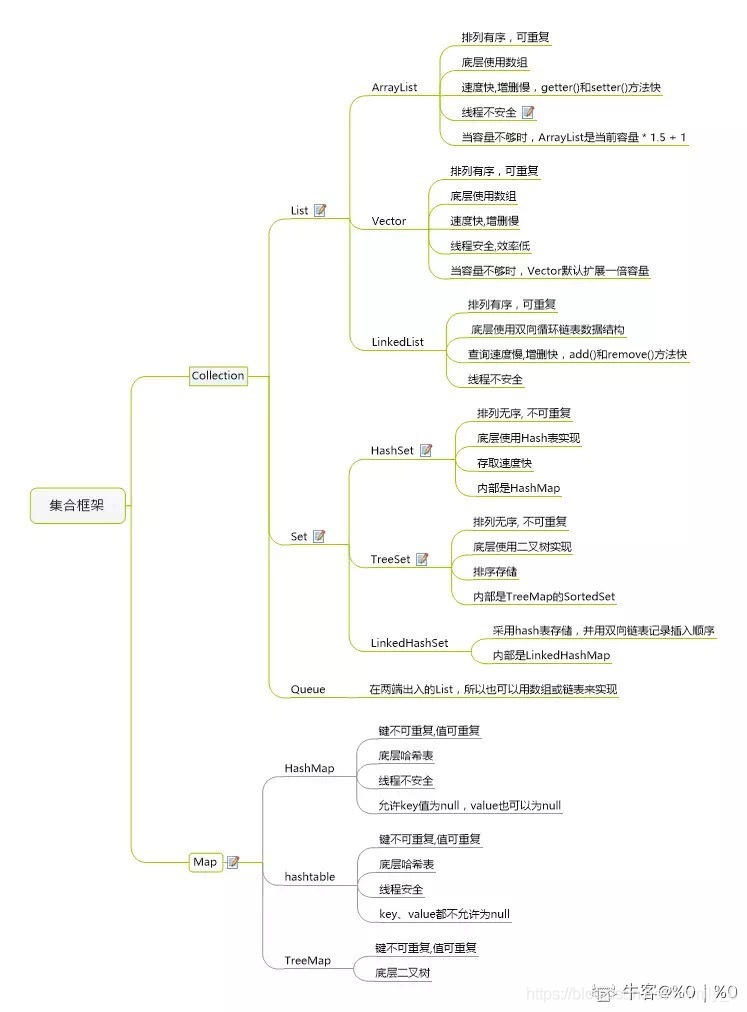
集合基础
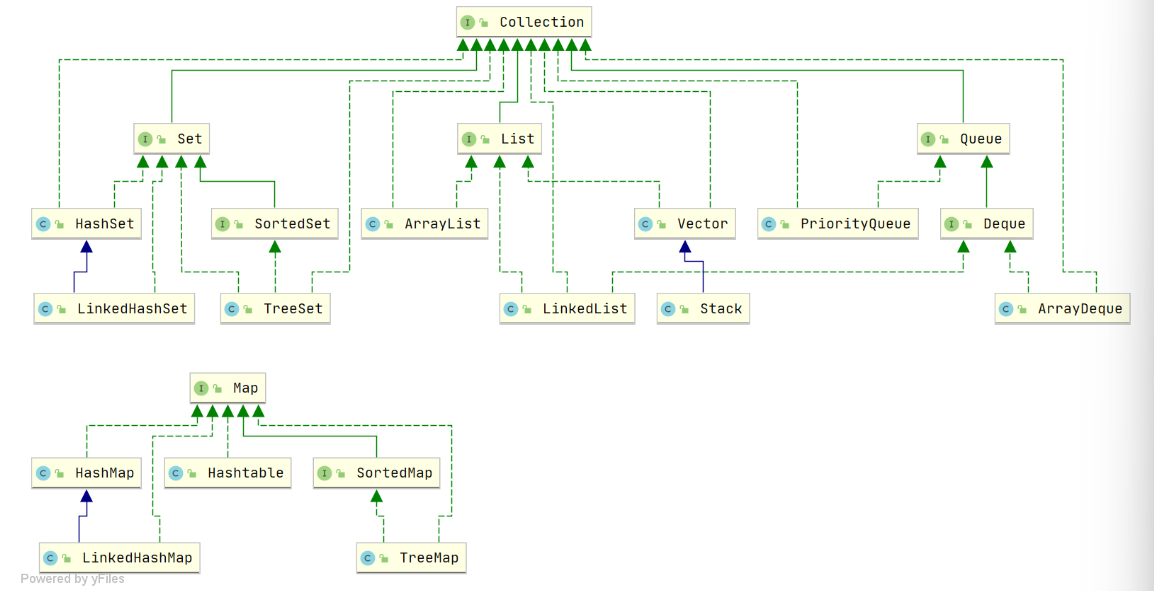
Set:无序不可重复(独一无二)
HashSet:HashMap
LinkedHashSet:LinkedHashMap(哈希表+链表),元素插入和取出顺序满足FIFO
TreeSet:红黑树(自平衡二叉排序树)
三者异同:
都是set接口的实现类,所以都能保证数据的唯一性,并且都不是线程安全的(使用了 fail-fast iterator 迭代器)(https://www.mianshigee.com/note/detail/237639vxm/)。
不同的特点由底层数据结构决定,也导致了三者的应用场景不同。
HashSet、LinkedHashSet 和 TreeSet 都是 Set 接口的实现类,都能保证元素唯一,并且都不是线程安全的。
HashSet、LinkedHashSet 和 TreeSet 的主要区别在于底层数据结构不同。
HashSet 的底层数据结构是哈希表(基于 HashMap 实现)。
LinkedHashSet 的底层数据结构是链表和哈希表,元素的插入和取出顺序满足FIFO。
TreeSet 底层数据结构是红黑树,元素是有序的,排序的方式有自然排序和定制排序。
底层数据结构不同又导致这三者的应用场景不同。
HashSet 用于不需要保证元素插入和取出顺序的场景,LinkedHashSet 用于保证元素的插入和取出顺序满足 FIFO 的场景,TreeSet 用于支持对元素自定义排序规则的场景。
线程不安全:
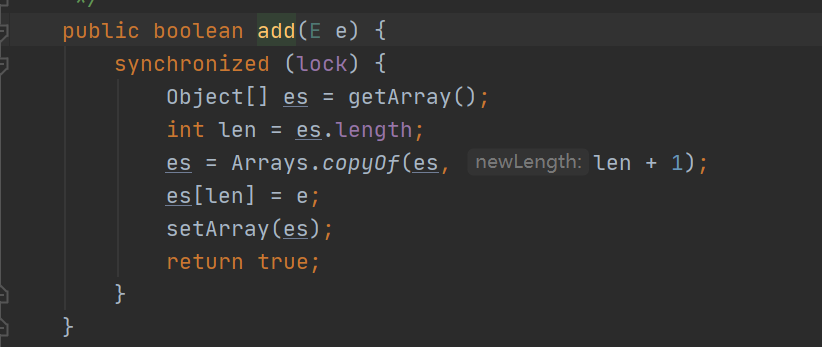
1.各个线程都读。不影响,前提是只有读; 2.各个线程都写。会出现问题,这里的点有两种情况: (1)值覆盖问题,因为 ArrayList 的底层数组,写入值的时候要先计算到一个下标位置,然后给对应的位置去赋值,多线程就会出现值覆盖的问题; (2)空指针异常,因为 ArrayList 的底层数组,写入值在数组满的时候需要扩容,在扩容还没完成的时候,新的下标却已经计算出来并且要去插入,那么就会出现空指针异常。 3.有的读有的写。那么显然对于多个线程来说,2 里面各个线程写的情况对应的问题就会出现。除此之外: (1)如果多线程有的读有的写,对于 ArrayList 底层,某些情况下,对象是不允许进行修改的,如果修改了,后面调用某些方法时,就会检测到,然后就直接抛出ConcurrentModificationException。 (2)具体一下,因为源码里,写操作对集合修改是写,而next、remove等 Itr 的遍历读操作的时候会通过当前集合的修改次数与 Itr 对象创建时记录的次数校验集合是否被修改,如果修改了,不一致就说明正读的时候还有别的线程在改,就会抛出异常。 (3)JDK作者说了,会抛这个异常的都叫fail-fast iterator。
解决方案:JUC提供CopyOnWriteArrayList、CopyOnWriteArraySet(写时复制)
List:有序可重复(排序帮手)
ArrayList:Object[] 数组
Vector:Object[] 数组
LinkedList:双向链表
Queue:有序可重复(叫号机)
PriorityQueue:Object[]数组实现二叉堆(JDK1.5引入,底层使用可变长数组,默认小顶堆,可接收Comparator作为构造参数定义优先级的先后,O(logn)插入删除,非线程安全)
Deque:双端队列
ArrayQueue:Object[]数组+双指针
Map:key无序不可重复,value无序可重复(key搜索) 不继承Collection
HashMap:数组+链表(拉链法解决哈希冲突)(JDK1.8后,当链表长度大于8,将链表转化为红黑树,减少搜索时间)
LinkedHashMap:HashMap+双向链表,使得上面的结构可以保持键值对的插入顺序,实现了访问顺序相关逻辑。
HashTable:数组+链表
TreeMap:红黑树
为什么要使用集合?
数组的缺点是一旦声明之后,长度就不可变了;同时,声明数组时的数据类型也决定了该数组存储的数据的类型;而且,数组存储的数据是有序的、可重复的,特点单一。 但是集合提高了数据存储的灵活性,Java 集合不仅可以用来存储不同类型不同数量的对象,还可以保存具有映射关系的数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号