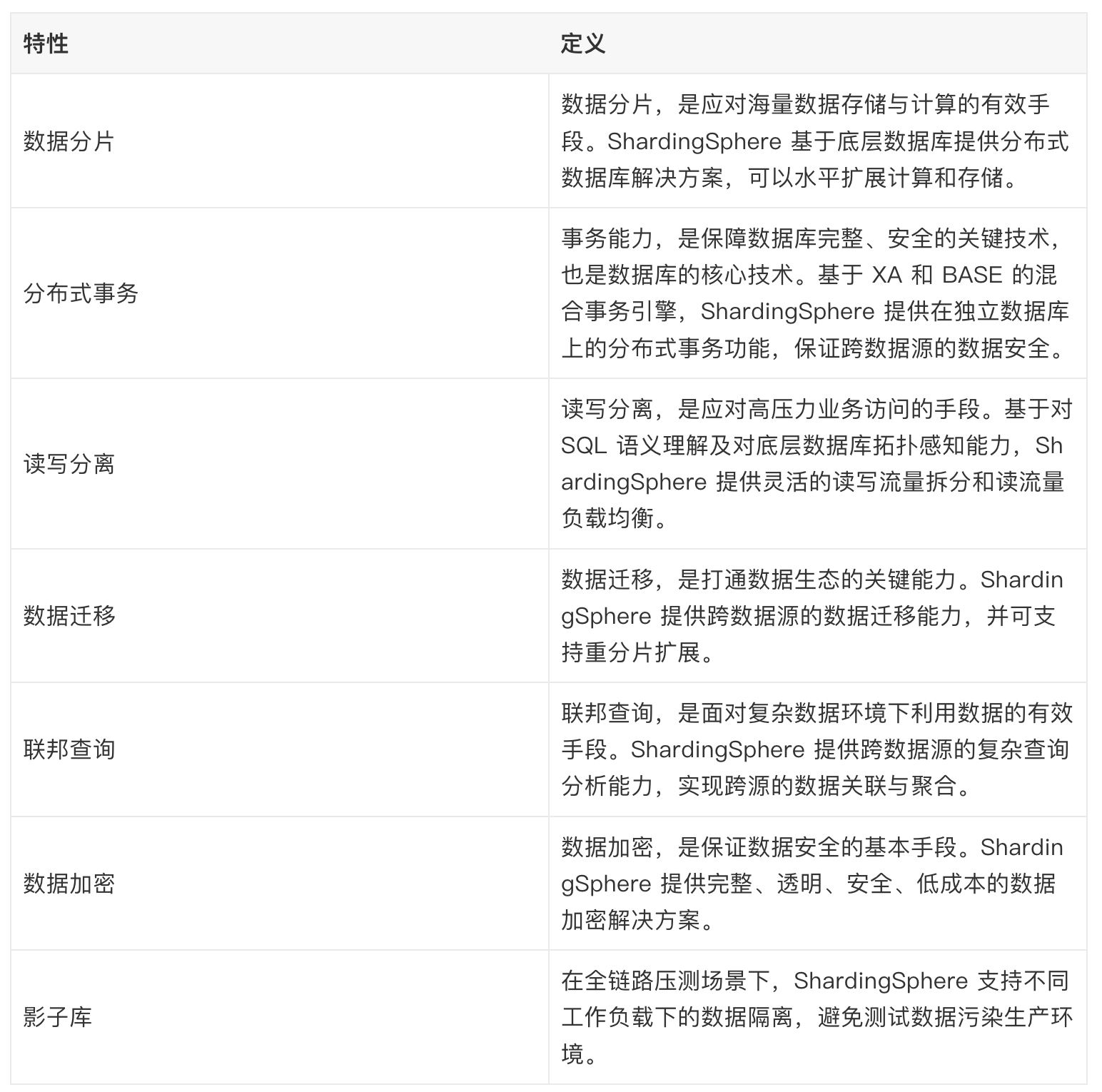 ShardingSphere 提供的功能
ShardingSphere 提供的功能
ShardingSphere 的优势如下(摘自 ShardingSphere 官方文档:https://shardingsphere.apache.org/document/current/cn/overview/
ShardingSphere 的优势如下:
- 极致性能:驱动程序端历经长年打磨,效率接近原生 JDBC,性能极致。
- 生态兼容:代理端支持任何通过 MySQL/PostgreSQL 协议的应用访问,驱动程序端可对接任意实现 JDBC 规范的数据库。
- 业务零侵入:面对数据库替换场景,ShardingSphere 可满足业务无需改造,实现平滑业务迁移。
- 运维低成本:在保留原技术栈不变前提下,对 DBA 学习、管理成本低,交互友好。
- 安全稳定:基于成熟数据库底座之上提供增量能力,兼顾安全性及稳定性。
- 弹性扩展:具备计算、存储平滑在线扩展能力,可满足业务多变的需求。
- 开放生态:通过多层次(内核、功能、生态)插件化能力,为用户提供可定制满足自身特殊需求的独有系统。
分库分表后,数据怎么迁移呢?
分库分表之后,我们如何将老库(单库单表)的数据迁移到新库(分库分表后的数据库系统)呢?
比较简单同时也是非常常用的方案就是停机迁移,写个脚本老库的数据写到新库中。比如你在凌晨 2 点,系统使用的人数非常少的时候,挂一个公告说系统要维护升级预计 1 小时。然后,你写一个脚本将老库的数据都同步到新库中。
如果你不想停机迁移数据的话,也可以考虑双写方案。双写方案是针对那种不能停机迁移的场景,实现起来要稍微麻烦一些。具体原理是这样的:
- 我们对老库的更新操作(增删改),同时也要写入新库(双写)。如果操作的数据不存在于新库的话,需要插入到新库中。 这样就能保证,咱们新库里的数据是最新的。
- 在迁移过程,双写只会让被更新操作过的老库中的数据同步到新库,我们还需要自己写脚本将老库中的数据和新库的数据做比对。如果新库中没有,那咱们就把数据插入到新库。如果新库有,旧库没有,就把新库对应的数据删除(冗余数据清理)。
- 重复上一步的操作,直到老库和新库的数据一致为止。
想要在项目中实施双写还是比较麻烦的,很容易会出现问题。我们可以借助上面提到的数据库同步工具 Canal 做增量数据迁移(还是依赖 binlog,开发和维护成本较低)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号