数据库之分组
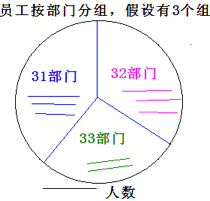
概念
按照一定标准把数据分成若干部分
语法
from 表名
where 条件
group by 分组标准
(group标准的要写在where之后,没有where写在from之后)
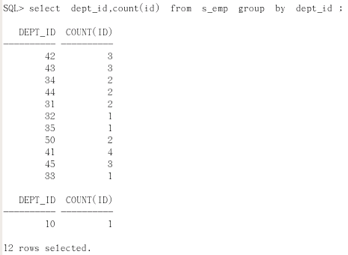
语句:select dept_id,count(id) from s_emp group by dept_id;
- 实际执行时先执行from s_emp
- 再执行group by dept_id
- 最后是统计输出select dept_id,count(id)
如何对组数据进行过滤
- where是对表数据进行过滤的。
- 组数据过滤有特殊的语法——having
- having要加在group后面
演示:按照部门号分组,统计每个部门的人数,显示人数大于2的部门并且按部门号降序排列
select dept_id, count(id) from s_emp group by dept_id having count(id)>2 order by dept_id desc;

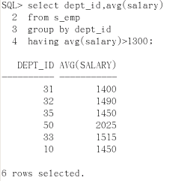
演示:按照部门号分组,统计每个部门的平均工资,显示平均工资大于1300的部门
select dept_id, avg(salary) from s_emp group by dept_id having avg(salary)>1300;
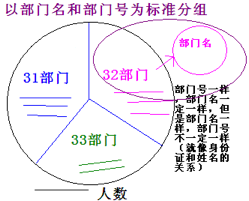
在分组语句中,select后的字段要么是分组标准,要么是经过合适组函数处理过的内容
举例:按照部门号分组,统计每个部门的平均工资,显示平均工资大于1300的部门,还要显示部门名
select dept_id, avg(salary), name from s_emp e, s_dept d where dept_id=d.id group by dept_id, name having avb(salary)>1300;

(存在一些问题)匹配显示次数问题
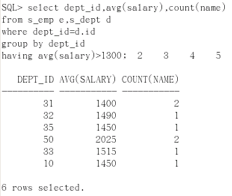
所以用组函数,因为组函数只会有一个结果, 如果用count:
select dept_id, avg(salary), count(name) from s_emp e, s_dept d where dept_id=d.id group by dept_id having avg(salary)>1300;
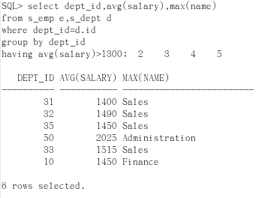
如果用max:
select dept_id, avg(salary), max(name) from s_emp e, s_dept d where dept_id=d.id group by dept_id having avg(salary)>1300;
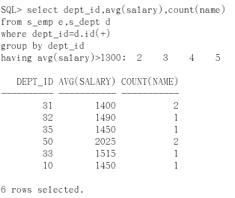
因为可能会有的部门没有对应部门名,数据会丢失,则要全部显示部门表的内容,所以还要加上外连接。
select dept_id, avg(salary), count(name) from s_emp e, s_dept d where dept_id=d.id(+) group by dept_id having avg(aslary)>1300;
sql语句的执行顺序
(1)from 先找到要操作的表
(2)where 会有过滤条件
(3)group by 分组肯定在having之前
(4)having 对组数据进行过滤 通过下面举例的别名可以确定having和select的执行顺序
(5)select 查询输出(语法规则要求select写前面)
(6)order by 永远在最后
演示:按照部门号分组,统计每个部门的人数,要求显示部门人数大于2的部门,还要求按照人数进行排序
select dept_id, count(id) ac from s_emp group by dept_id having count(id)>2 order by ac;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号