基于HiBench测试Flink的环境安装指南

Preface
Read Document这章的配置是我尝试过的配置,具体我能够跑出来的正确配置在 Setup and Configuration
Read Document
HiBench
HiBench Suite
HiBench is a big data benchmark suite that helps evaluate different big data frameworks in terms of speed, throughput and system resource utilizations.
编译环境准备
HiBench编译依赖Java和Maven环境,首先需要配置Java和Maven的环境变量及准备HiBench的源码包
-
JAVA环境检查及配置
cd ~/usr/java wget https://download.java.net/openjdk/jdk8u41/ri/openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz tar -zxvf openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz wget https://download.java.net/openjdk/jdk11.0.0.2/ri/openjdk-11.0.0.2_linux-x64.tar.gz tar -zxvf openjdk-11.0.0.2_linux-x64.tar.gz vim ~/.bashrc #export JAVA_HOME=~/usr/java/java-se-8u41-ri export JAVA_HOME=~/usr/java/openjdk-11.0.0.2 export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:${JAVA_HOME}/lib/tools.jar:${JAVA_HOME}/lib/dt.jar :wq -
MAVEN环境检查及配置
在 Linux 系统中,
/usr/local目录通常用于存放由系统管理员手动安装的软件包和应用程序。与通过包管理器(如 apt、yum 等)安装到/usr目录中的软件不同,/usr/local目录中的内容通常不会被系统更新或升级覆盖。cd ~/usr/local wget https://dlcdn.apache.org/maven/maven-3/3.8.8/binaries/apache-maven-3.8.8-bin.tar.gz tar -zxvf apache-maven-3.8.8-bin.tar.gz vim ~/.bashrc export MVN_HOME=~/usr/local/apache-maven-3.8.8 export PATH=$MVN_HOME/bin:$PATH :wq mvn -v Apache Maven 3.8.8 (4c87b05d9aedce574290d1acc98575ed5eb6cd39) Maven home: /home/yxlin/usr/local/apache-maven-3.8.8 Java version: 1.8.0_41, vendor: Oracle Corporation, runtime: /home/yxlin/usr/java/java-se-8u41-ri/jre Default locale: en_US, platform encoding: UTF-8 OS name: "linux", version: "6.2.0-37-generic", arch: "amd64", family: "unix" -
下载HiBench源码
git clone https://github.com/Intel-bigdata/HiBench.git
HiBench编译
It contains a set of Hadoop, Spark and streaming workloads, including Sort, WordCount, TeraSort, Repartition, Sleep, SQL, PageRank, Nutch indexing, Bayes, Kmeans, NWeight and enhanced DFSIO, etc. It also contains several streaming workloads for Spark Streaming, Flink, Storm and Gearpump.
Workloads:
- Hadoop
- Spark
- streaming
- Spark Streaming
- Flink
- Storm
- Gearpump
Build a specific framework benchmark
HiBench 6.0 supports building only benchmarks for a specific framework.
Supported frameworks includs: hadoopbench, sparkbench, flinkbench, stormbench, gearpumpbench.
Build a single module
If you are only interested in a single workload in HiBench. You can build a single module.
Supported modules includes: micro, ml(machine learning), sql, websearch, graph, streaming, structuredStreaming(spark 2.0 or higher) and dal.
Run StreamingBench
The streaming benchmark consists of the following parts:
-
Data Generation
-
Kafka cluster
-
Test cluster
This could be a Spark cluster, Flink cluster, Storm cluster or Gearpump cluster. The **streaming application (identity, repartition, wordcount, fixwindow) **reads data from Kafka, processes the data and writes the results back to another topic in Kafka. Each record in the result is also labeled a timestamp.
-
Metrics reader
**I need to do:**
-
Setup python
Python 2.x(>=2.6) is required.
python --version Python 2.7.18 -
Setup Hadoop
Supported Hadoop version: Apache Hadoop 2.x
cd ~/usr/local wget https://archive.apache.org/dist/hadoop/common/hadoop-2.4.0/hadoop-2.4.0.tar.gz vim ~/.bashrc export HADOOP_HOME=~/usr/local/hadoop-2.4.0 export PATH=$HADOOP_HOME/bin:$PATH
sudo apt-get install ssh sudo apt-get install pdsh cd ~/usr/local/hadoop-2.4.0 edit the file
etc/hadoop/hadoop-env.shto define some parametersexport JAVA_HOME=/home/yxlin/usr/java/jdk1.8.0_202 Pseudo-Distributed Operation
Configuration
vim etc/hadoop/core-site.xml <configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/home/yxlin/usr/local/hadoop-2.4.0/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration> vim etc/hadoop/hdfs-site.xml <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/yxlin/usr/local/hadoop-2.4.0/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/yxlin/usr/local/hadoop-2.4.0/tmp/dfs/data</value> </property> </configuration> Setup passphraseless ssh
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys Execution
bin/hdfs namenode -format sbin/start-dfs.sh or sbin/ When you’re done, stop the daemons with:
sbin/stop-dfs.shYARN on a Single Node
vim etc/hadoop/mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> vim etc/hadoop/yarn-site.xml <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> sbin/start-yarn.sh When you’re done, stop the daemons with:
sbin/stop-yarn.shlocalhost: starting nodemanager, logging to /home/yxlin/usr/local/hadoop-2.4.0/logs/yarn-yxlin-nodemanager-orange.out
localhost: OpenJDK 64-Bit Server VM warning: You have loaded library /home/yxlin/usr/local/hadoop-2.4.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
localhost: It's highly recommended that you fix the library with 'execstack -c', or link it with '-z noexecstack'.
Record:
-
The Hadoop installation location
hibench.hadoop.home ~/usr/local/hadoop-2.4.0
-
The path of hadoop executable
hibench.hadoop.executable ${hibench.hadoop.home}/bin/hadoop
-
Hadoop configuration directory
hibench.hadoop.configure.dir ${hibench.hadoop.home}/etc/hadoop
-
The root HDFS path to store HiBench data
hdfs://localhost:9000
-
Hadoop release provider
apache
尝试运行Hadoop官方文档上的执行程序,使用
jps命令查看启动进程,发现一个都没有运行起来到hadoop目录下的
logs/hadoop-yxlin-secondarynamenode-orange.logjava.net.BindException: Port in use: 0.0.0.0:50090
dfs.namenode.http-address
0.0.0.0:50071
dfs.datanode.address
0.0.0.0:50011
dfs.secondary.http.address
0.0.0.0:50091
Caused by: java.net.BindException: Address already in use
hadoop-yxlin-datanode-orange.logjava.net.BindException: Problem binding to [0.0.0.0:50010] java.net.BindException: Address already in use; For more details see: http://wiki.apache.org/hadoop/BindException
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:719)
at org.apache.hadoop.ipc.Server.bind(Server.java:419)
at org.apache.hadoop.ipc.Server.bind(Server.java:391)
at org.apache.hadoop.hdfs.net.TcpPeerServer.(TcpPeerServer.java:106)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initDataXceiver(DataNode.java:524)
at org.apache.hadoop.hdfs.server.datanode.DataNode.startDataNode(DataNode.java:736)
at org.apache.hadoop.hdfs.server.datanode.DataNode.(DataNode.java:281)
at org.apache.hadoop.hdfs.server.datanode.DataNode.makeInstance(DataNode.java:1878)
at org.apache.hadoop.hdfs.server.datanode.DataNode.instantiateDataNode(DataNode.java:1772)
at org.apache.hadoop.hdfs.server.datanode.DataNode.createDataNode(DataNode.java:1812)
at org.apache.hadoop.hdfs.server.datanode.DataNode.secureMain(DataNode.java:1988)
at org.apache.hadoop.hdfs.server.datanode.DataNode.main(DataNode.java:2012)
2024-07-27 17:53:41,988 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1java.net.BindException: Port in use: 0.0.0.0:50075
at org.apache.hadoop.http.HttpServer2.openListeners(HttpServer2.java:859)
at org.apache.hadoop.http.HttpServer2.start(HttpServer2.java:795)
at org.apache.hadoop.hdfs.server.datanode.DataNode.startInfoServer(DataNode.java:379)
at org.apache.hadoop.hdfs.server.datanode.DataNode.startDataNode(DataNode.java:737)
at org.apache.hadoop.hdfs.server.datanode.DataNode.(DataNode.java:281)
at org.apache.hadoop.hdfs.server.datanode.DataNode.makeInstance(DataNode.java:1878)
at org.apache.hadoop.hdfs.server.datanode.DataNode.instantiateDataNode(DataNode.java:1772)
at org.apache.hadoop.hdfs.server.datanode.DataNode.createDataNode(DataNode.java:1812)
at org.apache.hadoop.hdfs.server.datanode.DataNode.secureMain(DataNode.java:1988)
at org.apache.hadoop.hdfs.server.datanode.DataNode.main(DataNode.java:2012)
Caused by: java.net.BindException: Address already in use
at sun.nio.ch.Net.bind0(Native Method)
at sun.nio.ch.Net.bind(Net.java:433)
at sun.nio.ch.Net.bind(Net.java:425)
at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:223)
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:74)
at org.mortbay.jetty.nio.SelectChannelConnector.open(SelectChannelConnector.java:216)
at org.apache.hadoop.http.HttpServer2.openListeners(HttpServer2.java:854)java.net.BindException: Problem binding to [0.0.0.0:50020] java.net.BindException: Address already in use; For more details see: http://wiki.apache.org/hadoop/BindException
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:719)
at org.apache.hadoop.ipc.Server.bind(Server.java:419)
at org.apache.hadoop.ipc.ServerServer.(RPC.java:897)
at org.apache.hadoop.ipc.ProtobufRpcEngineBuilder.build(RPC.java:742)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initIpcServer(DataNode.java:415)
at org.apache.hadoop.hdfs.server.datanode.DataNode.startDataNode(DataNode.java:743)
at org.apache.hadoop.hdfs.server.datanode.DataNode.(DataNode.java:281)
at org.apache.hadoop.hdfs.server.datanode.DataNode.makeInstance(DataNode.java:1878)
at org.apache.hadoop.hdfs.server.datanode.DataNode.instantiateDataNode(DataNode.java:1772)
at org.apache.hadoop.hdfs.server.datanode.DataNode.createDataNode(DataNode.java:1812)
at org.apache.hadoop.hdfs.server.datanode.DataNode.secureMain(DataNode.java:1988)
at org.apache.hadoop.hdfs.server.datanode.DataNode.main(DataNode.java:2012)hadoop-yxlin-namenode-orange.log:java.net.bindexception: port in use: 0.0.0.0:50070 Caused by: java.net.BindException: Address already in use
vim etc/hadoop/hdfs-site.xml<property> <name>dfs.namenode.http-address</name> <value>0.0.0.0:50071</value> </property> <property> <name>dfs.datanode.address</name> <value>0.0.0.0:50011</value> </property> <property> <name>dfs.datanode.http.address</name> <value>0.0.0.0:50076</value> </property> <property> <name>dfs.secondary.http.address</name> <value>0.0.0.0:50091</value> </property> 记录下时间节点:2024/7/27 ,总算是跑通了hadoop,但是我还只搞到运行Hadoop伪分布式实例,没有搞到YARN
对于解决上述问题给我启关键性的博客是Hadoop安装教程_单机/伪分布式配置, 以及在Hadoop目录下查看logs
Hadoop 安装配置、官方案例、自己编写案例(入门到入土)
不启动 YARN 需重命名 mapred-site.xml: 如果不想启动 YARN,务必把配置文件 mapred-site.xml 重命名,改成 mapred-site.xml.template,需要用时改回来就行。否则在该配置文件存在,而未开启 YARN 的情况下,运行程序会提示 "Retrying connect to server: 0.0.0.0/0.0.0.0:8032" 的错误,这也是为何该配置文件初始文件名为 mapred-site.xml.template。
2024-07-28 09:49:23,227 INFO org.apache.hadoop.service.AbstractService: Service NodeManager failed in state STARTED; cause: org.apache.hadoop.yarn.exceptions.YarnRuntimeException: java.net.BindException: Problem binding to [0.0.0.0:8040] java.net.BindException: Address already in use; For more details see: http://wiki.apache.org/hadoop/BindException
org.apache.hadoop.yarn.exceptions.YarnRuntimeException: java.net.BindException: Problem binding to [0.0.0.0:8040] java.net.BindException: Address already in use; For more details see: http://wiki.apache.org/hadoop/BindExceptionem...总之各种冲突
官网下滑会找到Configuration,在里面对号入座找到冲突更改:
vim ./etc/hadoop/yarn-site.xml<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>0.0.0.0:8089</value> </property> <property> <name>yarn.nodemanager.localizer.address</name> <value>0.0.0.0:8041</value> </property> <property> <name>yarn.nodemanager.webapp.address</name> <value>0.0.0.0:8043</value> </property> vim ./etc/hadoop/mapred-site.xml<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.shuffle.port</name> <value>13563</value> </property>
一点查看端口的常用命令:
jps # 查看当前运行起来的java程序 lsof -i:9000 yxlin@orange:~/usr/local/hadoop-2.4.0$ netstat -tnlpa | grep 50010 (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) tcp 0 0 0.0.0.0:50010 0.0.0.0:* LISTEN - 最后的-本来会显示出运行的pid和进程,这里显示出-可能表示我们权限不够 -
-
Setup Spark
upported Spark version: 1.6.x, 2.0.x, 2.1.x, 2.2.x
wget https://archive.apache.org/dist/spark/spark-2.1.0/spark-2.1.0-bin-hadoop2.4.tgz vim ~/.bashrc export SPARK_HOME=spark-2.1.0-bin-hadoop2.4 export PATH=$SPARK_HOME/bin:$PATH Spark’s shell provides a simple way to learn the API, as well as a powerful tool to analyze data interactively.
./bin/pyspark -
Scala
wget https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz -
Start HDFS, Yarn in the cluster
cd ~/usr/local/hadoop-2.4.0 bin/hdfs namenode -format sbin/start-dfs.sh sbin/start-yarn.sh -
Setup ZooKeeper (3.4.8 is preferred)
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.8/zookeeper-3.4.8.tar.gz To start ZooKeeper you need a configuration file. Here is a sample, create it in conf/zoo.cfg:
cp conf/zoo_sample.cfg conf/zoo.cfg mkdir ~/var/lib/zookeeper #数据存储目录 vim conf/zoo.cfg # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/home/yxlin/var/lib/zookeeper bin/zkServer.sh start # run 运行Zookeeper会报错:
INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NIOServerCnxnFactory)
[2024-07-28 11:33:32,035] ERROR Unexpected exception, exiting abnormally (org.apache.zookeeper.server.ZooKeeperServerMain)
java.net.BindException: Address already in usevim conf/zoo.cfg the port at which the clients will connect clientPort=2183 -
Setup Apache Kafka (0.8.2.2, scala version 2.10 is preferred)
wget https://archive.apache.org/dist/kafka/0.8.2.2/kafka_2.11-0.8.2.2.tgz vim config/zookeeper.properties # 里面的配置要和Zookeeper一样 vim config/server.properties log.dirs=/home/yxlin/var/lib/kafka_log # log目录 # You can also append an optional chroot string to the urls to specify the # root directory for all kafka znodes. zookeeper.connect=localhost:2183 # 同Zookeeper中一样 bin/kafka-server-start.sh config/server.properties # run 需要注意的是官网上还有一条启动命令
bin/zookeeper-server-start.sh config/zookeeper.properties # 这条命令如果我们在zookeeper下启动了zookeeper,那么就不要再执行了,否则如下报错: INFO binding to port 0.0.0.0/0.0.0.0:2183 (org.apache.zookeeper.server.NIOServerCnxnFactory)
kafka.common.KafkaException: Socket server failed to bind to 0.0.0.0:9092: Address already in use.
at kafka.network.Acceptor.openServerSocket(SocketServer.scala:260)
at kafka.network.Acceptor.(SocketServer.scala:205)
at kafka.network.SocketServer.startup(SocketServer.scala:86)
at kafka.server.KafkaServer.startup(KafkaServer.scala:99)
at kafka.server.KafkaServerStartable.startup(KafkaServerStartable.scala:29)
at kafka.Kafka$.main(Kafka.scala:46)
at kafka.Kafka.main(Kafka.scala)
Caused by: java.net.BindException: Address already in use
at sun.nio.ch.Net.bind0(Native Method)
at sun.nio.ch.Net.bind(Net.java:433)
at sun.nio.ch.Net.bind(Net.java:425)
at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:223)
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:74)
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:67)
at kafka.network.Acceptor.openServerSocket(SocketServer.scala:256)
... 6 morevim config/server.properties # The port the socket server listens on port=9093 -
Setup one of the streaming frameworks that you want to test.
Apache Flink (1.0.3 is prefered but I need Flink 1.11.3)
Flink runs on all UNIX-like environments, i.e. Linux, Mac OS X, and Cygwin (for Windows). You need to have Java 11 installed. To check the Java version installed, type in your terminal:
wget https://archive.apache.org/dist/flink/flink-1.11.3/flink-1.11.3-bin-scala_2.11.tgz ./bin/start-cluster.sh # run ./bin/stop-cluster.sh # stop flink-yxlin-standalonesession-0-orange.log:
org.apache.flink.runtime.entrypoint.ClusterEntrypoint [] - Shutting StandaloneSessionClusterEntrypoint down with application status FAILED. Diagnostics java.net.BindException: Could not start actor system on any port in port range 6123
flink-yxlin-standalonesession-1-orange.log:
Caused by: java.net.BindException: Could not start actor system on any port in port range 6123
at org.apache.flink.runtime.clusterframework.BootstrapTools.startRemoteActorSystem(BootstrapTools.java:172) ~[flink-dist_2.11-1.11.3.jar:1.11.3]
at org.apache.flink.runtime.rpc.akka.AkkaRpcServiceUtils$AkkaRpcServiceBuilder.createAndStart(AkkaRpcServiceUtils.java:349) ~[flink-dist_2.11-1.11.3.jar:1.11.3]...
flink-yxlin-taskexecutor-0-orange.log :
org.apache.flink.runtime.taskexecutor.exceptions.RegistrationTimeoutException: Could not register at the ResourceManager within the specified maximum registration duration 300000 ms. This indicates a problem with this instance. Terminating now.
vim conf/flink-conf.yaml jobmanager.rpc.port: 6124 rest.port: 8083 vim conf/masters localhost:8082 vim conf/zoo.cfg # The port at which the clients will connect clientPort=2183 2024-07-28 15:40:23,282 WARN akka.remote.ReliableDeliverySupervisor
[] - Association with remote system [akka.tcp://flink@localhost:6124] has failed, address is now gated for [50] ms. Reason: [Association failed with [akka.tcp://flink@localhost:6124]] Caused by: [java.net.ConnectException: Connection refused: localhost/127.0.0.1:6124]
2024-07-28 15:40:23,282 WARN akka.remote.transport.netty.NettyTransport[] - Remote connection to [null] failed with java.net.ConnectException: Connection refused: localhost/127.0.0.1:6124
Could not start cluster entrypoint StandaloneSessionClusterEntrypoint.
org.apache.flink.runtime.entrypoint.ClusterEntrypointException: Failed to initialize the cluster entrypoint StandaloneSessionClusterEntrypoint. -
mvn -Pflinkbench -Dmodules -Pstreaming -Dspark=2.1 -Dhadoop=2.4 -Dscala=2.11 clean package Error
mvn clean installPlugin org.apache.maven.plugins:maven-clean-plugin:2.5 or one of its dependencies could not be resolved:
Failed to read artifact descriptor for org.apache.maven.plugins:maven-clean-plugin:jar:2.5:
Could not transfer artifact org.apache.maven.plugins:maven-clean-plugin:pom:2.5 from/to scala-tools.org (https://oss.sonatype.org/content/groups/scala-tools/):
transfer failed for https://oss.sonatype.org/content/groups/scala-tools/org/apache/maven/plugins/maven-clean-plugin/2.5/maven-clean-plugin-2.5.pom:
java.lang.RuntimeException:
Unexpected error: java.security.InvalidAlgorithmParameterException: the trustAnchors parameter must be non-empty -> [Help 1]出现上述原因我用Oracle jdk8会出现上述问题,Oracle jdk11就没有问题,但是运行Oracle jdk11会有如下错误:
[ERROR] error: scala.reflect.internal.MissingRequirementError: object java.lang.Object in compiler mirror not found.
出现这个原因,查询网络得到答案是要用JDK8
尝试过许多方法,最后兜兜转转还是回到了用jdk8,然后爆出如下错误:
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.2:
compile (default-compile) on project hibench-common: Execution default-compile of goal org.apache.maven.plugins:maven-compiler-plugin:3.2:
compile failed: Plugin org.apache.maven.plugins:maven-compiler-plugin:3.2 or one of its dependencies could not be resolved: Failed to collect dependencies at org.apache.maven.plugins:maven-compiler-plugin:jar:3.2 -> org.apache.maven:maven-plugin-api:jar:2.0.9:
Failed to read artifact descriptor for org.apache.maven:maven-plugin-api:jar:2.0.9:
Could not transfer artifact org.apache.maven:maven-plugin-api:pom:2.0.9 from/to scala-tools.org (https://oss.sonatype.org/content/groups/scala-tools/): transfer failed for https://oss.sonatype.org/content/groups/scala-tools/org/apache/maven/maven-plugin-api/2.0.9/maven-plugin-api-2.0.9.pom:
java.lang.RuntimeException: Unexpected error: java.security.InvalidAlgorithmParameterException: the trustAnchors parameter must be non-empty -> [Help 1]
最终我打算试一试降低maven版本和重新git clone hibench
wget https://archive.apache.org/dist/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz
注意下载的jdk版本位数一定要和操作系统一样(如操作系统是86位的,我们jdk就不能下64位的),否则会出现No such file or directory这样的问题
mvn -Pflinkbench -Dmodules -Pstreaming -Dscala=2.11 clean package
如果用如下命令会报错:
mvn -Pflinkbench -Dmodules -Pstreaming -Dspark=2.1 -Dhadoop=2.4 -Dscala=2.11 clean package [INFO] Scanning for projects... [ERROR] [ERROR] Some problems were encountered while processing the POMs: [ERROR] 'dependencies.dependency.version' for org.apache.hadoop:hadoop-hdfs:jar must be a valid version but is '${hadoop.mr2.version}'. @ com.intel.hibench:autogen:[unknown-version], /home/yxlin/HiBench/autogen/pom.xml, line 70, column 16 [ERROR] 'dependencies.dependency.version' for org.apache.hadoop:hadoop-client:jar must be a valid version but is '${hadoop.mr2.version}'. @ com.intel.hibench:autogen:[unknown-version], /home/yxlin/HiBench/autogen/pom.xml, line 85, column 16 [ERROR] 'dependencies.dependency.version' for org.apache.spark:spark-core_2.11:jar must be a valid version but is '${spark.version}'. @ com.intel.hibench:autogen:[unknown-version], /home/yxlin/HiBench/autogen/pom.xml, line 105, column 16 [ERROR] 'dependencies.dependency.version' for org.apache.spark:spark-sql_2.11:jar must be a valid version but is '${spark.version}'. @ com.intel.hibench:autogen:[unknown-version], /home/yxlin/HiBench/autogen/pom.xml, line 121, column 16 ...
em...目前没有影响就先不管了
Configure hadoop.conf
cd ~/HiBench cp conf/hadoop.conf.template conf/hadoop.conf vim conf/hadoop.conf # Hadoop home hibench.hadoop.home /home/yxlin/usr/local/hadoop-2.4.0 # The path of hadoop executable hibench.hadoop.executable ${hibench.hadoop.home}/bin/hadoop # Hadoop configraution directory hibench.hadoop.configure.dir ${hibench.hadoop.home}/etc/hadoop # The root HDFS path to store HiBench data hibench.hdfs.master hdfs://localhost:9000 # Hadoop release provider. Supported value: apache hibench.hadoop.release apache
Configure Kafka
vim hibench.conf hibench.streambench.kafka.home /home/yxlin/usr/local/kafka_2.11-0.8.2.2 # zookeeper host:port of kafka cluster, host1:port1,host2:port2... hibench.streambench.zkHost localhost:2181 # Kafka broker lists, written in mode host:port,host:port,.. hibench.streambench.kafka.brokerList localhost:9092 hibench.streambench.kafka.consumerGroup HiBench # number of partitions of generated topic (default 20) hibench.streambench.kafka.topicPartitions 20 # consumer group of the consumer for kafka (default: HiBench) hibench.streambench.kafka.consumerGroup HiBench # Set the starting offset of kafkaConsumer (default: largest) hibench.streambench.kafka.offsetReset largest
Configure Flink
Configure Data Generator
Set the below Kafka properites in conf/hibench.conf and leave others as default.
Configure the Streaming Framework
cp conf/flink.conf.template conf/flink.conf hibench.streambench.flink.home /home/yxlin/usr/local/flink-1.11.3 hibench.flink.master localhost:8082 #在flink配置中配置过
Generate the data
File "/home/yxlin/HiBench/bin/functions/load_config.py", line 500, in probe_masters_slaves_by_Yarn
assert 0, "Get workers from yarn-site.xml page failed, reason:%s\nplease sethibench.masters.hostnamesandhibench.slaves.hostnamesmanually" % e
AssertionError: Get workers from yarn-site.xml page failed, reason:( /home/yxlin/usr/local/hadoop-2.4.0/bin/yarn node -list 2> /dev/null | grep RUNNING ) executed timedout for 5 seconds
please sethibench.masters.hostnamesandhibench.slaves.hostnamesmanually
vim conf/hibench.conf hibench.masters.hostnames node1.novalocal hibench.slaves.hostnames node1.novalocal node2.novalocal node3.novalocal
Exception in thread "main" java.io.IOException: No space left on device
at java.io.FileOutputStream.writeBytes(Native Method)
at java.io.FileOutputStream.write(FileOutputStream.java:326)
at org.apache.hadoop.io.IOUtils.copyBytes(IOUtils.java:95)
at org.apache.hadoop.util.RunJar.unJar(RunJar.java:121)
at org.apache.hadoop.util.RunJar.unJar(RunJar.java:94)
at org.apache.hadoop.util.RunJar.run(RunJar.java:227)
at org.apache.hadoop.util.RunJar.main(RunJar.java:153)
ERROR: Hadoop job /home/yxlin/HiBench/autogen/target/autogen-8.0-SNAPSHOT-jar-with-dependencies.jar HiBench.DataGen failed to run successfully.
Hint: You can goto /home/yxlin/HiBench/report/identity/prepare/conf/../bench.log to check for detailed log.
Opening log tail for youException in thread "main" java.net.ConnectException: Call From orange/127.0.1.1 to localhost:9000 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
Module ?
-
Scala is often used to write Spark applications. HiBench itself is partially written in Scala
-
Hadoop is a framework for distributed storage and processing of large datasets using the MapReduce programming model.
Apache Hadoop 是一种开源框架,用于高效存储和处理从 GB 级到 PB 级的大型数据集。利用 Hadoop,您可以将多台计算机组成集群以便更快地并行分析海量数据集,而不是使用一台大型计算机来存储和处理数据。
- Hadoop 分布式文件系统 (HDFS)—一个在标准或低端硬件上运行的分布式文件系统。除了更高容错和原生支持大型数据集,HDFS 还提供比传统文件系统更出色的数据吞吐量。
- Yet Another Resource Negotiator (YARN)—管理与监控集群节点和资源使用情况。它会对作业和任务进行安排。
- MapReduce—一个帮助计划对数据运行并行计算的框架。该 Map 任务会提取输入数据,转换成能采用键值对形式对其进行计算的数据集。Reduce 任务会使用 Map 任务的输出来对输出进行汇总,并提供所需的结果。
- Hadoop Common—提供可在所有模块上使用的常见 Java 库。
-
Spark is a fast, in-memory data processing engine used for big data analytics.
HiBench includes benchmarks that specifically test the performance of Spark on various workloads.
Apache Spark 是一个用于进行大规模数据处理的统一分析引擎,内置了用于 SQL、流式传输、机器学习和图处理的模块。Spark 可以在云中针对不同的数据源在 Apache Hadoop、Apache Mesos、Kubernetes 上运行,也可以独立运行。
-
Apache Kafka is a distributed streaming platform widely used for building real-time data pipelines and streaming applications.
-
ZooKeeper 是一种集中式服务,用于维护配置信息、命名、提供分布式同步和提供组服务。
参考资料
采用Hibench在本地对Spark Streaming进行benchmark
The HiBench Benchmark Suite: Characterization of the MapReduce-Based Data Analysis
Flink
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
-
Stateful Computations
Stateful refers to computations that maintain some form of memory or context about past events or data. This means the system can remember previous inputs and use this information to influence future outputs.
-
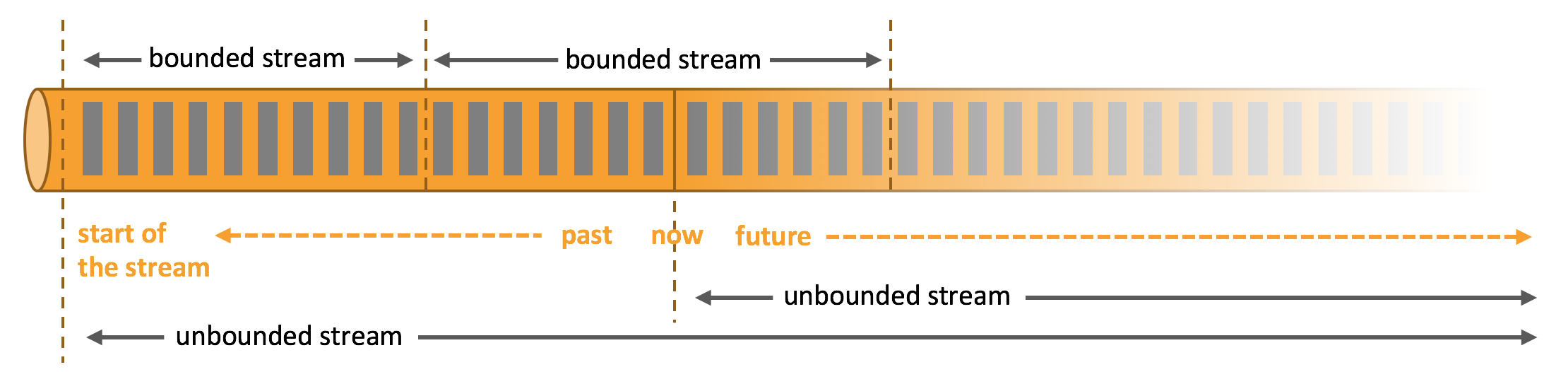
Process Unbounded and Bounded Data
Any kind of data is produced as a stream of events. Data can be processed as unbounded or bounded streams.
-
Unbounded streams have a start but no defined end. Unbounded streams must be continuously processed, i.e., events must be promptly handled after they have been ingested.
Examples include live sensor data, real-time financial transactions, or social media feeds.
-
Bounded streams have a defined start and end. Bounded streams can be processed by ingesting all data before performing any computations.
Examples include a fixed log file or a set of historical transaction records.
-
-
Cluster
A cluster is a collection of interconnected computers (often referred to as nodes or machines) that work together as a single system to perform tasks.
Cluster environments refer to the specific setups, configurations, and management systems used to organize and manage clusters.
-
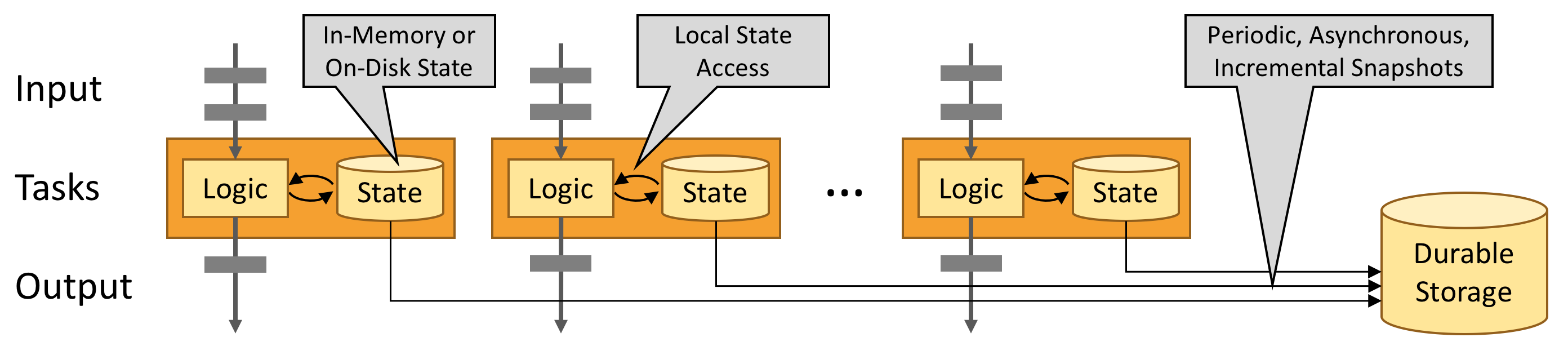
Leverage In-Memory Performance
Stateful Flink applications are optimized for local state access. Task state is always maintained in memory or, if the state size exceeds the available memory, in access-efficient on-disk data structures.
Setup and Configuration
Preface
我之所以会遇到如此多的配置问题,是因为机子上端口冲突了且无法kill掉冲突的程序
如果没有遇到端口冲突,完全可以就只按照官方文档上quickStart中配置的内容进行配置。
Hadoop-2.7.6
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.6/hadoop-2.7.6.tar.gz
etc/hadoop/hadoop-env.sh
export JAVA_HOME=/home/yxlin/usr/java/jdk1.8.0_202
etc/hadoop/core-site.xml
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/home/yxlin/usr/local/hadoop-2.7.6/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/yxlin/usr/local/hadoop-2.7.6/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/yxlin/usr/local/hadoop-2.7.6/tmp/dfs/data</value> </property> <!--Hadoop2.x 默认namenode进程在50070,Hadoop3.x 默认在9870,为避免冲突,需要更>改下--> <property> <name>dfs.namenode.http-address</name> <value>0.0.0.0:50071</value> </property> <property> <name>dfs.datanode.address</name> <value>0.0.0.0:50011</value> </property> <property> <name>dfs.datanode.http.address</name> <value>0.0.0.0:50076</value> </property> <property> <name>dfs.secondary.http.address</name> <value>0.0.0.0:50091</value> </property> <property> <name>dfs.datanode.ipc.address</name> <value>0.0.0.0:50021</value> </property> </configuration>
etc/hadoop/mapred-site.xml
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.shuffle.port</name> <value>13563</value> </property> </configuration>
etc/hadoop/yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>0.0.0.0:8089</value> </property> <property> <name>yarn.nodemanager.localizer.address</name> <value>0.0.0.0:8041</value> </property> <property> <name>yarn.nodemanager.webapp.address</name> <value>0.0.0.0:8043</value> </property> </configuration>
ssh localhost
# 要能够免密登入,否则执行如下: ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
zookeeper-3.4.8
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.8/zookeeper-3.4.8.tar.gz
conf/zoo.cfg
cp conf/zoo_sample.cfg conf/zoo.cfg
# the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/home/yxlin/var/lib/zookeeper # the port at which the clients will connect clientPort=2183 # the maximum number of client connections. # increase this if you need to handle more clients maxClientCnxns=60
kafka_2.10-0.8.2.2
wget https://archive.apache.org/dist/kafka/0.8.2.2/kafka_2.10-0.8.2.2.tgz
config/zookeeper.properties
# the directory where the snapshot is stored. dataDir=/home/yxlin/var/lib/zookeeper # the port at which the clients will connect clientPort=2183 # disable the per-ip limit on the number of connections since this is a non-production config maxClientCnxns=60
config/server.properties
# The id of the broker. This must be set to a unique integer for each broker. broker.id=1 # The port the socket server listens on port=9093 # The number of threads handling network requests num.network.threads=3 # The number of threads doing disk I/O num.io.threads=8 # The send buffer (SO_SNDBUF) used by the socket server socket.send.buffer.bytes=102400 # The receive buffer (SO_RCVBUF) used by the socket server socket.receive.buffer.bytes=102400 # The maximum size of a request that the socket server will accept (protection against OOM) socket.request.max.bytes=104857600 # A comma seperated list of directories under which to store log files log.dirs=/home/yxlin/var/lib/kafka-logs # Zookeeper connection string (see zookeeper docs for details). # This is a comma separated host:port pairs, each corresponding to a zk # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002". # You can also append an optional chroot string to the urls to specify the # root directory for all kafka znodes. zookeeper.connect=localhost:2183
# 查看当前所有topic列表 bin/kafka-topics.sh --list --zookeeper localhost:2181 # 查看topic identity里面的数据 bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic identity --from-beginning
flink-1.0.3
wget https://archive.apache.org/dist/flink/flink-1.0.3/flink-1.0.3-bin-hadoop24-scala_2.11.tgz
注意是要scala_2.11的,而不是scala_2.10
conf/flink-conf.yaml
# The host on which the JobManager runs. Only used in non-high-availability mode. # The JobManager process will use this hostname to bind the listening servers to. # The TaskManagers will try to connect to the JobManager on that host. jobmanager.rpc.address: localhost # The port where the JobManager's main actor system listens for messages. jobmanager.rpc.port: 6124 # The heap size for the JobManager JVM jobmanager.heap.mb: 1024 # The heap size for the TaskManager JVM taskmanager.heap.mb: 1024 # The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline. taskmanager.numberOfTaskSlots: 512 # Specify whether TaskManager memory should be allocated when starting up (true) or when # memory is required in the memory manager (false) taskmanager.memory.preallocate: false # The parallelism used for programs that did not specify and other parallelism. parallelism.default: 2 taskmanager.network.memory.fraction: 0.1 taskmanager.network.memory.min: 67108864 taskmanager.network.memory.max: 1073741824 # The port under which the web-based runtime monitor listens. # A value of -1 deactivates the web server. # jobmanager.web.port: 8084
conf/masters
localhost:8082
conf/zoo.cfg
# The port at which the clients will connect clientPort=2183
HiBench 7.1.1
conf/hadoop.conf
cp conf/hadoop.conf.template conf/hadoop.conf
hibench.hadoop.home /home/yxlin/usr/local/hadoop-2.9.0 # The root HDFS path to store HiBench data hibench.hdfs.master hdfs://localhost:9000/user/yxlin
到hadoop下 bin/hdfs dfs -mkdir /user/yxlin
conf/hibench.conf
hibench.streambench.kafka.home /home/yxlin/usr/local/kafka_2.10-0.8.2.2 hibench.streambench.zkHost localhost:2183 hibench.streambench.kafka.brokerList localhost:9093 hibench.streambench.kafka.topicPartitions 20 hibench.masters.hostnames node1.novalocal hibench.slaves.hostnames node1.novalocal node2.novalocal node3.novalocal
conf/flink.conf
cp conf/flink.conf.template conf/flink.conf
hibench.streambench.flink.home /home/yxlin/usr/local/flink-1.0.3 hibench.flink.master localhost:6124 # Default parallelism of flink job。这里的数字必须小于flink中slot数量 hibench.streambench.flink.parallelism 64 hibench.streambench.flink.bufferTimeout 10 hibench.streambench.flink.checkpointDuration 1000
若遇到版本问题,可能的冲突在于hive其中的guava.jar和可能hadoop中的guava.jar冲突了,这个时候一中解决方法是删除低版本的,换上高版本的
hive在Hibench位置是配置定义的
/home/yxlin/usr/local/hadoop-2.7.6/share/hadoop/common/lib/guava-11.0.2.jar
/home/yxlin/HiBench/hadoopbench/sql/target/apache-hive-3.0.0-bin/lib/guava-19.0.jar
hibench.hive.home ${hibench.home}/hadoopbench/sql/target/${hibench.hive.release} hibench.hive.release apache-hive-3.0.0-bin hibench.hivebench.template.dir ${hibench.home}/hadoopbench/sql/hive_template hibench.bayes.dir.name.input ${hibench.workload.dir.name.input} hibench.bayes.dir.name.output ${hibench.workload.dir.name.output}
Hibench中数据集可以定义:
# Data scale profile. Available value is tiny, small, large, huge, gigantic and bigdata. # The definition of these profiles can be found in the workload's conf file i.e. conf/workloads/micro/wordcount.conf hibench.scale.profile tiny
Get Start
start Hadoop
cd $HADOOP_HOME # bin/hdfs namenode -format 只需要执行一次 sbin/start-dfs.sh sbin/start-yarn.sh # jps 一定要看到DataNode,NameNode,SecondaryNameNode,ResourceManager在运行 # sbin/stop-all.sh 关闭程序
start Zookeeper
cd $ZOOKEEPER_HOME bin/zkServer.sh start
start Kafka
cd $KAFKA_HOME bin/kafka-server-start.sh config/server.properties
start Flink
cd $FLINK_HOME bin/start-cluster.sh #bin/stop-cluster.sh
build Hibench(执行一次)
cd $HIBENCH_HOME # 官方的github文档上Build HiBench指出是-Dhadoop=2.4有用的,但是实际上会报错...,手动改下pom.xml mvn -Dspark=2.4 -Dhadoop=2.4 -Dhive=0.14 -Dscala=2.11 clean package
本文作者:次林梦叶
本文链接:https://www.cnblogs.com/cilinmengye/p/18337118
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
2023-08-01 CAIP----2023省赛
2022-08-01 用贪心解决的区间问题