目标检测
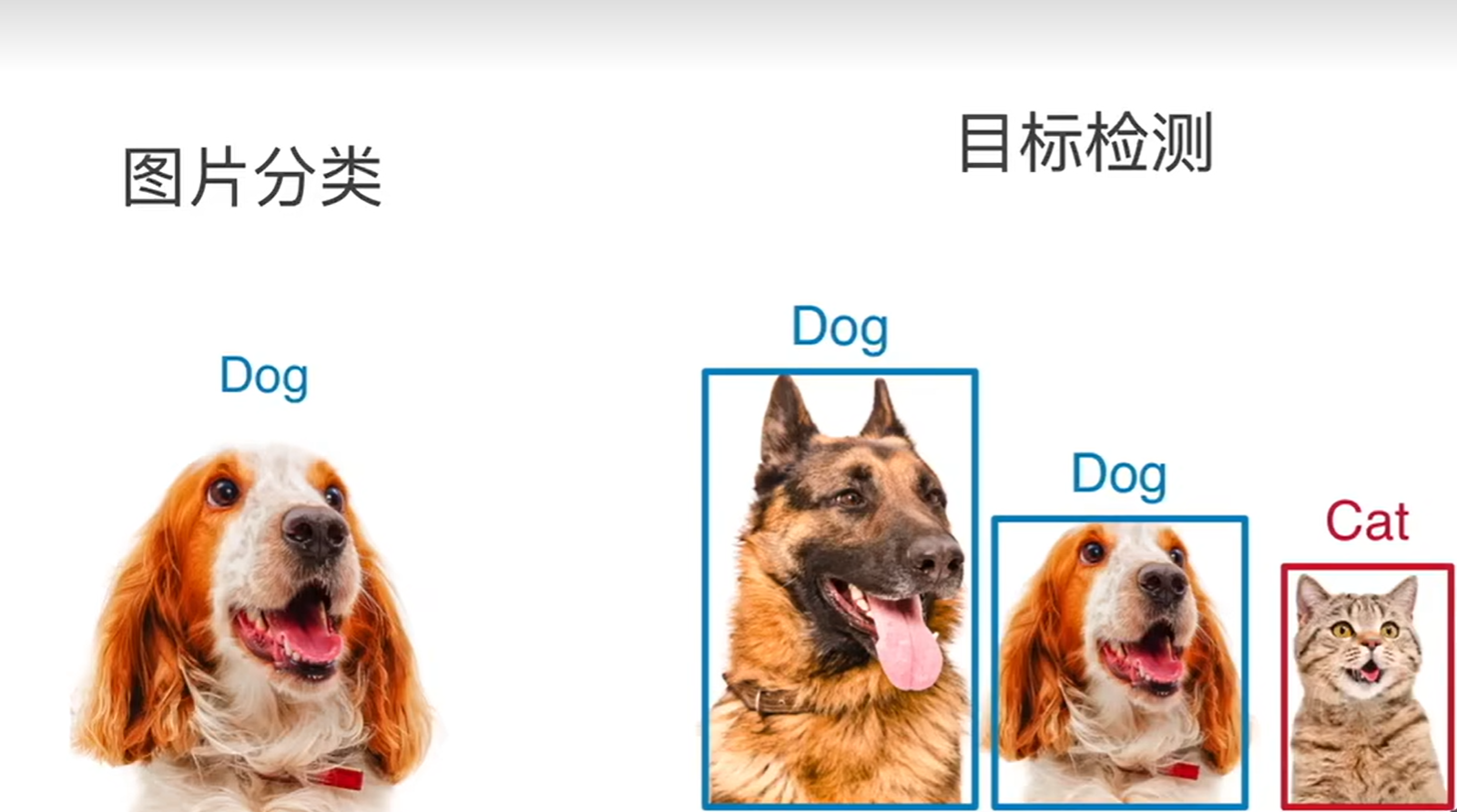
目标检测和图片分类的区别
图片分类:
在图像分类任务中,假设图像中只有一个主要物体对象,目标是识别出这个主要物体对象的类别(其他东西相对来说就不那么重要了)
目标检测:
在目标检测任务中,一张图像里往往不只一个感兴趣的物体对象,目标不仅仅是识别图像中所有感兴趣的物体(找出所有感兴趣的物体),还要找出它们在图像中所在的具体位置(通过方框来表示)
目标检测相对于图片分类来讲所做的工作更多,它需要找出所有感兴趣的物体,当图片中只有一个物体时,可以将目标检测看成是图像分类,把图像中最主要的物体当作是图片的类别,但是当图片中有多个物体的时候,目标检测不仅能将所有的物体都检测出来,还能将他们所在的位置标注出来,所以目标检测的应用场景相对来讲更多
目标检测的应用
- 无人驾驶:通过识别拍摄到的视频图像中的车辆、行人、道路和障碍物的位置来规划行进路线
- 无人售后:通过目标检测识别客户选购的物品
- 机器人通常通过目标检测来检测感兴趣的目标
- 安防领域使用目标检测来检测异常目标,比如歹徒或者炸弹
数据集
每行表示一个物体(图片文件名、物体类别、边缘框)
- 物体检测识别图片里的多个物体的类别和位置
- 位置通常用边缘框表示
边缘框
通过4个数字定义
- (左上x,左上y,右下x,右下y)
- (中间x,中间y,宽,高)
实现
基于matplot
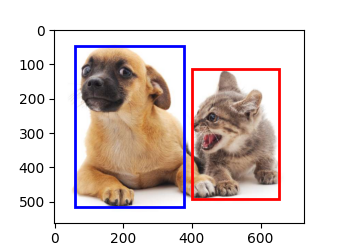
实现代码:
点击查看代码
plt.figure(figsize=(3.5, 2.5))
img = plt.imread('../img/catdog.jpg')
shape1 = bbox_to_rect(dog_bbox, 'blue')
shape2 = bbox_to_rect(cat_bbox, 'red')
plt.imshow(img)
plt.gca().add_patch(shape1) # 添加图形,可自定义
plt.gca().add_patch(shape2)
plt.show()
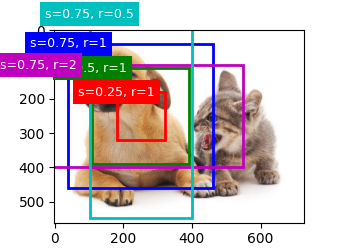
锚框
定义:以每个像素为中心,生成多个缩放比和宽高比不同的边界框
一类目标检测算法是基于锚框
- 提出多个被称为锚框的区域(边缘框)
- 预测每个锚框里是否含有关注的物体,如果是,预测从这个锚框到真实边缘框的偏移
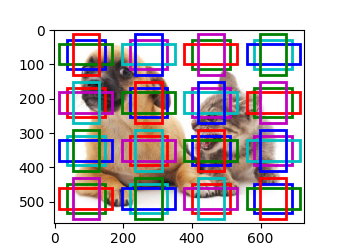
生成多个锚框
步骤:
1、获取数据的宽高信息,缩放比,宽高比
2、计算单个像素的锚框数 n+m-1
3、创建四角坐标
4、添加半高半宽
5、生成锚框中心网格
6、返回(批量大小,锚框数量,4个坐标元素(左上角轴坐标+右下角轴坐标))
IoU-交并比
IoU用来计算两个框之间的相似度:0表示无重叠,1表示重合,杰卡德系指数:给定集合A和B,利用它们的交集大小除以它们并集的大小
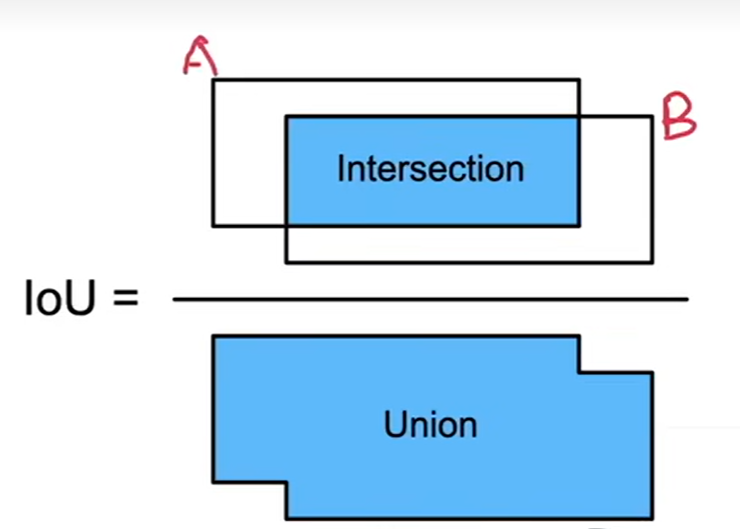
一个框就是一个像素的集合,IoU架构衡量两个框之间的相似度
度量锚框和真实边界框之间的相似性
赋予锚框标号
每个锚框是一个训练样本
将每个锚框,要么标注成背景,要么关联上一个真实边缘框
可能会生成大量的锚框(导致大量的负类样本)
使用非极大值抑制(NMS)输出
- 每个锚框预测一个边缘框
- NMS可以合并相似的预测
- 选中是非背景类的最大预测值
- 去掉所有其他和它IoU值大于θ的预测
- 重复上述过程直到所有预测要么被选中要么被去掉
思路:选取那些邻域里分类数值最高,并且抑制那些分数低的窗口。
做法:设定阈值(阈值通常设定0.3~0.5 ),比较两两区域的IoU与阈值的关系。
常见物体检测算法
R-CNN
初代
- 使用启发式搜索算法来选择锚框
- 使用预训练模型来对每个锚框抽取特征
- 训练一个SVM来对类别分类
- 训练一个线性回归模型来预测边缘框偏移
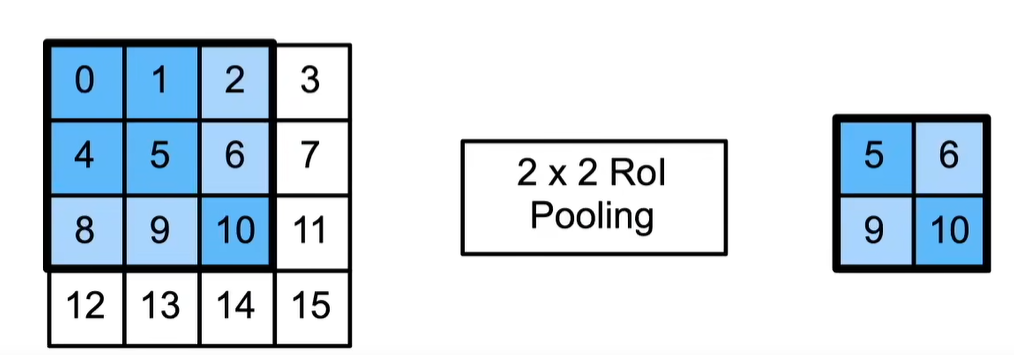
Rol 兴趣区域池化层
- 给定一个锚框,均匀分割成nxm块,输出每块里的最大值
- 不管锚框多大,总是输出nm个值
Fast RCNN
- 使用CNN对图片抽取特征
- 使用Rol池化层对每个锚框生成固定长度特征
Faster R-CNN
使用一个区域提议网络来代替启发式搜索来获得更好的锚框
应用场景:追求高精度
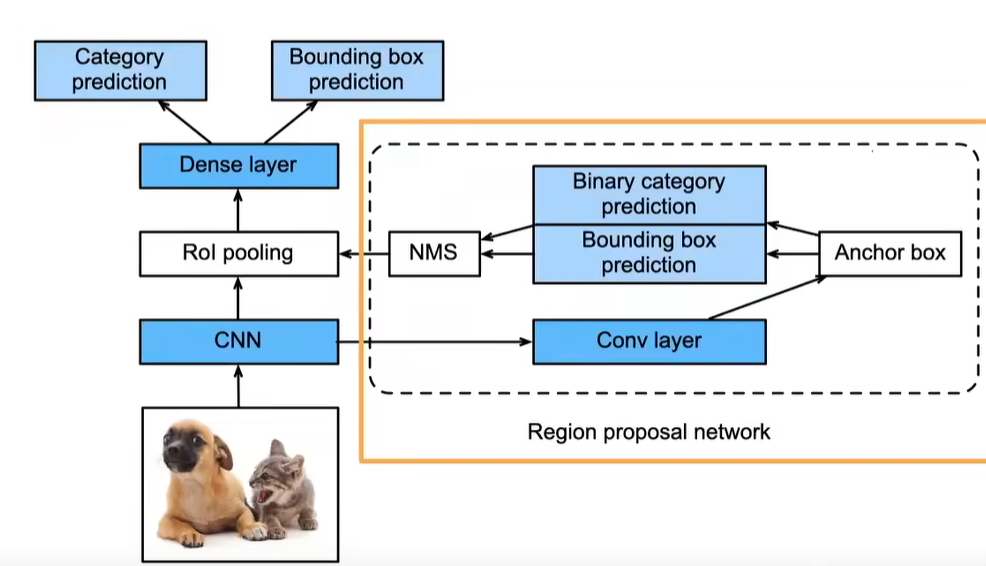
Mask R-CNN
如果有像素级别的标号,使用FCN来利用这些信息
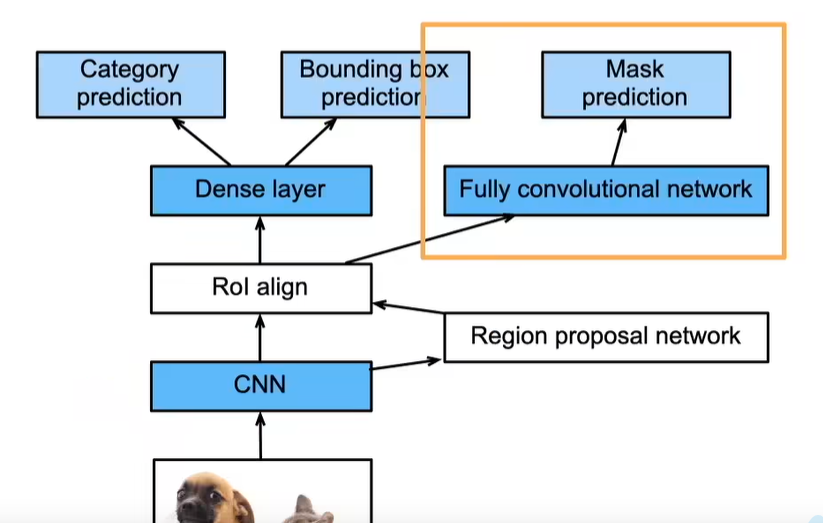
SSD(单发多框检测)
生成多个锚框,以每个像素为中心 n+m-1
- SSD通过单神经网络来检测模型
- 以每个像素为中心的产生多个锚框
- 在多个段的输出上进行多尺度的检测
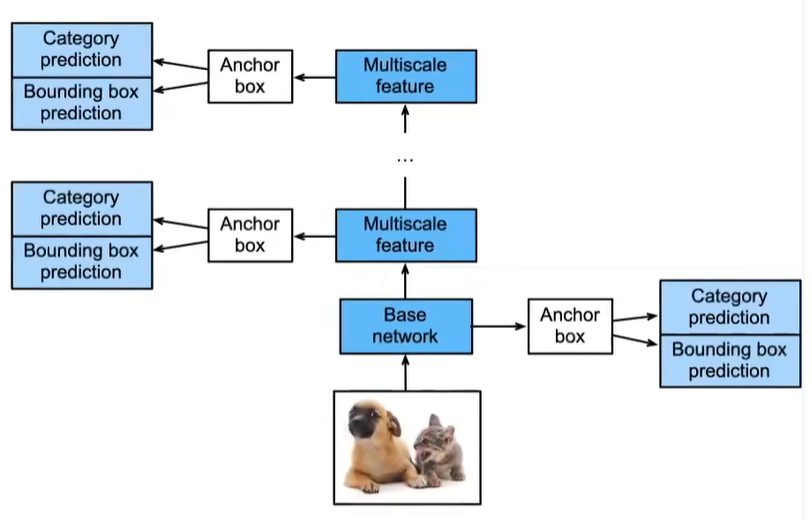
多尺度锚框
首先,先考虑小目标,4行4列 缩放比为0.15
然后,将特征图的高度和宽度缩小一半,一些锚框彼此重叠
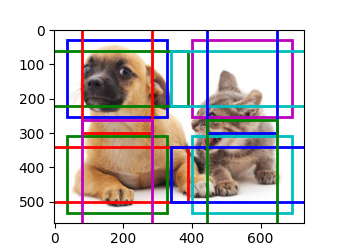
最后,进一步缩小一半,锚框的中心即图像的中心
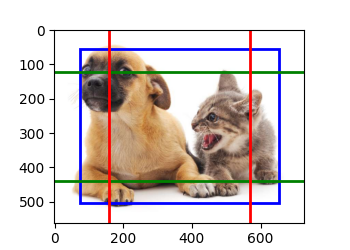
多尺度检测
在某种规模上,假设有c张形状为hXw的特征图,可以生成hw组锚框,其中每组都有a个中心相同的锚框。接下来,每个锚框都根据真实值边界框来标记了类和偏移量。 在当前尺度下,目标检测模型需要预测输入图像上hw组锚框类别和偏移量,其中不同组锚框具有不同的中心。
假设此处的c张特征图是CNN基于输入图像的正向传播算法获得的中间输出。 既然每张特征图上都有hw个不同的空间位置,那么相同空间位置可以看作含有c个单元。 特征图在相同空间位置的c个单元在输入图像上的感受野相同: 它们表征了同一感受野内的输入图像信息。 因此,我们可以将特征图在同一空间位置的c个单元变换为使用此空间位置生成的a个锚框类别和偏移量。 本质上,我们用输入图像在某个感受野区域内的信息,来预测输入图像上与该区域位置相近的锚框类别和偏移量。
当不同层的特征图在输入图像上分别拥有不同大小的感受野时,它们可以用于检测不同大小的目标。 例如,我们可以设计一个神经网络,其中靠近输出层的特征图单元具有更宽的感受野,这样它们就可以从输入图像中检测到较大的目标。
简言之,我们可以利用深层神经网络在多个层次上对图像进行分层表示,从而实现多尺度目标检测。
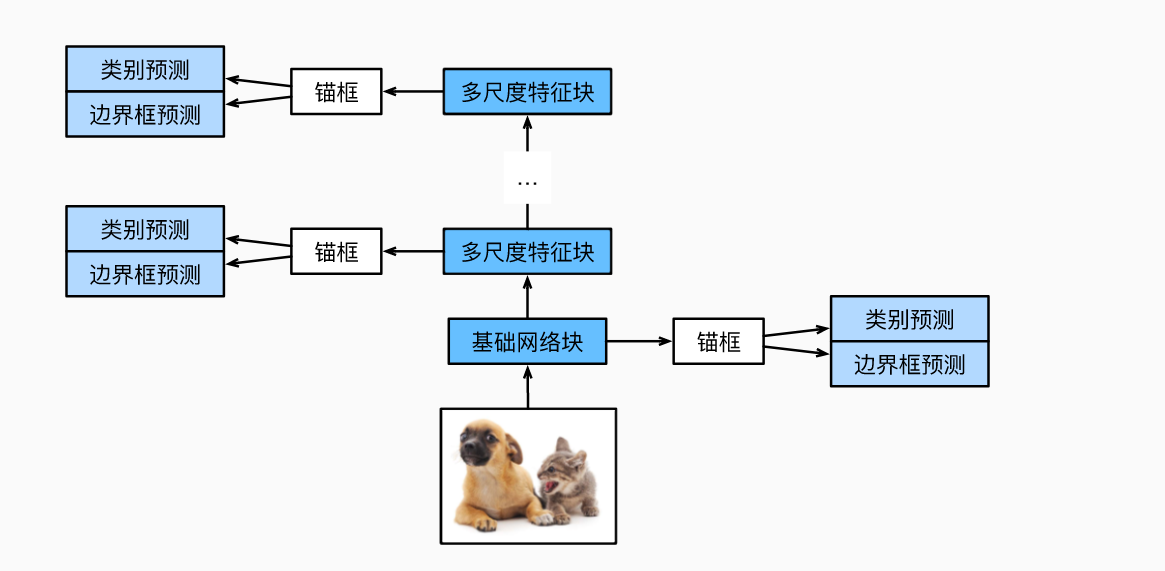
单发多框检测SSD实现
感受野:卷积神经网络每一层输出的特征图(feature map)上的像素点在原始输入图像上映射的区域大小。
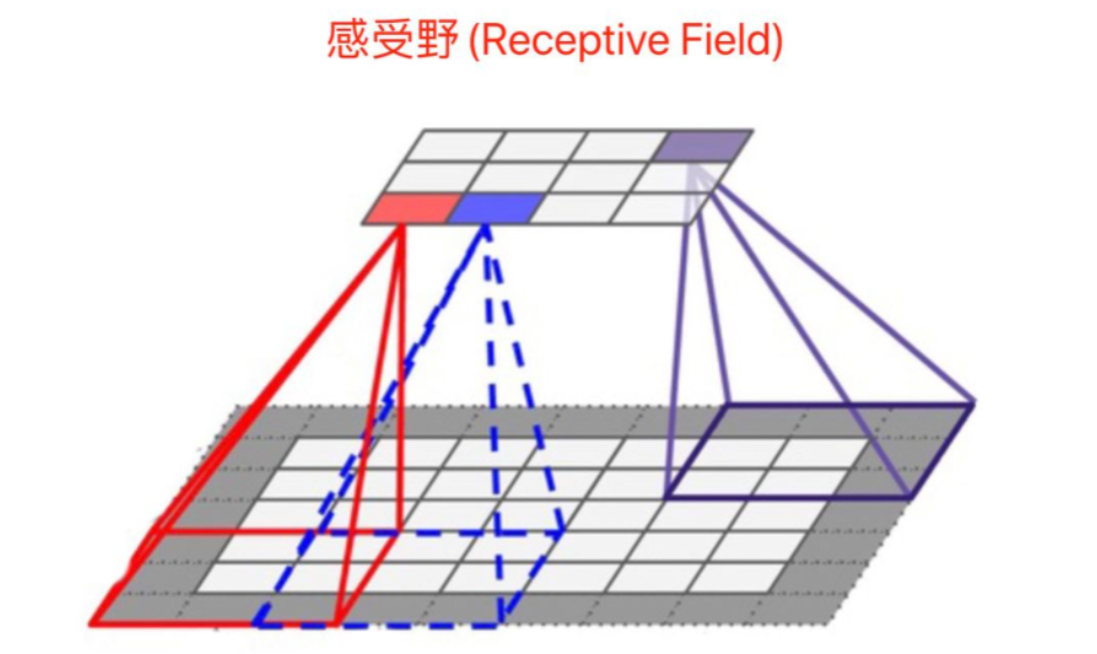
第一层卷积层的输出特征图像素的感受野大小等于卷积核大小,其它卷积层的输出特征图的感受野的大小和它之前所有层的卷积核大小和步长有关系
感受野的计算

YOLO
cente_net
非锚框
评价指标
目标识别(分类)+目标定位(回归)
1 Precision 查准率

2 Recall 查全率

3 Average Precision AP
AP即Average Precision,称为平均准确率,是对不同召回率点上的准确率进行平均,在PR曲线图上表现为PR曲线下面的面积。AP的值越大,则说明模型的平均准确率越高。
4 mean Average Precision mAP
mAP是英文mean average precision的缩写,称为平均精度均值,
在目标检测中,一个模型通常会检测很多种物体,那么每一类都能绘制一个PR曲线,进而计算出一个AP值。那么多个类别的AP值的平均就是mAP.
mAP衡量的是学出的模型在所有类别上的好坏,是目标检测中一个最为重要的指标,一般看论文或者评估一个目标检测模型,都会看这个值,这个值是在0-1之间,越大越好。
一般来说mAP针对整个数据集而言的,AP针对数据集中某一个类别而言的,而percision和recall针对单张图片某一类别的。
5 Interaction over Union IoU
检测结果的矩形框与样本标注的矩形框的交集与并集的比值
一般情况下对于检测框的判定都会存在一个阈值,也就是IoU的阈值,一般可以设置当IoU的值大于0.5的时候,则可认为检测到目标物体。
IoU 的取值范围是0到1,其中0表示没有重叠,1表示完全重叠。
IoU 在目标检测中具有重要的应用,常用于以下几个方面:
- 用于判断目标检测算法的预测结果是否正确,通常通过设置 IoU 阈值来决定预测框是否与真实框匹配。
- 在训练目标检测算法时,用于计算正样本与预测框之间的 IoU,以确定哪些预测框是与真实目标重叠较好的正样本。
- 在评估目标检测算法性能时,常用 IoU 作为指标之一,用于衡量算法的准确性和召回能力。
6 F1-score

7 nms 非极大值抑制
非极大值抑制虽然一般不作评价指标,但是也是目标检测中一个很重要的步骤,因为下期就要步入经典模型的介绍了,所以这里随着评价指标简单介绍下。
单个检测目标
NMS的英文为Non-Maximum Suppression,就是在预测的结果框和相应的置信度中找到置信度比较高的bounding box。对于有重叠在一起的预测框,如果和当前最高分的候选框重叠面积IoU大于一定的阈值的时候,就将其删除,而只保留得分最高的那个。
计算步骤:
- NMS计算出每一个bounding box的面积,然后根据置信度进行排序,把置信度最大的bounding box作为队列中首个要比较的对象;
- 计算其余bounding box与当前最大score的IoU,去除IoU大于设定的阈值的bounding box,保留小的IoU预测框;
- 然后重复上面的过程,直至候选bounding box为空。
多个检测目标
当存在多目标预测时,先选取置信度最大的候选框B1,然后根据IoU阈值来去除B1候选框周围的框。然后再选取置信度第二大的候选框B2,再根据IoU阈值去掉B2候选框周围的框。
8 模型的检测速度
一秒钟能够检测多少张图片,不同的目标检测技术往往会有不同的mAP和检测速度
实验截图
锚框测试
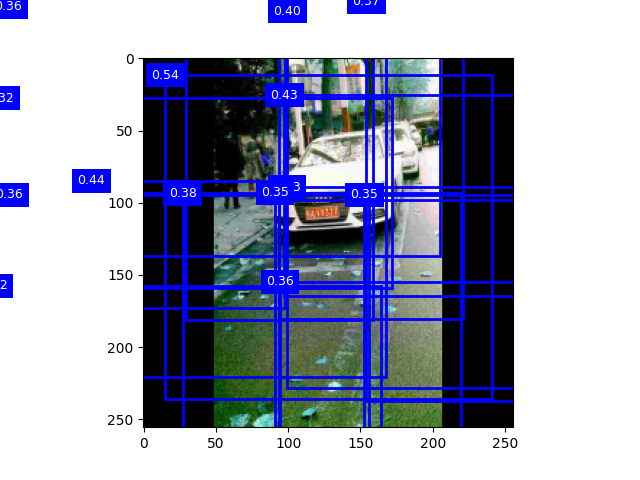
调整阈值
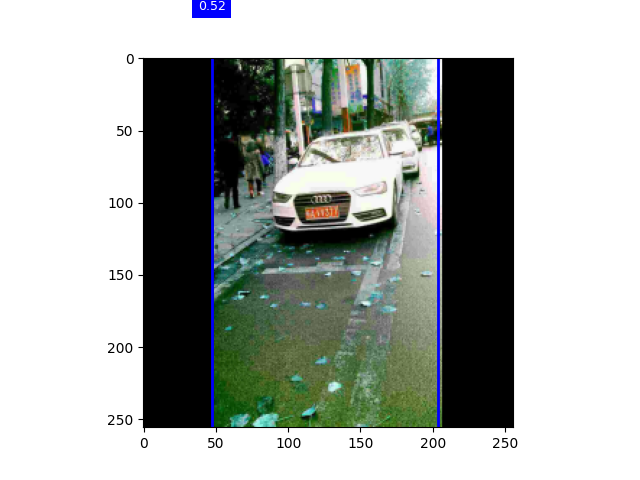
调整锚框缩放比
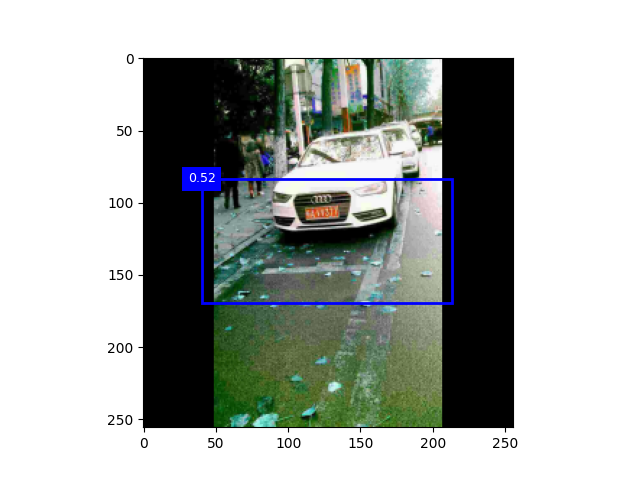
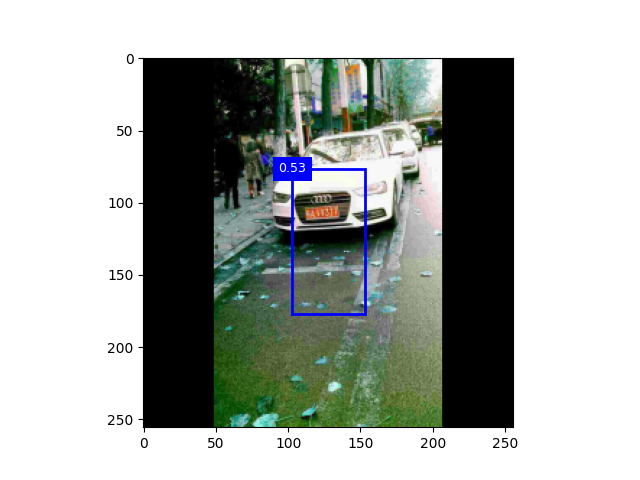
实验流程
一、
迭代一次,800数据集,阈值0.5 迭代十次,,阈值0.3
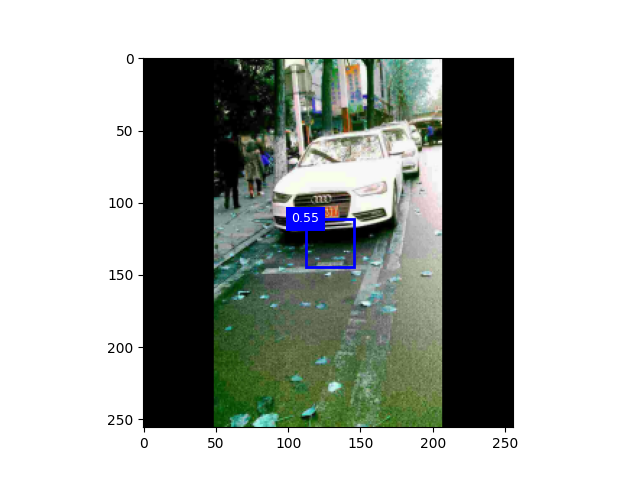
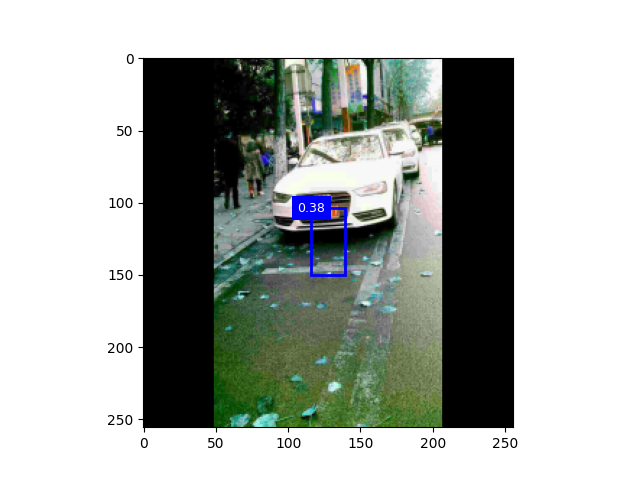
二、
以下考虑增加数据集
数据集5500 迭代次数30 数据集5500 迭代次数15
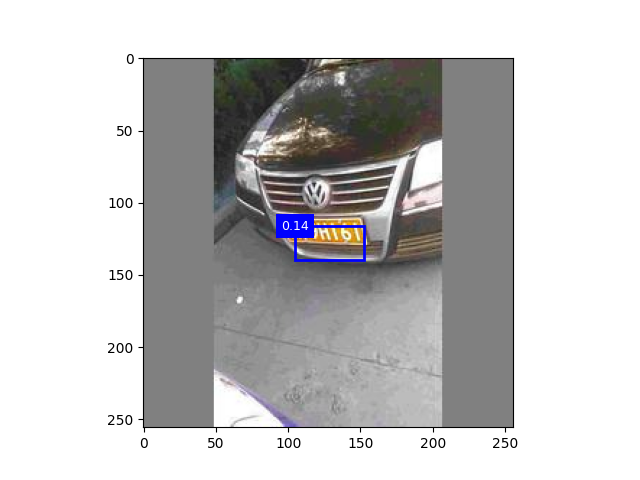
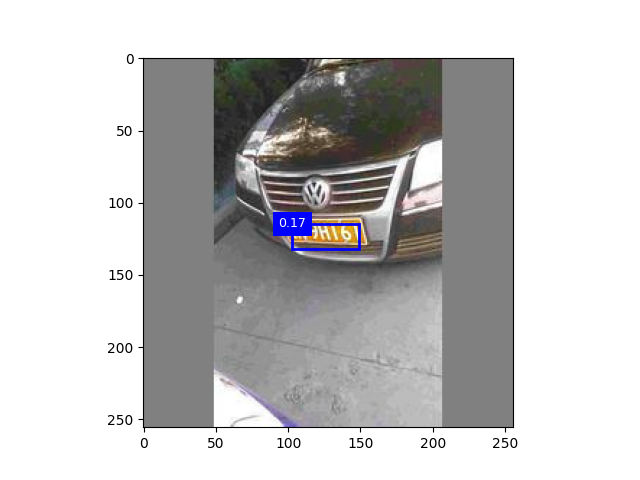
三、代码整合
1、重新提取6000图,九份用来训练,并对其标记提取标签,一份用来随机测试
2、优化图像预处理
等比例缩放并填充
def img_tans(data_path, resize):
image = Image.open(data_path)
in_width, in_height = image.size # 原图尺寸
out_width, out_height = resize # 目标尺寸
scale = min(out_width / in_width, out_height / in_height)
new_width = int(in_width * scale)
new_height = int(in_height * scale)
image = image.resize((new_width, new_height), Image.Resampling.LANCZOS)
delta_width = out_width - new_width
padding = (delta_width // 2, 0, delta_width - (delta_width // 2), 0)
image = ImageOps.expand(image, padding, fill='gray')
return image
3、调整项目结构
4、添加视频检测(效果不好)
四、优化阈值(提高置信度)
要提高 SSD(Single Shot MultiBox Detector)目标检测的置信度,可以尝试以下几种方法:
-
调整模型架构:可以尝试使用更深、更宽的网络架构来增加模型的表示能力,例如增加网络的层数、宽度或引入更多的卷积层。
-
数据增强:通过对训练数据进行旋转、缩放、裁剪、颜色增强等数据增强技术,可以增加模型的鲁棒性,提高检测的准确性和置信度。
-
多尺度特征融合:SSD 在不同层级提取不同尺度的特征,在预测时会合并这些特征。可以尝试改进特征融合机制,以更好地结合不同尺度的信息,提高检测的准确性和置信度。
-
调整损失函数:设计更适合目标检测任务的损失函数,例如 Focal Loss,可以帮助模型更关注难以分类的样本,提高检测的置信度。
-
后处理技术:使用非极大值抑制(NMS)等后处理技术,可以去除重叠的检测框并保留置信度最高的框,从而提高检测结果的质量。
-
模型融合:将多个不同训练方式或结构的模型进行融合,可以提高检测的稳定性和准确性。
-
精细调节参数:调节模型的超参数,如学习率、正则化参数等,以获得更好的性能。
-
持续优化:不断尝试新的技术和方法,例如迁移学习、自监督学习等,以优化模型并提高目标检测的置信度。
综合利用这些方法,可以不断改进 SSD 目标检测模型,提高其在实际场景中的性能和置信度。
实践对比
图1:未进行图像增强
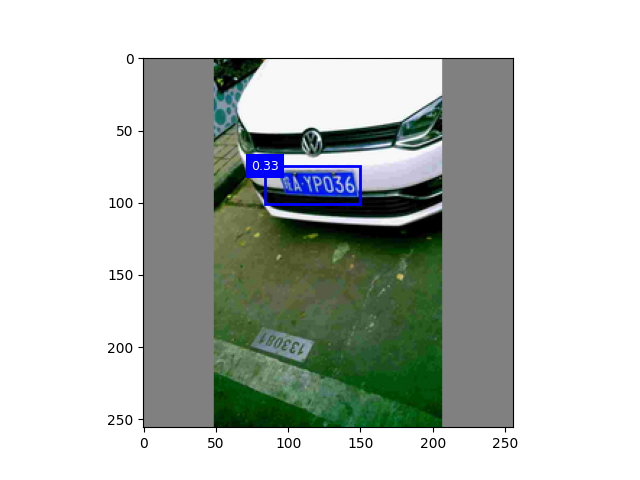
图2:颜色增强
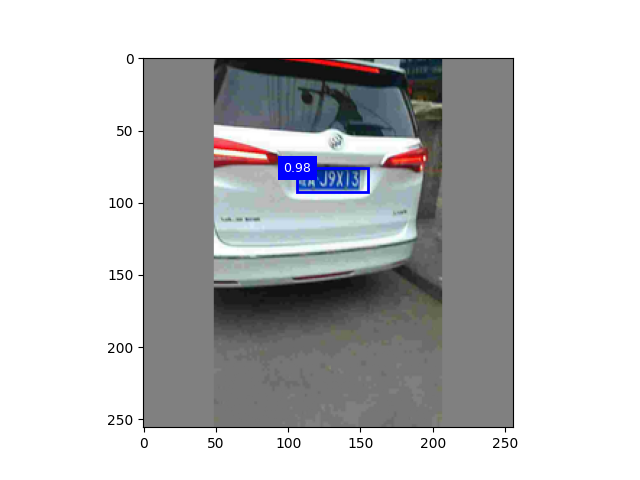
图3:颜色增强+正则化
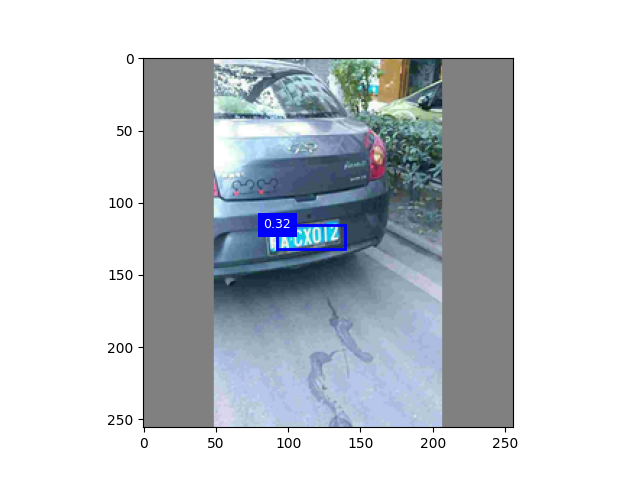
epoch30 + 颜色增强
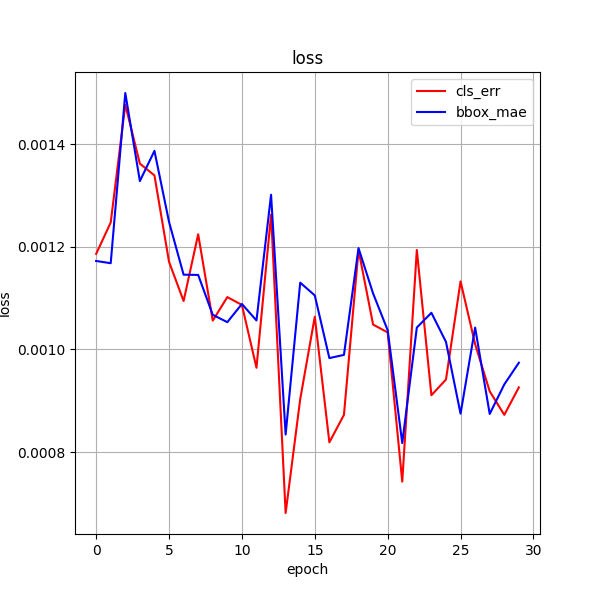
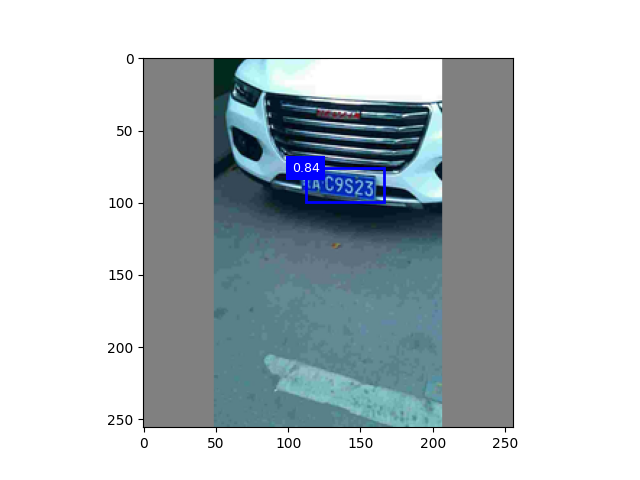
epoch50 + 颜色增强
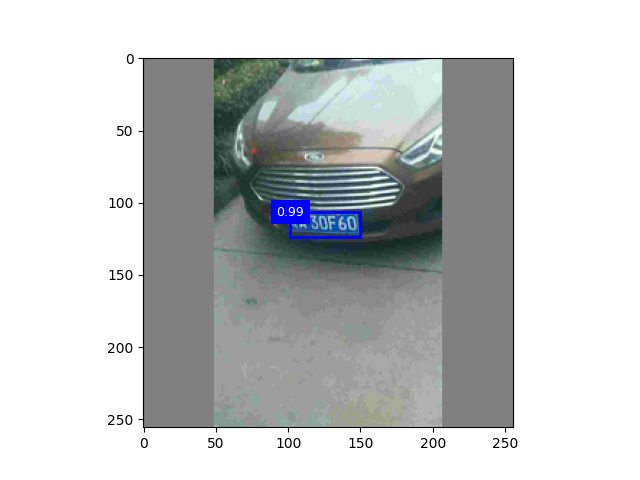
epoch30 + 高斯滤波 +颜色增强
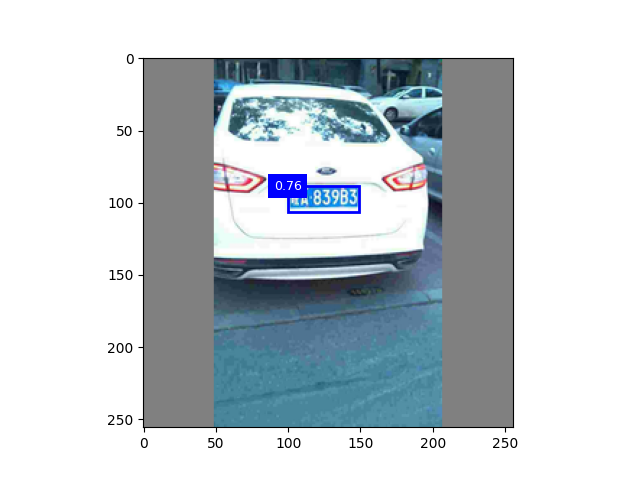
后续工作
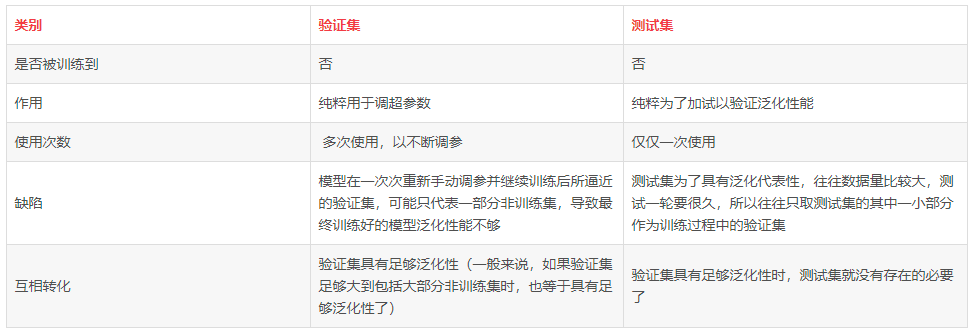
1 重新划分数据集
训练集(train set):用于模型拟合的数据样本。在训练过程中对训练误差进行梯度下降,进行学习,可训练的权重参数。
验证集(validation set):模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估。
测试集(test set):用来评估模最终模型的泛化能力。但不能作为调参、选择特征等算法相关的选择的依据。
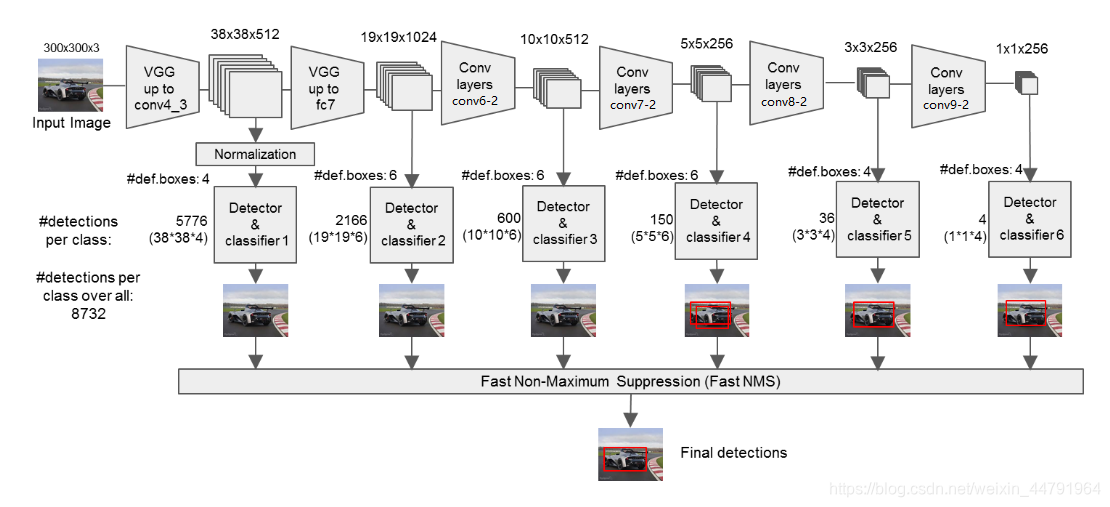
2 完整SSD
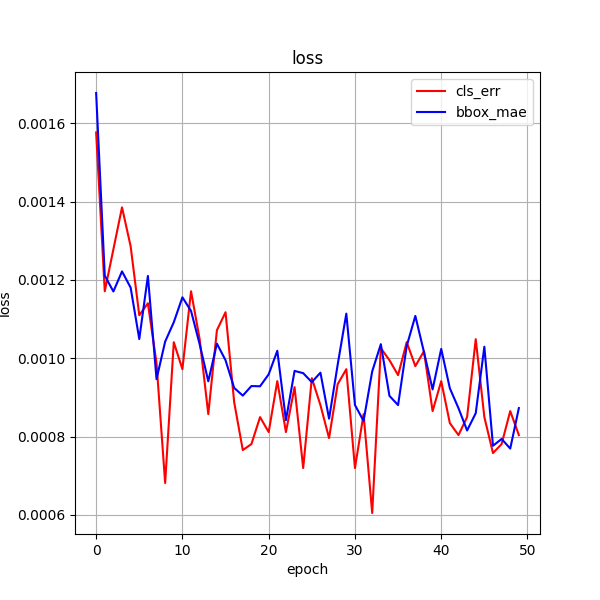
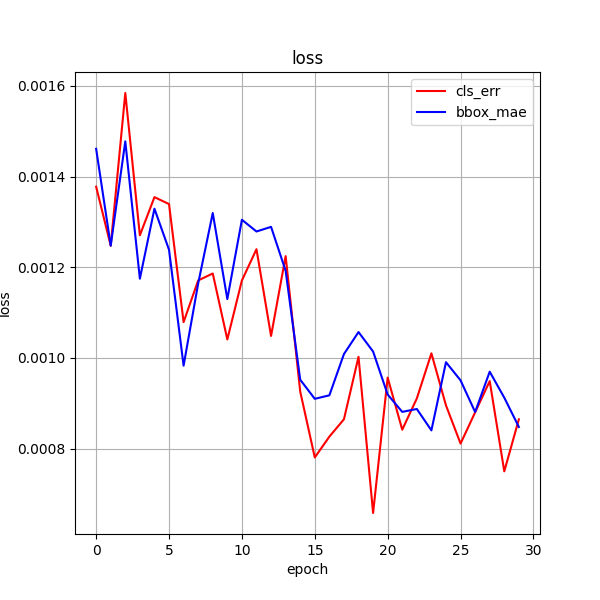
训练效果 30ci
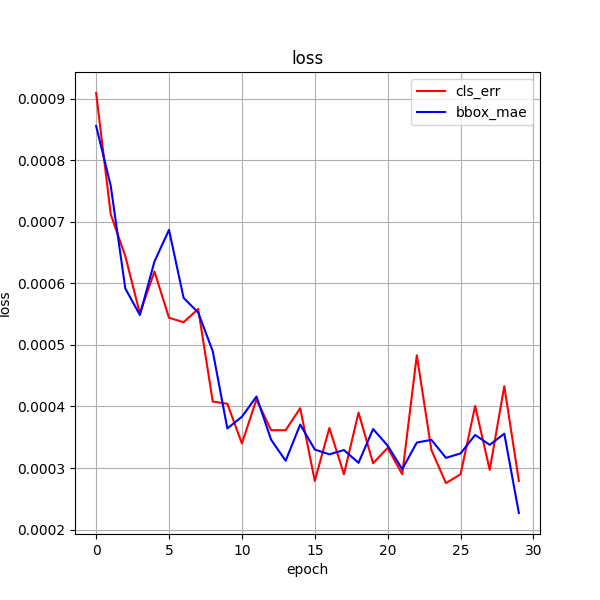
训练 50次
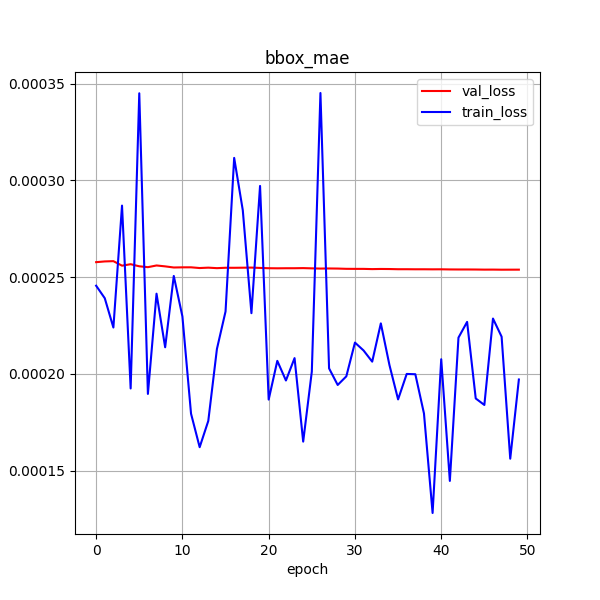
30ci + 50ci
网络运行9g,也尝试过将激活函数relu换成leakyrelu,效果也不是很好,跟tinyssd差不多
3 更换目标检测评估指标
自定义iou选择器
点击查看代码
def box_iou_choice(boxes1, boxes2, giou=False, diou=False, ciou=False):
"""
目标检测评估标准
:param boxes1: 预测框
:param boxes2: 真实框
:return: iou (iou giou diou ciou)
"""
b1_x1, b1_y1, b1_x2, b1_y2 = boxes1[:, 0], boxes1[:, 1], boxes1[:, 2], boxes1[:, 3]
b2_x1, b2_y1, b2_x2, b2_y2 = boxes2[:, 0], boxes2[:, 1], boxes2[:, 2], boxes2[:, 3]
eps = 1e-7
# 区域交集
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
# 区域并集
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
union = w1 * h1 + w2 * h2 - inter + eps # eps防止出现除以0的情况
# 计算iou 交集/并集
iou = inter / union
if giou or diou or ciou:
# 计算最小外接矩形的wh
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1)
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1)
if ciou or diou:
# 计算最小外接矩形角线的平方
c2 = cw ** 2 + ch ** 2 + eps
# 计算最小外接矩形中点距离的平方
center2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 +
(b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4
if diou:
# 输出DIoU
Diou = iou - center2 / c2 # [-1,1]
# return 1 - Diou
return Diou
elif ciou:
v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
# 输出CIoU
Ciou = iou - (center2 / c2 + v * alpha)
# return 1 - Ciou
return Ciou
else:
c_area = cw * ch + eps # convex area
# 输出GIoU
Giou = iou - (c_area - union) / c_area
# return 1 - Giou
return Giou
else:
# 输出IoU
return iou
结合tinyssd,实际演示中并不是很好,已测试giou,ciou
4 重新选择数据集
从ccpd每个文件夹下选择图像,提高图像特征多样性
未添加 无车牌的 图像
50ci giou
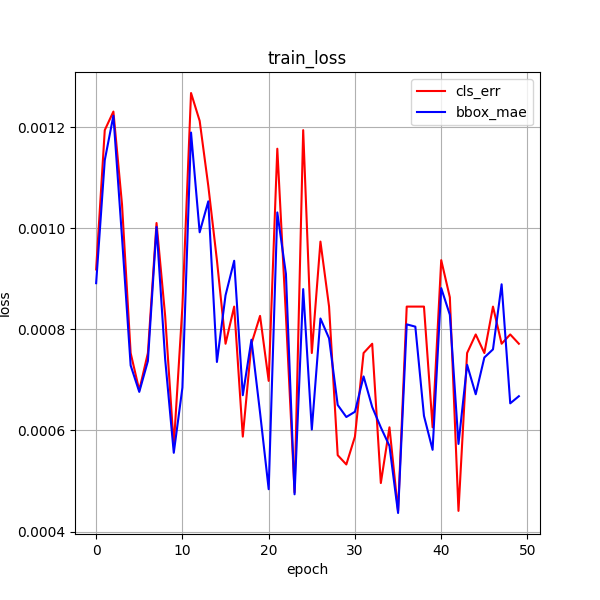
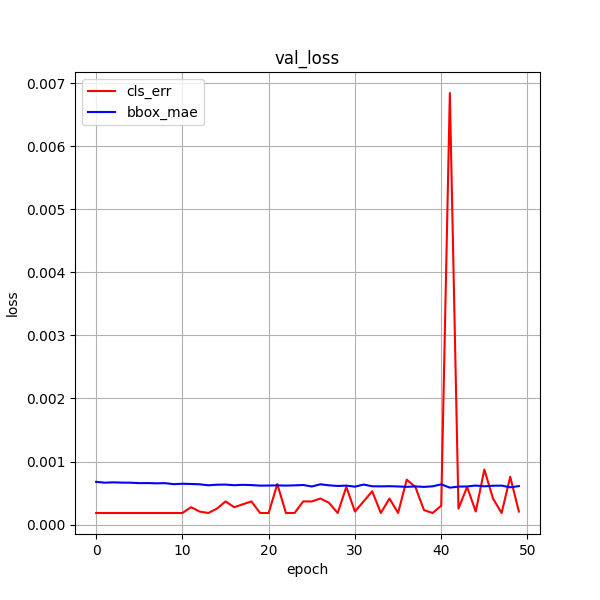
效果:


5 图像处理
- 边缘检测算子处理图像,锐化处理,需要较长时间
robert




车牌信息都很明显,还未实验
tiny+data+iou
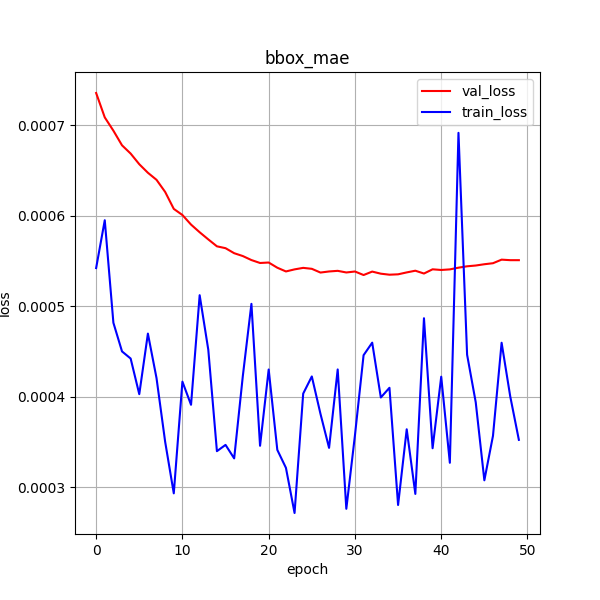

置信度太低
laplacian算子(pass)

- 小波变换进行图像缩放,尽可能多的保留原图特征吗,考虑中
6 实验中的问题
6.1 验证集的测试损失 一直低于 训练集的训练损失
原因可能如下:
(1)验证集的数据量不够多;(8000:1000)
(2)验证集中的样本类别要比训练集更容易分类或者识别等;(验证集和训练集的图像都是随机分配)
(3)训练集中的一些信息泄露(leak)给了验证集;
(4)训练集做了数据增强 (训练集做了颜色增强)
6.2 代码遇到的问题
-
文件夹中的文件乱序打开,解决办法如下:
images = os.listdir(os.path.join(self.path, 'images'))
images.sort() # 顺序打开文件列表 -
图像转视频,乱码打不开,解决办法如下:
videoWriter = cv2.VideoWriter(video_path, fourcc, fps, im_size, True)
最后一个参数True (bool): 这是一个可选参数,通常用于指示是否应该为视频文件创建彩色帧。在OpenCV中,默认情况下,帧是以BGR格式写入的,所以您通常不需要更改此参数。但是,某些编解码器可能要求使用灰度帧,这种情况下可能会传递 False,最后导致生成的视频打不开 -
图像的打开方法不同,格式不同,处理方法不同
- cv2.imread
所属库:OpenCV(通常通过 import cv2 导入)
用途:读取图像文件,主要用于计算机视觉任务。
返回的数据类型:一个 NumPy 数组,通常是三维的(高度 x 宽度 x 通道),数据类型通常是 uint8。在 OpenCV 中,图像通常是以 BGR 格式存储的,而不是 RGB。
示例:img = cv2.imread('image.jpg') - plt.imread
所属库:Matplotlib(通常通过 import matplotlib.pyplot as plt 导入,但 plt.imread 不直接来自 pyplot,而是来自 matplotlib.image)
用途:读取图像文件,主要用于绘图和数据可视化。
返回的数据类型:一个 NumPy 数组,通常是三维的(高度 x 宽度 x 通道),数据类型通常是 float32,并且像素值在 0 到 1 之间。图像是以 RGB 格式存储的。
示例:img = plt.imread('image.jpg') - Image.open
所属库:PIL(Python Imaging Library)或它的一个分支 Pillow(通常通过 from PIL import Image 导入)
用途:读取图像文件,用于图像处理和操作。
返回的数据类型:一个 PIL 图像对象,该对象提供了许多方法和属性来处理图像。可以使用 convert 方法将其转换为 RGB 模式,并使用 numpy.array 将其转换为 NumPy 数组。
示例:img = Image.open('image.jpg')
- cv2.imread
-
tensor类型的形状变换以及合并
torch.stack会沿着一个新的维度(维度默认为0)连接序列中的张量。所有张量必须具有相同的形状。
torch.cat会沿着指定的维度连接张量序列。与 torch.stack 不同,张量可以沿着任何现有维度连接,但除连接维度外,所有其他维度的大小必须相同。
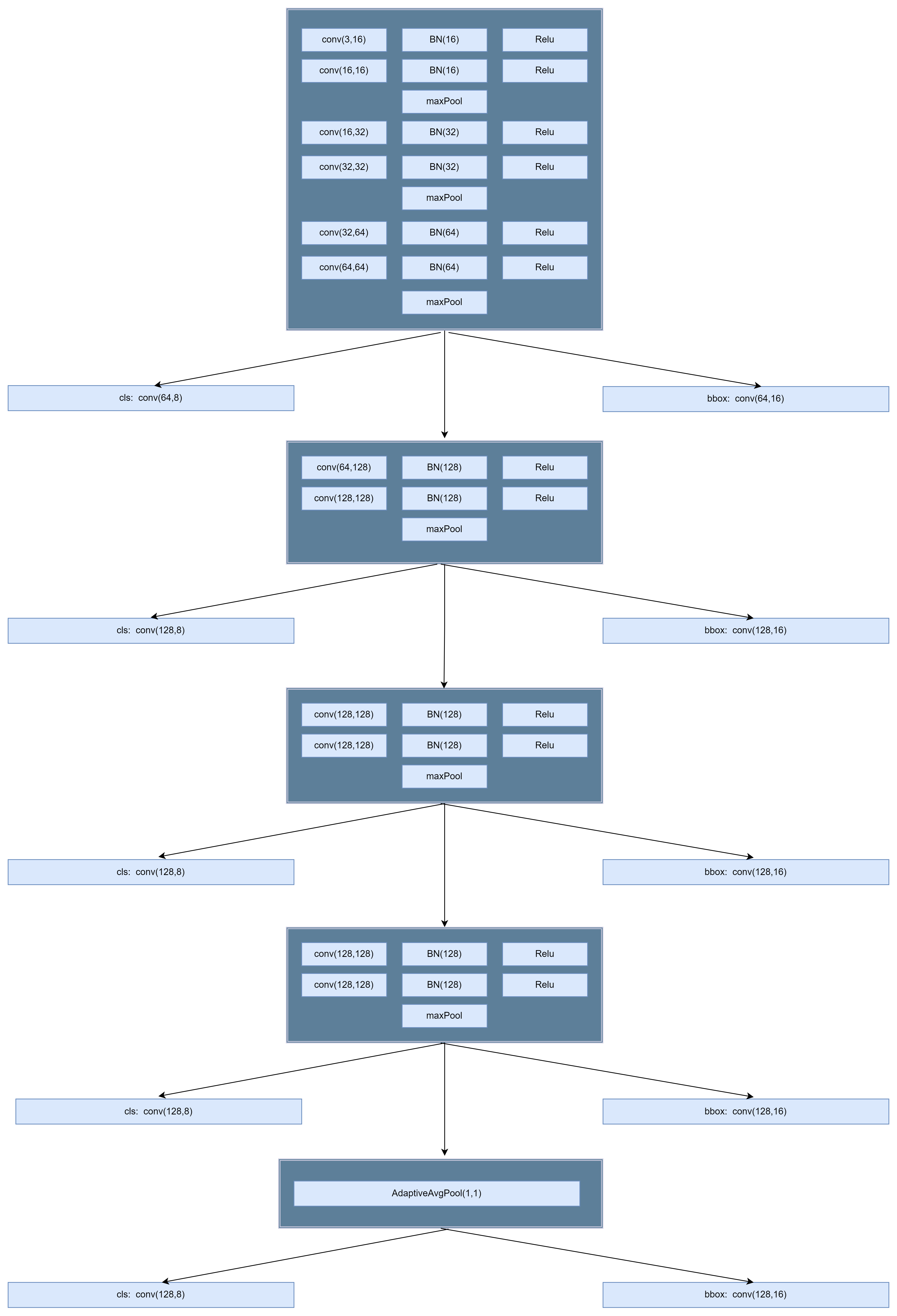
7 实验主要网络TinySSD