

Apache Flink 介绍
本篇文章首发于我的微信公众号大数据技术和人工智能,欢迎关注我的头条号和微信公众号“大数据技术和人工智能”(微信搜索bigdata_ai_tech)获取更多干货,也欢迎关注我的CSDN博客。
本文简单介绍一下Flink,部分内容来源于网络,想深入了解Flink的读者可以参照官方文档深入学习Apache Flink。
流计算
在介绍Flink之前首先说一下流计算的概念,流计算是针对流式数据的实时计算。
- 流式数据是指将数据看作数据流的形式来处理,数据流是在时间分布和数量上无限的一系列动态数据集合体,数据记录是数据流的最小组成单元。
- 流数据具有数据实时持续不断到达、到达次序独立、数据来源众多格式复杂、数据规模大且不十分关注存储、注重数据的整体价值而不关注个别数据等特点。
Apache Flink是什么
Apache Flink是一个分布式流批一体化的开源平台。Flink的核心是一个提供数据分发、通信以及自动容错的流计算引擎。Flink在流计算之上构建批处理,并且原生的支持迭代计算、内存管理以及程序优化。官方称之为Stateful Computations over Data Streams,即数据流上有状态计算。官方对Flink的详细介绍What is Apache Flink。
Flink的特点
现有的开源计算方案会把流处理和批处理作为两种不同的应用类型(如Apache Storm只支持流处理,Apache Spark只支持批(Micro Batching)处理),流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效率。Flink同时支持流处理和批处理,作为流处理时输入数据流是无界的,批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。
Flink重要基石
Apache Flink的四个重要基石:Checkpoint、State、Time、Window
- Checkpoint:基于Chandy-Lamport算法实现了分布式一致性快照,提供了一致性的语义
- State:丰富的State API,包括ValueState、ListState、MapState、BoardcastState
- Time:实现了Watermark机制,能够支持基于事件的时间的处理,能够容忍数据的延时、迟到和乱序
- Window:开箱即用的窗口,滚动窗口、滑动窗口、会话窗口和灵活的自定义窗口
Flink的优势
- 支持高吞吐、低延迟、高性能的流数据处理
- 支持高度灵活的窗口(Window)操作
- 支持有状态计算的Exactly-once语义
- 提供DataStream API和DataSet API
适用场景
Flink支持下面这三种最常见类型的应用示例,官网有详细的介绍Use Cases。
- 事件驱动的应用程序
- 数据分析应用
- 数据管道应用
基础架构
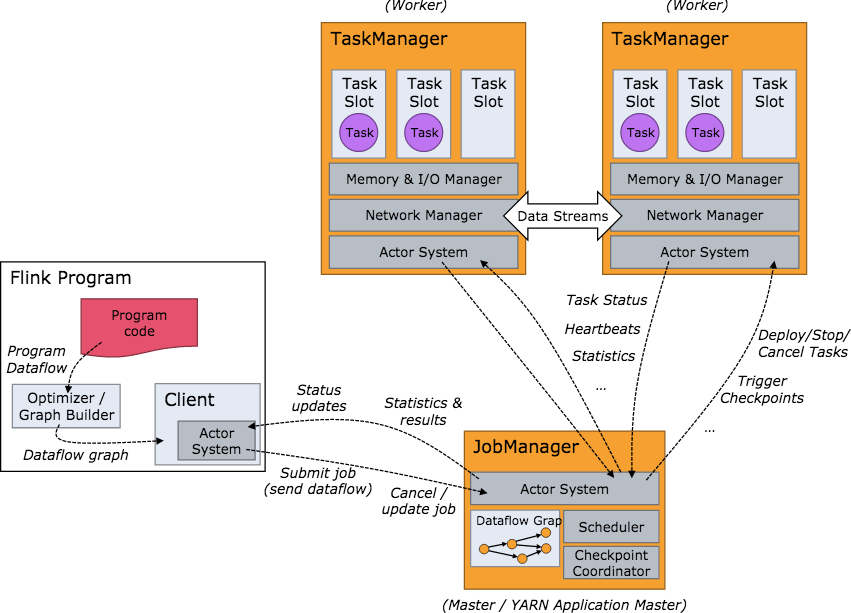
Flink集群启动后,首先会启动一个JobManger和一个或多个TaskManager。由Client提交任务给JobManager,JobManager再调度任务到各个TaskManager去执行,然后TaskManager将心跳和统计信息汇报给JobManager,TaskManager之间以流的形式进行数据的传输。JobManager、TaskManager和Client均为独立的JVM进程。
- JobManager是系统的协调者,负责接收Job,调度组成Job的多个Task的执行,收集Job的状态信息,管理Flink集群中的TaskManager。
- TaskManager是实际负责执行计算的Worker,并负责管理其所在节点的资源信息,在启动的时候将资源的状态向JobManager汇报。
- Client负责提交Job,可以运行在任何与JobManager环境连通的机器上,提交Job后,Client可以结束进程,也可以不结束并等待结果返回。
基本编程模型
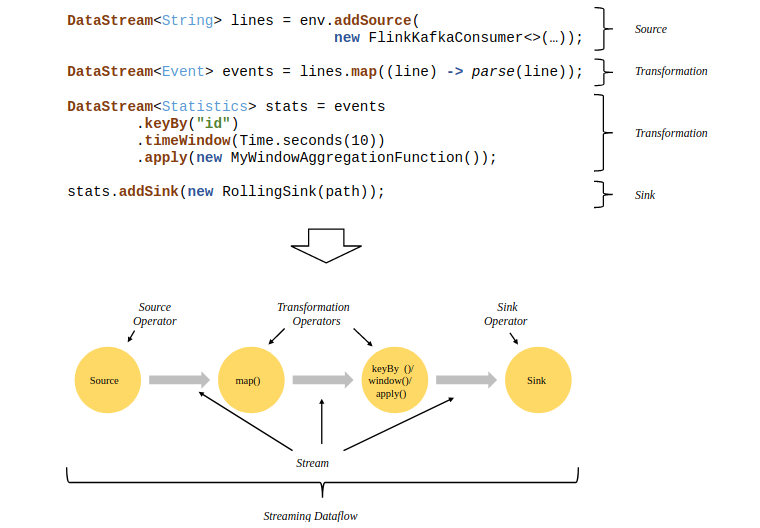
Flink程序的基础构建模块是流(streams)与转换(transformations),每一个数据流都起始于一个或多个source,并终止于一个或多个sink,下面是一个由Flink程序映射为Streaming Dataflow的示意图:
容错机制
Flink的容错机制的核心部分是分布式数据流和operator state的一致性快照,系统发生故障的时候这些快照可以充当一致性检查点来退回,恢复作业的状态和计算位置等。官网有详细介绍Data Streaming Fault Tolerance。
- Checkpointing
- Recovery
- Operator Snapshot Implementation

 浙公网安备 33010602011771号
浙公网安备 33010602011771号