pod的网络通讯方式
导言

我们继续去学习我们的基础概念中的另一个就是网络的通讯方式,我们要先对k8s中的网络通讯有一定的认知以后,那才能帮助我们比较好的去构建我们的k8s。
那首先我们先看第一点,就是 k8s它的网络模型,他说假定了所有的pod都在一个可以直接连通的扁平的网络空间中,可以直接连通扁平的网络空间,我们其实对扁平的概念已经有了一定的了解了,对吧?
比如我们在一些面试,那一些hr都会说唉我们公司是扁平化管理比较人性化,那赶快加入我们公司。
其实说白了来说就是讲这家公司规模比较小,不然的话怎么可能扁平化,在k8s里的扁平化的概念就是所有的pod都可以通过对方的IP直接到达。当然这里的直接到达你需要加一个双引号,就是pod认为我是直接到达的,其实底层有一堆的转换机制存在,比如到时候我可以带大家去看一下我们的flannel的转换机制,对吧?这在gce里,也就是谷歌的云服务器里是现成的网络模型,在K8s中假定这个网络已经存在了,也就意味着如果我们想在自己的集群中去构建k8s的话,你先要去解决扁平化的网络空间。

这个其实如果现在没有这些开源方案的话,就是比较难去做到的,原因是我们需要每一个集群的pod容器需要去打通,那比如我们之前讲过的ovs对吧?Open v switch,那这个软件加上我们的隧道模式,可以去实现我们的扁平空间,但是比较费劲。那所幸的是我们到今天为止已经有大量的一些企业加入到我们的k8s开发队里来,比如我们后面要学到一个网络组件叫flannel,他可以帮我去实现这么一个扁平的网络空间。
互相访问
那我们今天大家看一下同一个pod之间的多个容器,也就是我现在有一个pod,pod里面呢有很多容器
那他们之间要想互相访问的话,走的是谁呢?

没忘吧我们之前说过,只要是同一个pod,它会共用我们的一个叫做什么?Pause容器的这么一个网络站,那他们之间互相访问的话,是不是走的就是这个网络战的lo,互联网卡,通过localhost的方式就可以直接访问,这是完全没有问题的。这是第一种。
第二种,各pod之间的通讯,各pod之间的通讯,那这里说的叫overlay network。我们先跳一下,因为等会我们就会看到这个所谓的overlay network到底是一种怎样的方式,它叫全覆盖网络
那下一个也叫pod与service之间的通讯,通过各节点的IPtables规则,也就是通过IPtables规则的转换去实现。当然在最新版本中已经加入了 lvs的机制去为它进行转发,这是完全没有问题的。那它的转发效率会更高,对吧?上限也会更高。
那对于我们现在来说,最主要想解决的就是这个 overlay network网络到底是怎样去实现的,以及他们今天之间经历了哪些的转换机制,对吧?好,那接下来我们去看一下,在k8s中,其实我们呢谷歌没有对自己的k8s做了很强的定义,它允许我们通过cni的接口去接入我们自己想要达到的这么一个网络方案。
flannel
那其中的flannel是我们比较最常用的,在k8s里解决我们的扁平化网络的这么一种方案,符合我们的cni接口对吧?Flannel到底是什么?它是Carlos团队针对k8s设计的一个网络规划服务,想法来说就是可以让我们在不同节点主机,不同节点主机创建了docker容器,具有全局唯一的虚拟IP地址,并且还能在这些IP之间建立一个覆盖网络,通过这个覆盖网络,将数据包原封不动的传递到目标容器内部

那从这句话提取出来的概念,就是不同机器这里指的是我们的物理机对吧?
docker,首先这些docker这里面的容器,他们之间 IP一定不能一致,都说扁平化了。那既然是扁平化的话,那万一你俩IP冲突的话,那是不是已经出现 IP从某这么一个报错了对吧?所以他们之间的IP一定不能一样,不能一样,其实很好解决,我们因为之前已经学过docker了,我们学docker时候是不是给大家说过,我可以去修改我们的docker启动的配置文件,把这个docker0这个网桥它的网段给它改掉。
那只要docker0分配的网段不一样,那这里的容器的IP肯定能够不一样,是这个意思吧?
那其实最难的就是这个pod或这个容器,我们现在docker里面还没有还没有pod的概念对吧?这个容器那这个容器如果想访问这个容器想访问这个容器,怎么让他能够直接通过对方的IP到达,这才是最难的,或者是迫切需要解决的,对吧?那我们去看一下flannel是怎么解决的。
网络解决方案 k8s+flannel
这里画了两台大主机,物理机对吧?一个是192168.66.11,一个是192168.66.12,那这里呢运行了4个pod,一个pod的是web APP1,一个是web APP2,一个是web APP3,一个是backend,也就是我们前端组件。
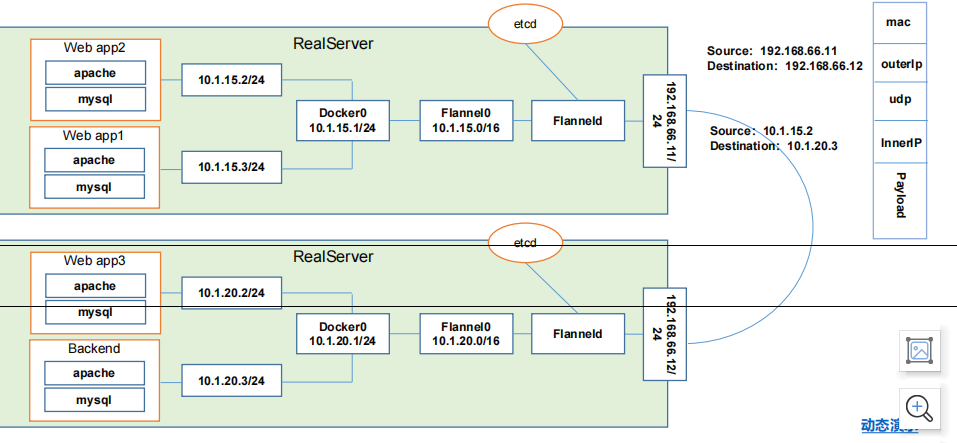
那它们的结构应该是backend,web APP1,web APP2,APP3,然后所有流量访问到backend上,他去经过自己的网关去处理,把什么样的请求分配到什么样的服务上,是这个意思吧?那也就意味着当backend想要去跟 web APP2或者说web APP2想要想要去跟我们backend通讯的时候,就需要跨主机了,以及 web APP3跟本集的backend,两个不同pod之间通讯的话,那是同主机的,他们到底怎样去解决?很重要,对吧?好,那我们过来看一下,详细看一下。
首先在我们的真实的note服务器上,我们会去安装一个flanned的守护进程,这个进程呢会监听一个端口,这个端口就是用于后期转发数据包以及接收数据包的这么一个服务端口。那这个 Final一旦这个进程启动以后,它会开启一个网桥叫flannel0,这个网桥flannel0专门去收集docker0转发出来的数据报,那你可以理解为它也是一个勾子函数,强行获取我们的数据报文对吧?好,然后呢这个 docker0呢会分配自己的IP到对应的pod上,到对应的pod上。
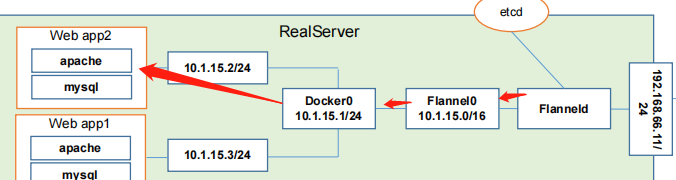
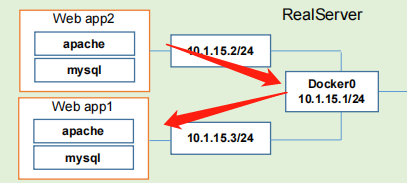
那如果是我们的同一台主机的两个不同的pod之间访问的话,他走的其实是docker0的网桥,因为大家都是在同一个网桥下面的两个不同的子网ip而已,就那我凭什么不能走docker0帮我转发,所以这是可以的。也就是在真实服务器的主机内核已经完成了支持数据化的转换,这个没有问题
难就难在怎么跨主机,还能通过对方的IP直接到达,那怎么到达呢我们给大家走一下流程。首先我们现在假设web APP2想去把数据包发送到backend,它的数据包是不是要原地址要写自己的10.
1.15.2/24,目标要写这里的。
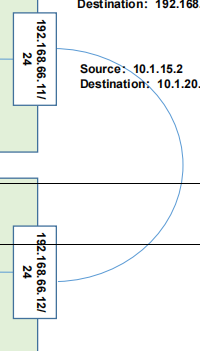
那这个呢因为目标对方的网段跟我不是同一个网段,这可以判断对吧?所以他发到他的网关,这里的网关是docker0,那docker0上面会有对应的勾入函数,把这个数据包抓到我们的flannel0,这里还会有一堆的路由表记录,是从我们的etcd里去获取到,写入到我们当前的主机,判断到底路由到哪台机器。那到flannel0以后,因为flannel0是flanned的这么一个开启的这么网桥。所以这个数据包会到flanned,到flanned以后,它会对这个数据报文进行封装,怎么封装,看这里有这么一个结构,mac部分,然后呢到我们的下一层source192.168.66.11,那目标写的是destination192.168.66.12,那下一层封装是udp的数据报文,也就意味着flanned他使用的是 udp的数据报文去转发这些数据包的,因为更快
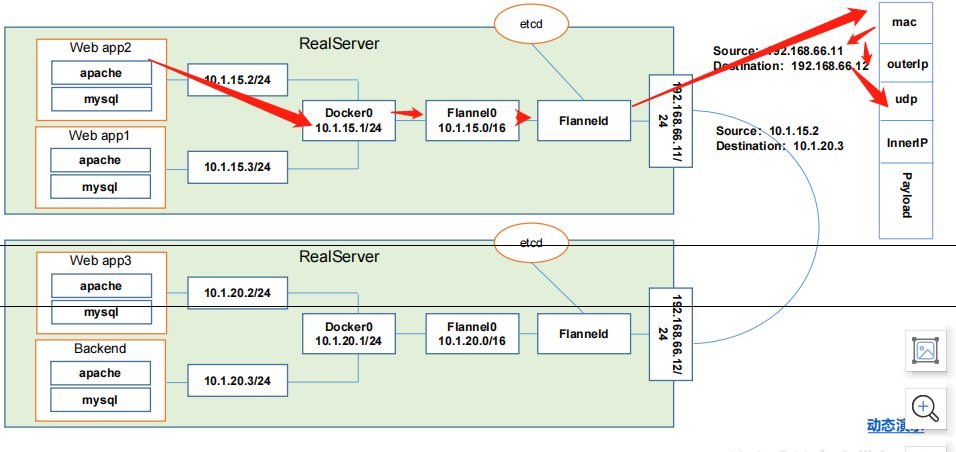
毕竟在同一个局域网内部,好,再下一层又封装了一层新的上层信息,source是10.1.15.2,目标是10.1.20.3。那封装到这一层以后,外面封装了一个数据包实体192.168.66.11/24,所以呢这个数据包肯定是能够到这里的,并且它的目标端口应该就是192.168.66.12/24端口,所以这个数据包会被 flanned所截获,截获以后他会拆封,他知道这是干嘛的对吧?他知道这是干嘛的,都会被拆封,拆分完了以后会转发到我们的flannel0,那 flannel0呢会把它转换到docker0,docker0呢自然而然会被录到 backend很多,并且这个是经过二次解封的
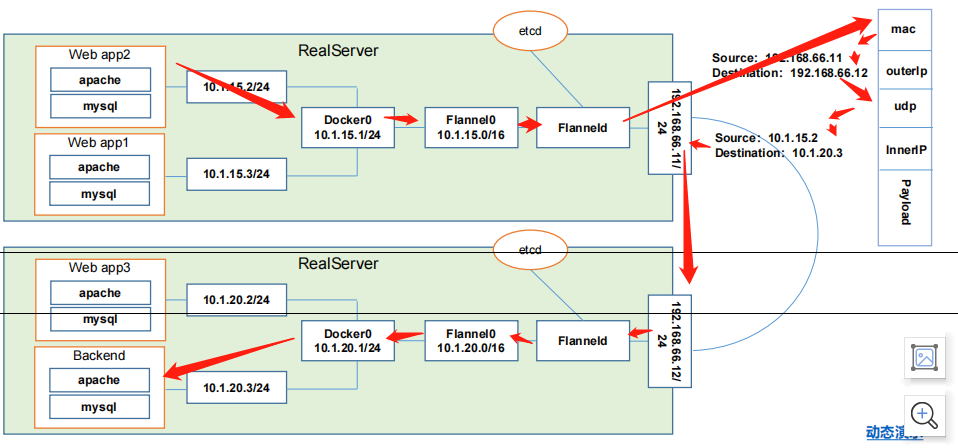
.第一层的信息,11到12

我们的docker0是看不见的,他看的是这一层信息15.2到20.3。

所以他一看唉目标是15.2的这么一个机器发过来的,目标找的就是我自己的机器的地址20.3,对吧?那这样的话就可以实现我们的跨主机的扁平化网络。
其实这里消耗的资源还是比较高的,对吧?首先你要在这里进行数据包二次封装(上面的的flanned),到这里还要解封(下面的flanned)。那这就是我们的flanned这么一个网络的通讯方案。
flannel和我们的etcd之间有哪些关联
那接下来我们去看一下flannel和我们的etcd之间有哪些关联?
第一个就是存储管理flannel可分配的IP地址段资源,也就意味着我们的flannel在启动以后,会像 etcd里去插入,可以被分配的网段,并且把哪个网段分配到哪台机器了,它要记录上,防止这个已分配的网段再被flannel利用分配给其他的note节点,那这样的话迟早有一天会出现我们所谓的IP冲突

好,其次监控etcd里每个pod的实际地址,并在内容中建立维护pod的节点的路由表。
为什么需要去维护pod的节点路由表吗?原因是我们想一下,在这里封装最上层的三层信息的时候,他要知道对方主机的地址信息,那我怎么知道你这个对吧?我怎么知道你这个pod的网段,它对应的物理主题是那是66.12。就是因为通过这里的维护的edcd中的pod的实际地理信息的路由表去判断的。这是etcd和flannel之间的调用关系,需要注意一下,也就是etcd啊其实在我们的k8s集群中,它的角色是非常非常非常非常非常重要
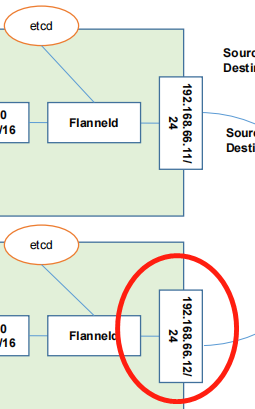
好,所以如果要进行高可用的话,etcd一定是我们最先要搞活动的这么一个组件,他是必须要解决的。那etcd的官方已经给我们解决好了它的集群化,并且非常优秀的集群化。所以这就不需要我们去担心了。
总结
那接下来呢我们再把刚才给大家讲的一些知识点给它统一一下。我们在详细的看一遍,对吧?
第一个,同一个 pod的内部通讯,因为共享的是同一个Linux协议站,共享都是我们的pause的这么一个基础容器的这么一个协议站.所以它使用的都是我们的localhost的或者叫回环网卡去通讯的,没问题
第二个,pod1到pod2访问两个不同pod之间访问,我们刚才已经学习过了,它会分为两种不同的情况。
第一种情况,就是在同一台机器,第二种情况是不在同一台机器,那在同一台机器很好理解了或很好实现了,就是由当前机器的docker0网桥直接转发请求至pod2,不需要经过我们的flannel即可完成所谓的数据报送达。
那还有一种方式就是pod1和pod2不在同一台主机,那pod的地址和docker0在同一个网段,但docker0网段与宿主机的网卡是两个不同的网段,并且不同的node之间的通讯只能通过宿组机的物理网卡进行,将pod IP和所在node IP关联起来,通过这个关联让pod 可以互相访问,这里是简化版的说明
第三个。Pod至Service的网络,目前基于性能,考虑全部为IPtables转发和维护,这个呢已经比较老了。那最新版呢我们可以直接把它的转换模式改为lvs模式,也就通过lvs进行转化和维护,那这样的话性能会更高。
第四个。pod到外网,pod向外网发送请求查找路由表,将数据包转换到宿主机的网卡, 宿主机 网卡完成路由选择以后,IPtables执行masquerade,把源IP更改为宿主网卡的IP,然后向外发送请求,也就意味着如果 pod里面的容器想上网,直接通过我们的snat转换,对吧?动态转换,去完成所谓的上网行为。
第五个。外网如果想访问pod内部,就需要通过借助到我们的service ,才能去进行所谓的访问到集群内部。
因为它虽然是一个扁平化的网络,但你可别忘了,这个扁平化网络是一个私有网络,并不能在跟物理机相连的网络内访问到他,所以要借助到我们的note进行映射,那这个呢我们后面会详细讲解。大家现在先不要急。

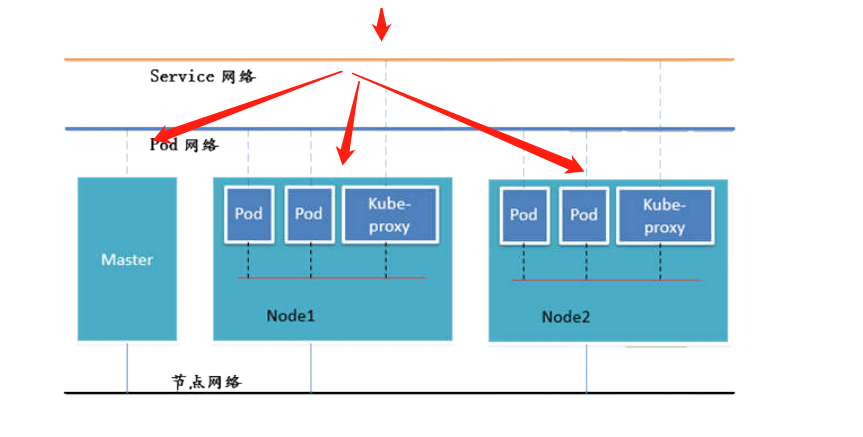
三层网络
在我们的k8s里,它有三层网络,第一个叫节点网络,第二叫pod网络以及service网络。需要注意的是真实的物理的网络只有一个,就是节点网络,也就意味着我们在构建服务器的时候,只需要一张网卡就可以去实现。
我并不说多种网卡不行,一张网卡就可以实现。
那 pod网络呢是一个虚拟网络,service网络也是一个虚拟网络,需要大家注意一下,那这里我们都可以把它理解为是一个内部网络。内部网络、所有的pod都会在这个扁平化的网络中进行通讯。那如果想你想访问service的话,
你需要在 service的这么一个网络中去访问,service呢再去跟后面的 pod进行所谓的对应的。通过IPtables的,或者是通过lvs的转换去达到。
那当然我们最新版都会用 lvs进行所谓的 svc的转换,这样的话效率会更高。
本文来自博客园,作者:小陈子博客,转载请注明原文链接:https://www.cnblogs.com/cj8357475/p/17100714.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号