数据库之子查询
概念
把一个查询结果作为另一个查询的基础。
子查询出现的位置
- where 之后
- having 之后 把结果作为组数据过滤的条件
- from 之后 把查询结果作为一个表
where 之后 作为条件
select distinct manager_id from s_emp;
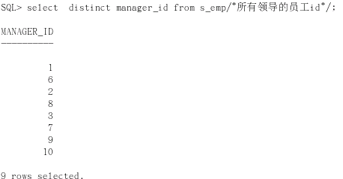
查询结果应该是8个,但是因为有一个null,所以有9个,但是不影响下面的运算。比如:
select id, first_name from s_emp where id in(1,2,3,NULL);
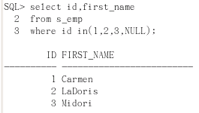
null对其查询没有影响。如果有人的员工id出现在上面的查询结果里面,则该人是领导。
select id, first_name from s_emp where id in(select distinct manager_id from s_emp);
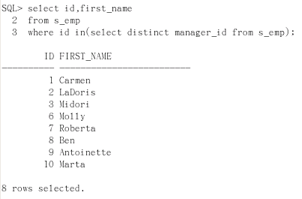
in找到一个,就能断定该字段在里面。那么要找出所有普通员工就不能用“not in”。(因为有null,它不受控制会影响查询)

select id, first_name from s_emp where id not in(select distinct manager_id from s_emp where manager_id is not null);

having之后 把结果作为组数据过滤的条件
演示:按照部门号分组,求每个部门的平均工资,要求显示平均工资大于42部门的平均工资
select avg(salary) from s_emp where dept_id=42;

select dept_id, avg(salary) from s_emp group by dept_id having avg(salary)>(select avg(salary) from s_emp where dept_id=42);

子查询出现在from之后
任何一个核发的select语句,都可以看成一张内存表。
演示:
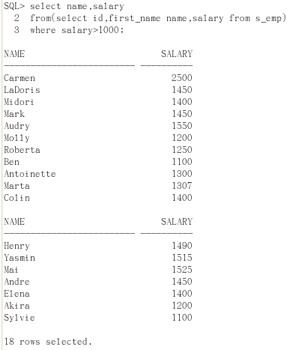
select id, first_name name, salary from s_emp;

。。。。。。
select id,first_name name,salary from s_emp; 可以看成一张有两个字段的内存表
select name, salary from(select id, first_name name, salary from s_emp) where salary>1000;
演示:按照部门号分组,求每个部门的平均工资,要求显示平均工资大于42部门的平均工资(结合子查询在from之后和where之后)
select dept_id, avg(salary) asal from s_emp group by dept_id;
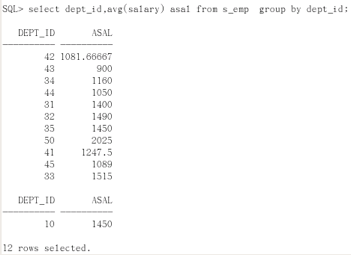
select dept_id,avg(salary) asal from s_emp group by dept_id 放在from后面作为一张有两个字段:dept_id asal 的内存表使用。
select * from (select dept_id, avg(salary) asal from s_emp group by dept_id) where asal>(select avg(salary) from s_emp where dept_id=42);


 浙公网安备 33010602011771号
浙公网安备 33010602011771号