

python—网络爬虫(Requests库的get方法)
Requests库的七个主要方法
------------------------------------------------
| 方法 | 说明 |
| requests.request() | 构造一个请求,支撑以下各方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页的头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete() | 向HTML网页提交删除请求的方法,对应于HTTP的DELETE |
r = requests.get(url) :
构造一个向服务器请求资源的Request对象(Request),并且get方法返回一个包含服务器资源的Response对象;
requests.get函数的完整参数如下:
requests.get(url, params = None, **kwargs)
url: 拟获取页面的url链接
params: url中额外参数,字典或字节流格式,可选
**kwargs: 12个控 访问的参数
Requests库的2个重要的对象 Request 和 Response对象(Response对象包含爬虫返回的所有内容)
>>> import requests #导入requests库
>>> r = requests.get("http://www.baidu.com")
>>> print(r.status_code) #检测请求的状态码,200表示请求成功
200
>>> type(r)
<class 'requests.models.Response'>
>>> r.headers
{'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'Keep-Alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Tue, 05 Jun 2018 11:48:31 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:27:36 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
Response对象的属性:
| 属性 | 说明 |
| r.status_code | HTTP请求的返回状态,200表求连接成功,404表示失败 |
| r.text | HTTP响应内容的字符串形式,即,url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式 |
Response对象的处理流程如下图示: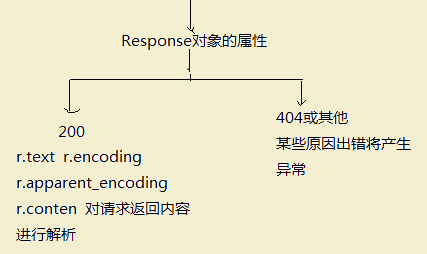
>>> import requests
>>> r = requests.get("http://www.baidu.com")
>>> r.status_code
200
>>> r.text #发现是乱码
>>> r.encoding #查看它的编码
'ISO-8859-1'
>>> r.apparent_encoding #再查看它的apparent_encoding编码
'utf-8'
>>> r.encoding ='utf-8' #用'utf-8'编码来替换'ISO-8859-1'这个编码。
>>> r.text #结果可以正常显示网页内容
理解Response的编码:
| 属性 | 说明 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应编码方式(备选编码方式) |
r.encoding:如果header中不存在charset,则认为编码为'ISO-8859-1'
r.apparent_encoding: 根据网页内容分析出的编码方式

