目标跟踪
目标检测
在图像中找出物体,目标跟踪是实时追踪物体在视频或实时图像中的位置。因此,可以简单看成目标跟踪是目标检测+跟踪算法的结合。
常用方法
由于目标检测方法的不同,常用的目标跟踪方法也可分为传统方法+滤波类跟踪算法,深度学习方法+滤波类跟踪算法。其中,滤波类跟踪算法主要包括:卡尔曼滤波和粒子滤波等。
其中,卡尔曼滤波计算量较小,适用于实时性要求较高的场景,但不适用于复杂目标运动的情形,而粒子滤波可以处理多目标跟踪和复杂背景下的跟踪问题,但存在计算量较大,不适用于实时性要求较高的场景。因此,可以根据实际需求来选择这两种滤波算法。如果目标的运动规律比较简单,可以选择卡尔曼滤波;如果目标运动比较复杂,或需要处理多目标跟踪和复杂背景下的跟踪问题,可以选择粒子滤波。
常用滤波方法
卡尔曼滤波
数学表达式



推导过程:



举例推导



重要公式

粒子滤波
算法详解
卡尔曼滤波算法
目标:训练权重项(卡尔曼增益K),使得最终得到的K值能让最优值的不确定性最小
第一帧检测得到的目标信息用来初始化卡尔曼滤波的状态变量(追踪器tracks)
目标追踪的8维状态向量: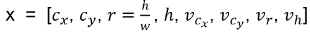 ,中心坐标
,中心坐标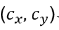 、高宽比
、高宽比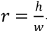 、高h以及该方向各自对应的变化速度值
、高h以及该方向各自对应的变化速度值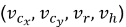
协方差矩阵:表示目标位置信息之间的皮尔逊关系。8个状态得到8x8矩阵

目标跟踪两个阶段:
1)每个追踪器track都要基于当前状态去预测下一时刻状态
2)然后基于目标检测得到的结果去修正估计值
匈牙利匹配算法
概念:一种寻找二分图的最大匹配的算法
目标:使得匹配后的代价矩阵最小
缺点:并非最优匹配,而是尽可能使得每个目标都匹配上
匹配规则:如果代价矩阵中的某一行或某一列同时加上或减去某个数,则新代价矩阵的最优分配与原代价矩阵的最优分配完全相等
详细步骤:
- 代价矩阵的每一行元素,减去当前行中的最小元素
- 步骤1中的每一列元素,减去当前列中的最小元素
- 用最少的水平线或垂直线覆盖矩阵中所有的0,如果线的数量=N(目标数),则找到了最优匹配,匹配结束;否则进入4
- 在所有没被线覆盖中取最小元素;若当前行没被线覆盖则当前行减去该元素,若当前列被线覆盖则当前列加上该元素。然后返回3
代价矩阵的三种形式
第一步:运动信息匹配,通过卡尔曼滤波得到下一帧的8个估计状态量,将估计结果与下一帧实际检测结果进行比对,得到运动信息的代价矩阵
第二步:外观匹配,deepsort核心,以实现较长时间遮挡的目标跟踪
第三步:IOU匹配,表示下一帧目标框与当前帧目标框的IOU重叠区域,1-IOU表示IOU的距离
匈牙利算法是用于解决二分图最大匹配问题的经典算法,其时间复杂度为O(n^3),其中n为节点数,二分图是指一个图中的节点可以分为两部分,使得每条边的两个端点属于不同部分的部分。二分图最大匹配问题是指在这样的二分图中找到一个匹配,使得匹配的边数最多。
匈牙利是算法的基本思路是从一个未匹配的节点开始,不断寻找增广路径,直到找不到为止。增广路径指的是在未匹配的节点中依次选择一个节点,然后找到它的匹配节点,再继续找匹配节点的匹配节点,最终找到一个未匹配的节点。
匈牙利算法使用了深度优先搜索和交替路的概念来寻找增广路径,并通过改进的路径翻转操作来更新匹配。在每次寻找增广路径时,算法都会尝试从前未匹配节点开始找到一条曾广路径,如果找不到,则回溯到上一个节点,寻找其他的增广路径。直到找到一条增广路径为止。
追踪算法
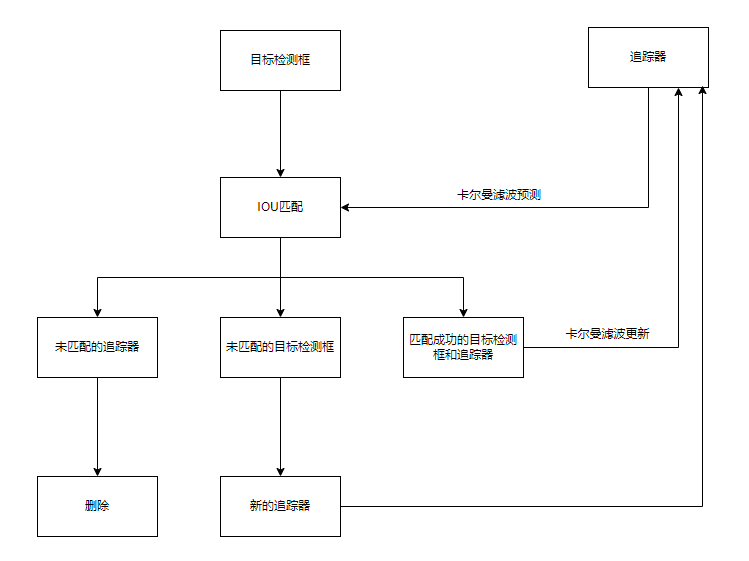
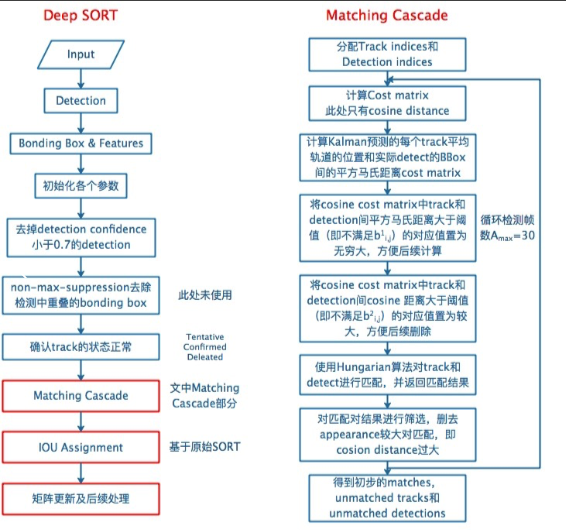
sort算法
核心:卡尔曼滤波算法、匈牙利算法
关键步骤:
- 卡尔曼滤波预测出predict预测框
- 使用匈牙利算法将卡尔曼滤波的预测框和目标检测的检测框进行IOU匹配来计算相似度
- 卡尔曼滤波使用目标检测的检测框update卡尔曼滤波的预测框
预测框:来自卡尔曼滤波器跟踪器tracker
检测框:来自深度学习算法
deepsort算法
在sort算法的基础上新增了深度学习模型提取特征(级联匹配、状态确认)
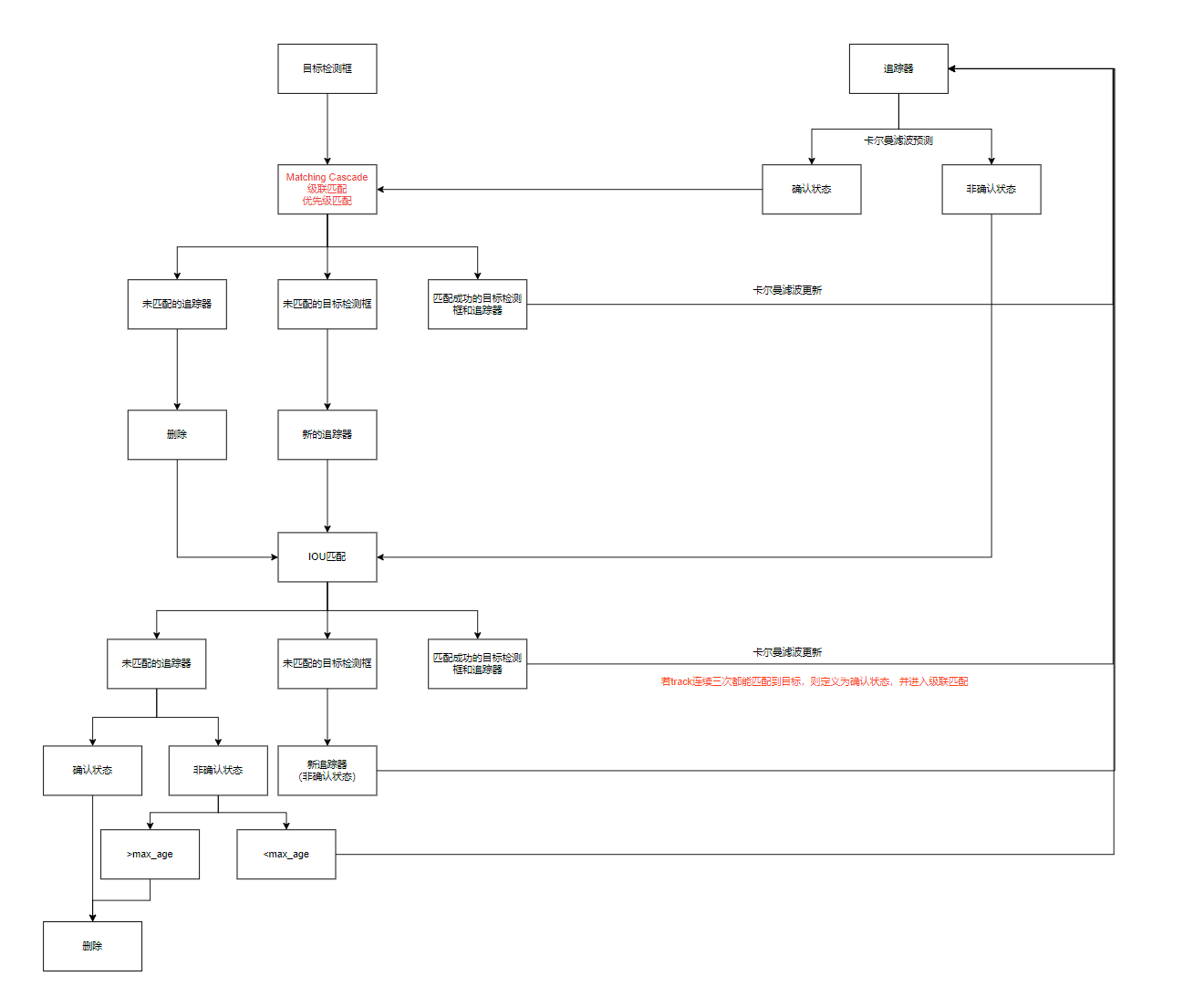
级联匹配
目的:长时间遮挡中。卡尔曼滤波的prediction会发散,不确定性增加,而这样不确定性强的track的马氏距离反而更容易竞争到detection匹配。因此,需要按照遮挡时间n从小到大给track分配匹配的优先级。基于匈牙利算法。
输入为:
1、基于第k-1帧由卡尔曼滤波predict到的当前第k帧所有confirmed状态的track;
2、当前第k帧的所有detection
输出为:
1、match上的detection、track
2、没有match上的track
3、没有match上的detection
具体过程:
逻辑过程
#input:基于第k-1帧由卡尔曼滤波predict到的当前第k帧所有confirmed状态的track索引T={1,...,N},当前第k帧所有detections D={1,...,M},最大未匹配帧数Amax=30
1.用外观最小余弦距离和马氏距离计算成本矩阵C(实操中lambda=0,只会用到外观最小余弦距离)
2.用外观最小余弦距离和马氏距离计算阈值矩阵B,用来滤掉不可能的匹配
3.用空集初始化match上的集合M
4.用D来初始化unmatch集合U
5. for n 属于 {1,...,Amax} : #n是每个track未匹配帧数
6. 从T中挑出一个子集Tn,即那些未匹配帧数=n的track的索引
7. 用匈牙利算法 对上一步选出的子集Tn和D进行匹配
8. 向M中添加匹配的序列号对(i,j),确保这个匹配满足阈值矩阵B(即bij=1)
9. 从未匹配索引集合U中删去匹配的序列号对(i,j)的j,确保这个匹配满足阈值矩阵B(即bij=1)
10. end
11. return M,U
级联匹配流程图里下半部分匈牙利算法数据关联作为流程的主体。为什么叫级联匹配,主要是它的匹配过程是一个循环。从missing age=0的轨迹(即每一帧都匹配上,没有丢失过的)到missing age=30的轨迹(即丢失轨迹的最大时间30帧)挨个的和检测结果进行匹配。也就是说,对于没有丢失过的轨迹赋予优先匹配的权利,而丢失的最久的轨迹最后匹配。
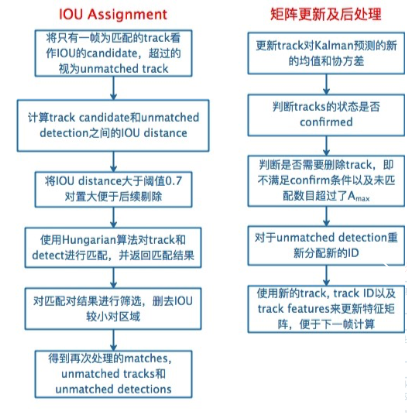
IOU匹配
IOU匹配是在级联匹配之后做的东西,从SORT中继承而来,用来解决突然的外观变换导致级联匹配难以match的情况,如部分遮挡等。也是基于匈牙利算法做的。
输入:
1、candidate track,包括:
1.1 级联匹配中剩下的unmatched,n=1的track;
1.2 基于第k-1帧由卡尔曼滤波predict到的当前第k帧所有unconfirmed状态(即tenative)的track;
2、级联匹配中剩下的unmatched detection
输出:
1、match上的detection、track;
2、没有match上的track;
3、没有match上的detection。
然后进行更新处理,包括:
1、卡尔曼滤波 update track在第k帧状态的均值和方差
2、是否有track需要转为confirmed(到本帧match上且已连续命中3帧)
3、是否有要删除的track,即n>Amax
4、对unmatched detections分配新的track ID,为unconfirmed态即tenative态。
三者关系:
逻辑实现
1. 根据上一帧的目标框结果来预测当前帧的目标框状态,预测边界框(目标框)的模型定义为一个等速运动/匀速运动模型。
2. 每个目标框都有对应的一个卡尔曼滤波器(KalmanBoxTracker实例对象),
KalmanBoxTracker类中的实例属性专门负责记录其对应的一个目标框中各种统计参数,
并且使用类属性负责记录卡尔曼滤波器的创建个数,增加一个目标框就增加一个卡尔曼 滤波器(KalmanBoxTracker实例对象)。
3. yoloV3、卡尔曼滤波器预测/更新流程步骤
3.1. 第一步:
yoloV3目标检测阶段:
--> 1.检测到目标则创建检测目标链/跟踪目标链,反之检测不到目标则重新循环目标检测。
--> 2.检测目标链/跟踪目标链不为空则进入卡尔曼滤波器predict预测阶段,反之为空则重新循环目标检测。
3.2.第二步:
卡尔曼滤波器predict预测阶段:
如果连续多次预测而不进行一次更新操作,那么代表了每次预测之后所进行的“预测目标和检测目标之间的”相似度匹配都不成功,导致不会进入一次更新阶段。
如果一次预测然后相似度匹配成功的话,那么然后就会进入更新阶段。
--> 3.2.1.目标位置预测
1.kf.predict():目标位置预测
2.目标框预测总次数:age+=1。
3.if time_since_update > 0: #如果连续预测的次数>0
hit_streak = 0 # 连续更新次数归0
time_since_update += 1
1.每执行predict一次即进行time_since_update+=1。
2.在连续预测(连续执行predict)的过程中,一旦执行update的话,time_since_update就会被重置为0。
3.在连续预测(连续执行predict)的过程中,只要连续预测的次数time_since_update大于0的话,
就会把hit_streak(连续更新的次数)重置为0,表示连续预测的过程中没有出现过一次更新状态更新向量x(状态变量x)的操作,
即连续预测的过程中没有执行过一次update。也就是我们上面说的相似度匹配不成功。
--> 2.预测的目标和检测的目标之间的相似度匹配成功则进入update更新阶段,反之匹配失败则删除跟踪目标。
3.3第三步:
卡尔曼滤波器update更新阶段:
如果一次预测然后“预测目标和检测目标之间的”相似度匹配成功的话,那么然后就会进入更新阶段。
kf.update([x,y,s,r]):使用的是通过yoloV3得到的“并且和预测框相匹配的”检测框来更新预测框。
--> 1.目标位置信息更新到检测目标链/跟踪目标链
1.目标框更新总次数:hits+=1。
2.history = []
time_since_update = 0
hit_streak += 1
1.history列表保存的是单个目标框连续预测的多个结果([x,y,s,r]转换后的[x1,y1,x2,y2]),一旦执行update就会清空history列表。
2.连续更新的次数,每执行update一次即进行hit_streak+=1。
3.在连续预测(连续执行predict)的过程中,一旦执行update的话,time_since_update就会被重置为0。
4.在连续更新(连续执行update)的过程中,一旦开始连续执行predict两次或以上的情况下,
当连续第一次执行predict时,因为time_since_update仍然为0,并不会把hit_streak重置为0,
然后才会进行time_since_update+=1;
当连续第二次执行predict时,因为time_since_update已经为1,那么便会把hit_streak重置为0,
然后继续进行time_since_update+=1。
--> 2.目标位置修正。
1.kf.update([x,y,s,r]):
使用观测到的目标框bbox更新状态变量x(状态更新向量x)。
使用的是通过yoloV3得到的“和预测框相匹配的”检测框来更新卡尔曼滤波器得到的预测框。
1.初始化、预测、更新
1.__init__(bbox):
初始化卡尔曼滤波器的状态更新向量x(状态变量x)、观测输入[u,v,s,r](通过[x1,y1,x2,y2]转化而来),u,v是目标框中心点的坐标,s是目标框的面积,r是目标框宽高比例 w/h、
初始化状态转移矩阵F、量测矩阵H(观测矩阵H)、测量噪声的协方差矩阵R、先验估计的协方差矩阵P、过程激励噪声的协方差矩阵Q。
2.update(bbox):根据观测输入来对状态更新向量x(状态变量x)进行更新
3.predict():根据状态更新向量x(状态变量x)更新的结果来预测目标的边界框
2.状态变量、状态转移矩阵F、量测矩阵H(观测矩阵H)、测量噪声的协方差矩阵R、先验估计的协方差矩阵P、过程激励噪声的协方差矩阵Q
1.状态更新向量x(状态变量x)
状态更新向量x(状态变量x)的设定是一个7维向量:x=[u,v,s,r,u^,v^,s^]T。
u、v分别表示目标框的中心点位置的x、y坐标,s表示目标框的面积,r表示目标框的纵横比/宽高比。
u^、v^、s^分别表示横向u(x方向)、纵向v(y方向)、面积s的运动变化速率。
u、v、s、r初始化:根据第一帧的观测结果进行初始化。
u^、v^、s^初始化:当第一帧开始的时候初始化为0,到后面帧时会根据预测的结果来进行变化。
2.状态转移矩阵F
定义的是一个7*7的方阵(其对角线上的值都是1)
运动形式和转换矩阵的确定都是基于匀速运动模型,状态转移矩阵F根据运动学公式确定,跟踪的目标假设为一个匀速运动的目标。
通过7*7的状态转移矩阵F 乘以 7*1的状态更新向量x(状态变量x)即可得到一个更新后的7*1的状态更新向量x,
其中更新后的u、v、s即为当前帧结果。
3.量测矩阵H(观测矩阵H)
量测矩阵H(观测矩阵H),定义的是一个4*7的矩阵。
通过4*7的量测矩阵H(观测矩阵H) 乘以 7*1的状态更新向量x(状态变量x) 即可得到一个 4*1的[u,v,s,r]的估计值。
4.测量噪声的协方差矩阵R、先验估计的协方差矩阵P、过程激励噪声的协方差矩阵Q
1.测量噪声的协方差矩阵R:diag([1,1,10,10]T)
2.先验估计的协方差矩阵P:diag([10,10,10,10,1e4,1e4,1e4]T)。1e4:1x10的4次方。
3.过程激励噪声的协方差矩阵Q:diag([1,1,1,1,0.01,0.01,1e-4]T)。1e-4:1x10的-4次方。
4.diag表示对角矩阵,写作为diag(a1,a2,...,an)的对角矩阵实际表示为主对角线上的值依次为a1,a2,...,an,
而主对角线之外的元素皆为0的矩阵。
对角矩阵可以认为是矩阵中最简单的一种,值得一提的是:对角线上的元素可以为 0 或其他值,对角线上元素相等的对角矩阵称为数量矩阵;
对角线上元素全为1的对角矩阵称为单位矩阵。对角矩阵的运算包括和、差运算、数乘运算、同阶对角阵的乘积运算,且结果仍为对角阵。
目标跟踪(Object Tracking)是计算机视觉中的一个重要任务,常用于视频监控、自动驾驶等领域。SORT(Simple Online and Realtime Tracking)和 DeepSORT(Deep Simple Online and Realtime Tracking)是两种流行的多目标跟踪算法。以下是它们的介绍和主要区别:
SORT(Simple Online and Realtime Tracking)
SORT 是一种简单高效的多目标跟踪算法,主要特点如下:
- 核心思想:利用卡尔曼滤波(Kalman Filter)和匈牙利算法(Hungarian Algorithm)进行目标的状态估计和数据关联。
- 输入:目标检测算法(如 YOLO、SSD 等)提供的检测框。
- 步骤:
- 检测框的输入:从目标检测算法中获取每一帧的检测框。
- 预测阶段:使用卡尔曼滤波预测每个目标的下一状态。
- 数据关联:利用匈牙利算法将当前帧的检测框与上一帧的预测框进行匹配,更新目标状态。
- 更新阶段:根据匹配结果更新卡尔曼滤波器的状态。
- 优点:计算量小,适用于实时应用。
- 缺点:仅基于空间信息进行匹配,容易在目标密集或目标快速移动时出现跟踪错误。
DeepSORT(Deep Simple Online and Realtime Tracking)
DeepSORT 是 SORT 的改进版本,引入了深度学习模型进行外观特征提取,从而提高了跟踪的鲁棒性和准确性。其主要特点如下:
- 核心思想:在 SORT 基础上结合了目标的外观特征进行多目标跟踪。
- 输入:目标检测算法提供的检测框和预训练的深度特征提取网络(如深度卷积神经网络)。
- 步骤:
- 检测框的输入:从目标检测算法中获取每一帧的检测框。
- 特征提取:使用预训练的深度神经网络提取每个检测框的外观特征。
- 预测阶段:使用卡尔曼滤波预测每个目标的下一状态。
- 数据关联:结合空间信息(如 SORT 中的卡尔曼滤波预测)和外观特征进行匹配,通常使用马氏距离(Mahalanobis distance)和余弦相似度(cosine similarity)。
- 更新阶段:根据匹配结果更新卡尔曼滤波器的状态和目标的外观特征。
- 优点:结合空间和外观特征,显著提高了跟踪精度,特别是在目标密集和目标外观变化较大时表现更好。
- 缺点:计算复杂度较高,对硬件资源要求较高。
总结
- SORT 适用于计算资源有限且目标变化不大的实时应用场景。
- DeepSORT 适用于需要高跟踪精度且有较好计算资源支持的场景。
