
尚硅谷_组件说明
导言
好,接着呢我们去进行第三部分的讲解,也就是我们的组件说明,那整个k8s的框架还是非常庞大的,对吧?那我们要对它有一个非常高的了解以后,我们再去安装我们的k8s才会有一个比较好的效果。好,那对于我们的k8s来说,你可以理解为它的前身是我们的博格系统,对吧?采用go语言的编译版或叫重构版。好,那就意味着如果我们先去了解我们的博格系统,再转而去看我们的 k8s,整个调度系统的话,那可能会帮助我们更加强一部分了解,对吧?
博格的架构
好,那我们首先我们看一下我们的博格的架构,那这张图呢就是显示我们的博格的谷歌的博格的这么一个调度器的这么一个架构,那首先你会发现这里有一堆的borgmaster和borglet对吧?由两部分去组成。
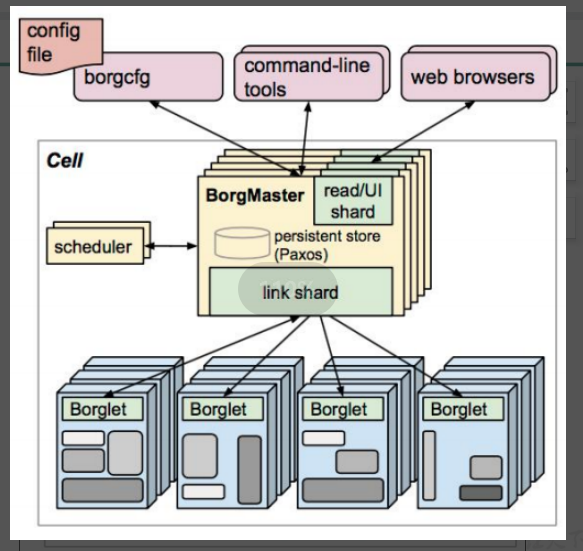
好,那borgmaster就是专门去负责这些所谓的请求的分发的,你可以理解为它是整个集群大脑对吧?那真正工作的节点其实是我们的borglet,也就如果有对应的容器要运行的话,比如有一些计算能力对吧?它是通过我们的borglet去给他提供的,需要大家注意一下,在这里他给他去提供对吧?
好,那为了防止我们的borgmaster由于单节点故障,所以你会发现这里有很多的副本,并且这个副本数目其实是有讲究的,需要注意一下。
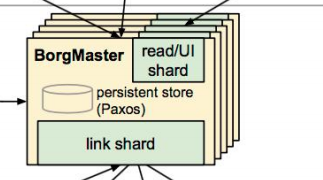
你仔细数一下12345,5个,那我问大家一个问题,可以是两个吗?可以是4个,嘛可以是6个。那这里为什么要这样去给大家描述?因为对于我们的高可用集群来说,一般我们要满足这么一个需求,就是它最好是13579,听明白我意思吗?会叫3579,最好大于一对,因为一个节点是不是就产生我们单节点故障了?那为什么要这样选择?防止有一天出现,比如你两票我两票,那咱俩谁是老大呢?那如果有三个人同时过来投票的话,肯定不会出现这种状态。
能理解我有意思吗?所以对于我们的高可用集群来说,它的调度器或它的高可用节点最好保持在三个以上,基数也就3579比较合适。好,这个是需要我们特别注意的。
集中访问方式
并且你会发现这里有这么集中访问方式对吧?那第一种是通过我们的浏览器,命令行,以及我们的一些文件的读取,那在我们的k8s里呢也会有这么几种方式进行所谓的整个调度集群的管理。好,那这种三种方式会被接入到我们的borgmaster,他去请求以后再去做分发,那分发这个概念很重要对吧?
也就请求过来以后,我要把这个任务交给谁去处理。
scheduler
那假设我现在就是一个包工头,对吧?那有一些任务过来了,比如唉把什么钢筋扛到几楼,把什么砖扛到几楼对吧?那我要去安排一些我的工人去干这件事情,那对于我来说呢就是这么一个组件。scheduler?scheduler,也就是我们的调度器,那所有的任务在到这里以后被会被分发分发至不同的节点去运行。当然这里并不是我们的 schedule去跟我们后面的borglet交互,而是schedule把数据写入至paxos,这是我们谷歌的这么一个键值对的这么一个数据库,他去存储,并且borglet呢会实时的在这里paxos这么一个数据库里进行监听,如果发现,唉有我的请求了,那我会把这个请求取出来,又叫消费对吧?
去处理这些任务,达到这么一个流程目的。
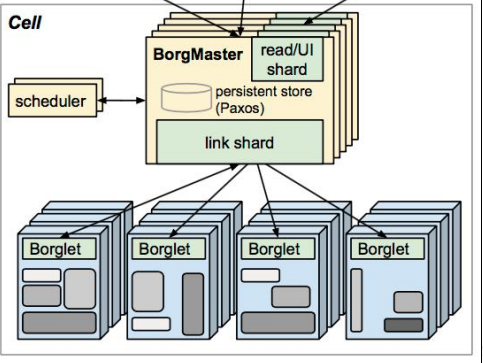
好,那这个呢就是我们的博格系统的这么一个示意图了,那也意味着对于我们的k8s它的更新版或叫精良版,对吧?好,那它是不是应该也是跟它类似的
k8s
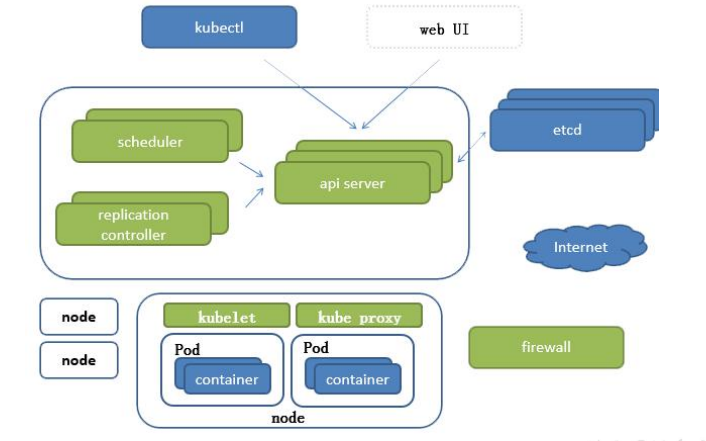
所以接下来我们看这么一张图,这是我们的k8s的这么一个架构图,里面的一些重要组件,我也画在这里了,对吧?那在这里呢它会分为 CS结构,一个是我们的 master服务器,
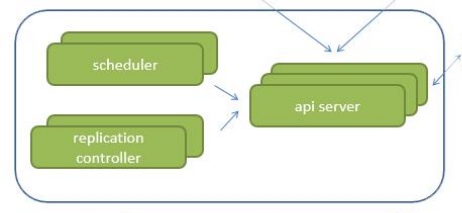
一个是我们的 node的节点
那也就意味着在这里它跟我们的 borgmaster一样,它也是我们的一个领导者,对吧?
也是我们的领导者头头。
那在这里的所有的note呢就是我们的工人了,执行者。那我们先看一下对于我们的领导者里面他有哪些东西。
schedule
第一个schedule,虽然是一个调度器,任务过来以后,我还需要通过schedule把这些任务分散至不同的note里,但这里需要注意一下,我们刚才给大家说的是在博格系统,在这里schedule会写入到我们的pasos数据库中,那在这里呢做了一些更改,什么更改呢就是schedule把任务交给我们的api server,api server再去负责把这个请求写入到etcd,也就意味着schedule,并不会跟我们的etcd直接交互,需要注意一下。
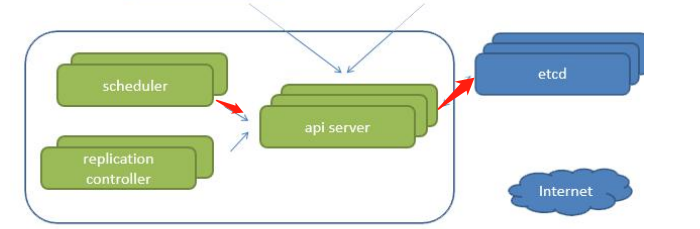
RC
那在这里呢还会有一个RC(replication controller)那我们把它叫做控制器,他们就是维护我们的副本的数目呢或叫做我们的期望值的。那举个例子,我想让这个容器运行几个副本对吧?那就是由他去控制的,一旦他的副本数不满足我的期望值了,那这个 RC呢要负责把这个副本数改写到我们的期望值,或叫申请到我们的期望值,也就是创建对应的pod的或删除对应的pod.需要注意一下。
api server
好,那 api server就是我们的主服务器里面最后一个组建了对吧?那它呢讲白来说就是我们一切的服务的访问的入口,你会发现schedule,需要跟我们api server交互交互,我们的RC需要跟api server交互,kubectl呢是我们的命令行管理工具,它也需要跟我们的api server会进行交互,web UI呢也需要跟api server进行交互,包括etcd所以你会发现这里的api server是非常繁忙的,对吧?
那为了减轻他的压力,每个组件其实还可以在本地生成一定的缓存,并不需要每件事情都到api server去申请,需要注意一下。
etcd
api server我在进行了请求以后呢会去操作 etcd。 EtCT在我们的k8s集群里呢就比较类似于在这里的paxos这么一个键值对系统了。那 Etcd呢是Carlos公司开源的这么一个项目,采用go语言编写,键值对数据库,那在这里呢起到了整个k8s集群的这么一个持久化的方案。并且etcd还有一些东西需要给大家讲一下,我们可以看这么几张图,第一个 epc官方将它定位一个可信赖的分布式键值对存储服务。

那这里说说明一下什么叫可信赖。那为了官方让这个所谓的etct能够持久化的话,不会造成单节点故障,所以它天生支持集群化,并不需要其他的组件参与进来,它就能实现自己的集群化方案。需要注意一下,它不像我们mysql对吧?如果你想实现一个读写分离的话,那还需要介入到阿米巴等一些中间件,在这里不需要,本身可以完成。分布式键值存储服务也就意味着可以扩容说非常方便对吧?键值存储,kv结构需要注意一下,好。协助我们分布式集群正常运转,这里的正常运转的含义就是保存我们的整个分布式集群的需要持久化的配置文件配置信息,那一旦我们集群死亡以后,可以借助到etcd里面的一些信息进行所谓的数据恢复,那这就是edcd在我们的k8s集群的一个定位。
还有需要注意一下,在我们的k8s的集群中,我们会使用etcd作为持续化方案,但对于etcd来说,它的存储有两个版本,一个是VR版,一个是v三版,这两个版本是我们还在用的,VR版会把所有的数据全部写入到我们的内存中,v三版会引入一个本地的券的持久化操作,也就意味着关机以后并不会造成数据损坏,会从我们的本地磁盘进行恢复。那理论上我们是不是应该选择v三版,因为这样不会造成数据丢失对吧?但需要注意一下
1.11版包括之前他自带的etcd是没有 v三版的,也就那时候还不支持v三版,需要注意一下,那我们现在安装的已经是1.15.1的最新稳定版了,所以这个问题是不需要我们去思考的了。
那万一你的集群是一个非常古老的集群,对吧?那还在使用1.11版之前的版本,那你就需要注意一下对etcd进行我们的备份操作,需要注意一下。
etct
好,那这里呢还有一个etct的这么一个内部架构图
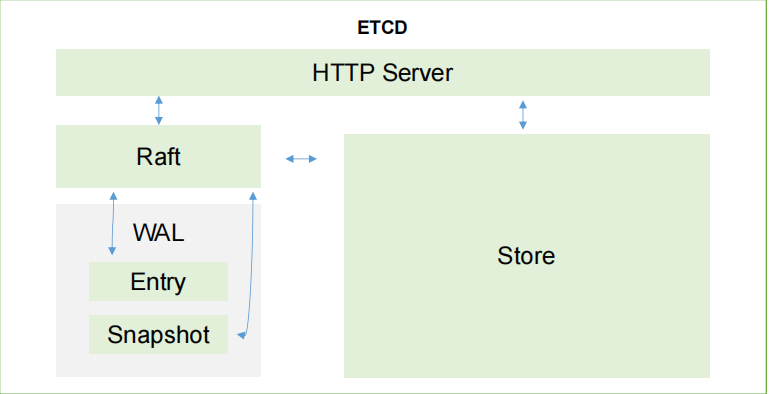
那在这里你会发现它采用的是一个http server的形式,也就意味着这里依然是一个采用HTTP协议进行CS的构建服务。那除此以外,其实还有个东西也是采用这种方案,那就是我们的k8s ,k 8s也采用的是我们的 HTTP协议,进行我们的CS结构的开发,需要注意一下。那为什么要这样做?因为我们的http 协议天生支持很多一种操作方式,比如put啊 Get啊 change啊等等,对吧?
包括授权认证,所以我没有必要再去采用我们一个标准TCP协议,开发一系列的认证流程,没有必要。
所以我们直接采用http 协议即可。
raft
那在这里呢我们有一个raft,就是我们的读写的一些信息了,所有的信息都会存在这里,并且为了防止这些信息出现损坏的话,它还有一个叫wal这是一个预写日志,也就是如果你想对我们里面的数据进行更改的话,唉你先给我生成一个日志,我先存一下对吧?我先存一下,并且会定时的去对这些日志进行一个完整的备份,也就完整加临时。比如我先备份一个大版本,备份完成以后,如果有一些新的修改,唉一个子版本,两个子版本三个子版本,到达它的时间以后,会再进行一次完整的合并,把它转换成一个大版本。
然后再子子子。那这样有什么好处?首先我们不可能随时的进行完整备份,因为消耗的数据量太大,那为什么还要在一定的时间内进行完整备份,防止这里的对吧?增量备份太多,我们在还原的时候太费事太费时,所以采用了这么一种方案,并且他还会实时的把这些日志,包括我们的数据写入到我们的本地磁盘中进行持久化设置,那这就是我们的一个etcd的这么一个架构的说明了。好,我们再回来,etcd已经over了对吧?那我们就直接理解为它是我们整个集群中的这么一个重要的存储,对吧?
存储我们的k8s集群的这么一些参数信息的,离开了他k8s鸡群就瘫了,这是肯定的对吧?那么再往后,我们master服务器 master节点的一些重要组件
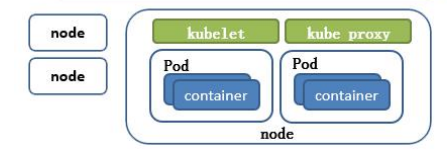
node的节点
我们就已经说完了,那在这里我们先看一下我们node的节点,note node呢你会发现有我们的kube proxy, kubeLet以及container了。
好,也就意味着我们在我们的 node节点需要安装三个软件, kube proxy, kubeLet以及docker。那当然你在这里可以选择docker,也可以选择一些其他的容器引擎也是没有问题的。因为我们说容器虽然我们现在都会默认为docker对吧?但是容器是不是除了docker以外,还有其他很多的一些引擎?这个可别忘了对吧?docker只是引擎的一种实现方案而已,或者最主流的实现方案而已。
kubeLet
好,那 kubeLet到底有什么作用?我们需要讲一下。
它呢会跟我们的cri,叫什么? c 容器,R呢 runtime运行环境,I呢 interface,接口,那这个呢讲白来说就是我们的docker在这里的表现形式,那kubeLet会跟docker进行交互操作,docker去创建对应的容器,也就kubeLet维持我们的pod到的生命周期,
kube proxy
那 kube proxy是干嘛的呢?我们之前说过我们的svc还记得吗?是不是有一点印象,我们在讲我们的讲解结构的时候给大家说明过.有一个叫svc可以进行我们的负载操作,那负载的组件呢就是通过我们的kube proxy去完成的,就通过我们的kube proxy去完成的,需要注意一下,也就意味着怎么去实现我们的pod的与pod的之间的访问,包括负载均衡,那需要借助到我们的kube proxy,它的默认操作对象是操作防火墙去实现这里的pod的映射。
整理
当然我们新版本中还支持ipvs,也就是我们的iOS组件,对吧?好,那这个呢就是我们的k8s架构了一个标准的这么一些组件。那我们接下来带大家好好的把它整理一下,对吧?这些组件的意义还是很重要的。那我们先看我们的第一个,api server,所有服务访问的统一入口,所有服务统一入口对吧?包括我们的schedule,包括我们的rc,包括我们的etCD啊,web ui啊等等,都需要去访问到我们的api server,当然这里还有我们的kube proxy和kubelet呢也需要注意一下,好所有组件都需要访问的api server,所以你可以可想而知他的压力还是比较大的,对吧?
好,那我们后面会给大家讲怎么去,官方是怎么去为api server我进行减压的,这后面给大家去介绍。好,那这是我们的api server。
那第二个组件呢是我们的控制器。也就是我们的控制器,它呢去维持或者维护我们的副本的期望数目,他是我们k8s集群的重要组件。
好,下一个schedule,schedule对吧?schedule,好,我们的调度器,负责接受任务选择合适的节点进行分配任务,那什么叫合适呢?我想保障的是唉这个节点有足够的资源,可以供给给我的pod的去运行。我想这个节点有一些什么样的固态硬盘啊对吧?或者一些带宽比较高, CPU比较高,内存比较大,这些特殊的资源能够分配给我的pot,都是由我们的schedule去完成的需要注意一下。
那除了这里以外,我们还有etcd对吧?键值对数据库、存储 k 8s集群的所有重要信息。当然这里的重要我们需要打一个关键字叫持久化。因为有些数据虽然很重要,但是它不需要持久化,那需要持久化的数据,我们都会被写入到我们的etcd中,也就意味着如果有一天我们想恢复说恢复我们的k8s集群的话,只需要对我们的etcd进行还原即可,需要注意一下。
这是我们的master服务里面有的一些主键,对吧?好,那除此以外,我们还有什么?kubelet,我们去写一下。他呢直接跟docker或叫容器引擎交互,实现容器的生命周期管理,你可以这样理解kubelet接触到指令以后,先把我们的k8s发过来的指令先理解,理解完成以后再去把对应的指令直接转化为我们的container,对吧?容器能够听懂的命令让他去创建,达到这么一个pod的创建的这么一个流程。
好,除此以外,我们还有一个叫kube proxy,好,他呢是负责写入我们的规则去id tables,或者是 IPVS实现,实现服务建设访问的.主要组件呢就这么多
这是我们官方的主要组件。整个ks结构我们就已经讲到这里了,那接下来我们继续往后看,那还有一些其他的也是比较重要的一些插件给大家说明一下。

比如第一个core DNS,core DNS我们听名字就听出来对吧?core公cos公司的这么一个DNS服务器。好,那它主要实现的是什么功能?可以为集群中的 svc创建一个 a记录,或者创建一个域名IP的对应关系解析,也就意味着以后我们在集群中访问我们的一些其他的一些 pod的时候,我完全不需要通过这个pod的IP地址,通过什么?
通过core DNS给它生成的这么一个域名去实现访问。他也是我们整个集群的重要重要重要组件,也是我们实现我们的负载均衡的其中一项功能。
好,那下一个。dashboard,它呢是我们的一个 BS结构的访问,也就是给 k 8s集群提供一个 b s结构的访问体系,
还有ingress controller ,好,这个是什么?它可以我们的官方的k8s集群呢只能实现一个4层代理,不能讲,只能他为我们实现了4层代理,没有实现7成。那 ingress controller 可以实现7层代理,也就是可以根据我们的主机名,根据我们的域名进行负载均衡,对吧?ingress 那这个我们后面也会给大家详细去讲解,先简单听一下到底有什么作用。
那最后一个federation,他们给我们提供一个可以跨集群中心,多k8s的统一管理的功能,这是我们的federation这么一个作用。
还有最后一个普罗米修斯(prometheus)。好,最后一个普罗米修斯,那中文呢就是普罗米修斯。好,那普罗米修斯呢它能够注入的作用呢是什么?提供一个集群的监控能力。当然我们还会有efk对吧?提供集群日志统一分析,接入平台
好,那这些呢就是我们整个 k 8s集群的非常重要的一些组件,说明了我们是不是这里少写了一个什么?高可用集群副本数目最好是大于等于3的奇数个,那这个呢就是我们这一章的内容。
本文来自博客园,作者:小陈子博客,转载请注明原文链接:https://www.cnblogs.com/cj8357475/p/17097710.html

