MIT 6.828 Lab 05:File system, Spawn and Shell
MIT 6.828 Lab5:File system, Spawn and Shell
概括总结
本lab将实现JOS的文件系统,只要包括如下四部分:
- 引入一个文件系统进程(FS进程)的特殊进程,该进程提供文件操作的接口。
- 建立RPC机制,客户端进程向FS进程发送请求,FS进程真正执行文件操作,并将数据返回给客户端进程。
- 更高级的抽象,引入文件描述符。通过文件描述符这一层抽象就可以将控制台,pipe,普通文件,统统按照文件来对待。(文件描述符和pipe实现原理)
- 支持从磁盘加载程序并运行。
File system preliminaries
我们要完成一个相对简单的文件系统,其可以实现创建、读、写以及删除在分层目录结构中组织的文件。目前我们的OS只支持单用户,因此我们的文件系统也不支持UNIX文件拥有或权限的概念。同时也不支持硬链接、符号链接、时间戳或是特别的设备文件。
On-Disk File System Structure
大多是 Unix 文件系统将磁盘空间分为 inode和数据 区域。目录包含文件名和指向inode的指针; 如果文件系统中的多个目录引用该文件的inode,则称文件是硬链接的。由于我们的文件系统不需要支持硬链接,因此我们不需要这一间接层并且能做一个方便的简化:我们的文件系统根本不使用inode,相反我们仅仅将所有文件(或子目录)的 meta-data存储在描述该文件的唯一的目录中(directory entry)。 文件和目录逻辑上都是由一系列数据blocks组成,这些blocks分散在磁盘中,文件系统屏蔽blocks分布的细节,提供一个可以顺序读写文件的接口。
补充:inode
inode其实本质就是操作系统课程学习的“索引结点”。刚开始看到这里其实有点混乱,感觉不知道对应学的哪部分知识(可能是因为上学期学操作系统是中文学的,有些名词对不上)。复习了文件系统的知识之后,恍然发现这就是索引结点!
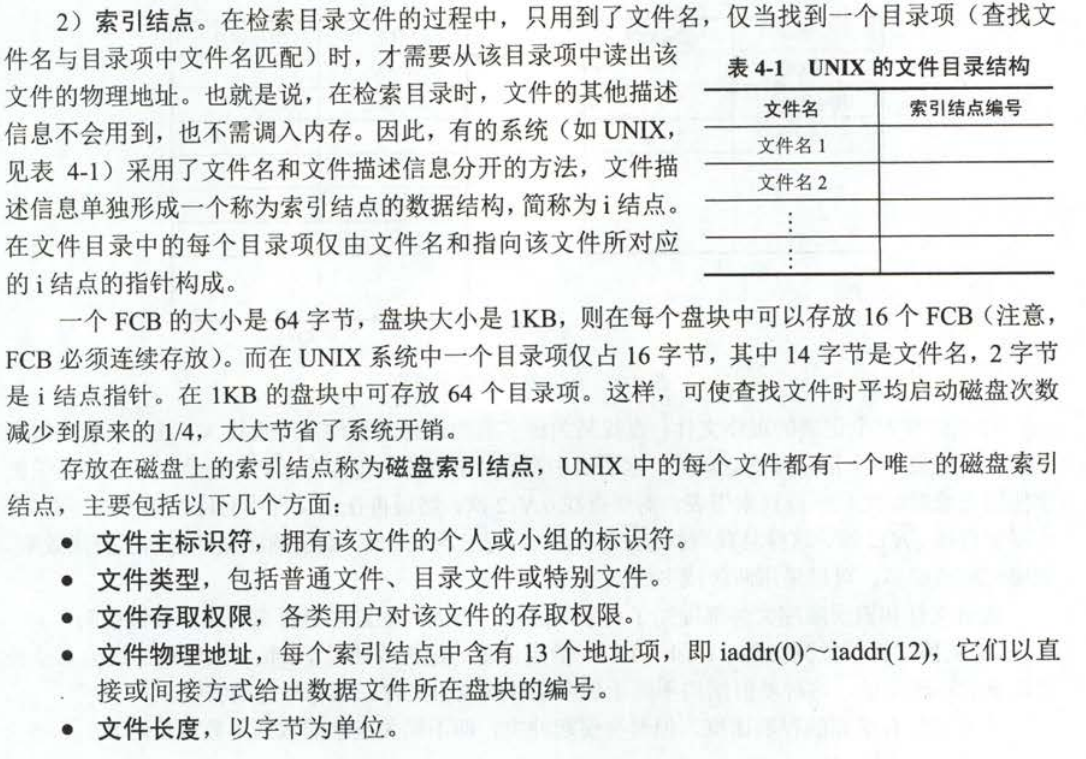
文件存储在硬盘上,硬盘的最小存储单位叫做“扇区”(Sector)。每个扇区储存512字节(相当于0.5KB)。
操作系统读取硬盘的时候,不会一个个扇区的读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个“块”(block)。这种由多个扇区组成的“块”,是文件存取的最小单位。“块”的大小,最常见的是4KB,即连续八个sector组成一个block。
文件数据都储存在“块”中,那么很显然,我们还必须找到一个地方储存文件的“元信息”,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做*inode*,中文译名为"*索引节点*"。
每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。


Sectors and Blocks
大部分磁盘都是以Sector为粒度进行读写,JOS中Sectors为512字节。文件系统以block为单位分配和使用磁盘。注意区别,sector size是磁盘的属性,block size是操作系统使用磁盘的粒度。JOS的文件系统的block size被定为4096字节 ( 4kB ) 。
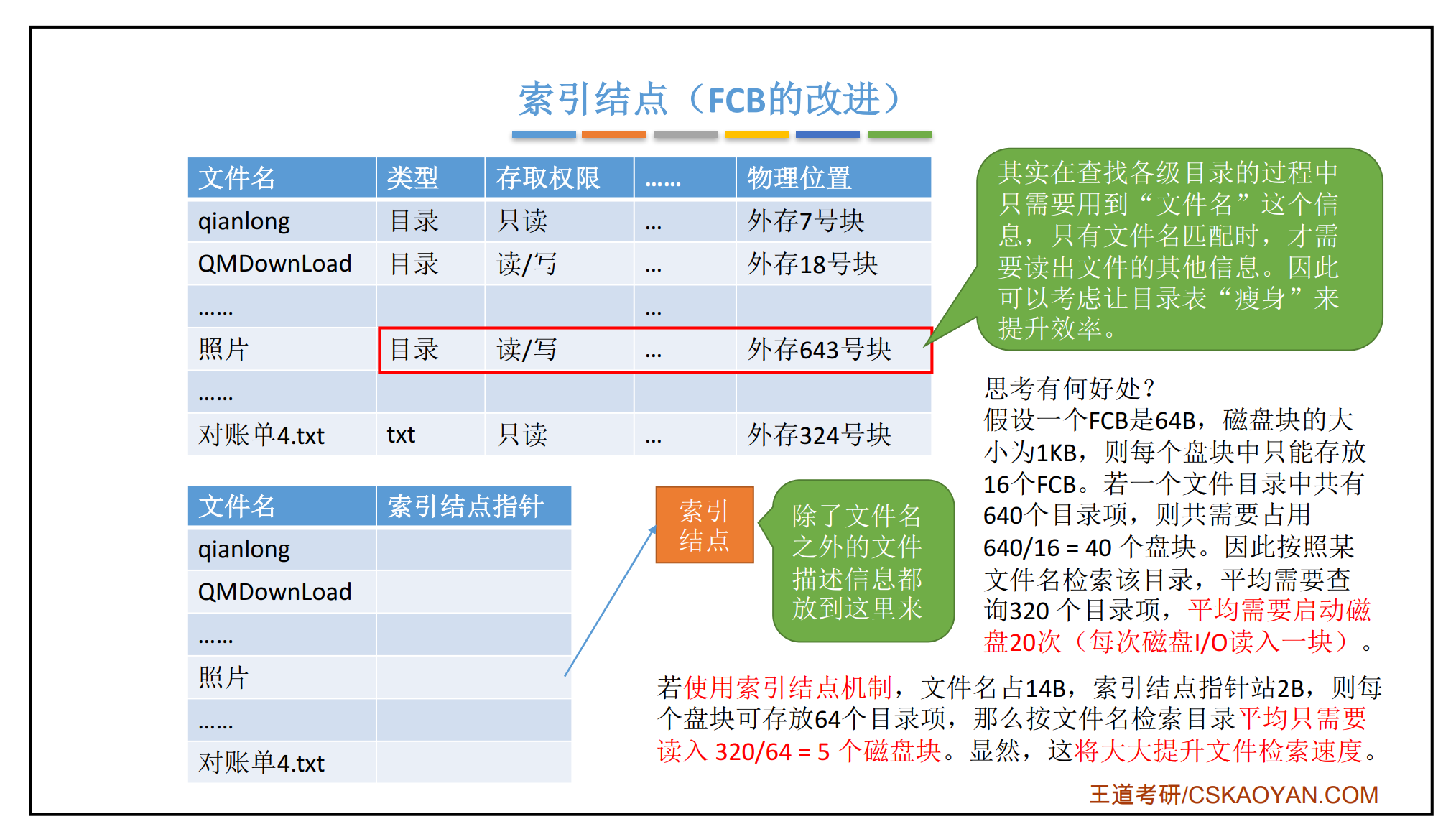
Superblocks
文件系统使用一些特殊的block保存文件系统属性元数据,比如block size, disk size, 根目录位置等。这些特殊的block叫做superblocks。
我们的文件系统使用一个superblock,位于磁盘的block 1。block 0被用来保存boot loader和分区表。
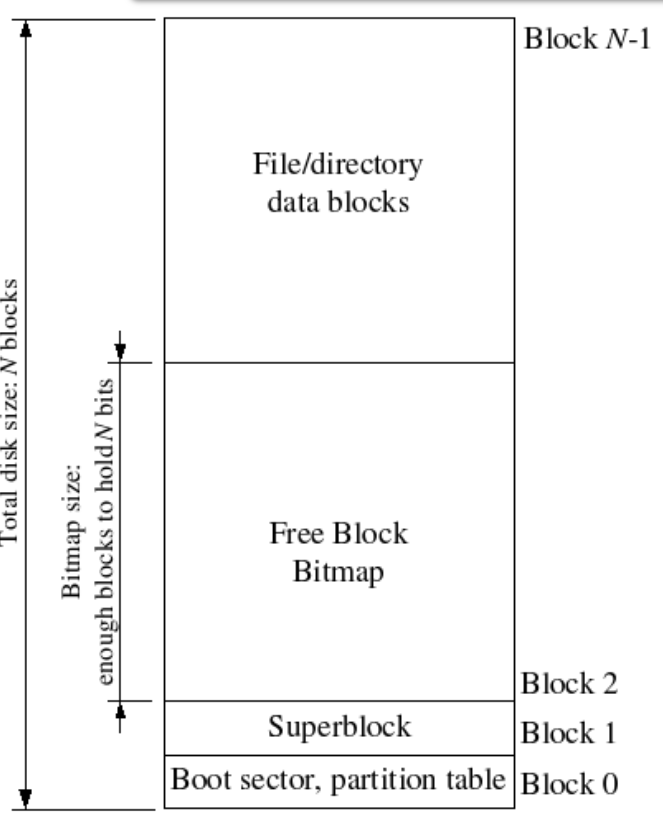
struct Super {
uint32_t s_magic; // Magic number: FS_MAGIC
uint32_t s_nblocks; // Total number of blocks on disk
struct File s_root; // Root directory node
};
File Meta-data
我们的文件系统使用struct File结构描述文件,该结构包含文件名,大小,类型,保存文件内容的block号。struct File结构的f_direct数组保存前NDIRECT(10)个block号,这样对于10*4096=40KB的文件不需要额外的空间来记录内容block号。对于更大的文件我们分配一个额外的block来保存4096/4=1024 block号。
🚩 操作系统课程内容:文件的物理结构——索引分配的混合索引方式 的一级简介索引
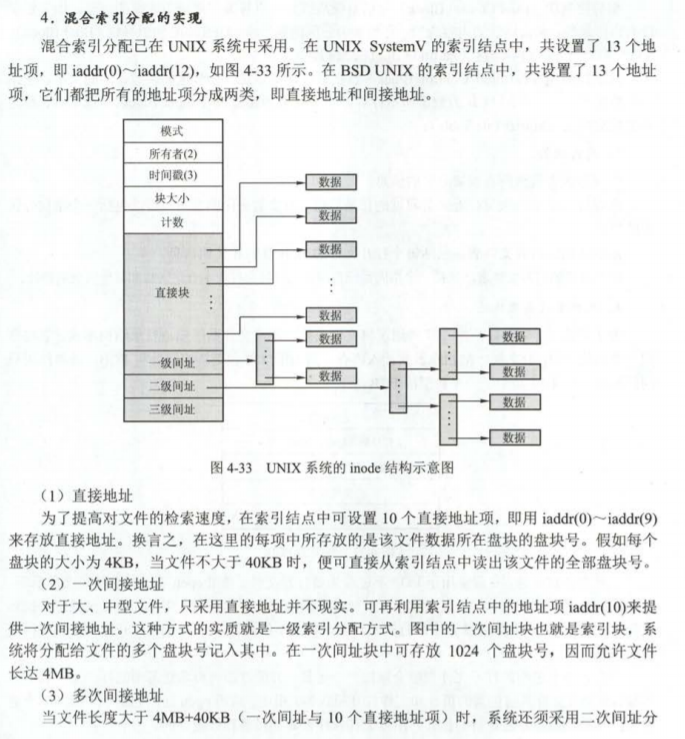
inc/fs.h
struct File {
char f_name[MAXNAMELEN]; // filename
off_t f_size; // file size in bytes
uint32_t f_type; // file type
// Block pointers.
// A block is allocated iff its value is != 0.
uint32_t f_direct[NDIRECT]; // direct blocks
uint32_t f_indirect; // indirect block
// Pad out to 256 bytes; must do arithmetic in case we're compiling
// fsformat on a 64-bit machine.
uint8_t f_pad[256 - MAXNAMELEN - 8 - 4*NDIRECT - 4];
} __attribute__((packed)); // required only on some 64-bit machines
Directories versus Regular Files
File结构既能代表文件也能代表目录,由type字段区分,文件系统以相同的方式管理文件和目录,只是目录文件的内容是一系列File结构,这些File结构描述了在该目录下的文件或者子目录。
超级块中包含一个File结构,代表文件系统的根目录。
The File System
Disk Access
到目前为止内核还没有访问磁盘的能力。JOS不像其他操作系统一样在内核添加磁盘驱动,然后提供系统调用。我们实现一个文件系统进程来作为磁盘驱动。
内核必须在接收设备中断并将它们分派到正确的用户模式环境。
x86处理器使用EFLAGS寄存器的IOPL为来控制保护模式下代码是否能执行设备IO指令,比如in和out。我们希望文件系统进程能访问IO空间,其他进程不能。
Exercise 1
文件系统进程的type为ENV_TYPE_FS,需要修改env_create(),如果type是ENV_TYPE_FS,需要给该进程IO权限。
在env_create()中添加如下代码:
if (type == ENV_TYPE_FS) {
e->env_tf.tf_eflags |= FL_IOPL_MASK;
}
Question
- 你是否不得不做一些其他事来确保当环境不断切换时,I/O特权设定依然能被保存和恢复? 为什么?
不需要,因为在环境切换时,会保存eflags的值,也会用
env_pop_tf恢复eflags的值。
The Block Cache
我们的文件系统最大支持3GB,文件系统进程保留从0x10000000 (DISKMAP)到0xD0000000 (DISKMAP+DISKMAX)固定3GB的内存空间作为磁盘的缓存。比如block 0被映射到虚拟地址0x10000000,block 1被映射到虚拟地址0x10001000以此类推。
由于我们的文件系统有独立于系统中其他环境的虚拟地址空间(不重叠),因为我们的文件系统唯一需要做的事是实现文件的 access。如此看来我们为文件系统保留大量的空间也是十分合理的。
如果将整个磁盘全部读到内存将非常耗时,所以我们将实现按需加载,只有当访问某个block对应的内存地址时出现页错误,才将该block从磁盘加载到对应的内存区域,然后重新执行内存访问指令。
Exercise 2
实现bc_pgfault()和flush_block()。
要注意区分这sector 和 block 两个概念。 JOS 块大小位4kB,扇区大小为512B,每次读写一个块,就需要读写4个扇区。因此,JOS使用了一个宏定义#define BLKSECTS (BLKSIZE / SECTSIZE)来描述两者的关系。
bc_pgfault(struct UTrapframe *utf)
{
void *addr = (void *) utf->utf_fault_va;
uint32_t blockno = ((uint32_t)addr - DISKMAP) / BLKSIZE;
int r;
// Check that the fault was within the block cache region
if (addr < (void*)DISKMAP || addr >= (void*)(DISKMAP + DISKSIZE))
panic("page fault in FS: eip %08x, va %08x, err %04x",
utf->utf_eip, addr, utf->utf_err);
// Sanity check the block number.
if (super && blockno >= super->s_nblocks)
panic("reading non-existent block %08x\n", blockno);
// Allocate a page in the disk map region, read the contents
// of the block from the disk into that page.
// Hint: first round addr to page boundary. fs/ide.c has code to read
// the disk.
//
// LAB 5: you code here:
addr = ROUNDDOWN(addr, PGSIZE);
sys_page_alloc(0, addr, PTE_W|PTE_U|PTE_P);
if ((r = ide_read(blockno * BLKSECTS, addr, BLKSECTS)) < 0)
panic("ide_read: %e", r);
// Clear the dirty bit for the disk block page since we just read the
// block from disk
if ((r = sys_page_map(0, addr, 0, addr, uvpt[PGNUM(addr)] & PTE_SYSCALL)) < 0)
panic("in bc_pgfault, sys_page_map: %e", r);
// Check that the block we read was allocated. (exercise for
// the reader: why do we do this *after* reading the block
// in?)
if (bitmap && block_is_free(blockno))
panic("reading free block %08x\n", blockno);
}
flush_block()将一个block写入磁盘。flush_block()不需要做任何操作,如果block没有在内存或者block没有被写过。可以通过PTE的PTE_D位判断该block有没有被写过。
void
flush_block(void *addr)
{
uint32_t blockno = ((uint32_t)addr - DISKMAP) / BLKSIZE;
int r;
if (addr < (void*)DISKMAP || addr >= (void*)(DISKMAP + DISKSIZE))
panic("flush_block of bad va %08x", addr);
// LAB 5: Your code here.
addr = ROUNDDOWN(addr, PGSIZE);
if (!va_is_mapped(addr) || !va_is_dirty(addr)) { //如果addr还没有映射过或者该页载入到内存后还没有被写过,不用做任何事
return;
}
if ((r = ide_write(blockno * BLKSECTS, addr, BLKSECTS)) < 0) { //写回到磁盘
panic("in flush_block, ide_write(): %e", r);
}
if ((r = sys_page_map(0, addr, 0, addr, uvpt[PGNUM(addr)] & PTE_SYSCALL)) < 0) //清空PTE_D位
panic("in bc_pgfault, sys_page_map: %e", r);
}
练习2做完后疯狂报错
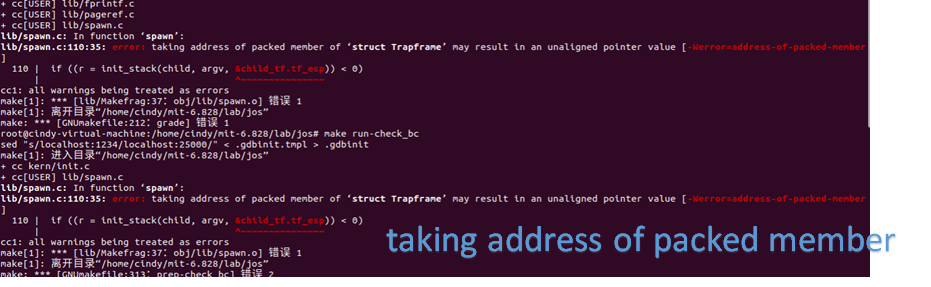
查询对应代码发现:
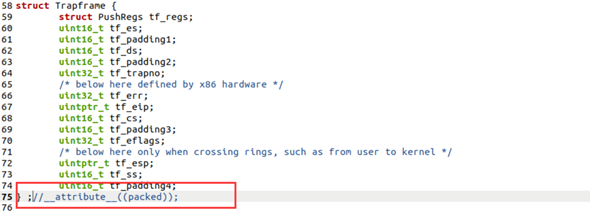
然后查到这里:attribute((packed))的作用:告诉编译器取消结构在编译过程中的优化对齐,按照实际占用字节数进行对齐,是GCC特有的语法。
所以斗胆将这里注释了!没想到居然对了!后面还遇到过这个问题,在struct file处,源码直接由注释(required only on some 64-bits machine 嗐!对了对了!咱这是32-bit的)
练习2 做完之后的截图:通过当前要求的所有测试)
The Block Bitmap
bitmap = diskaddr(2);,位图存放在 2 号块中。操作系统课程一般都会提到这个概念,位图概念也挺好理解的。每一个bit 标记一个 block 是否 free。但这里如果为使用状态标记为0.
例如:若标记第35个块(块号为34)为使用状态, 则将bitmap[1] 的第 2 (34%32)位标记为 0。
Exercise 3
实现fs/fs.c中的alloc_block(),该函数搜索bitmap位图,返回一个未使用的block,并将其标记为已使用。
alloc_block(void)
{
// The bitmap consists of one or more blocks. A single bitmap block
// contains the in-use bits for BLKBITSIZE blocks. There are
// super->s_nblocks blocks in the disk altogether.
// LAB 5: Your code here.
uint32_t bmpblock_start = 2;
for (uint32_t blockno = 0; blockno < super->s_nblocks; blockno++) {
if (block_is_free(blockno)) { //搜索free的block,free为1
bitmap[blockno / 32] &= ~(1 << (blockno % 32)); //标记为已使用
flush_block(diskaddr(bmpblock_start + (blockno / 32) / NINDIRECT)); //将刚刚修改的bitmap block写到磁盘中
return blockno;
}
}
return -E_NO_DISK;
}
练习3结束后,完成当前要求的所有测试
File Operations
fs/fs.c文件提供了一系列函数用于管理File结构,扫描和管理目录文件,解析绝对路径。
基本的文件系统操作:
file_block_walk(struct File *f, uint32_t filebno, uint32_t **ppdiskbno, bool alloc):查找f指向文件结构的第filebno个block的存储地址,保存到ppdiskbno中。如果f->f_indirect还没有分配,且alloc为真,那么将分配要给新的block作为该文件的f->f_indirect。类比页表管理的pgdir_walk()。file_get_block(struct File *f, uint32_t filebno, char **blk):该函数查找文件第filebno个block对应的虚拟地址addr,将其保存到blk地址处。walk_path(const char *path, struct File **pdir, struct File **pf, char *lastelem):解析路径path,填充pdir和pf地址处的File结构。比如/aa/bb/cc.c那么pdir指向代表bb目录的File结构,pf指向代表cc.c文件的File结构。又比如/aa/bb/cc.c,但是cc.c此时还不存在,那么pdir依旧指向代表bb目录的File结构,但是pf地址处应该为0,lastelem指向的字符串应该是cc.c。dir_lookup(struct File *dir, const char *name, struct File **file):该函数查找dir指向的文件内容,寻找File.name为name的File结构,并保存到file地址处。dir_alloc_file(struct File *dir, struct File **file):在dir目录文件的内容中寻找一个未被使用的File结构,将其地址保存到file的地址处。
文件操作:
file_create(const char *path, struct File **pf):创建path,如果创建成功pf指向新创建的File指针。file_open(const char *path, struct File **pf):寻找path对应的File结构地址,保存到pf地址处。file_read(struct File *f, void *buf, size_t count, off_t offset):从文件f中的offset字节处读取count字节到buf处。file_write(struct File *f, const void *buf, size_t count, off_t offset):将buf处的count字节写到文件f的offset开始的位置。
Exercise 4
实现file_block_walk()和file_get_block()。
file_block_walk():
- file_block_walk 获得文件第
filebno块的地址(其本身是个指针),编写需要注意以下几点。具体实现,看代码就好啦。
ppdiskbno是块指针(记录块的地址)f_indirect直接记录块号,而不是记地址。- Don't forget to clear any block you allocate. 对分配的块进行清零操作后,要写入 disk 中。
static int
file_block_walk(struct File *f, uint32_t filebno, uint32_t **ppdiskbno, bool alloc)
{
// LAB 5: Your code here.
int bn;
uint32_t *indirects;
if (filebno >= NDIRECT + NINDIRECT)
return -E_INVAL;
if (filebno < NDIRECT) {
*ppdiskbno = &(f->f_direct[filebno]);
} else {
if (f->f_indirect) {
indirects = diskaddr(f->f_indirect);
*ppdiskbno = &(indirects[filebno - NDIRECT]);
} else {
if (!alloc)
return -E_NOT_FOUND;
if ((bn = alloc_block()) < 0)
return bn;
f->f_indirect = bn;
flush_block(diskaddr(bn));
indirects = diskaddr(bn);
*ppdiskbno = &(indirects[filebno - NDIRECT]);
}
}
return 0;
}
file_get_block():
int
file_get_block(struct File *f, uint32_t filebno, char **blk)
{
// LAB 5: Your code here.
int r;
uint32_t *pdiskbno;
if ((r = file_block_walk(f, filebno, &pdiskbno, true)) < 0) {
return r;
}
int bn;
if (*pdiskbno == 0) { //此时*pdiskbno保存着文件f第filebno块block的索引
if ((bn = alloc_block()) < 0) {
return bn;
}
*pdiskbno = bn;
flush_block(diskaddr(bn));
}
*blk = diskaddr(*pdiskbno);
return 0;
}
练习4做完后疯狂报错✖2
和之前练习2的错误相同,还是把packed标识注释掉

debug后可以运行make grade
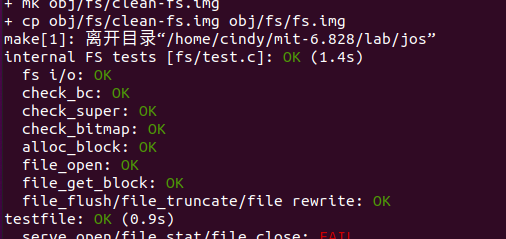
The file system interface
到目前为止,文件系统进程已经能提供各种操作文件的功能了,但是其他用户进程不能直接调用这些函数。我们通过进程间函数调用(RPC)对其它进程提供文件系统服务。RPC机制原理如下:
- RPC(Remote Procedure Call )
Regular env FS env
+---------------+ +---------------+
| read | | file_read |
| (lib/fd.c) | | (fs/fs.c) |
...|.......|.......|...|.......^.......|...............
| v | | | | RPC mechanism
| devfile_read | | serve_read |
| (lib/file.c) | | (fs/serv.c) |
| | | | ^ |
| v | | | |
| fsipc | | serve |
| (lib/file.c) | | (fs/serv.c) |
| | | | ^ |
| v | | | |
| ipc_send | | ipc_recv |
| | | | ^ |
+-------|-------+ +-------|-------+
| |
+-------------------+
本质上RPC还是借助IPC机制实现的。
在开始时,read只需调度到适当的设备读取函数,就可以适用于任何文件描述符,在本例中为devfile_read(我们可以有更多的设备类型,如管道)。 devfile_read专门为磁盘文件实现读取。 这个和lib / file.c中的其他devfile_ *函数实现了FS操作的客户端,并且所有工作都以大致相同的方式工作,在请求结构体中捆绑参数,调用fsipc发送IPC请求,以及解包和返回 结果。 fsipc函数只处理向服务器发送请求和接收回复的常见细节。
fsipc联合体
通过前面的讲解,我们知道结构体(Struct)是一种构造类型或复杂类型,它可以包含多个类型不同的成员。在C语言中,还有另外一种和结构体非常类似的语法,叫做共用体(Union),它的定义格式为:
union 共用体名{
成员列表
};
共用体有时也被称为联合或者联合体,这也是 Union 这个单词的本意。
结构体和共用体的区别在于:结构体的各个成员会占用不同的内存,互相之间没有影响;而共用体的所有成员占用同一段内存,修改一个成员会影响其余所有成员。
结构体占用的内存大于等于所有成员占用的内存的总和(成员之间可能会存在缝隙),共用体占用的内存等于最长的成员占用的内存。共用体使用了内存覆盖技术,同一时刻只能保存一个成员的值,如果对新的成员赋值,就会把原来成员的值覆盖掉。
Exercise 5
Fsipc 联合体很有意思:
union Fsipc {
struct Fsreq_open {
char req_path[MAXPATHLEN];
int req_omode;
} open;
struct Fsreq_set_size {
int req_fileid;
off_t req_size;
} set_size;
struct Fsreq_read {
int req_fileid;
size_t req_n;
} read;
struct Fsret_read {
char ret_buf[PGSIZE];
} readRet;
struct Fsreq_write {
int req_fileid;
size_t req_n;
char req_buf[PGSIZE - (sizeof(int) + sizeof(size_t))];
} write;
struct Fsreq_stat {
int req_fileid;
} stat;
struct Fsret_stat {
char ret_name[MAXNAMELEN];
off_t ret_size;
int ret_isdir;
} statRet;
struct Fsreq_flush {
int req_fileid;
} flush;
struct Fsreq_remove {
char req_path[MAXPATHLEN];
} remove;
// Ensure Fsipc is one page
char _pad[PGSIZE];
};
OpenFile结构是服务端进程维护的一个映射,它将一个真实文件struct File和用户客户端打开的文件描述符struct Fd对应到一起。
struct OpenFile {
uint32_t o_fileid; // file id
struct File *o_file; // mapped descriptor for open file
int o_mode; // open mode
struct Fd *o_fd; // Fd page
};
struct Fd {
int fd_dev_id;
off_t fd_offset;
int fd_omode;
union {
// File server files
struct FdFile fd_file;
};
};
实现fs/serv.c中的serve_read()。这是服务端也就是FS进程中的函数。直接调用更底层的fs/fs.c中的函数来实现。
int
serve_read(envid_t envid, union Fsipc *ipc)
{
struct Fsreq_read *req = &ipc->read;
struct Fsret_read *ret = &ipc->readRet;
if (debug)
cprintf("serve_read %08x %08x %08x\n", envid, req->req_fileid, req->req_n);
// Lab 5: Your code here:
struct OpenFile *o;
int r;
r = openfile_lookup(envid, req->req_fileid, &o);
if (r < 0) //通过fileid找到Openfile结构
return r;
if ((r = file_read(o->o_file, ret->ret_buf, req->req_n, o->o_fd->fd_offset)) < 0) //调用fs.c中函数进行真正的读操作
return r;
o->o_fd->fd_offset += r;
return r;
}
练习5 完成后,通过目前需要通过的所有测试:
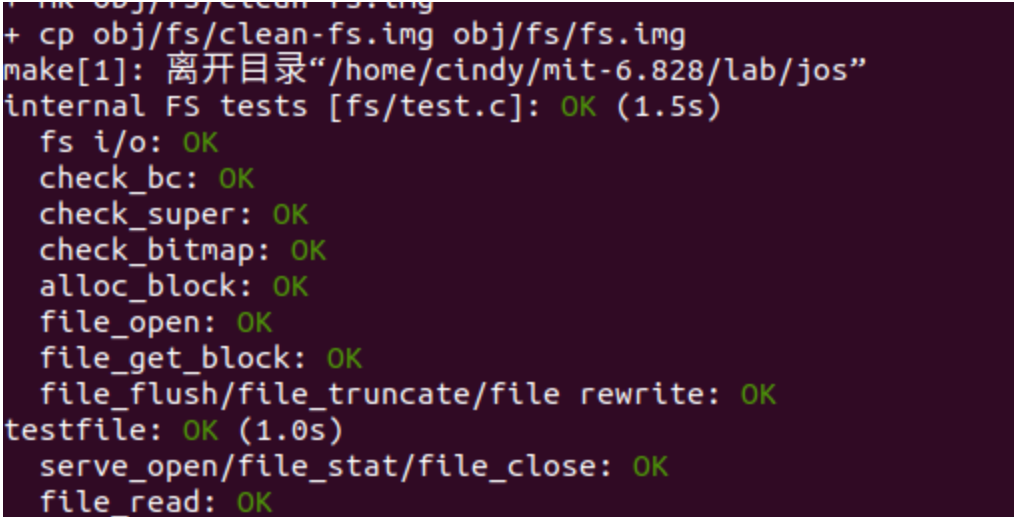
Exercise 6
serve_write():
int
serve_write(envid_t envid, struct Fsreq_write *req)
{
if (debug)
cprintf("serve_write %08x %08x %08x\n", envid, req->req_fileid, req->req_n);
// LAB 5: Your code here.
struct OpenFile *o;
int r;
if ((r = openfile_lookup(envid, req->req_fileid, &o)) < 0) {
return r;
}
int total = 0;
while (1) {
r = file_write(o->o_file, req->req_buf, req->req_n, o->o_fd->fd_offset);
if (r < 0) return r;
total += r;
o->o_fd->fd_offset += r;
if (req->req_n <= total)
break;
}
return total;
}
devfile_write():客户端进程函数,包装一下参数,直接调用fsipc()将参数发送给FS进程处理。
static ssize_t
devfile_write(struct Fd *fd, const void *buf, size_t n)
{
// Make an FSREQ_WRITE request to the file system server. Be
// careful: fsipcbuf.write.req_buf is only so large, but
// remember that write is always allowed to write *fewer*
// bytes than requested.
// LAB 5: Your code here
int r;
fsipcbuf.write.req_fileid = fd->fd_file.id;
fsipcbuf.write.req_n = n;
memmove(fsipcbuf.write.req_buf, buf, n);
return fsipc(FSREQ_WRITE, NULL);
}
练习6完成后,通过目前需要通过的测试
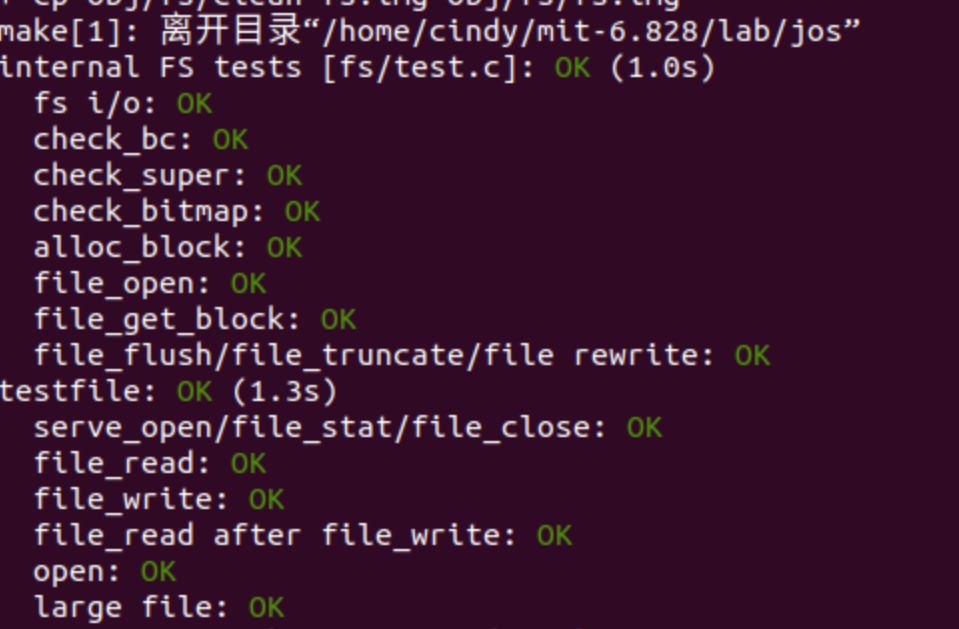
Spawning Processes
spawn函数表现得像在Unix下创建子进程带有一个立刻执行exec的fork函数。spawn,一个加载并运行磁盘可执行文件的库调用
lib/spawn.c中的spawn()创建一个新的进程,从文件系统加载用户程序,然后启动该进程来运行这个程序。spawn()就像UNIX中的fork()后面马上跟着exec()。spawn(const char *prog, const char **argv)做如下一系列动作:
- 从文件系统打开prog程序文件
- 调用系统调用sys_exofork()创建一个新的Env结构
- 调用系统调用sys_env_set_trapframe(),设置新的Env结构的Trapframe字段(该字段包含寄存器信息)。
- 根据ELF文件中program herder,将用户程序以Segment读入内存,并映射到指定的线性地址处。
- 调用系统调用sys_env_set_status()设置新的Env结构状态为ENV_RUNNABLE。
Exercise 7
static int
sys_env_set_trapframe(envid_t envid, struct Trapframe *tf)
{
// LAB 5: Your code here.
// Remember to check whether the user has supplied us with a good
// address!
int r;
struct Env *e;
if ((r = envid2env(envid, &e, 1)) < 0) {
return r;
}
tf->tf_eflags = FL_IF;
tf->tf_eflags &= ~FL_IOPL_MASK; //普通进程不能有IO权限
tf->tf_cs = GD_UT | 3;
e->env_tf = *tf;
return 0;
}
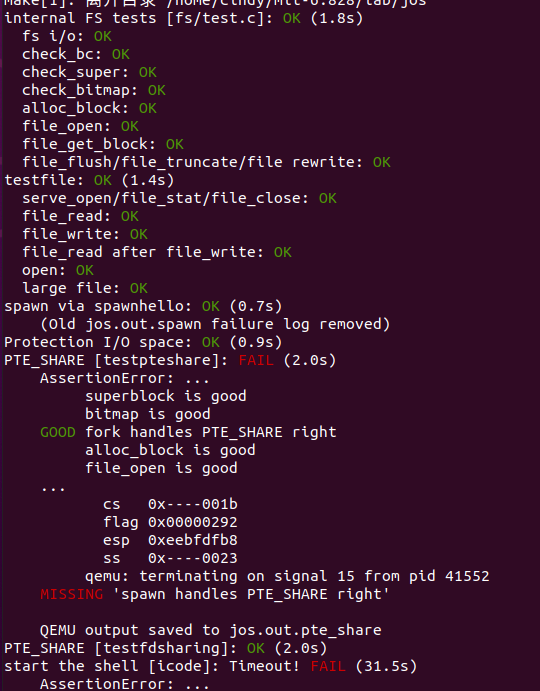
练习7 运行make run-spawn
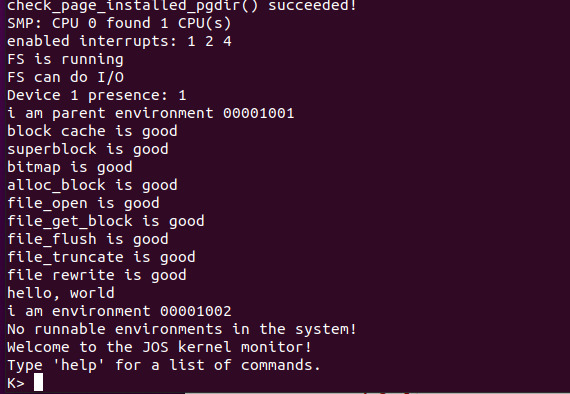
make grade成功通过目前需要通过的测试:
Sharing library state across fork and spawn
UNIX文件描述符是一个大的概念,包含pipe,控制台I/O。在JOS中每种设备对应一个struct Dev结构,该结构包含函数指针,指向真正实现读写操作的函数。
lib/fd.c文件实现了UNIX文件描述符接口,但大部分函数都是简单对struct Dev结构指向的函数的包装。
我们希望共享文件描述符,JOS中定义PTE新的标志位PTE_SHARE,如果有个页表条目的PTE_SHARE标志位为1,那么这个PTE在fork()和spawn()中将被直接拷贝到子进程页表,从而让父进程和子进程共享相同的页映射关系,从而达到父子进程共享文件描述符的目的。
Exercise 8
修改lib/fork.c中的duppage(),使之正确处理有PTE_SHARE标志的页表条目。同时实现lib/spawn.c中的copy_shared_pages()。
static int
duppage(envid_t envid, unsigned pn)
{
int r;
// LAB 4: Your code here.
void *addr = (void*) (pn * PGSIZE);
if (uvpt[pn] & PTE_SHARE) {
sys_page_map(0, addr, envid, addr, PTE_SYSCALL); //对于标识为PTE_SHARE的页,拷贝映射关系,并且两个进程都有读写权限
} else if ((uvpt[pn] & PTE_W) || (uvpt[pn] & PTE_COW)) { //对于UTOP以下的可写的或者写时拷贝的页,拷贝映射关系的同时,需要同时标记当前进程和子进程的页表项为PTE_COW
if ((r = sys_page_map(0, addr, envid, addr, PTE_COW|PTE_U|PTE_P)) < 0)
panic("sys_page_map:%e", r);
if ((r = sys_page_map(0, addr, 0, addr, PTE_COW|PTE_U|PTE_P)) < 0)
panic("sys_page_map:%e", r);
} else {
sys_page_map(0, addr, envid, addr, PTE_U|PTE_P); //对于只读的页,只需要拷贝映射关系即可
}
return 0;
}
static int
copy_shared_pages(envid_t child)
{
// LAB 5: Your code here.
uintptr_t addr;
for (addr = 0; addr < UTOP; addr += PGSIZE) {
if ((uvpd[PDX(addr)] & PTE_P) && (uvpt[PGNUM(addr)] & PTE_P) &&
(uvpt[PGNUM(addr)] & PTE_U) && (uvpt[PGNUM(addr)] & PTE_SHARE)) {
sys_page_map(0, (void*)addr, child, (void*)addr, (uvpt[PGNUM(addr)] & PTE_SYSCALL));
}
}
return 0;
}
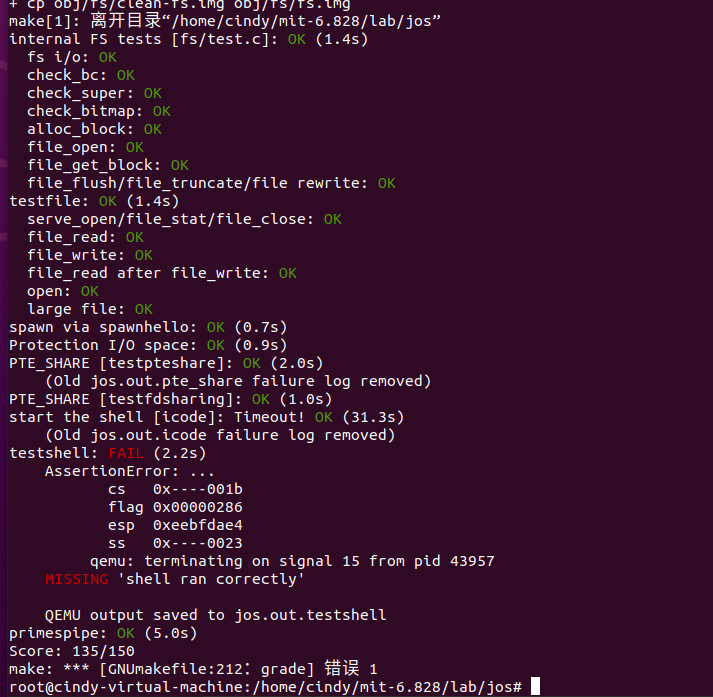
练习8结束后成功通过当前测试:
The keyboard interface
目前我们只能在内核监视器中才能接收输入。kern/console.c already contains the keyboard and serial drivers that have been used by the kernel monitor since lab 1, but now you need to attach these to the rest of the system.
Exercise 9
In your
kern/trap.c, callkbd_intrto handle trapIRQ_OFFSET+IRQ_KBDandserial_intrto handle trapIRQ_OFFSET+IRQ_SERIAL.
在/kern/console.c/cons_getc()中的代码,实现了在 monitor 模式下(禁止中断)可以正常获取用户输入。
// poll for any pending input characters,
// so that this function works even when interrupts are disabled
// (e.g., when called from the kernel monitor).
serial_intr();
kbd_intr();
在 trap.c 中加入中断处理函数。
case (IRQ_OFFSET + IRQ_KBD):
lapic_eoi();
kbd_intr();
break;
case (IRQ_OFFSET + IRQ_SERIAL):
lapic_eoi();
serial_intr();
break;
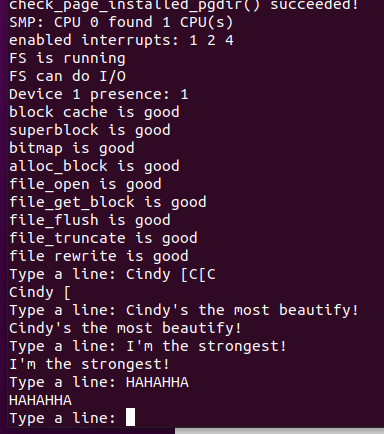
练习9,测试keyboard
The Shell
Run make run-icode。 QEMU将运行内核并执行user/icode,icode 将 console 设置为 文件描述符 0 和 1。然后 spawn sh。
Exercise 10
The shell doesn't support I/O redirection. It would be nice to run
sh <scriptinstead of having to type in all the commands in the script by hand, as you did above. Add I/O redirection for<touser/sh.c.
实现 I/O 重定向。第一反映就是解析<后的文件,通过打开文件获得文件描述符,再将此文件描述符传入关联到标准输入 0(使用dup实现),最后关闭之前获得的描述符。
if ( (fd = open(t, O_RDONLY) )< 0 ) {
fprintf(2,"file %s is no exist\n", t);
exit();
}
if (fd != 0) {
dup(fd, 0);
close(fd);
}
// LAB 5: Your code here.
// panic("< redirection not implemented");
break;
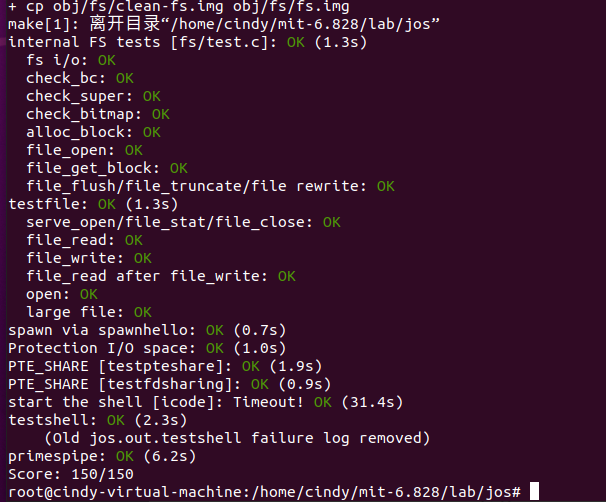
练习10之后!!成功啦!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号