exam
机器学习
1、概念
机器学习:计算机模拟人进行学习,从数据中不断获取新的信息或技能以改善自身的性能
监督学习:教计算机如何去完成任务。它的数据集是有标签的,训练目标是能够给新数据(测试数据)以正确的标签(训练数据有目标数据项,用训练数据训练出目标模型)
分类问题:预测离散值的输出,区分类别
回归问题:预测一个连续值的输出,预测之后的拟合值
无监督学习:让计算机自己去进行学习,它的数据集是无标签的,训练目标是对观察值进行分类或者区分等。(用训练数据训练出模型,自己归类或拟合出目标模型)
2、K-means具体 手动计算 欧氏距离
思想:
首先指定需要划分的簇的个数k值;
然后随机地选择k个初始数据对象点作为初始的聚类中心;
接着计算其余的各个数据对象到这k个初始聚类中心的距离,把数据对象划归到距离它最近的那个中心所处在的簇类中,
最后调整新类并且重新计算出新类的中心,如果两次计算出来的聚类中心未曾发生任何的变化,那么就可以说明数据对象的调整己经结束,也就是说聚类采用的准则函数是收敛的,表示算法结束。
步骤:
(1) 从 n个数据对象任意选择 k 个对象作为初始聚类中心;
(2) 根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分;
(3) 重新计算每个(有变化)聚类的均值(中心对象);
(4) 计算标准测度函数,当满足一定条件,如函数收敛时,则算法终止;如果条件不满足则回到步骤(2)
评估标准:
簇内相似度高且簇间相似度低
举例如下:
我搞了6个点,从图上看应该分成两推儿,前三个点一堆儿,后三个点是另一堆儿。现在手工执行K-Means,体会一下过程,同时看看结果是不是和预期一致。
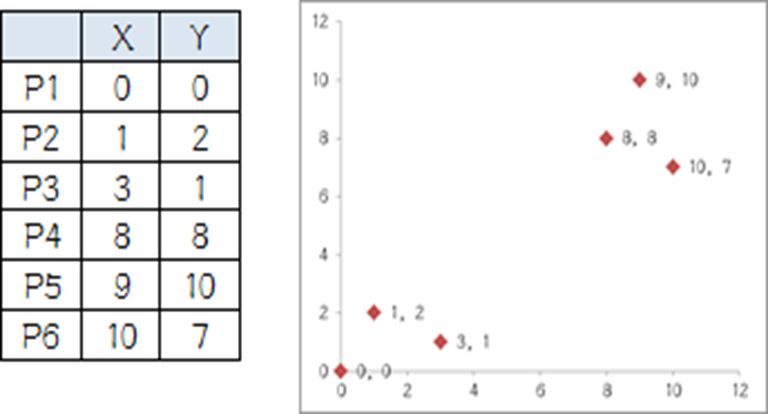
第一步:选择初始大哥:选P1、P2(初始质心)
第二步:计算小弟和大哥的距离
P3到P1的距离从图上也能看出来(勾股定理),是√10 = 3.16;P3到P2的距离√((3-1)2+(1-2)2 = √5 = 2.24,所以P3离P2更近,P3就跟P2混。同理,P4、P5、P6也这么算,如下:
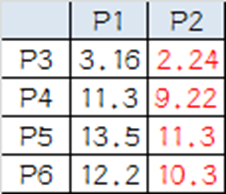
P3到P6都跟P2更近,所以第一次站队的结果是:
·组A:P1
·组B:P2、P3、P4、P5、P6
第三步:人民代表大会
组A没啥可选的,大哥还是P1自己
组B有五个人,需要选新大哥,这里要注意选大哥的方法是每个人X坐标的平均值和Y坐标的平均值组成的新的点,为新大哥,也就是说这个大哥是“虚拟的”。
因此,B组选出新大哥的坐标为:P哥((1+3+8+9+10)/5,(2+1+8+10+7)/5)=(6.2,5.6)。
综合两组,新大哥为P1(0,0),P哥(6.2,5.6),而P2-P6重新成为小弟。
第四步:再次计算小弟到大哥的距离
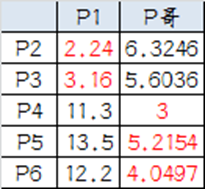
这时可以看到P2、P3离P1更近,P4、P5、P6离P哥更近,所以第二次站队的结果是:
·组A:P1、P2、P3
·组B:P4、P5、P6(虚拟大哥这时候消失)
第五步:第二次人民代表大会
按照上一届大会的方法选出两个新的虚拟大哥:P哥1(1.33,1) P哥2(9,8.33),P1-P6都成为小弟。
第六步:第三次计算小弟到大哥的距离
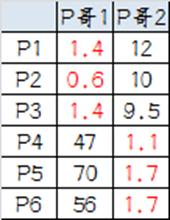
这时可以看到P1、P2、P3离P哥1更近,P4、P5、P6离P哥2更近,所以第二次站队的结果是:
·组A:P1、P2、P3
·组B:P4、P5、P6
我们发现,这次站队的结果和上次没有任何变化了,说明已经收敛,聚类结束,聚类结果和我们最开始设想的结果完全一致。
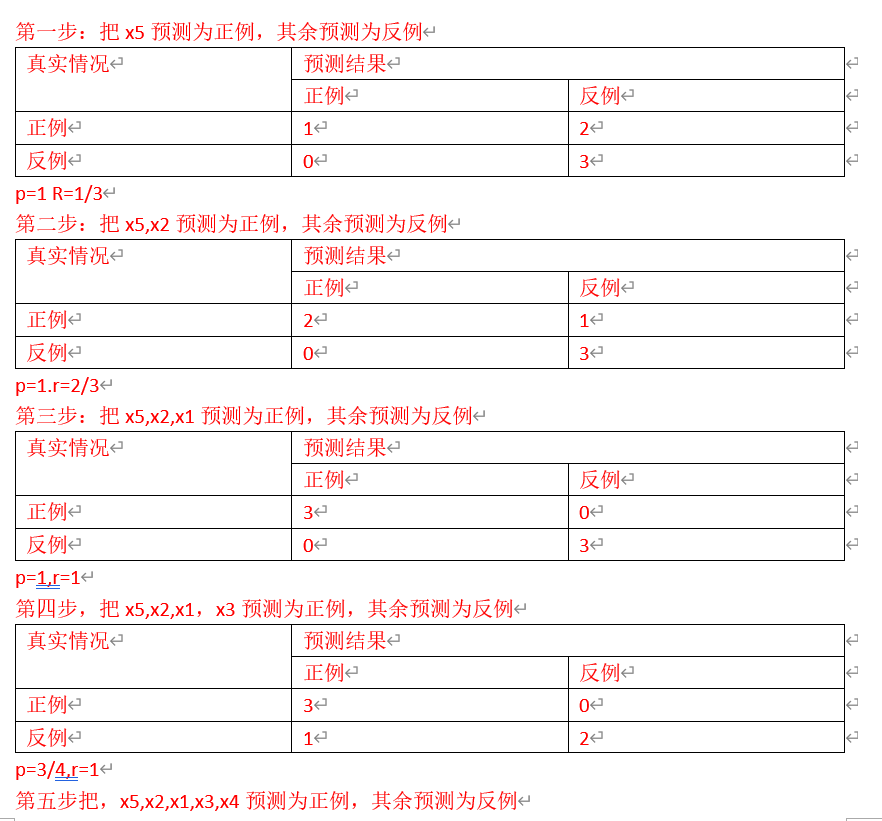
3、模型评估 指标:精确度。。以及指标计算
查准率 查全率
查准率(准确率):描述检索到结果中有多少是正确的
查全率(召回率):描述所有正确的结果中有多少被检索出来了
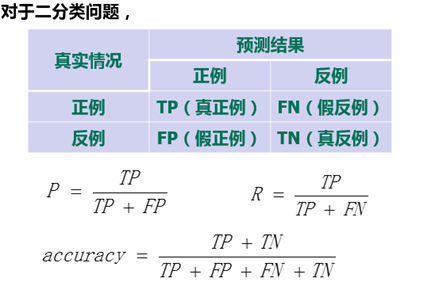
对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例(TP),假反例(FN),假正例(FP),真反例(TN),具体分类结果如下 :

真阳性(TP)——正确的肯定
真阴性(TN)——正确的否定
假阳性(FP)——错误的肯定,假报警,第一类错误
假阴性(FN)——错误的否定,未命中,第二类错误
查准率P和查全率R分别定义为:
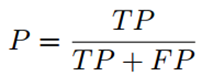
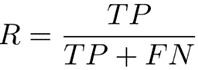
查准率关心的是”预测出正例的正确率”即从正反例子中挑选出正例的问题。预测结果中真正的正例的比例。
查全率关心的是”预测出正例的保证性”即从正例中挑选出正例的问题。所有正例中被正确预测出来的比例。
F1度量

Fβ度量

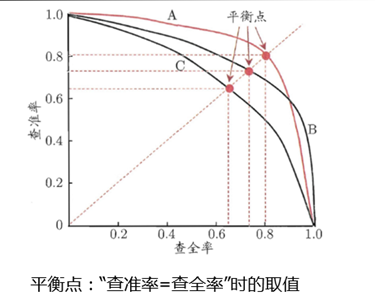
PR曲线
在linear model中,我们对各个特征线性组合,得到linear score,然后确定一个threshold,linear score ﹤threshold 判为负类,linear score ﹥threshold 判为正类。画PR曲线时, 我们可以想象threshold 是不断变化的。首先,threshold 特别大,这样木有一个是正类,我们计算出查全率与查准率; 然后 threshold 减小, 只有一个正类,我们计算出查全率与查准率;然后 threshold再减小,有2个正类,我们计算出查全率与查准率;threshold减小一次,多出一个正类,直到所有的类别都被判为正类。 然后以查全率为横坐标,查准率为纵坐标,画出图形即可。
PR曲线绘制前提:



Roc曲线 绘画 以及 计算
P-R图:
纵坐标:p查准率 P = TP/(TP+FP)
横坐标:r查全率 R = TP/(TP+FN)
若pr曲线A包住B则学习器A的性能优于学习器B的性能
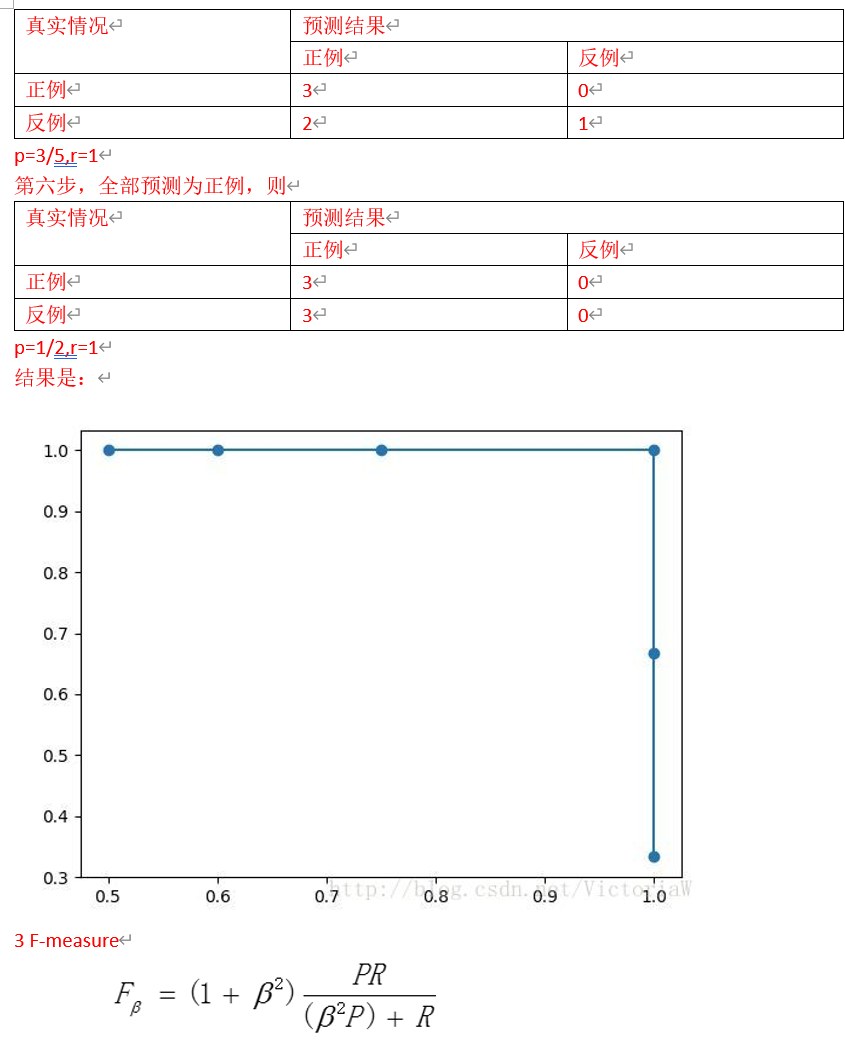
ROC曲线
纵坐标:真正例率 TPR = TP/(TP+FN)
横坐标:假正例率 FPR = FP/(FP+TN)
若一个学习器的ROC曲线被另一个学习器的曲线完全包住,则后者的性能优于前者
若两者曲线发生交叉,则难以判断,合理判据是比较ROC曲线下的面积,即AUC

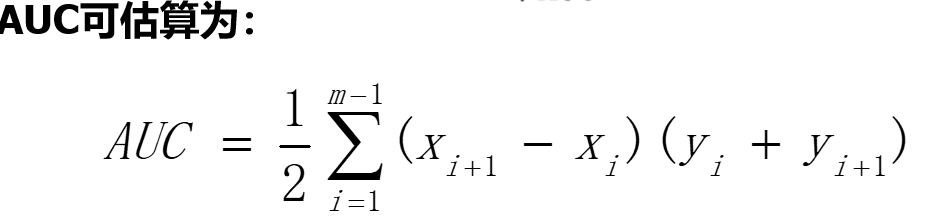
4、线性规划模型 带正则化 梯度下降法
线性规划模型



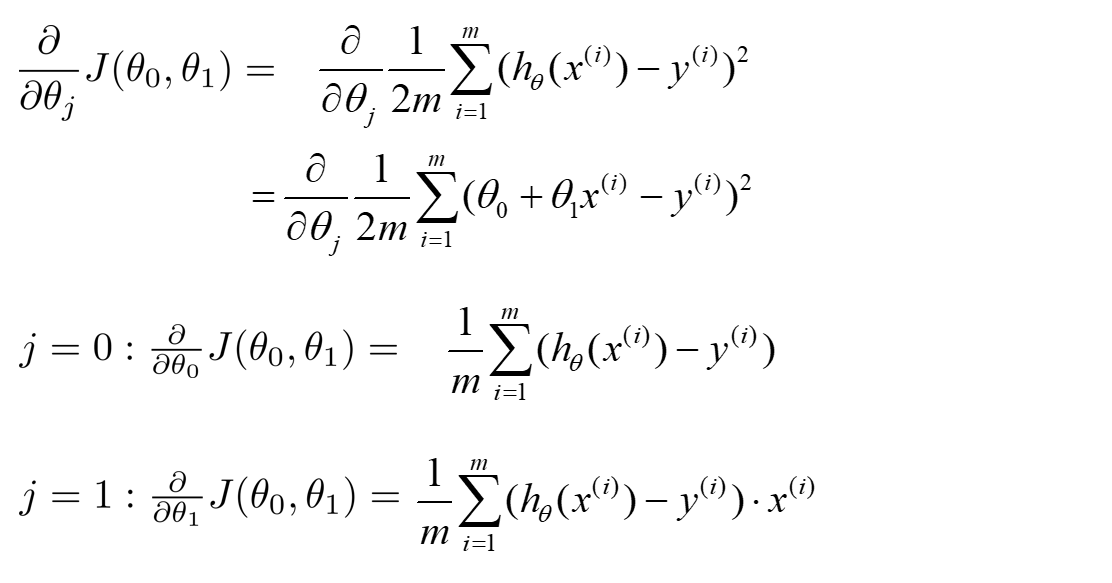

线性回归正则化的梯度下降和正规方程


正则化后的梯度下降
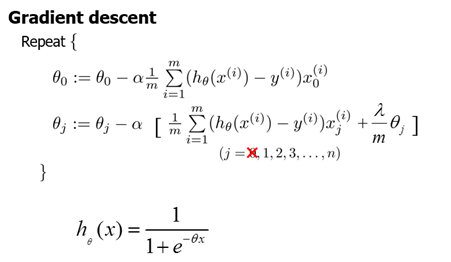
梯度下降法
梯度下降法作用:能够找出cost function函数的最小值;
梯度下降原理:将函数比作一座山,我们站在某个山坡上,往四周看,从哪个方向向下走一小步,能够下降的最快;
方法:
(1)先确定向下一步的步伐大小,我们称为Learning rate;
(2)任意给定一个初始值:;
(3)确定一个向下的方向,并向下走预先规定的步伐,并更新;
(4)当下降的高度小于某个定义的值,则停止下降;
算法:

学习率的作用
学习率决定了下降的步伐大小,下降的步伐大小非常重要,因为如果太小则找到函数最小值的速度就很慢,如果太大,则可能会超过最小值,无法收敛甚至发散;
正规方程
采用矩阵运算能够直接求解出参数θ。假设一个数据集X有m个样本,n个特征。则假设函数为: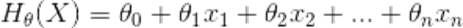 ,数据集X的特征向量表示为:
,数据集X的特征向量表示为:
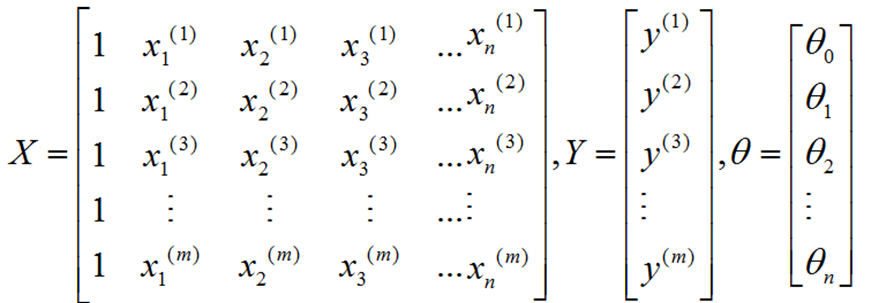

梯度下降法和正规方程对比


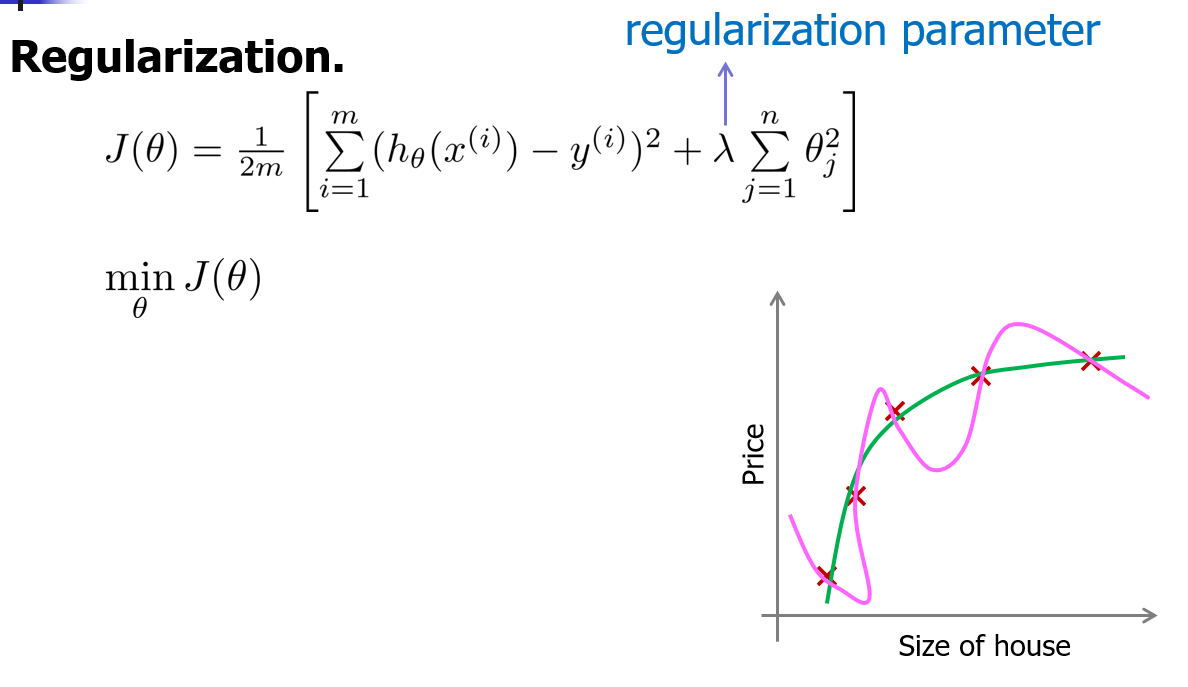
正则化

正规

正则化参数的目标
λ在这里我们称做正则化参数。λ 要做的就是控制在两个不同的目标中的平衡关系。它的目标:
1、第一个目标就是我们想要训练,使假设更好地拟合训练数据。我们希望假设能够很好的适应训练集。
2、第二个目标是我们想要保持参数值较小。(通过正则化项)
在正则化线性回归中,如果正则化参数值λ被设定为非常大,那么将会发生什么呢?
我们将会非常大地惩罚参数θ1 θ2 θ3 θ4 … 也就是说,我们最终惩罚θ1 θ2 θ3 θ4 …在一个非常大的程度,那么我们会使所有这些参数接近于零。
如果我们这么做,那么就是我们的假设中相当于去掉了这些项,并且使我们只是留下了一个简单的假设,这个假设只能表明房屋价格等于θ0的值,那就是类似于拟合了一条水平直线,对于数据来说这就是一个欠拟合。这种情况下这一假设它是条失败的直线,对于训练集来说这只是一条平滑直线,它没有任何趋势,它不会去趋向大部分训练样本的任何值。
这句话的另一种方式来表达就是这种假设有过于强烈的"偏见"或者过高的偏差 (bias),认为预测的价格只是等于θ0。对于数据来说这只是一条水平线。
若 λ设置的非常大,则会使
1、算法依然正常运行,λ将破坏它。
2、算法无法消除过拟合。
3、算法将导致欠拟合。(不能很好地拟合训练数据)
4、梯度下降算法无法收敛。
调试误差
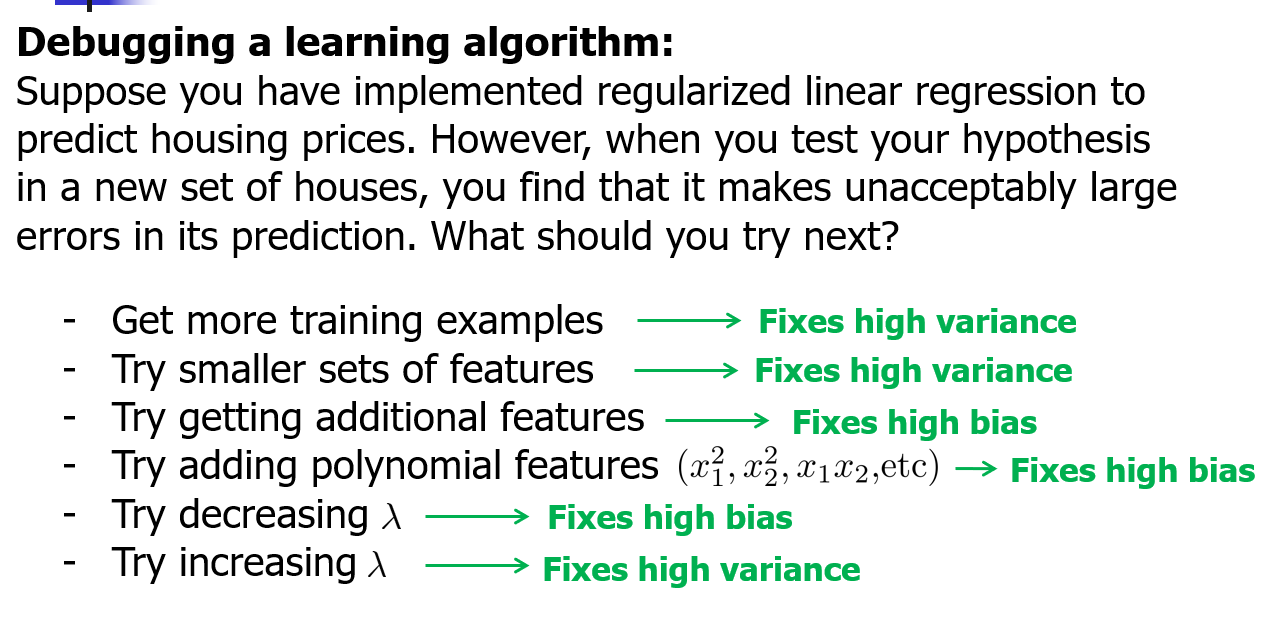
获取更多训练集----修正高方差(过拟合)
尝试更小的特征集----修正高方差
尝试获取更多的特征----修正高偏差(欠拟合)
尝试添加多项式特征----修正高偏差
尝试减小正则化参数----修正高偏差
尝试增加正则化参数----修正高方差
5、过拟合 欠拟合 判断 以及 解决方法
过拟合:(机器学习面临的关键障碍:过拟合无法彻底避免,只能缓解)学习得到的假设函数能够很好的拟合训练集,但不能很好的拟合测试集
1)原因:学习能力过于强大
2)解决方法:使用重采样来评价模型效能、保留一个验证数据集、减少特征维度、采用正则化方法(保留所有的特征,通过降低参数的值来影响模型,正则化参数不能太大,否则会导致欠拟合)
解决过拟合(高方差)的思路
过拟合问题,根本的原因则是特征维度过多,导致拟合的函数完美的经过训练集,但是对新数据的预测结果则较差。
1、使用重采样来评价模型效能。
2、保留一个验证数据集。
3、减少特征维度。
4、采用正则化方法,保留所有的特征,通过降低参数θ的值,来影响模型。
欠拟合:
1)原因:学习能力低下
2)解决方法:决策树学习中扩展分支、神经网络学习中增加训练轮数等
解决欠拟合(高偏差)的思路:
欠拟合问题,根本的原因是特征维度过少,导致拟合的函数无法满足训练集,误差较大。
1、增加模型的参数维度。如利用线性回归预测房屋价格的例子中,增加“卧室数量”,“停车位数量”,“花园面积”等维度以解决欠拟合,或相应的减少维度去解决过拟合。
2、添加多项式特征,在线性回归模型中,可增加多项式维度,比如将加入高阶多项式来更好地拟合曲线,用以解决欠拟合。
3、减少正则化参数,正则化的目的是用来防止过拟合的,但是现在模型出现了欠拟合,则需要减少正则化参数。
6、Bp 过拟合怎么解决
提出新型激活函数ReLU改进网络

7、决策树
基本思想
分而治之
停止条件 (导致递归返回)
1)当前节点包含的样本全属于同一类别,无需划分
2)当前属性集为空,或是所有样本在所有属性上取值相同,无法划分
3)当前节点包含的样本集合为空,不能划分
划分选择
1)信息增益、熵



信息增益对可取值数目较多的属性有所偏好
2)增益率

3)基尼指数

划分选择VS剪枝处理

剪枝处理

1)预剪枝

2)后剪枝

3)两者对比

8、异常检测 算法

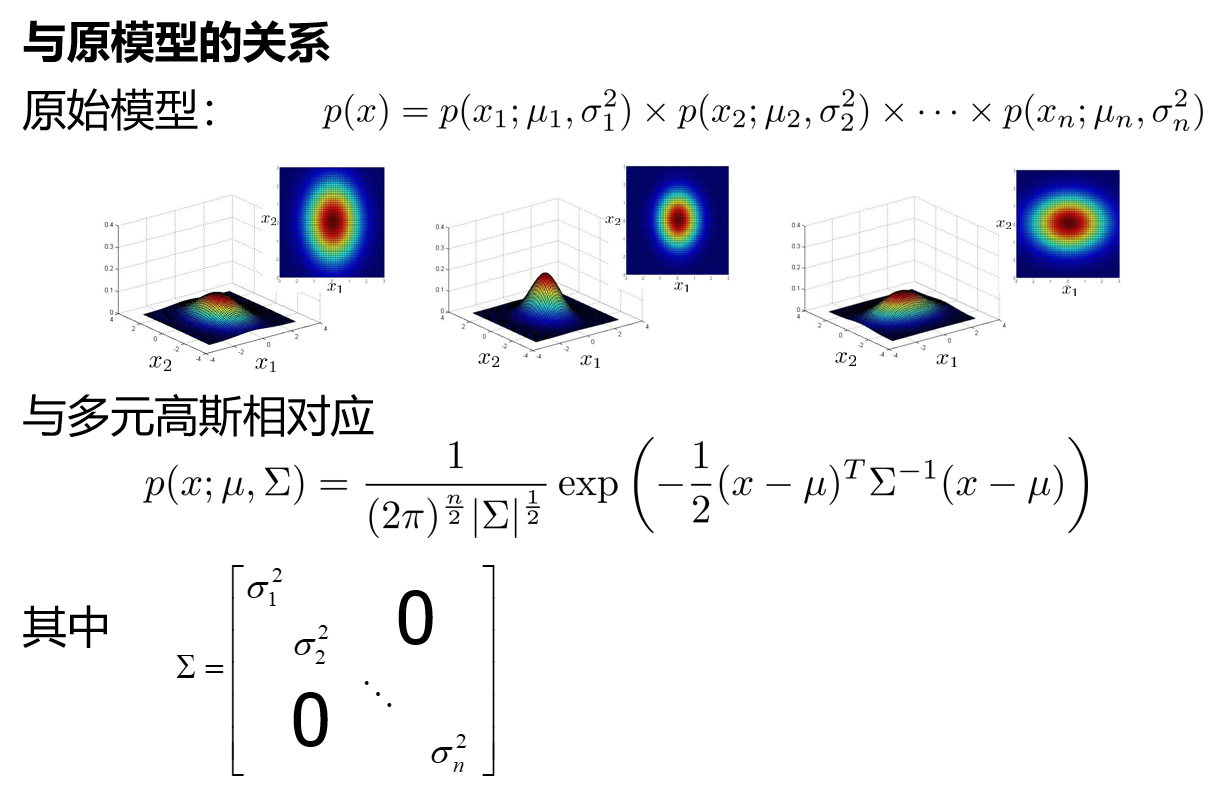
原始模型:
手动创建特征,捕捉异常值组合
计算成本更低(或者说,规模n越大计算成本越低)
即使m(训练集大小)很小也没关系
多变量高斯:
自动捕捉特征之间的相关性
计算成本更高
必须有m>n,否则![]() 不可逆转
不可逆转
9、推荐系统的协同过滤
协同过滤推荐系统
协同过滤:根据用户-物品的打分矩阵,计算物品的相似度或者用户的相似度,基于相似物品和相似用户做推荐。这种推荐,是基于向量空间的计算,而非对内容的分析。
协同过滤推荐系统思路如下:
(1)从每个用户对商品的评级信息中构建用户档案;
(2)使用如余弦相似度、皮尔森相关系数或距离函数来识别和目标用户具有相似意向的用户,他们对商品有相似的评级;
(3)对来自具有相似意向用户的偏好评级取均值、加权和或调整后的加权和,推荐n个商品。
代价函数cost function
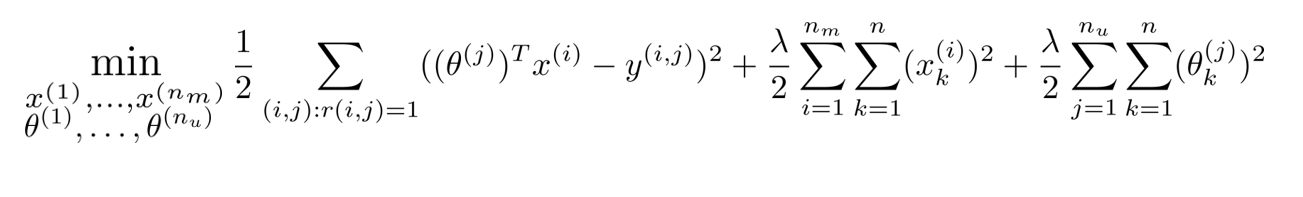




协同过滤算法


中文:
同时学习参数以及特征,下面我们来讨论一下协同过滤算法的构建过程

基于内容过滤推荐系统
基于内容的过滤:本质是对内容进行分析,建立特征;基于用户对什么特征的内容感兴趣、以及分析一个内容具备什么特征,来做推荐。
基于内容过滤推荐系统思路如下:
(1)通过在抓取每个商品的一系列特征来构建商品档案;
(2)通过用户购买的商品特征来构建基于内容的用户档案;
(3)通过特定的相似度方程计算用户档案和商品档案的相似度;
(4)推荐相似度最高的n个商品。所以,这种推荐基于与已购买商品的相似度来进行推荐。
协同过滤中的冷启动问题(新用户未进行过评分时系统无法进行推荐的问题)
冷启动问题又称第一评价问题(first- rater),或新物品问题(New-item),从一定角度可以看成是稀疏问题的极端情况。因为传统的协同过滤推荐是基于相似用户/物品计算来得到目标用户的推荐,在一个新的项目首次出现的时候,因为没有用户对它作过评价,因此单纯的协同过滤无法对其进行预测评分和推荐。而且,由于新项目出现早期,用户评价较少,推荐的准确性也比较差。相似的,推荐系统对于新用户的推荐效果也很差。冷启动问题的极端的案例是:当一个协同过滤推荐系统刚开始运行的时候,每个用户在每个项目上都面临冷启动问题。
在协同过滤时,冷启动问题怎么处理?
1.提供非个性化的推荐:热门排行榜,当用户数据收集到一定的时候,再切换为个性化推荐。
2.利用用户注册时提供的年龄、性别等数据做粗粒度的个性化。
3.利用用户的社交网络帐号登录,导入用户在社交网站上的好友信息,然后给用户推荐其好友喜欢的物品。
4.要求用户在登录时对一些物品进行反馈,收集用户对这些物品的兴趣信息,然后给用户推荐那些和这些物品相似的物品。
5.对于新加入的物品,可以利用内容信息,将它们推荐给喜欢过和它们相似的物品的用户。
6.在系统冷启动时,可以引入专家的知识,通过一定的高效方式迅速建立起物品的相关度表。
10、在二分类的基础上实现多分类
一对多法(one-versus-rest,简称OVR SVMs)
训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为具有最大分类函数值的那类。
假如我有四类要划分(也就是4个Label),他们是A、B、C、D。
于是我在抽取训练集的时候,分别抽取
(1)A所对应的向量作为正集,B,C,D所对应的向量作为负集;
(2)B所对应的向量作为正集,A,C,D所对应的向量作为负集;
(3)C所对应的向量作为正集,A,B,D所对应的向量作为负集;
(4)D所对应的向量作为正集,A,B,C所对应的向量作为负集;
使用这四个训练集分别进行训练,然后的得到四个训练结果文件。
在测试的时候,把对应的测试向量分别利用这四个训练结果文件进行测试。
最后每个测试都有一个结果f1(x),f2(x),f3(x),f4(x)。
于是最终的结果便是这四个值中最大的一个作为分类结果。
评价:
这种方法有种缺陷,因为训练集是1:M,这种情况下存在biased.因而不是很实用。可以在抽取数据集的时候,从完整的负集中再抽取三分之一作为训练负集。
一对一的投票策略(可能会考)
将A、 B、C、 D四类样本两类两类地组成训练集, 即(A,B)、(A.C)、(A,D)、(B,C)、(B,D)、(C,D), 得到6个(对于n类问题,为n(n-1)/2个)SVM二分器。在测试的时候,把测试样本又依次送入这6个二分类器, 采取投票形式, 最后得到一组结果。投票是以如下方式进行的。
- 初始化:vote(A)= vote(B)= vote(C)= vote(D)=0。
- 投票过程:如果使用训练集(A,B)得到的分类器将一个测试样本判定为A类,则vote(A)=vote(A)+1 ,否则vote(B)=vote(B)+ 1;如果使用(A,C)训练的分类器将又判定为A类,则vote(A)=vote(A)+1, 否则-vote(C)=vote(C)+1; ... ;如果使用(C,D)训练的分类器将又判定为C类,则vote(C)=vote(C)+ 1 , 否则vote(D)=vote(D)+ 1。
- 最终判决:Max(vote(A), vote(B), vote(C), vote(D))。如有两个以上的最大值,则一般可简单地取第一个最大值所对应的类别。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号