

寒假作业 2/2
| 这个作业属于哪个课程 | 2021春软件工程实践|W班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | <阅读《构建之法》并提问、完成词频统计个人作业> |
| 作业正文 | 寒假作业 2/2 |
| 其他参考文献 | 简书/博客园/CSDN/GitHub |
任务一:阅读《构建之法》并提问
一、基本要求
快速看完整部教材(教材开学会发,可以先看邹欣老师的博客园讲义),列出你仍然不懂的5到10个问题,发布
在你的个人博客上。如何提出有价值的问题? 请看这个文章,以及在互联网时代如何提问题。 还有这些要点:
在每个问题后面,请说明哪一章节的什么内容引起了你的提问,提供一些上下文。
列出一些事例或资料,支持你的提问。
说说你提问题的原因,你说因为自己的假设和书中的不同而提问,还是不懂书中的术语,还是对推理过程有疑问,
还是书中的描述和你的经验(直接经验或间接经验)矛盾?
问题一:(如何避免过早地优化)
P53写到:
过早优化:一个工程师在写程序的时候,经常容易在某一个局部问题上陷进去,花大量时间对其进行优化;无视这个模块对全局的重要性,甚至还不知道这个“全局”是怎么样的。这个毛病早就被归纳为“过早的优化是一切罪恶的根源”。
在网上搜索资料后得到一段话:
优化之前先问三个问题:
优化后代码量会减少吗?
优化的是系统瓶颈吗?
优化方案中,是否增加了隐藏条件和系统限制?
在这次的实际编码中,我也出现了这种过早优化的情况。当我在编写统计字符的时候,我发现我的读入文件非常缓慢,于是我去修改了IO流,然后IO流中的读入方法因为正确性又修改了一次,导致统计字符的功能的完成被拖后了很多。我认为在之后的优化过程中,先问自己这三个问题能够避免一部分的过早优化。
问题二:(代码量与成长的关系)
我在P65页的讨论中关注到代码量与成长的关系。
我有所疑问的是,倘若在项目上遇到自己不会学的已封装好的库,例如在sk-learn库中早已封装好各类机器学习的库,自然语言的NLTK库,但只会调用库无法提高自己对于知识方面的进一步了解。
当去彻底的了解源代码耗费的时间与得到的收获并不成正比,如何平衡这一方面的矛盾呢?
问题三:(结对编程)
P85写到:
在结对编程模式下,一对程序员肩并肩、平等地、互补地进行开发工作。他们并排坐在一台电脑前,面对同一个显示器,使用同一个键盘、同一个鼠标一起工作。他们一起分析,一起设计,一起写测试用例,一起编码,一起做单元测试,一起做集成测试,一起写文档,等等。
结对编程的好处书中已经详细描述了,那结对编程的不足之处呢?结对编程在现实生活中国内的公司似乎很少采用,是有什么局限吗?
我发现知乎有一个相似的提问:国内为何很少有人做结对编程呢?是确实不好还是属于中国特色
阅读了他们的回答以后,我总结了一些看法:
1、一些内向的程序员不太喜欢在编程中与他人频繁交流
2、管理者怀疑结对编程的产出比不上两个人以传统方式进行开发
3、有些工作不适合结对,结对的人有明显的思维趋同性,可能范一样的错误
而到目前为止,我对结对编程的感受是互相沟通一起完成工作确实会比单干少犯错、进度快,但是也要取决于工程的大小,若是较小的工程,结对编程的沟通成本可能会较高。
问题四:(典型用户)
P218提到:
定义了最初的典型用户之后,是不是就可以开始写程序了?不,典型用户只是我们的设想,这些都是纸上谈兵,我们还要和这些典型用户的代表交流,理解用户,理解他们的工作方式和需要。然后再修改,细化典型用户。于是,移山公司的员工和实习生花了几天时间,做了不少用户调查,搞了不少头脑风暴,画了无数草图。
小李:(回来报告)除了进一步了解用户的需求,细化了一些功能的设想外,我们还有一个重大发现,我们的第一个典型用户,吴石头,好像不喜欢上网,他事实上不太会用电脑,也搞不懂如何上传照片。凡是和网络相关的事情,都交给了他的儿子。所以我们不得不把吴石头从典型用户中删除。
经过查阅资料得知,典型用户是指,按不同维度来区分用户的过程中,在每个维度中能代表目标用户的那类群体。比如,按人数多少来划分的,能代表最多用户特征的群体;按盈利来划分,能代表带来最多盈利价值特征的群体。
但是典型用户的定义和删除让我觉得非常奇怪,典型用户在何种情况下需要进行删除呢?
问题五:(创新者与先行者)
P351写到:
大家听了很多创新者的故事,有些人想,他们真了不起,第一个想出了这些美妙的想法,要是我早生几十年,也第一个实现那些想法就好了。其实,大部分成功的创新者都不是先行者,例如搜索引擎,Google是很晚才进入这个领域的。又如 Apple的音乐播放器iPod,发布于2001年10月23日,在它之前市面上已经有很多同类产品了.
论及市场竞争时,人们喜欢用下面这样一些词汇:。
先行者( First Mover )、先发优势(First Mover Advantage,FMA )·
后起者( Second Mover ),后发优势( Second Mover Advantage,SMA)
我在网上查到sma的定义:
后动优势(late-mover advantage;Second-mover advantage;又称为次动优势、后发优势、先动劣势)是指相对于行业的先进入企业,后进入者由于较晚进入行业而获得的较先动企业不具有的竞争优势,通过观察先动者的行动及效果来减少自身面临的不确定性而采取相应行动,获得更多的市场份额。
搜索到sma定义后,我想一些成功的后发者凭借的并不仅仅是后发优势,如微信打败米聊更多的是因为QQ庞大的用户基数可以使微信迅速发展用户流量罢了,同样ie超过mosaic更多的应该是商业策略的原因.
二、附加题
大家知道了软件和软件工程的起源,请问软件工程发展的过程中有什么你觉得有趣的冷知识和故事?
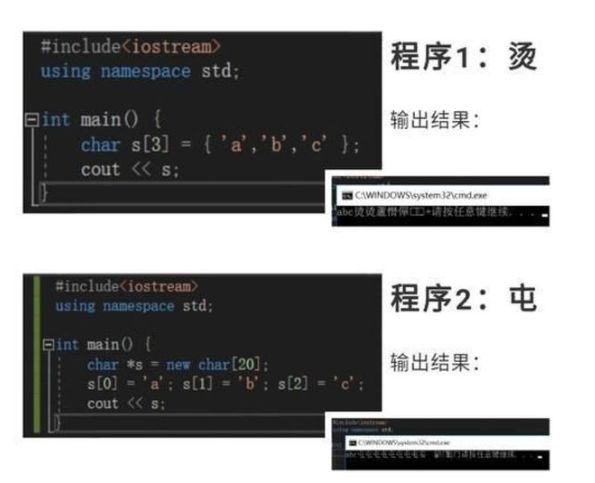
VS输出“烫烫烫”、“屯屯屯”的缘由
相信很多码友在用Visual Studio写程序时都碰到过这种情况:程序编译能通过,但是输出一大堆的“烫烫烫”和“屯屯屯”等字符,这是啥子情况?难道是程序占用过多内存导致CPU发疯了吗(笑)?
!!!听起来就不靠谱!
原来,在Visual Studio中的Debug模式下,如果声明一个变量,但是没有初始化,微软会给未初始化的内存复制为0xCC。给为初始化的内存赋0xCC是有原因的,0xCC其实是INT3中断指令,所以如果在Debug模式下试图去执行这块未初始化的内存的话就会中断程序。
但VS中调试器默认的字符集是MBCS,而在MBCS中0xCCCC正好就是中文中的“烫”,所以显示出来就都是烫……
而如果是用分配堆的内存,会初始化成0xCD,0xCDCD在MBCS字符集中就是屯……
所以,如果VS输出这种形如“烫烫烫”、“屯屯屯”的问题,就检查下初始化吧!
相关的有这样一个笑话:
程序员加班回到家,母亲递过一碗刚煮好的饺子,程序员十分感动,接过去就大口吞进一个饺子,突然脸色不对,把饺子吐出来大喊:
#include
using namespace std;
int main()
{
char a[50];
cout << a <<endl;
system("pause");
return 0;
}
就是“烫烫烫”的意思啦hhh…
任务二:WordCount编程
-
GitHub项目地址
-
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 20 | 30 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 150 | 180 |
| • Design Spec | • 生成设计文档 | 20 | 20 |
| • Design Review | • 设计复审 | 20 | 40 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 40 |
| • Design | • 具体设计 | 90 | 100 |
| • Coding | • 具体编码 | 300 | 500 |
| • Code Review | • 代码复审 | 60 | 90 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 90 | 120 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 15 | 30 |
| • Size Measurement | • 计算工作量 | 30 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 100 | 120 |
| 合计 | 915 | 1300 | |
-
解题思路描述
-
前置部分(学习git、GitHub基本操作、复习Java)
-
功能分析
功能描述:
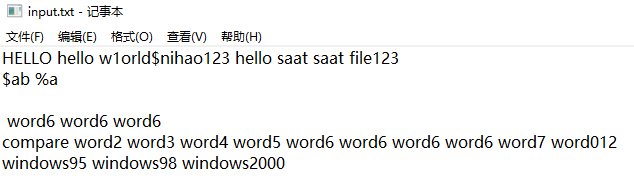
- 统计文件的字符数(对应输出第一行);
- 统计文件的单词总数(对应输出第二行),单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 统计文件的有效行数(对应输出第三行):任何包含非空白字符的行,都需要统计。
- 统计文件中各单词的出现次数(对应输出接下来10行),最终只输出频率最高的10个。
-
解题思路
初步审题思考后,有如下几点思路:
1.需要读取文件。
2.解决单个字符读取并且计数(即可实现统计字符数的功能)
- 根据readLine()函数根据行来读入,再判断是否为空白行后再计数(即可实现统计有效行的功能)
- 将读入的字符拼接,根据分隔符进行分割成单词,再判断是否为一个至少4位字母开头的单词,并统计(即可实现统计单词的功能)
- 在(4)的基础上,将单词存储下来并进行重复判断,最后再对存储下来的词频进行排序输出(即可实现单词频率统计排序的功能)。
-
-
代码规范制定链接
-
设计与实现的过程
-
设计部分
设想由一个单独的Function类来封装并实现题目所要求的的4个功能。其中为了方便对单词和频率的存储设计了一个Word类用来将单词与频率一一对应。在编写代码的过程中为了效率在编写的后期又加入了一个CompareRule类来自定义排序Word类,来实现最后的词频排序功能。WordCount仅用于作为命令行输出的主程序。 下方列出几个类的具体设计
public class Function { public Function(){} public boolean IsEmptyLine(String wordLine){} //用于判断是否是空白行 public int CountChar(File readFile){} //用于计数字符数 public int CountLine(File readFile){} //用于统计有效行 public int CountWord(File readFile){} //用于统计单词数 public Vector<Word> CountFrequentWord(File readFile){} //用于统计词频并排序 public int FindWord(Vector<Word> allWords,String word){} //在统计词频函数中查找单词是否已经存在 } public class Word { private String words; //用于存储单词 private int frequent; //用于存储频率 public Word(String word,int fre){} //用于初始化Word对象 public String GetWords(){} //用于得到单词的内容 public int GetFrequent(){} //用于得到频率 public void AddFrequent(){} //用于频率的增加 } public class CompareRule implements Comparator<Word> { public int compare(Word aWord,Word bWord){} //该方法用于编写自定义的对Word类的排序 }
-
-
实现部分
- 在IO中选择FileInputStream和BufferedReader,通过单个字符的读取来实现功能。
- 在存储单词时选择容器Vector,并且使用Collections.sort()方法来对频率排序。
-
具体实现
- 使用正则表达式判断空白行,排除掉空白符后如果是空则为空行。(流程图和代码如下)
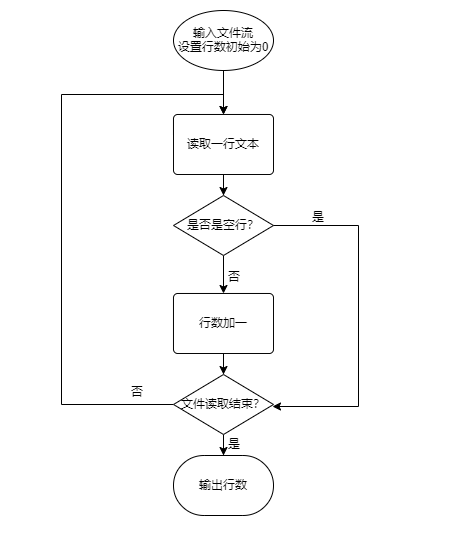
public boolean IsEmptyLine(String wordLine) { if(wordLine.replaceAll("\\s*", "").equals("")) //替换掉输入行的空格、制表、换页符后是否为空 { return true; } else { return false; } }- 计算字符时,每读取一个字符,这字符数增加一,这样即使是\r\n的情况也能够正确统计出结果
FileInputStream fileIn = new FileInputStream(readFile); int readChar =0; while((readChar = fileIn.read())!=-1) //每读入一个字符,字符数自增1 { charNum++; } 3. 统计单词数时候,同样采取单个字符读取,对字母和数字进入判断分支,拼接成单词,如果不是字母或者数字则认定为是分隔符,便进行单词判断,如果是属于长度>4且头四个字符为字母的即为单词。流程图和代码如下:
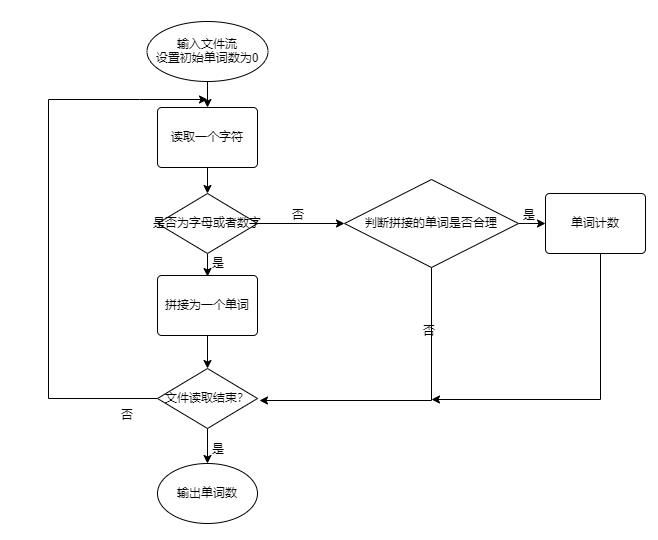
if((readChar>='a'&&readChar<='z') ||(readChar>='A'&&readChar<='Z') ||(readChar>='0'&&readChar<='9')) //如果不是 { if(readChar>='0'&&readChar<='9') { if(wordLength>=4) { char[] ch = new char[1]; ch[0] = (char)readChar; word += ch[0]; //拼接单词 wordLength++; } else { isNotWord = 1; //如果读入是数字且此时长度没有超过4则判断不属于单词 } } else { char[] ch = new char[1]; ch[0] = (char)readChar; word += ch[0]; //读入字符为字母,直接拼接 wordLength++; } }- 此功能中仍然适用(3)中的单词读取,并利用Vector来存储单词,封装了FindWord()函数来判断是否已经存在,最后读入所有单词后,利用自定义的sort来快排,利用重写排序规则可以做到先根据词频排序,在相等的情况下根据字典序来排。
public class CompareRule implements Comparator<Word> { public int compare(Word aWord,Word bWord) { if(aWord.GetFrequent() > bWord.GetFrequent()) //频率大的在前 { return -1; } else if(aWord.GetFrequent() == bWord.GetFrequent()) { if(aWord.GetWords().compareTo(bWord.GetWords()) < 0) //同频率时,字典序小的在前 { return -1; } else { return 0; } } else { return 1; } } }
-
性能改进
- 在对频率最大的十个数排序时,一开始是利用自己写的冒泡排序一个个对比,代码量又长,运行又不迅速。后改进为利用自定义Collections类的sort来快排,代码量减少而且速度更快。
- 读取行的时候,选用BufferedReader,不同于读取单词与字符时选用的FileInputStream
性能截图如下:
- 单元测试截图的用例,百个字符级别运行时间(5ms):

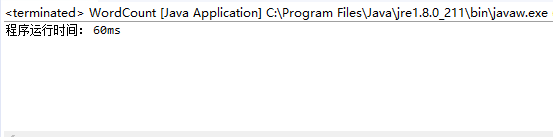
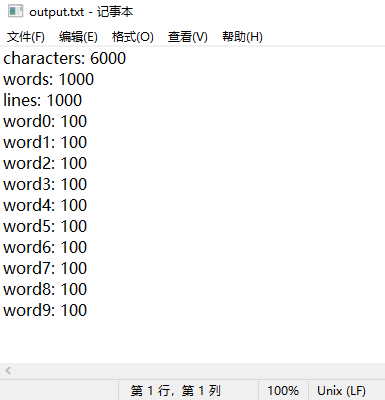
- 6000个字符级别的用例测试(1000行,1000个单词,所花时间60ms):

- 60万个字符级别的用例(10万行,10万个单词,所花时间为3.6S):


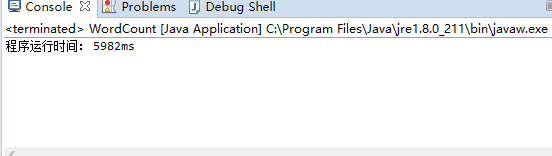
- 1百万个字符级别的用例(10万行,10万个单词,所花时间为5.982S):
单元测试
使用JUnit4对封装好后的4个模块的功能进行测试。以下是覆盖率最高的测试用例以及覆盖率和源程序输出结果的截图:
构造思路:如该用例,尽量设计每一个分支,将每种在编写过程中考虑的情况都写入用例中。该用例涉及了大小写转换、空白行的判断、长度不够4的词的判断、以及前四个字符中含有数字的单词的判断、以及字典序的排序判断,以及最后一个单词后面无分隔符。所以对Funciton函数里面的方法都覆盖到了(因为是单元测试所以只对模块进行测试,main函数就没有涉及)。
优化覆盖率:多考虑标红的没有覆盖到的代码,思考用例为什么没有覆盖,再将特例添加到用例中,逐步优化覆盖率。
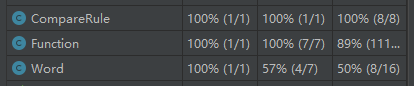

对Function和Word类代码函数没有百分百覆盖的原因分析:
通过对单元测试过的代码标红的部分进行查看,Funcion类中没覆盖到的地方基本上都是异常捕获,唯有一个分支是对如果最后一次读取的单词后无分隔符的时候判断是否重复(所以只能进入其中一个分支,重复或是新词)。
Word类的没有全覆盖是由于,我在设计类时为了类的完整性,添加了对私有变量设值的方法,在这次代码中没有用到。
测试函数利用传入文件路径并测试4个主要模块的函数。
以下是用于单元测试的代码:
public class FunctionAllTest {
@Test
public void countChar() {
File file = new File("input.txt");
int count = 186;
Function f=new Function();
assertEquals(count,f.CountChar(file));
}
@Test
public void countLine() {
File file = new File("input.txt");
int count = 5;
Function f=new Function();
assertEquals(count,f.CountLine(file));
}
@Test
public void countWord() {
File file = new File("input.txt");
int count = 24;
Function f=new Function();
assertEquals(count,f.CountWord(file));
}
@Test
public void countFrequentWord() {
File file = new File("input.txt");
Function f=new Function();
f.CountFrequentWord(file);
}
}
异常处理说明
本次作业设计的异常处理在对文件打开时的处理,如果找不到文件以及文件名出错时抛出异常,代码如下:
try
{
}
catch(Exception e)
{
System.out.println("未找到文件");
e.printStackTrace();
}
心路历程与收获
这次实践作业相比上一次作业,坎坷了许多,由于最近看了很多机器学习算法,接触了比较多的python,所以开始选用的是python语言,但由于没有系统学过python,很多细节语法会出现问题(也正如开课时,看到17级学长给我们的建议:一定要打好基础,不然可能80%的时间是在学,只有20%的时间在敲代码( ╯□╰ )...),所以后来还是改用了Java来编写这次作业,在编写代码的过程中,也对Java进行了复习,是一个愉快的过程。
在这次作业之前,也仅仅在GitHub上下载些机器学习算法用于理解学习和应用,但从未在GitHub上传过项目文件。而在做本次作业时,发现每次都可以用commit保存我的代码进度,以便于代码的保存和迭代更新,虽还未参与过团队开发,但也了解到GitHub的奇妙之处,也更好理解为什么世界各地的程序员热衷于在这个平台上传自己的代码。学会GitHub的使用也是本次作业的一个不小的收获。
在完成对项目的fork之后,对作业要求进一步的去学习了解,在看到单元测试时,心中产生了恐惧,因为之前一直都没有接触过,也是在《构建之法》的阅读中才有所了解。不过好在,万事开头难,动手开始编写代码时也顾不得去恐惧了,跟打怪一样,项目功能的一步步实现就像是攻克了一个个大小boss,完成实现后还是很有成就感的。
编写过程中遇到了许多不解,有的是因为语法基础,有的是由于刚开始审题时没有读懂就急冲冲的开始写代码,所以在写项目前做好流程图也很重要啊!在最后的测试阶段也学到了如何利用工具来写单元测试。学到了以后动手开始编写代码前一定要把考虑设计的时间增长,对作业要求多读几遍,认真体会需要实现的每个功能和之间的关系,最好画出思维导图或是流程图后再入手,效率会提高很多!
