CSAPP 系统级I/O和网络编程

系统级I/O
文件
所有的 I/O 设备(例如网络、磁盘和终端)都被模型化为文件,而所有的输入和输出都被当作对相应文件的读和写来执行。这种将设备优雅地映射为文件的方式,允许 Linux 内核引出一个简单、低级的应用接口,称为 Unix I/O
Linux 文件有主要有三种类型:
- 普通文件
- 目录
- 网络socket(套接字)
当然还有命名通道(named pipe)、 符号链接(symbolic link),以及字符和块设备(character and block device)等类型先不予讨论。
改变当前的文件位置。对于每个打开的文件,内核保持着一个文件位置 k,初始为 0。这个文件位置是从文件开头起始的字节偏移量。应用程序能够通过执行 seek 操作,显式地设置文件的当前位置为 k。
对于这种行为,对于普通文件是有效的,对于如socket、目录等类型文件无效。
当我们调用open函数两次打开同一个普通文件foo.txt,那么这两次打开均会从文件起始位置开始,然后记录file_offset, read和write的读写操作均会改变file_offset。
且两次open返回的是不同的文件描述符。有点像CSAPP书上下图:
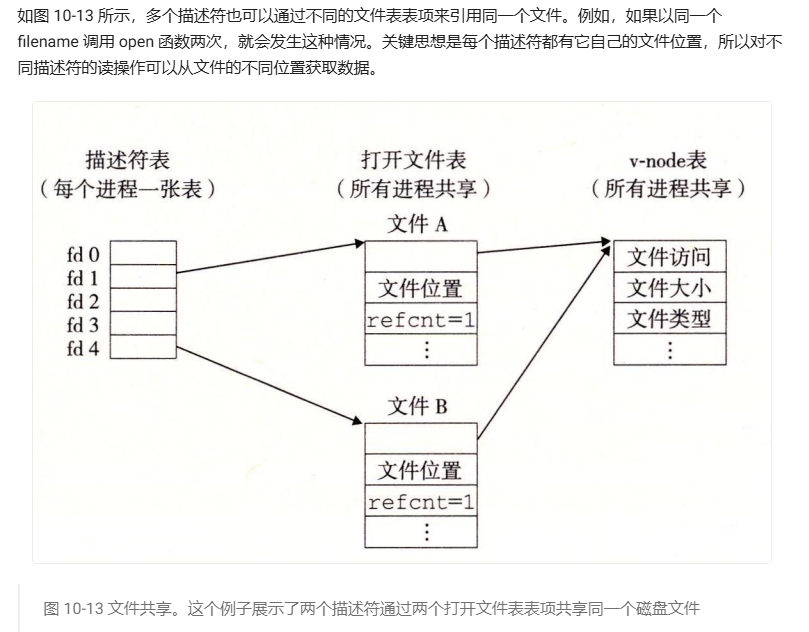
关于文件描述符,文件表,v-node表在fork后,重定向后如何均有提及。
RIO
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t n);
// 返回:若成功则为读的字节数,若 EOF 则为0,若出错为 -1。
ssize_t write(int fd, const void *buf, size_t n);
// 返回:若成功则为写的字节数,若出错则为 -1。
在 x86-64 系统中,size_t 被定义为 unsigned long,而 ssize_t(有符号的大小)被定义为 long。
read 函数返回一个有符号的大小,而不是一个无符号大小,这是因为出错时它必须返回 -1。
RIO(Robust I/O,健壮的 I/O)包,其实现的思路和目的为:
-
处理不足值:在某些情况下,read 和 write 传送的字节比应用程序要求的要少。这些不足值(short count)不表示有错误。出现这样情况的原因有:
- 读时遇到 EOF。这个时候说明确实没有内容可以读了,直接返回。
- 从终端读文本行。这个时候每个 read 函数将一次传送一个文本行。
- 读和写网络套接字(socket)。那么内部缓冲约束和较长的网络延迟会引起 read 和 write 返回不足值。这个时候必须通过反复调用 read 和 write 处理不足值,直到所有需要的字节都传送完毕。
-
实现无缓冲的输入输出函数:
rio_readn和rio_writen。这些函数直接在内存和文件之间传送数据,没有应用级缓冲。它们对将二进制数据读写到网络和从网络读写二进制数据尤其有用。
ssize_t rio_readn(int fd, void *usrbuf, size_t n);
ssize_t rio_writen(int fd, void *usrbuf, size_t n);
// 返回:若成功则为传送的字节数,若 EOF 则为 0(只对 rio_readn 而言),若出错则为 -1。
- 实现带缓冲的输入函数。这些函数允许你高效地从文件中读取文本行和二进制数据。
#define RIO_BUFSIZE 8192
typedef struct {
int rio_fd; /* Descriptor for this internal buf */
int rio_cnt; /* Unread bytes in internal buf */
char *rio_bufptr; /* Next unread byte in internal buf */
char rio_buf[RIO_BUFSIZE]; /* Internal buffer */
} rio_t;
//初始化rp指针
void rio_readinitb(rio_t *rp, int fd);
// 返回:无。
//对于文本数据,rio_readlineb,它从一个内部读缓冲区复制一个文本行,当缓冲区变空时,会自动地调用 read 重新填满缓冲区。
ssize_t rio_readlineb(rio_t *rp, void *usrbuf, size_t maxlen);
//对于既包含文本行也包含二进制数据的文件,提供了一个 rio_readn 带缓冲区的版本,叫做 rio_readnb,它从和 rio_readlineb 一样的读缓冲区中传送原始字节。
ssize_t rio_readnb(rio_t *rp, void *usrbuf, size_t n);
// 返回:若成功则为读的字节数,若 EOF 则为 0,若出错则为 -1。
手动实现一下
rio.c
#include "rio.h"
void unix_error(char *msg) /* Unix-style error */
{
fprintf(stderr, "%s: %s\n", msg, strerror(errno));
exit(0);
}
ssize_t rio_readn(int fd, void *userbuf, size_t n)
{
size_t nleft = n; // nleft为剩余需要读的字节数。
ssize_t nread = 0; // nread为接受read返回的字节数。
char *buf = userbuf; //char数据类型正好一个字节,这里的buf是userbuf的一个指针。
while (nleft > 0) {
if ((nread = read(fd, buf, nleft)) < 0) {
if (errno == EINTR) nread = 0; // 如果遇到中断,需要继续尝试读。
else return -1; // 否则其他错误返回-1。
} else if (nread == 0) break; // 说明读完了
nleft -= nread; buf += nread; // 还需要继续读
}
return (n - nleft); // 总共读到的字节数
}
ssize_t rio_writen(int fd, const void *userbuf, size_t n)
{
size_t nleft = n;
ssize_t nwrite = 0;
const char *buf = userbuf;
while (nleft > 0) {
if ((nwrite = write(fd, buf, n)) <= 0) { //需要注意的是这里和rio_readn不同,若 == 0说明是写失败了
if (errno = EINTR) nwrite = 0;
else return -1;
}
nleft -= nwrite; buf += nwrite;
}
return (n - nleft);
}
void rio_readinitb(rio_t *rp, int fd)
{
rp->rio_fd = fd;
rp->rio_cnt = 0;
rp->rio_bufptr = rp->rio_buf;
}
// rio_readnb 和 rio_readlineb都是从rp的内部缓冲区中读数据出来到指定数组中。
// 所以需要一个函数将数据从文件读到内部缓冲区来,并且再从内部缓冲区读数据到指定数组中。
// 且此函数还需要当内部缓冲区空了,则自动从文件中读数据填充。这个函数命名为rio_read
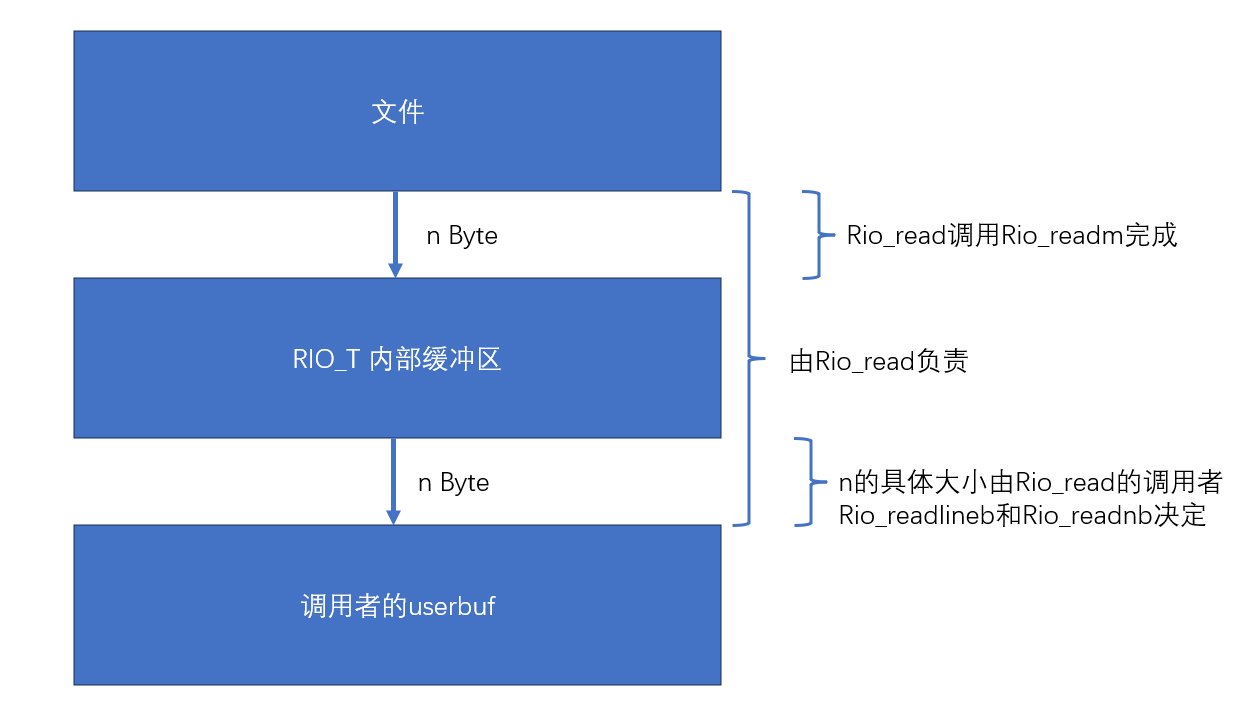
ssize_t rio_read(rio_t *rp, void *userbuf, size_t n)
{
ssize_t nread = 0;
if (rp->rio_cnt <= 0){ // 查看内部缓冲区是否还有数据,若没有则从文件中读取数据到内部缓冲区。
if ((nread = rio_readn(rp->rio_fd, rp->rio_buf, sizeof(rp->rio_buf))) < 0) return -1;
else if (nread == 0) return 0; // 说明读完了且rp内部缓冲区还没有数据了。
rp->rio_cnt = nread; rp->rio_bufptr = rp->rio_buf;
}
nread = n < rp->rio_cnt ? n : rp->rio_cnt;
memcpy(userbuf, rp->rio_bufptr, nread);
rp->rio_cnt -= nread; rp->rio_bufptr += nread; // rp->rio_bufptr的作用在于当内部缓冲区还未读完时,继续从未读的地方开始。
return nread;
}
ssize_t rio_readnb(rio_t *rp, void *userbuf, size_t n)
{
size_t nleft = n;
ssize_t nread = 0;
char *buf = userbuf;
while (nleft > 0){
if ((nread = rio_read(rp, buf, nleft)) < 0) return -1;
else if (nread == 0) break;
nleft -= nread; buf += nread;
}
return (n - nleft);
}
ssize_t rio_readlineb(rio_t *rp, void *userbuf, size_t maxlen) //读出一行文本,这一行文本<=maxlen个字符,不包括换行符\n
{
size_t nleft = maxlen;
ssize_t nread = 0;
char c, *buf = userbuf;
while (nleft > 0) {
if ((nread = rio_read(rp, &c, 1)) < 0) return -1;
else if (nread == 0) break;
assert(nread == 1);
if (c == '\n') break;
*buf = c; buf++; nleft--;
}
return (maxlen - nleft);
}
/**********************************
* Wrappers for robust I/O routines
**********************************/
ssize_t Rio_readn(int fd, void *ptr, size_t nbytes)
{
ssize_t n;
if ((n = rio_readn(fd, ptr, nbytes)) < 0)
unix_error("Rio_readn error");
return n;
}
void Rio_writen(int fd, void *usrbuf, size_t n)
{
if ((size_t)rio_writen(fd, usrbuf, n) != n)
unix_error("Rio_writen error");
}
void Rio_readinitb(rio_t *rp, int fd)
{
rio_readinitb(rp, fd);
}
ssize_t Rio_readnb(rio_t *rp, void *usrbuf, size_t n)
{
ssize_t rc;
if ((rc = rio_readnb(rp, usrbuf, n)) < 0)
unix_error("Rio_readnb error");
return rc;
}
ssize_t Rio_readlineb(rio_t *rp, void *usrbuf, size_t maxlen)
{
ssize_t rc;
if ((rc = rio_readlineb(rp, usrbuf, maxlen)) < 0)
unix_error("Rio_readlineb error");
return rc;
}
其中rio_read的实现思路为:
rio.h
#ifndef __RIO_H__
#define __RIO_H__
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <errno.h>
#include <assert.h>
void unix_error(char *msg);
//不带缓冲的输入输出函数
ssize_t rio_readn(int fd, void *userbuf, size_t n); // 返回:若成功则为读的字节数,若 EOF 则为0,若出错为 -1。
ssize_t rio_writen(int fd, const void *userbuf, size_t n); // 返回:若成功则为写的字节数,若出错则为 -1。
//带缓冲的输入函数
#define RIO_BUFSIZE 8192
typedef struct {
int rio_fd;
size_t rio_cnt; //rio_buf中还未读数据的大小
char *rio_bufptr; //rio_buf中下一个要读取的位置
char rio_buf[RIO_BUFSIZE]; //rio内部缓冲区
} rio_t;
void rio_readinitb(rio_t *rp, int fd);
ssize_t rio_readnb(rio_t *rp, void *userbuf, size_t n); // 返回:若成功则为读的字节数,若 EOF 则为 0,若出错则为 -1。
ssize_t rio_readlineb(rio_t *rp, void *userbuf, size_t maxlen); // 返回:若成功则为读的字节数,若 EOF 则为 0,若出错则为 -1。
/* Wrappers for Rio package */
ssize_t Rio_readn(int fd, void *usrbuf, size_t n);
void Rio_writen(int fd, void *usrbuf, size_t n);
void Rio_readinitb(rio_t *rp, int fd);
ssize_t Rio_readnb(rio_t *rp, void *usrbuf, size_t n);
ssize_t Rio_readlineb(rio_t *rp, void *usrbuf, size_t maxlen);
#endif
errno是一个全局变量,用于存储最近一次系统调用或库函数调用所发生错误的错误码。
在 Unix、Linux 和其他类 Unix 操作系统中,许多系统调用(如open、read、write、fork等)和一些库函数在执行过程中如果遇到错误,会将一个对应的错误码存储到errno中。
使用errno需要导入#include <errno.h>
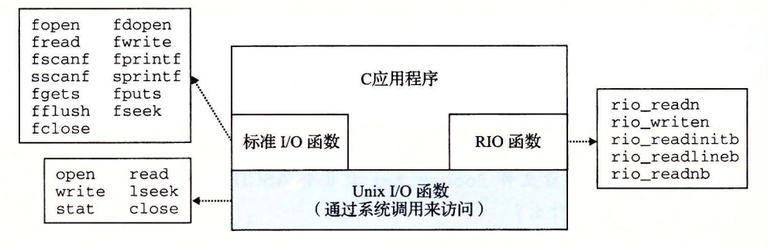
标准I/O
C 语言定义了一组高级输入输出函数,称为标准 I/O 库,为程序员提供了 Unix I/O 的较高级别的替代。
标准 I/O 库将一个打开的文件模型化为一个流。对于程序员而言,一个流就是一个指向 FILE 类型的结构的指针。
类型为 FILE 的流是对文件描述符和流缓冲区的抽象。流缓冲区的目的和 RIO 读缓冲区的一样:就是使开销较高的 Linux I/O 系统调用的数量尽可能得小。
#include <stdio.h>
extern FILE *stdin; /* Standard input (descriptor 0) */
extern FILE *stdout; /* Standard output (descriptor 1) */
extern FILE *stderr; /* Standard error (descriptor 2) */
-
G1:只要有可能就使用标准 I/O。
-
G2:不要使用 scanf 或 rio_readlineb 来读二进制文件。
因为scanf和rio_readlineb中均有通过换行符或终止符来判断是否需要'截断'的操作,二进制文件可能散布着很多 Oxa 字节,而这些字节又与终止文本行无关。 -
G3:对网络套接字的 I/O 使用 RIO 函数,而不要使用标准I/O。
具体理由和标准I/O内部实现有关,比如标准I/O需要使用 Unix I/O lseek 函数来重置当前的文件位置,但是socket没有文件位置这个概念。
网络编程
全球 IP 因特网是最著名和最成功的互联网络实现。
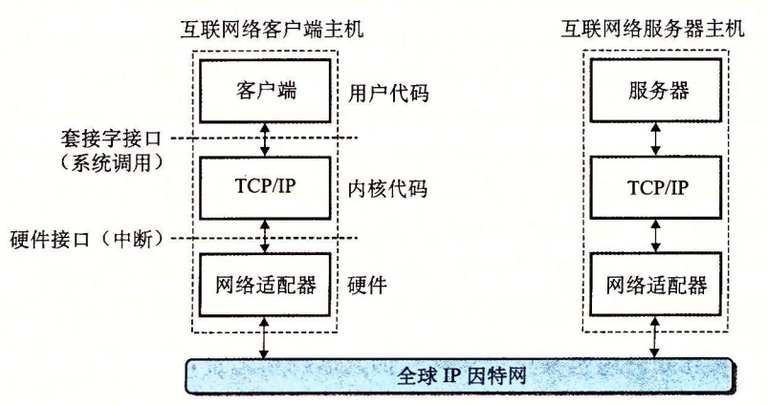
- 主机集合被映射为一组 32 位的 IP 地址。
- 这组 IP 地址被映射为一组称为因特网域名(Internet domain name)的标识符。
- 因特网主机上的进程能够通过连接(connection)和任何其他因特网主机上的进程通信。
套接字接口(socket interface)是一组函数,它们和 Unix I/O 函数结合起来,用以创建网络应用。大多数现代系统上都实现套接字接口,包括所有的 Unix 变种、Windows 和 Macintosh 系统。
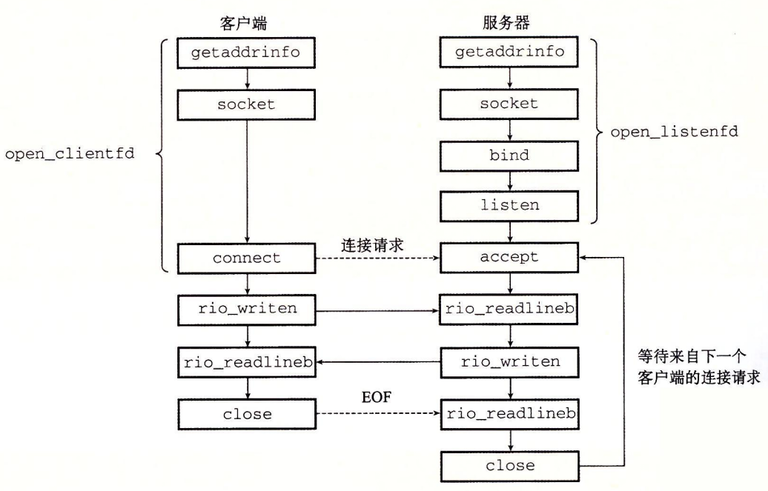
从 Linux 内核的角度来看,一个套接字就是通信的一个端点。从 Linux 程序的角度来看,套接字就是一个有相应描述符的打开文件。
套接字接口
套接字接口和其余相关函数过于复杂,并不是我想要理解的重点,这里我只使用CSAPP上分装好的函数,并理解好几个概念也能使用好套接字接口。
open_clientfd 函数
int open_clientfd(char *hostname, char *port); // 返回:若成功则为描述符,若出错则为 -1。
客户端调用 open_clientfd 建立与服务器的连接。
open_clientfd 函数建立与服务器的连接,该服务器运行在主机 hostname 上,并在端口号 port 上监听连接请求。它返回一个打开的套接字描述符,该描述符准备好了,可以用 Unix I/O 函数做输入和输出。
open_listenfd 函数
int open_listenfd(char *port); // 返回:若成功则为描述符,若出错则为 -1。
调用 open_listenfd 函数,服务器创建一个监听描述符,准备好接收连接请求。
open_listenfd 函数打开和返回一个监听描述符,这个描述符准备好在端口 port 接收连接请求。
Accept函数(非CSAPP的封装函数)
#include <sys/socket.h>
int accept(int listenfd, struct sockaddr *addr, int *addrlen);// 返回:若成功则为非负连接描述符,若出错则为 -1。
服务器通过调用 accept 函数来等待来自客户端的连接请求。
accept 函数等待来自客户端的连接请求到达侦听描述符 listenfd,然后在 addr 中填写客户端的套接字地址,并返回一个已连接描述符(connected descriptor)
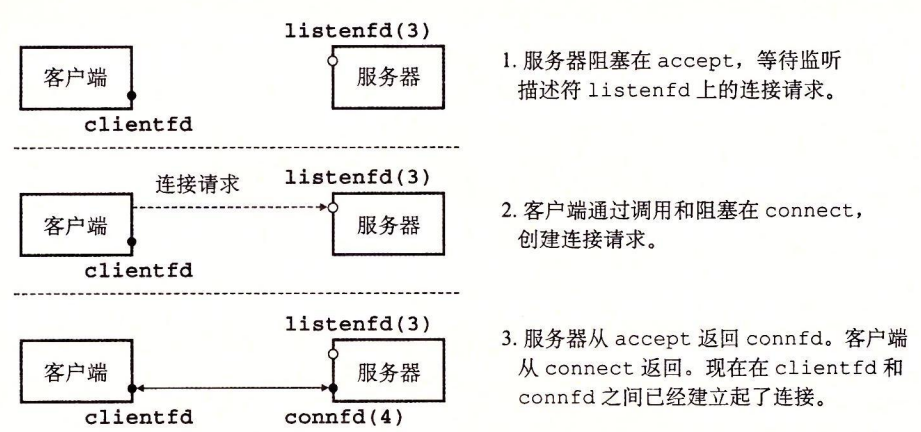
你可能很想知道为什么套接字接口要区别监听描述符和已连接描述符。乍一看,这像是不必要的复杂化。然而,区分这两者被证明是很有用的,因为它使得我们可以建立并发服务器,它能够同时处理许多客户端连接。例如,每次一个连接请求到达监听描述符时,我们可以派生(fork)—个新的进程,它通过已连接描述符与客户端通信。
其中套接字地址为如下结构:
struct sockaddr_in {
uint16_t sin_family; /* Protocol family (always AF_INET) */ 协议族
uint16_t sin_port; /* Port number in network byte order */ 端口
struct in_addr sin_addr; /* IP address in network byte order */ 主机地址
unsigned char sin_zero[8]; /* Pad to sizeof(struct sockaddr) */ 填充
};
sin_port 成员是一个 16 位的端口号,而 sin_addr 成员就是一个 32 位的 IP 地址。IP 地址和端口号总是以网络字节顺序(大端法)存放的。
但是实际使用的并不是上述的套接字地址,而是更加通用的sockaddr 结构
/* Generic socket address structure (for connect, bind, and accept) */
struct sockaddr {
uint16_t sa_family; /* Protocol family */
char sa_data[14]; /* Address data */
};
typedef struct sockaddr SA;
然后要求应用程序将与协议特定的结构的指针强制转换成这个通用结构。
EOF 的概念常常使人们感到迷惑,尤其是在因特网连接的上下文中。首先,我们需要理解其实并没有像 EOF 字符这样的一个东西。进一步来说,EOF 是由内核检测到的一种条件。
应用程序在它接收到一个由 read 函数返回的零返回码时,它就会发现出 EOF 条件。
对于磁盘文件,当前文件位置超出文件长度时,会发生 EOF。
对于因特网连接,当一个进程关闭连接它的那一端时,会发生 EOF。连接另一端的进程在试图读取流中最后一个字节之后的字节时,会检测到 EOF。
Web 服务器
Web 服务器以两种不同的方式向客户端提供内容:
- 取一个磁盘文件,并将它的内容返回给客户端。磁盘文件称为静态内容(static content),而返回文件给客户端的过程称为服务静态内容(serving static content)。
- 运行一个可执行文件,并将它的输出返回给客户端。运行时可执行文件产生的输出称为动态内容(dynamic content),而运行程序并返回它的输出到客户端的过程称为服务动态内容(serving dynamic content)。
客户端如何将程序参数传递给服务器?
在Http POST请求主体中。
服务器如何将参数传递给子进程
环境变量,使用setenv和getenv函数
子进程将它的输出发送到哪里
在子进程加载并运行程序之前,它使用 Linux dup2 函数将标准输出重定向到和客户端相关联的已连接描述符。

