Redis生产问题
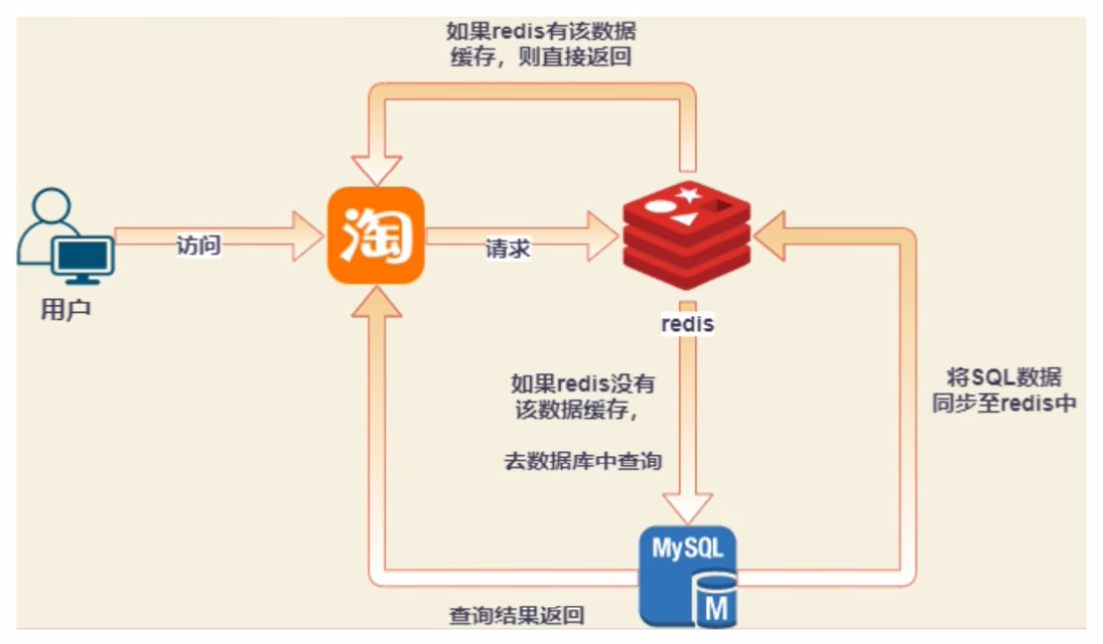
正常缓存流程:
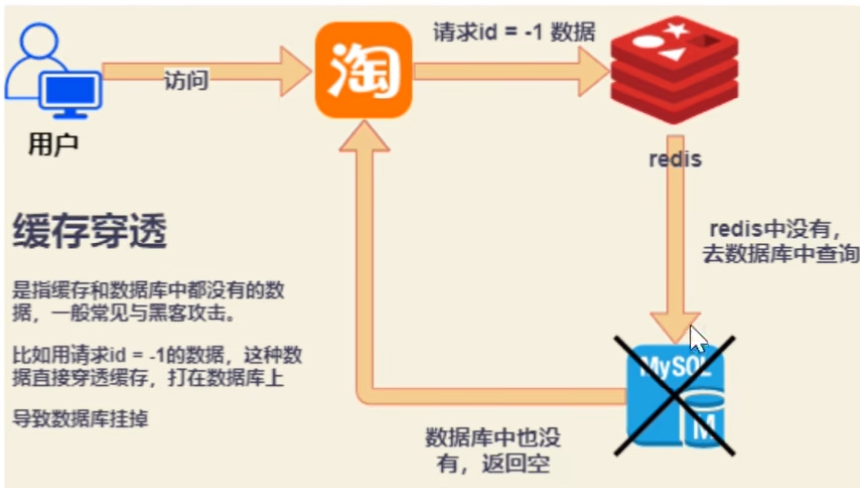
1.缓存穿透
问题来源: 缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求。由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
解决方案:
·接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截。
·从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击。
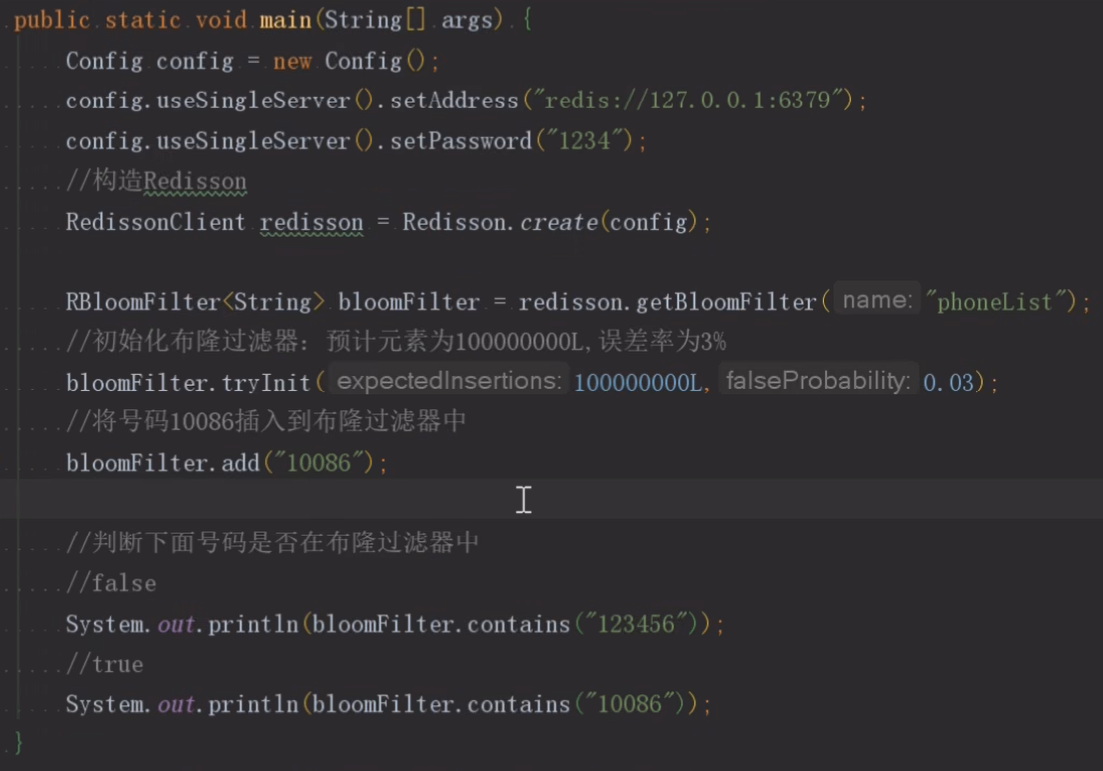
·布隆过滤器。bloomfilter就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。布隆过滤器的关键就在于hash算法和容器大小。(不同数据计算出的Hash值可能是相同的,可能出现误判,删除操作比较难) guava
2.缓存击穿
问题来源: 缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
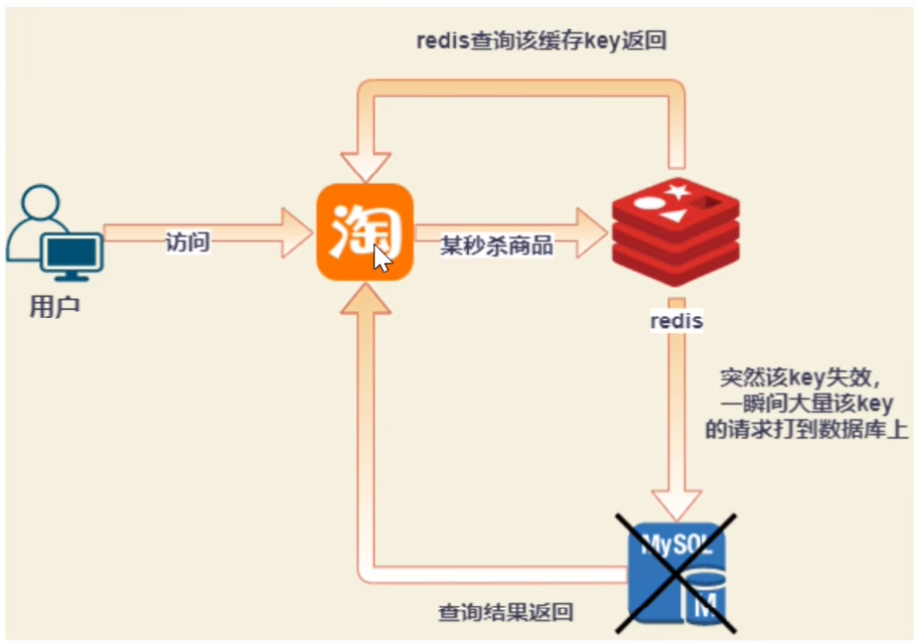
解决方案:
·设置热点数据永远不过期。
·接口限流与熔断,降级。重要的接口一定要做好限流策略,防止用户恶意刷接口,同时要降级准备,当接口中的某些服务不可用时候,进行熔断,失败快速返回机制。
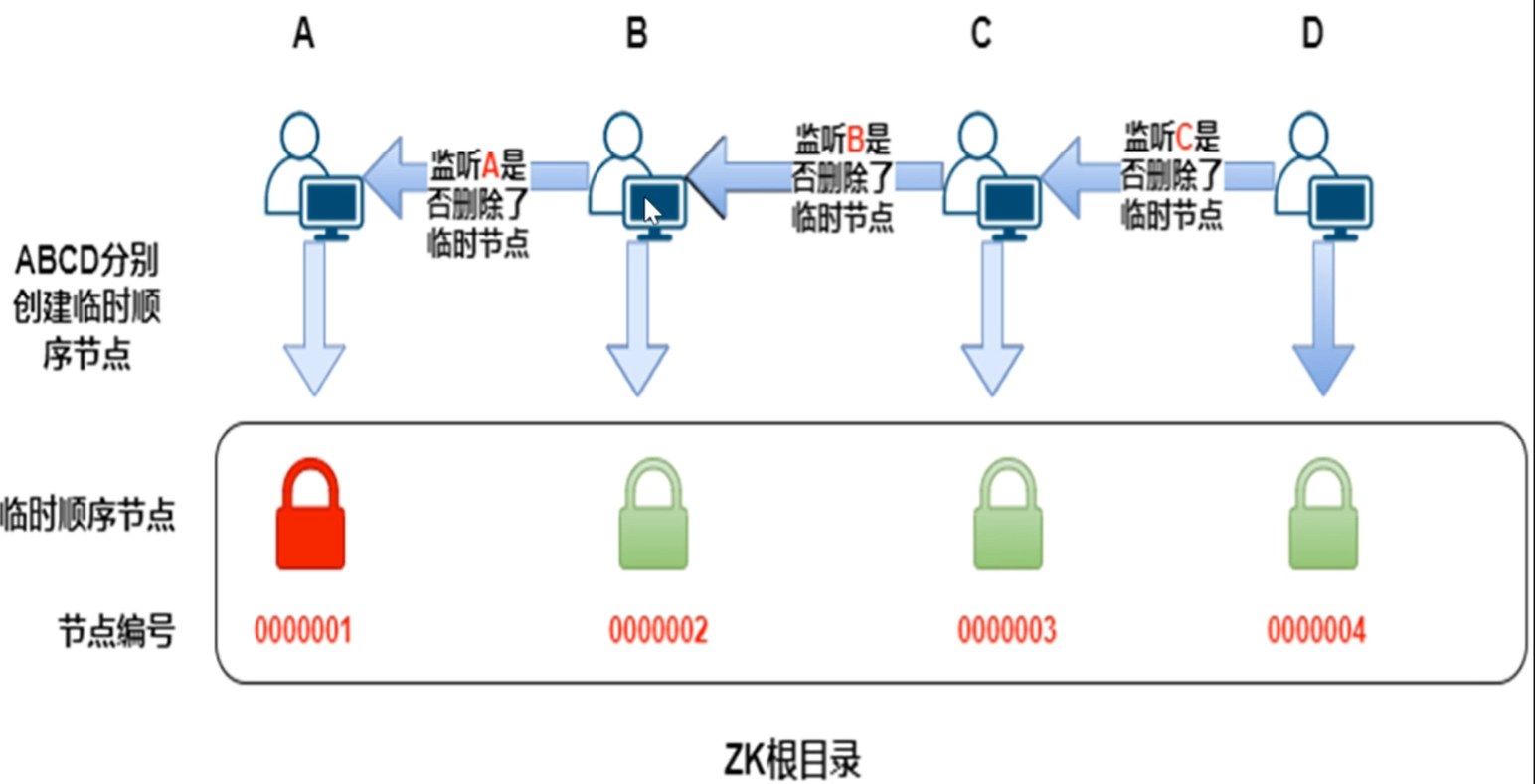
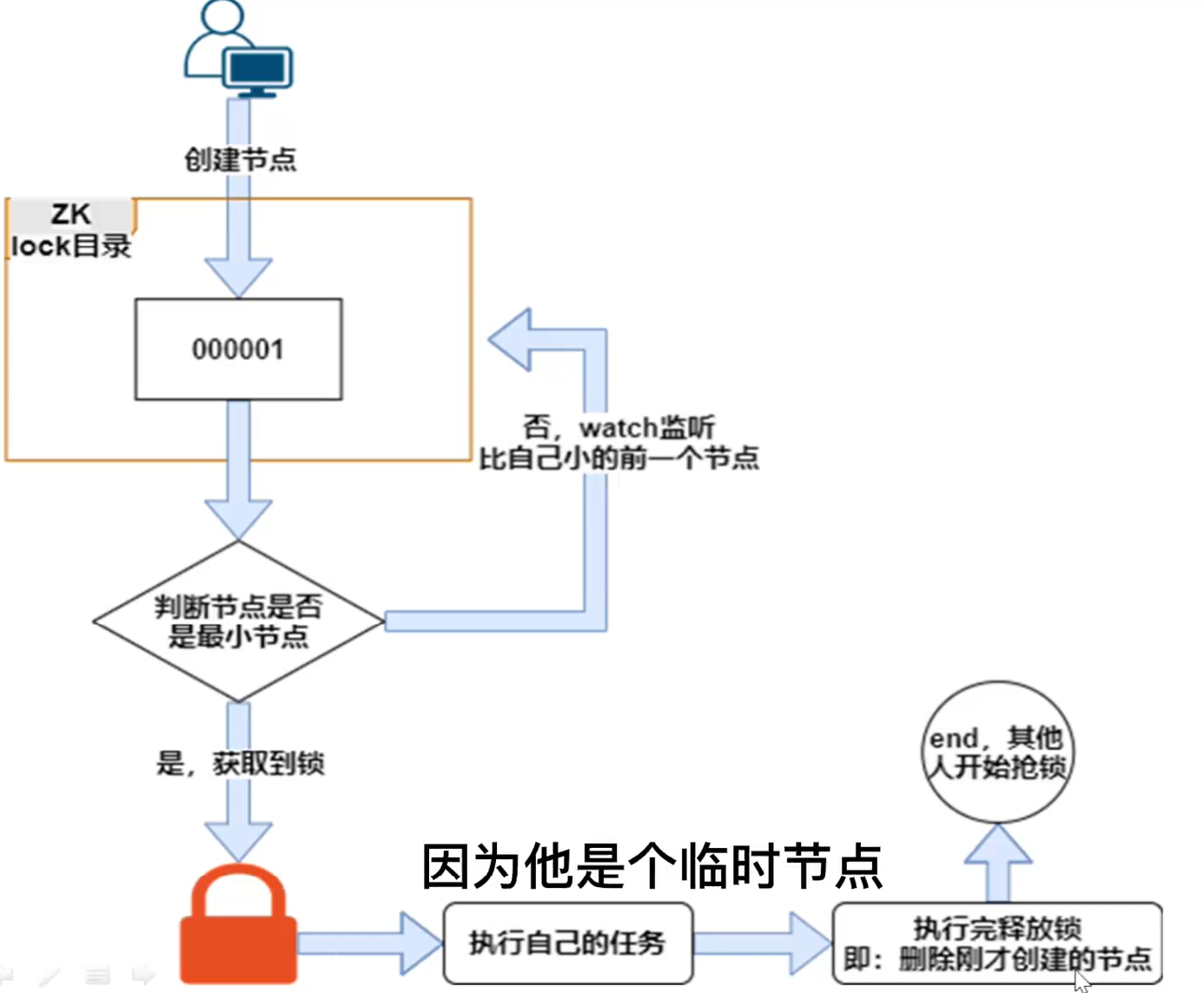
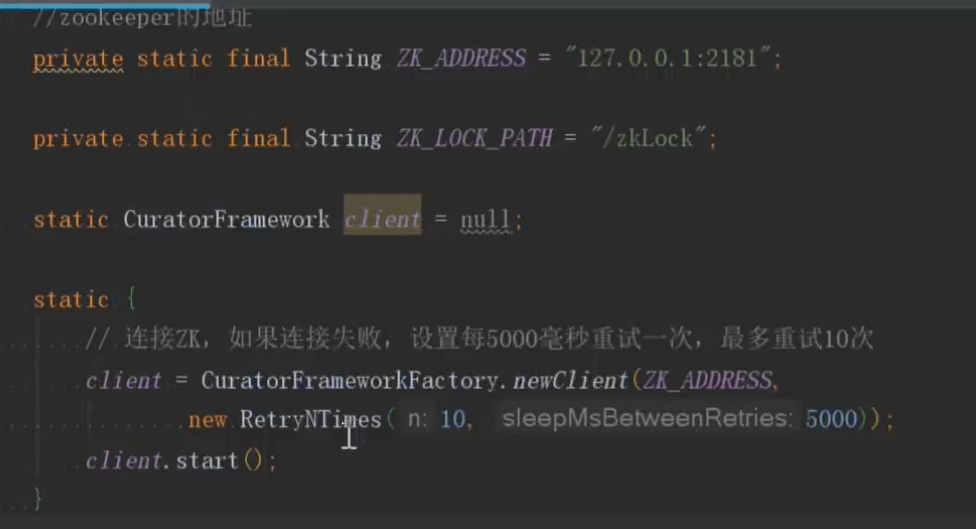
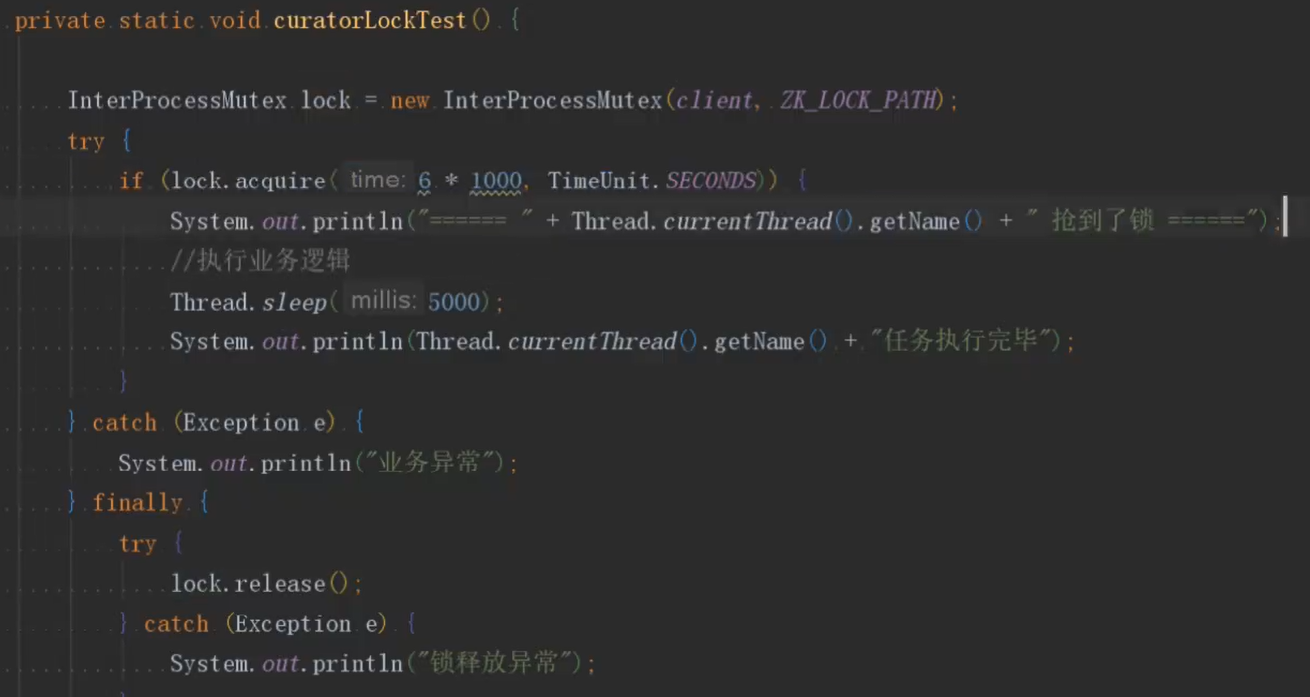
·加互斥锁:在redis请求MySQL的阶段,进行加锁,这样每次只有一个线程能抢到锁,也就是只有一个线程才能操作数据库,数据库压力减小,然后数据就会存到redis里,其他线程也不用抢锁了。
zookeeper:
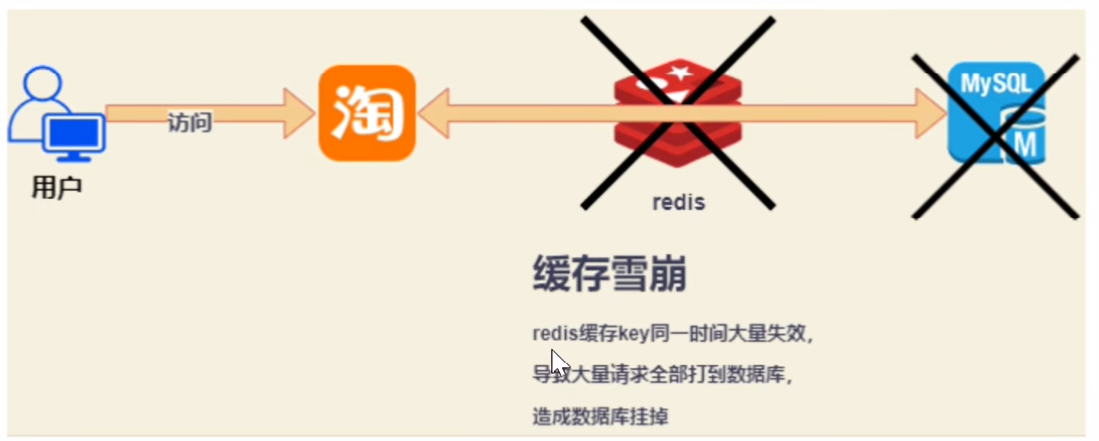
3.缓存雪崩
问题来源: 缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
·缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
·如果缓存数据库是分布式部署,将热点数据均匀分布在不同的缓存数据库中。
·设置热点数据永远不过期。
(大量缓存同时失效,导致DB负载上升影响到整个集群。缓存服务器宕机。)
4.缓存污染(缓存满了)
缓存污染问题说的是缓存中一些只会被访问一次或者几次的的数据,被访问完后,再也不会被访问到,但这部分数据依然留存在缓存中,消耗缓存空间。
应对措施:
项目上线前:redis集群、MySQL集群、项目本身的分布式集群
项目运行中:限流、降级、熔断,防止大量请求打到数据库上
项目宕机后:集成报警系统,第一时间通知开发人员,同时利用Redis的AOF和RDB等持久化机制快速恢复其缓存数据,最大程度减少系统不可用时间
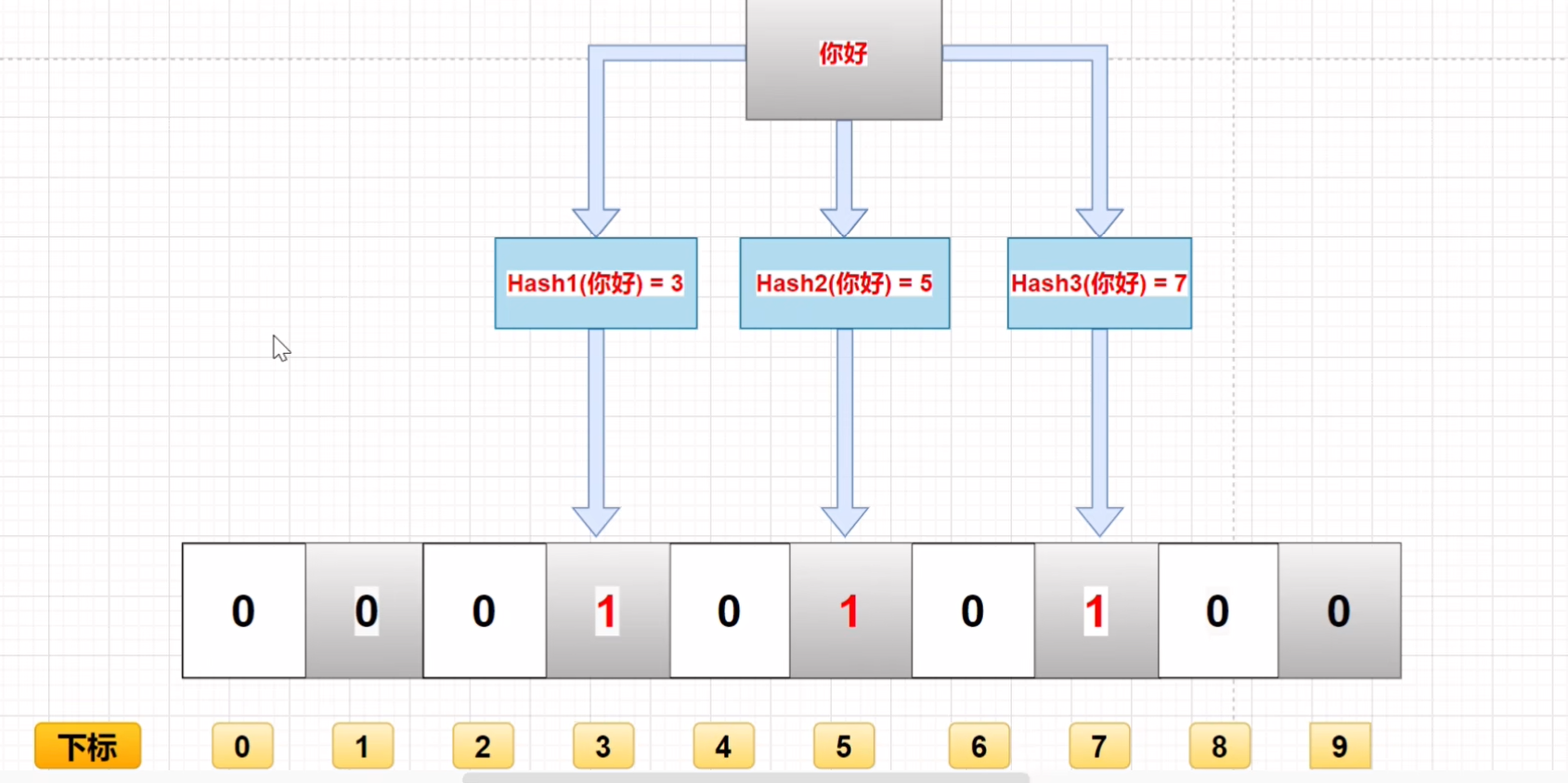
布隆过滤器(Bloom Filter)
是一种数据结构,用于快速检查一个元素是否属于某个集合中。它可以快速判断一个元素是否在一个大型集合中,且判断速度很快且不占用太多内存空间。
布隆过滤器的主要原理是使用一组哈希函数,将元素映射成一组位数组中的索引位置。
当要检查一个元素是否在集合中时,将该元素进行哈希处理,然后查看哈希值对应的位数组的值是否为1。如果哈希值对应的位数组的值都为1,那么这个元素可能在集合中,否则这个元素肯定不在集合中。
由于哈希函数的映射可能会发生冲突,因此布隆过滤器可能会出现误判,即把不在集合中的元素判断为在集合中。但是,布隆过滤器不会漏判,即不会把在集合中的元素判断为不在集合中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号