
Pod 概念
那上节课呢给大家讲了一些我们k8s的组件的一些相关的功能,包括它的一些原理性介绍,对吧?那这节课呢大家去看一下我们k8s中最重要的一些技术概念,比如我们的pod的是怎样的?比如我们的网络是怎样去构建的?对吧?这还是很重要的。这个如果不理解的话,在后面我们进行k8s构建的话,你是很难理解的。那今天的内容呢主要分为两个章节,第一个就是我们的pod的概念,什么是pod的?

pod这个概念
pod这个概念是开发之中特有的一个新的概念。原来我们是没有接触过的,对吧?所以接下来呢我们要去详细的讲一下什么是pod。以及第二个网络通讯的方式,到底在k8s中pod与pod之间是怎样通讯的?与外部是怎样通讯的?我们都需要把它解决。那我们先看第一个知识点,也就是pod的概念。其实对于pod来说它是有一定的分类的,当然官方并不是这样分类的,在国外的一个博主里面写过这么一句话,就是pod可以分为两种,一个是自主式pod,一个是控制器管理的pod,我觉得他的想法挺不错的,就拿过来去演示了。

那自主式pod的含义,简单来说。就是不是被控制器管理的好的。另一种就是被控制器管理的pod,那如果不是被控制器管理的pod被创建以后,你会发现他一旦死亡的话,就没有人会把他给拉起来,就重启一下,不会也不会把它比如这个pod一旦死了以后,它的副本数是不是就达不到期望值了,也不会有人去创建出来一个新的pod满足他的期望值,这都是就是自主式pod一个缺憾。那第二种是我们的控制器管理的pod那不管怎么说,其实我们现在对pod的概念没有一个太深的认识,那接下来呢我们去带大家去给pod做一下详细的讲解。
首先我去创建一个我们的PPT,在传统情况下,比如我们在我们的传统的docker里,在我们的主题上,我去运行一个容器的话,每一个容器都是独立存在的,对吧?通过我们的名称空间进行隔离,每一个容器都有自己的IP地址,每一个容器都有自己的美根,每一个容器都可能有自己的挂载券等等。但在进行K8s移植的时候就不太容易了,比如我想把一个没有在我们呢容器运行过的一个环境,把它转移到或叫迁移到我们的k8s上,就比较难迁移。
因为有些软件,比如我们的fpm fpm和我们的PHP之间呢可能有联系,那如果把它给分开了,它两个是不同的地址,我还得去配他的反向代理。比较费劲对吧?那我想给大家描述一种怎样的状态,就是有些组件他们应该在一起,并且还能够直接互相见面,也就是通过localhost的方式可以访问到。但是如果采用的是标准的容器方案的话,你会发现不可以这样做,除非你把两个不同的进程封装在同一个容器内部,或者是这个容器采用了这个容器的网络栈,也可以做到,但是安全性是不是会有隐患?
K 8s呢给我们建立一个新的概念叫pod,pod是怎样实现的?首先我要定义一个pod,那它会先启动第一个容器,这个容器需要注意一下,只要你运行了这个pod这个周期就会被启动,这种就叫pausa听清楚了。只要是有pod这个容器就要被启动。那这个容器启动成功以后,假设我在这个 pod里定义了两个容器,也就是一个pod里会封装很多个容器,一个两个,甚至还可能有3个4个,当然也也可能只有1个,明白我意思吗?
也就是大于=1。然后这两个pod呢会共用 pausa的网络栈,共用它的存储券。我们先讲第一个共用它的网络栈,也就意味着这两个pod没有自己独立的IP地址,它有的都是pausa的,或者说有的只是这个 pausa的地址,他俩之间呢尾根隔离,但是他们的进程不合理,也就意味着如果这里运行的是PHP fpm,这个运行呢是我们nginx,如果nginx的想反向代理到PHP fpm的话,只需要写localhost的冒号9000即可,不需要写什么他的IP地址要加映射啊什么什么乱七八糟一堆,不需要直接localhost就可以访问到他。

原因是这两个容器都共享的是 pausa的网络战。那既然是共享他的那他俩是不是都见面了?也就意味着另一个概念,就是在同一个pod里,容器之间的端口不能冲突,你别这里搞了一个80,这个容器也是80,那这个pod肯定是起不来的,或者是起来以后无限重启,你要知道原因是为什么,能理解我的意思吗?好,这是第一个共享。第二共享,共享的是我们的网络站,假设这个pod挂载了一个存储,pod的挂载的一个存储,那这两个是不是都想去访问到这个网页存储?
同理,这个pod也会共享pausa的网页存储,nginx也会共享它的存储,也就意味着在同一个框里,既共享网络,又共享存储券,需要大家注意一下,这就是一个pod的基本概念。
控制器
控制器管理的pod的概念,也就意味着控制器是不是要整理一下?每个控制器有什么特点,他管理的pod有什么特点?那这样的话你在了解每一种以后,你是不是才可能再去做对应的一些选项的时候才才会去做比较匹配的方案。

很好理解,对吧?好,我们先看第一种,replication Controller 简称RC。replicaset 简称rs,deployment.这其实是三种,并不是一种那为什么会把这三种放在一起讲,原因是他们有一定的重合性。我们过来看一下。
第一个,replication Controller也就是RC,用来确保容器的应用副本数始终保持在用户定义的部分数上。即如果有容器异常退出,会自动创建新的pod来代替。
讲白了说就是我之前说的那个期望值的概念,假设有一天有个一个pod的死了,那我会创建一个新的pod来满足这个期望值。为什么说是期望值?万一我们现在的资源不够用了,他创建不出来是不是也没办法?对吧?所以说是期望值,而如果异常多出来的容器也会被自动回收,你不能少,但是你也不能多.要刚刚好满足我的期望。在新版本中的k8s建议使用replicaset取代replication Controller。原因是什么?

他们没有本质区别说了对吧?只是名字不一样。但是 RS支持集合试的selector。我们在创建pod的时候会被它打标签,打标签,比如APP等于阿帕奇,比如version==v1版本,我们会被他打一堆的标签。那当有一天我想删除我们的容器或者做对应的一些设施的时候,我可以这样去说,我说APP等于阿帕奇,当version==v1时候,我要干嘛干嘛干嘛?Rs就支持这种集合方案,但是R C不支持,所以在大型项目的管理中,RS肯定会比RC更简单,更有效更有意义。
所以在新版本中,官方抛弃RC全部专用 RS,需要大家注意一下。这是RS和RC的关系,那还有一个deployment对吧?虽然replicaset可以独立使用,但一般还是建议使用deployment来自动管理replicaset,这样无需担心跟其他的机制不兼容,比如不支持 rolling update。就滚动更新。但development的支持滚动更新还是很有意义的,尤其在生态环境中对吧?比如而我现在运行了,运行了两个pod,这炮都用的镜像版本是v1版,我们现在要把这个镜像版本给它改成V2版,那怎么办?
我可以进行一个滚动更新,他先删除一个pod,或者是先多一个pod,它是V2版,然后呢再把这个老旧pod给删除,第一步创建一个新的,第二步删除它,那再创建一个新的。
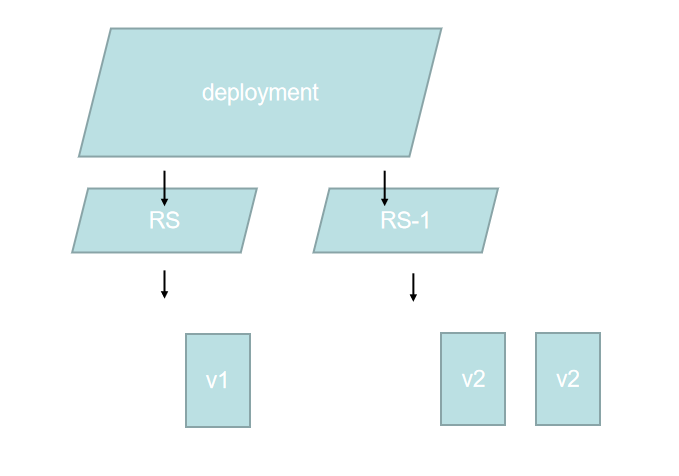
好的。镜像也是V2版,这是第三步,第四步把它删除,那这样的话你会发现最终我是不是就会出现一个最新的这么一个版本状态了,对吧?这就是我们滚动更新的含义。RS不支持滚动更新,但是我们deployment的支持,那他支持就支持,为什么要跟我们的RS放在一起去讲解,原因是 development并不负责我们pod创建,它是通过这种机制达到pod创建的,给大家画一下。假设这是一个我们的deployment,deployment在创建出来以后,他会去创建一个RS,也就意味着这个 Rs并不是我们自己定义的,而是deployment的定义的。
那 development呢再去负责去创建我们对应的pod。比如这里创建了三个pod,那如果有一天我说了唉 development,你给我更新一下,把镜像更新成V2版本,我们现在写一个v1,所以所以好那他会怎么做呢?它会新建一个RS,比如这个RS可能是-1了,当然它并并不是以-1去标识的,我这里只是随便写了一个。好,关于那这样的话它会把它给起来,就是启动第一个容器,是第二版的第一个容器,那这里会退出第一个。
启动第二个容器,这里会退出一个。启动第三个容器,这里会退出一个达到滚动更新的状态,能理解我的意思吧?这样就滚动更新了,并且还可以回滚,什么叫回滚?我如果发现更新到V2版本有一定小bug了,我可以回滚,直接我们的rolling out,唉他就回去了。他会去新建一个老旧版本的v1,v2要删了,以此类推,原因是什么能回滚,原因是deployment在滚动更新以后,这个Rs并不会被删除,而是被停用。
当你回滚的时候,他就会把这个老旧版本的RS给它启用。逐渐达到他想要达到的预期状态,这是deployment它的原理。他需要去创建Rs达到创建pod能力,这个需要大家理解一下。我们继续。
hpa
下一个叫hpa简单来说就是我们的平滑的pod,平滑扩散对吧?根据我们的利用率。仅适用于和deployment和RS,在vlalpha版本中支持根据pod的CPU利用率所扩容,也就意味着什么?

用PPT画,我运行了一个RS,Rs下面管理了两个pod,然后我再定义一个hpa hpa 也是一个对象,需要被定义,那hpa 定义的是基于这个rs去定义了,他怎么写的?当我们的 CPU大于80的时候,那就进行扩展,扩展的最大值是10个,最小值是两个,有这么一种描述方式,也就意味着他会去监控这些pod的当前的资源利用率。
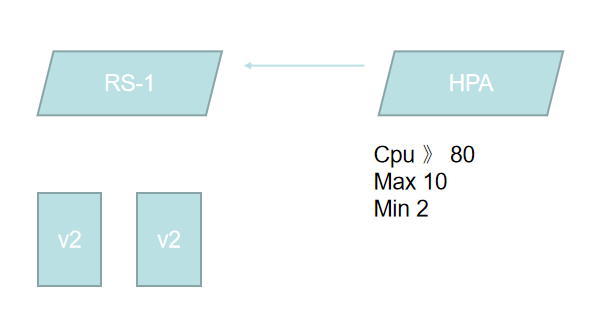
当他的CPU达到80的时候,他会去新建出来新的pod,直到达到它的最大值。当然如果你建三个pod以后,他的CPU平均利用率已经达到80了,就不会再进行继续创建了。能理解我的意思吧?当创第三个的时候,还在大于等于80,他才会继续向下去创建。一定要理解这里的概念,一旦它的利用率变低以后,这里pod就会被回收,来上一个上一个。但他不能继续少了,因为这里说了最小为2,所以在这种情况下,他就可以给我们达成一个水平自动扩展的这么一个目的。
这也是hpa 可以去实现的。那在我们的阿尔法版中呢还可以根据内存或用户的自定义的一些阀值去进行我们的所谓的扩容说现在还不是一个稳定版,需要大家注意一下。好,在不久的将来我们就可以这样去用了,对吧?那我们继续往后看HPa。
statefullset

下一个叫statefullset。statefullset主要解决的是我们有状态服务问题,为什么说是为了解决有状态服务问题?我们想一下,在刚开始给大家讲docker的时候,我们就知道了,docker它主要面对的是我们的无状态服务,对吧?
我们一直在讲这个概念就是 docker主要面对的是无状态服务,无状态的服务的含义就是没有对应到存储需要去实时的保留,或者是我们把它摘出来以后,那经过一段时间运行以后,我再把它放回去,他依然能够正常访问工作。
无状态服务典型的有哪些?比如我们的阿帕奇服务,对吧?比如我们的一些iOS负载均衡调度器,那这些都是无状态服务,那有状态服务更多了,比如mysql,它就是典型的有状态服务,比如mongoDB,他们都需要实时的进行数据的更新以及存储,把它抽离出集群以后,再把他放回来,他就没法正常工作了。这是不是典型的有状态服务?那statefullset就是为了解决我们有状态服务去诞生出来的。它主要有哪些可以去帮我们做到了,第一个叫做稳定的持久化存储,稳定的持续化存储,就是我们pod去死亡以后,我们再调度回来,在调度一个新的pod把它给取代的时候,它的存储依然用到的还是之前的存储,并不会变,并且里面的数据也不会丢失。
第二叫稳定的网络标识,之前的pod叫什么,现在pod还叫什么?之前的主机名叫什么?现在的主机名还叫什么?不会变化,防止我们在集群里面对吧?定了一个pod的名称去调用,结果出现了一个新的pod的把它顶替以后,唉名字变了,我需要重新去写入。不需要。它会实时的稳定这么一个网络标识。
第三个有序部署,有序部署会分为扩展和回收阶段,叫有序部署和有序回收。那什么叫有序部署呢?只有当前一个前一个的pod的处于running 和 Ready的状态,就是运行和准备已经就绪了状态。
第二个才可以被创建。为什么这样说?或者为什么需要这种?原因是比如我们去构建一个集群化,比如一个nginx,阿帕奇 mysql。他们的启动顺序的关系应该是先起mysql。在阿帕奇 再nginx,原因是如果我要去先起的是nginx,他是不是反向代理到你的后端阿帕奇,他会判断唉阿帕奇怎么不在,那如果再起阿帕奇的话,他会判断唉mysql怎么不在,所以这里在大型环境中是有一定的启动顺序的,是这个意思吧?那既然有启动顺序,我是不是要定义有序部署?
他第一个起他第二个起,他第三个起,并且在回收的时候,在删除的时候是不是也一样?
我们应该先删谁?先删最上层的nginx再删阿帕奇,再删mysql,所以叫有序部署或叫有序回收,这都是statefullset给我们带来的一个特点。当然他只是给我们带来了这些特点,你要真正想去解决有状态服务的话,还需要自己去制定一些功能,那这个过程其实是非常之难的。哪怕到今天为止mysql还不太能够正常的在我们的 k 8s集群,稳定的运行,或者说跟我们在传统的虚拟化里面去运行的话,还是有一定的缺憾的。
daemonset
我们看下一个控制器daemonset,daemonset确保全部或者一些的node上运行一个pod副本,当有node加入集群时,他会为他们增加一个pod,当有node从集群移出时,这些pod也会被回收,删除daemonset将会删除他们创建的所有pod。首先这里面有一些说法,第一个叫确保全部或者一些,为什么说是一些,因为我们可以在我们的 node打一些污点,那这些污点可以是不被调度的。所以在daemonset创建的时候,这些打了污点的node上就不会运行这个pod的。

但是正常情况下默认情况下,我们的所有的node都会被运行一个pod副本,运行一个有且只有一个需要注意一下,有切只有一个。好,那有什么典型的用法?比如我们的存储集群,都可以运行在我们每一个node?提供我们的存储能力。那比如我们的日志收集工具,fluentd和 logstash,对吧?好,那这些我们都可以去收集日志,以及我们的监控程序,prometheus node exporter
都可以把它封装在我们的daemonset里,在每一个model上去运行,帮我们去收集数据,也就意味着只要你有需求,每一个note上都需要运行一个守护进程,去帮我们干某些事情。那daemonset都是一个比较好的选择。当然当如果你想比如我在一个脉络上,我运行了好几个不同的pod,我需要运行好几个不同的pod,那这时候怎么办?有没有想过一个问题?你是不是可以把这好几个pod里的主要的进程给它提取出来,放到同一个pod里的不同容器上,那这样的话通过一个daemonset是不是也可以去设置?
当然也可以设置三个不同的daemonset都是可以的,需要大家注意一下。
job cron job

我们看下一个 job cron job,job呢是负责我们的批处理的任务,仅执行一次的任务,它可以保证批处理任务的一个或多个pod的成功结束,那这个有什么作用?比如我们可以举个例子,我想备份一下我的数据库,那备份数据库呢?备份代码我就完全可以把它封装在一个pod里去运行,对吧?那我在放到job里去把它执行一下,那这个脚本是不是就可以正常执行,把我们的数据库备份出来。
你说我直接在我们linux操作系统里运行不也是一样的吗?对,没有问题没有没有问题。你这样说没有问题,但是我们这个pod的封装的这个pod是不是可以重复利用的?这是之一之二。如果脚本执行意外退出是没办法重新执行的,对吧?但是job如果判断这个脚本不是正常退出,那他就会重新执行一遍。能理解我的意思吗?直到正常退出为止,并且你还可以设置它的正常退出的次数,比如正常退出两次,我才允许你这个job执行成功,这就是job的含义。
那 Cron jobs讲的来说就是可以在特定的时间重复执行,那他有一些特点需要去注意一下,到时候我们再讲到这个控制器的时候再去跟他说?
好,我们先简单看一下,那这个呢就是我们的pod的控制器类型了。
服务发现
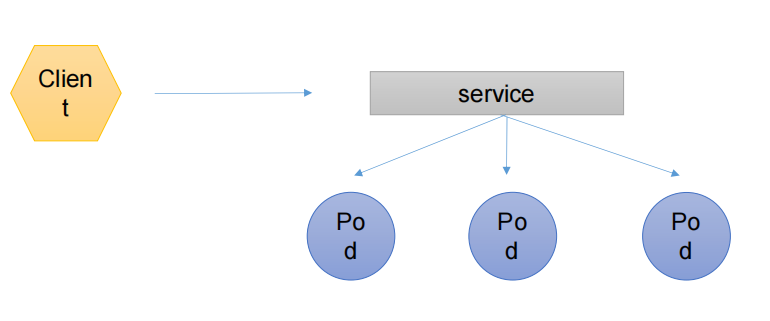
那接下来我们继续往后看,服务发现之前那个概念其实已经给大家灌输过不少次了,对吧?就是我们的客户端想去访问一组pod,注意是一组pod,如果这些pod无相干的话,是不可以通过我们的service统一代理的,对吧?那pod必须要有相关性,比如是同一个我们的Rs deployment创建的对吧?或者拥有同一组标签,那都可以被我们的service所收集到。那也就意味着我刚才的话,其实衍生出来的一个含义就是service去收集这些pod,是通过我们的标签去选择到了这个概念非常重要。
那选择到以后,那这个service呢会有自己的一个IP加上端口,那我们的客户端就可以访问service的IP加端口,那间接的访问到这些所谓对应的pod,并且这里是有一个轮巡的算法存在的,轮巡先访问第一次,访问第二次访问第三次访问第四次,以此类推对吧?好,那这是我们的一个服务发现的一个简单说明。那当然从服务发现还可以衍生出来一些别的概念,那比如我们可以看一下这样的,假设我们画一个正儿八经的图,这是我们的阿帕奇加 fpm模块。

这个是然后前面呢是有一些缓存服务器,比如squid的,那这个呢是我们的mysql,我们就不把它化机械化了。假设就是这么一个简单的结构,那 squid前面呢肯定是需要有个负载的服务的对吧?那可以是我们的lvs,假设有这么一种情况,那当然这个负载周期可以不是lvs,可以是hot process等等对吧?有这么一个结构,也就意味着首先我要构建一个阿帕奇加php fpm的集群,我再构建一个mysql的,我再构建一个squid,然后再构建lvs如果我想把这个结构放在我们的k8s里运行的话,我们看看需要几步,第一步mysql是不是要运行成一个pod?
当然我们mysql,现在放在我们k8s中,放在我们的statefulset控制器里。是可以做到的,但是集群化的话还是不是那么方便。好,那就意味着我们先把mysql封装成一个pot,mysql封装成一个pot以后,我们还有阿帕奇pm那是居然有这么多节点,其实他们都是类似的对吧?那既然是类似的,我们之前是不是学过控制器了?
我们是不是可以在deployment上面去创建?也就是我创建一个development,指定它的副本数目为三个副本,那这样的话是不是有三个不同的阿帕奇php pod,那再往上呢我们会发现有三个squid,那这个squid我是不是也可以把它封装成pod,通过我们的控制器把它给控制。Squid那 lVs呢我们就可以靠我们集群本身的功能把它负载掉多了。
那这样的话我们出现这么一种结构,你会发现不太好写对吧?吃亏的我们要写反向代理的话,需要写三台机器。并且我们之前讲过一个概念,就是这个pod再去退出以后再重新建立的过程中,这个IP地址会变换对吧?除非你采用的是statefulset,但是在 php-fpm里面是不是没有意义?所以这怎么办?我们就可以在前端刚才我们说过了一个service对吧?在前面加一个service,这个service呢就是php-fpm的service,它会绑定我们的php-fpm的他的标签选择进行绑定。
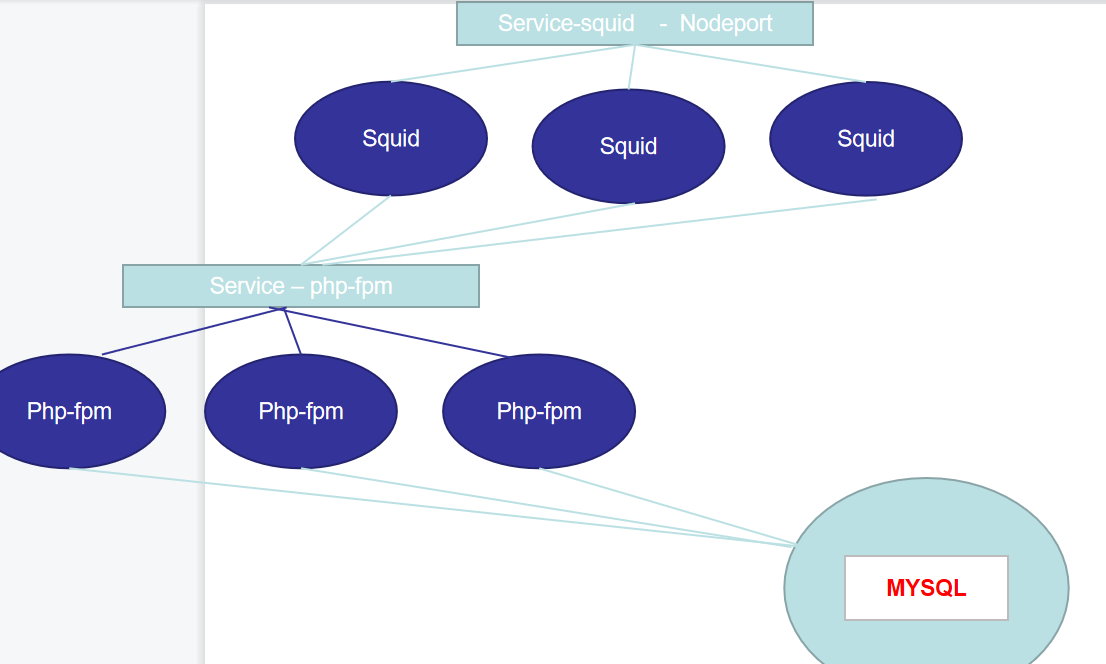
那 squid的呢如果想去进行反向代理设置的话,它不需要去写这三个所谓的对应的IP地址,因为我们一直在强调这个概念,php-fpm一旦死亡以后,我们的控制器会把它维稳在三个副本,那会创建出来一个新的副本取代于它,那取代他的副本跟现在的这个副本,他们的IP地址是不一样的。那squid如果在里面填写的是它的目标IP的话,那就会出现问题对吧?因为它一换的话,我们的squid里面的所有配置文件是不是要重写?要重新修改对吧?
重启服务,这样不太友好。所以我们squid里面写的是这个service-php-fpm的这么一个地址,那这样的话 service只要 squid去执行,指定到我们的service上面即可。
并且php-fpm这是一个pod,mysql也是一个pod,他们之间其实会出现一定的关联,比如我们把mysql部署在我们的statefulset里面,那它的名称是不是就不会变?那我可以通过它的名称去固定到我们对应的pod上,因为我们之前说过 k 8s内部是一个扁平化的网络,那容器之间是能够互相访问的,所以我这样画,直接php-fpm里面写他的地址信息是完全没有问题的。对于这三台squid来说,外网用户要访问对吧?我可以再创一个svc也就是我们service与之绑定,通过去判断我们的 squid的相关的一些标签进行确定,那这样的话我们只需要把这个 service暴露到外部即可。
Service呢其中有一种暴露模式叫做我们的nodeport,可以通过我们的ingress Controller等一些方案都可以去做到,那这样的话我们就可以把这个架构完整的部署在我们的开发式集群中了,这也是我们的pod与pod之间的通讯方案
本文来自博客园,作者:小陈子博客,转载请注明原文链接:https://www.cnblogs.com/cj8357475/p/17098635.html

