CSAPP Malloc Lab

知识点
- Physical Address (PA)
- Virtual Address (VA)
- Memory Management Unit (MMU):利用存放在主存中的查询表来动态翻译虚拟地址。
- Virtual Page (VP):VM系统通过将虚拟内存分割为若干大小固定的块,称为虚拟页
- Physical Page(PP):类似上述
- Page Table Entry (PTE)
- Translation Lookaside Buffer (TLB)
知识笔记在这位大佬的【读薄 CSAPP】柒 虚拟内存与动态内存分配已经很详细了
在这里我想要强调平时忽略的几个点
-
虚拟内存的三大作用
作为缓存工具 P561
作为内存管理工具 P565
作为内存保护工具 P565 -
内存与磁盘之间的缓存是全相联的
-
每一个进程都是看到的都是内存映像
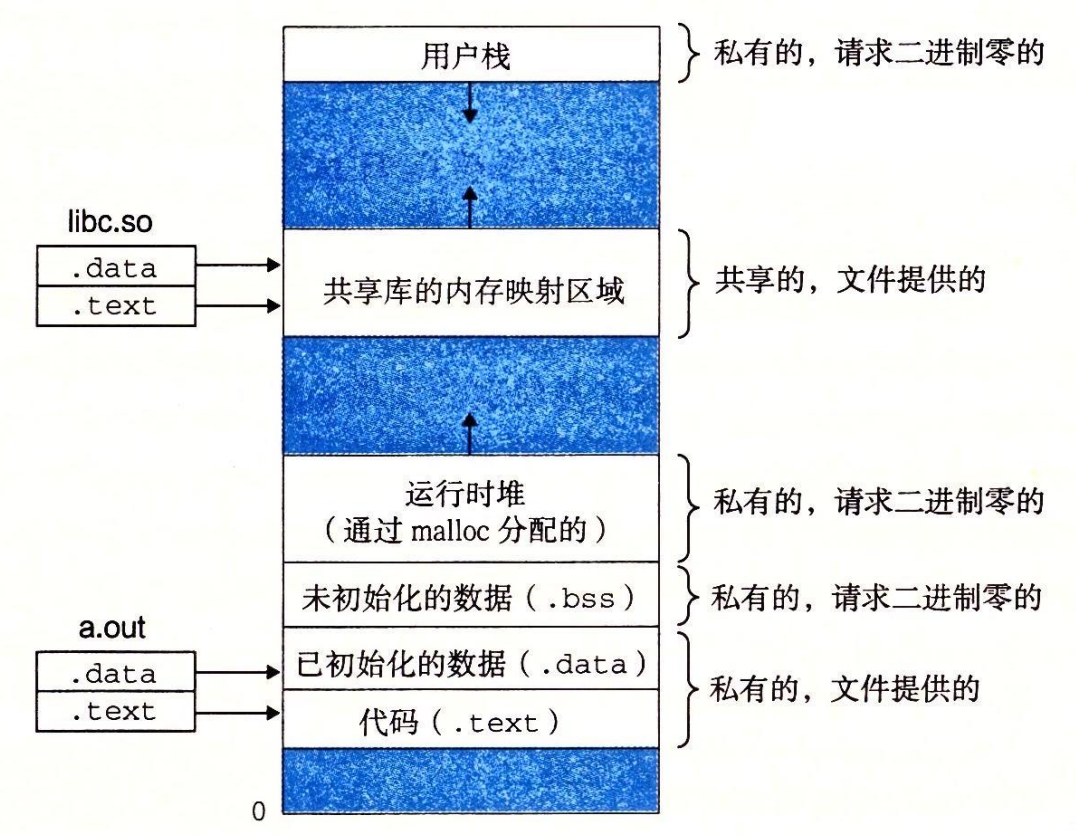
每一个进程都有一个独立的虚拟的运行内存,这个内存我们也可以称为虚拟内存,好像整个存储系统就为这一个进程工作,内存映像如上图,我们在C语言等打印出的内存地址都是这个虚拟内存的内存地址,不是存放在真实物理地址的地址实际上是操作系统为每一个内存都分配了一张页表,这个页表与虚拟内存按页(块)划分后的页(块)一一对应
即虚拟内存按照页大小进行划分空间后,有许多的页,同时页表上有许多页表项,每一个页表项记录了虚拟内存一个页的状态,即页表项和虚拟内存的页是一一对应的
(对你没看错,居然每一个进程都有一张页表,而且页表项的个数与虚拟内存的页的个数相同,那么页表岂不是占很大的空间?同时当有许多进程,自然也就会有许多页表,这么多的页表占空间岂不是巨大?对,这是个问题,在下面的多级页表会减缓这个问题)

当进程在虚拟内存中分配了空间,被分配了空间的页,在页表中的对应页表项就会记录为未缓存,因为这个时候数据还只是在磁盘上占分配了空间,而且将内容放到了真正的物理内存的页,页表中的对应页表项就会记录为已缓存
没有分配空间的页,页表中的对应页表项就会记录为空
-
多级页表是如何节省空间的 P571,P572
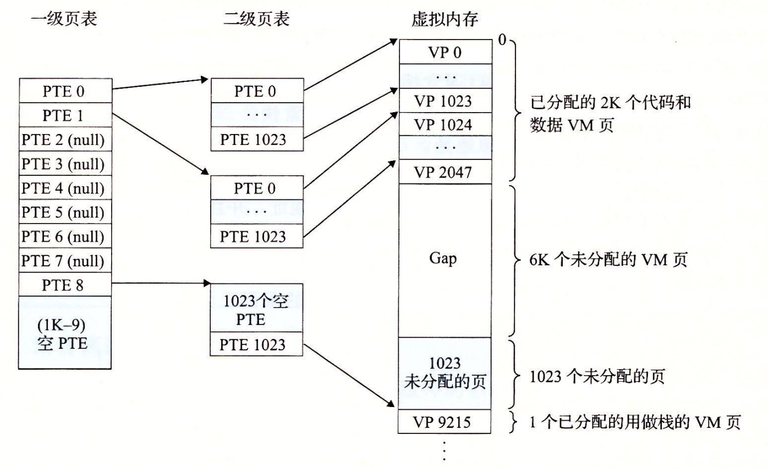
在没有使用多级页表的时候,我们页表项和虚拟内存页的数量是一样多的其实虚拟内存页在很多情况下都是没有数据的,即在页表项中记录为空。花费大量的空间让页表项记录空,这是个很不明智的选择
于是我们就想:能不能尽量不要记录虚拟内存中为空的页?
如上图,假设虚拟内存有4GB,每一个页有4kB,那么总共有
4GB / 4KB = 2^20 = 2^20 = 1024 * 1024 = 1M个页我们让1级页表中每一个页表项指向一个有
1024个页表项的页表,即2级页表2级页表每一个页表项都能与虚拟内存中的一个页对应,即需要
1M / 1024 = 1024个2级页表,即也需要1024个以及页表项
这个时候你肯定会灵魂发问了,咋我的页表项还比不用多级页表时更多了呢?不要急,仔细看看上图,当虚拟内存的页大量为空时,那么我们的二级页表也就没有必要要创建了
代价是一级页表对应的页表项上为空,但是牺牲1级页表一个页表项的空间,能够换来没浪费一整个2级页表(1024个页表项)的空间。
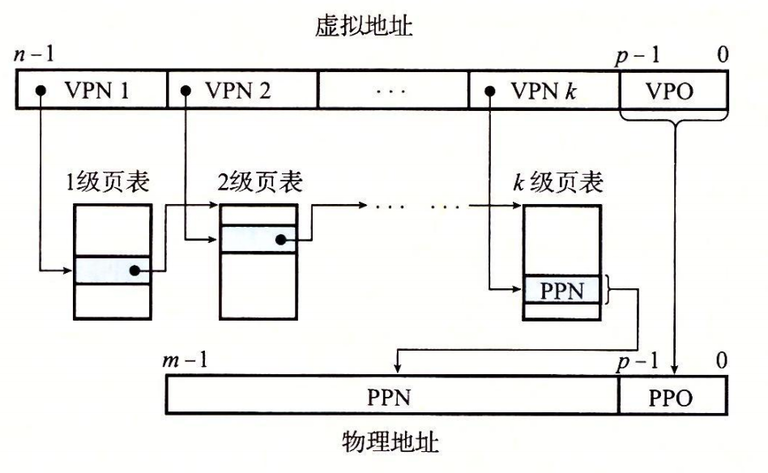
首先我们要知道页表是保存在物理内存的,每次地址翻译硬件将一个虚拟地址转化为物理地址时,都会读取页表,CPU中的一个控制寄存器,页表基址寄存器(Page Table Base Register, PTBR)指向当前的一级页表
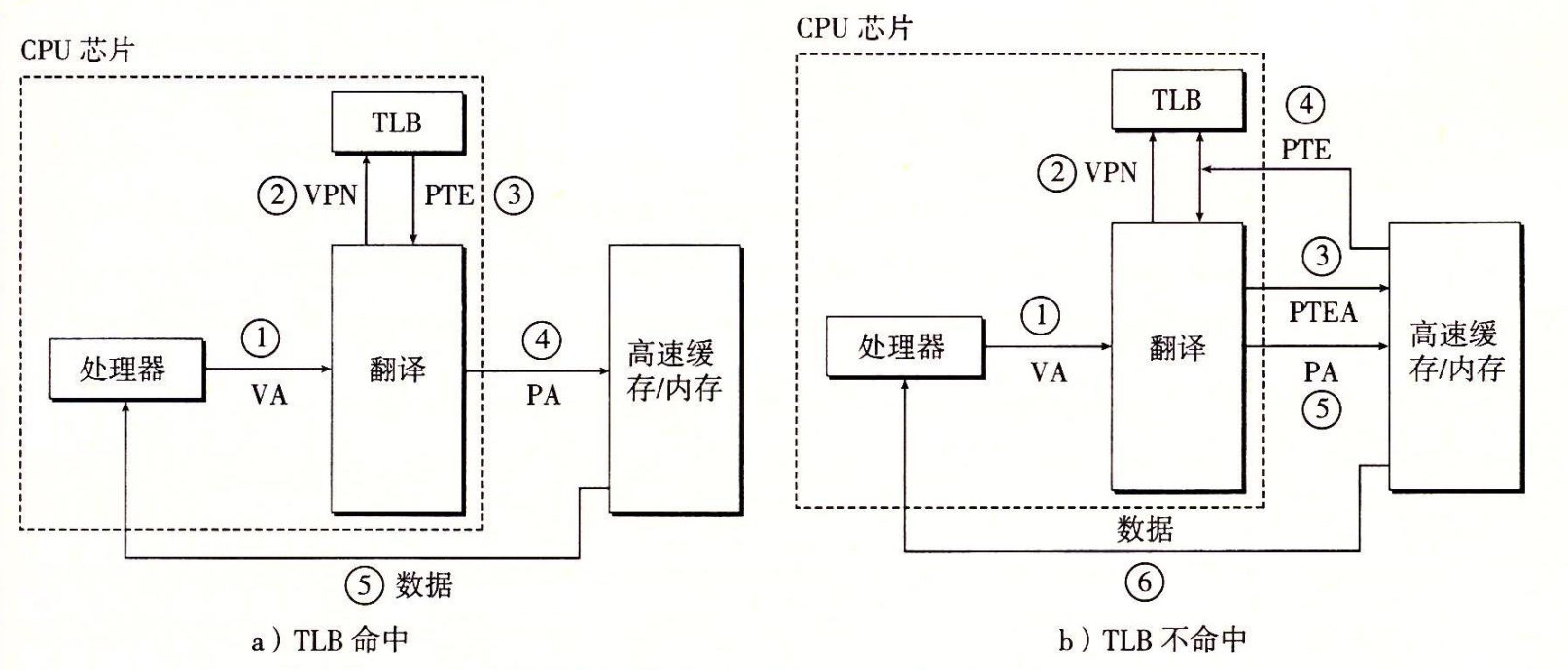
当 TLB 不命中时,MMU 必须从 L1 缓存中取出相应的 PTE,如图 9-16b 所示。给出一级页表地址PTEA,然后获得新的PTE,存放在 TLB 中,可能会覆盖一个已经存在的条目。
更加具体地的图为:
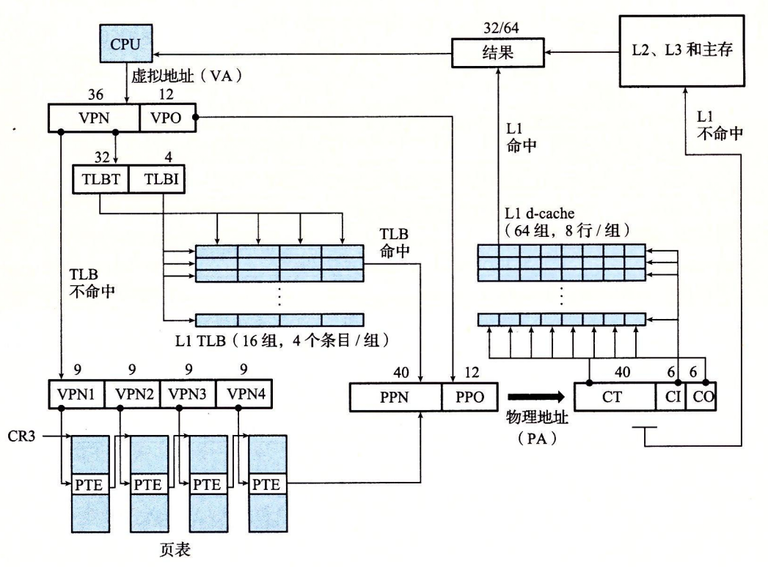
CR3控制器指出第一级页表的起始位置。其值是每个进程上下文的一部分,每次上下文切换时,CR3的值都会被恢复。
其中物理地址PA会被转化为CT CI CO,是因为接下来要访问高速缓冲了:
-
CT:高速缓存标记
-
CI:高速缓存索引
-
CO:高速缓存块内的字节偏移量
思考过程
-
mm_init:calls mm_init to perform any necessary initializations, such as allocating the initial heap area.
-
mm_malloc: The mm_malloc routine returns a pointer to an allocated block payload of at least size bytes.
Since the libc malloc always returns payload pointers that are aligned to 8 bytes, your malloc implementation should do likewise and always return 8-byte aligned pointers.
-
mm free
-
mm realloc
编写malloc函数,动态内存分配
分配器遇到的主要问题:
-
对齐块。
分配器必须对齐块,使得他们可以保存任何类型的数据对象。
在x86-64中,malloc返回的块的地址总是16的倍数
-
分配器的性能目标,最大化吞吐率和最大化内存利用率是相互冲突的。我们要在这之间权衡
-
碎片
内部碎片:一个已分配块比有效载荷大时发生的。如分配器可能增加块大小以满足对齐要求
外部碎片:空闲内存合并起来足够满足一个分配请求,但是没有一个单独的空闲块足够大可以来处理这个请求时发生的。
分配器往往采用启发式策略来试图维持少量的大空闲块,而不是维持大量的小空闲块
分配器主要操作:
- 空闲块组织:如何记录空闲块
- 放置:如何选择空闲块进行分配
- 分割:如何处理空闲块被分配后的剩余部分
- 合并:如何处理刚刚被释放的块
解决方法
-
空闲块组织:
-
空闲块通过显式链表法单独组织成一个双链表
-
分配块通过隐式链表法记录块大小


-
左边的隐式链表法,右边的为显式链表法
通过头部和尾部,我们能够清楚的知道每一个空闲块/分配块的大小。
在显式链表法中,通过前后指针,我们加快选择合适的空闲块
我规定双链表是按照空闲块大小从小到大组织的,即每一次插入双链表时间是O(n)的
-
放置:
我使用首次适配法,因为我的空闲块双链表是从小到大组织的,所以这里使用首次适配也就是最优匹配
-
分割:
如果一个空闲块分配后多出来的空间我可以再生成一个空闲块,那么就分割。
因为我生成一个空闲块需要加上头部和尾部以及前后指针,一个指针类型的数据是8B。、
-
合并:
通过头部和尾部(都记录了是否分配和块大小的信息)完成合并。
在mm_init时,我们需要设置序言块和结尾块,这两个块都设置为已分配,但是没有数据。这两个块的作用是避免在合并时对堆的边界进行复杂的判断
缺陷
这种方法在放置和空闲块组织这两个步骤执行的还是太慢了
使用分离适配法上述过程会快很多,而且而且相比普通显式空闲链表法,每一个空闲块可以少一个Pred指针,即可以让允许是空闲块的最小空间变小,这样可以提高空间利用率
实验
先上结果
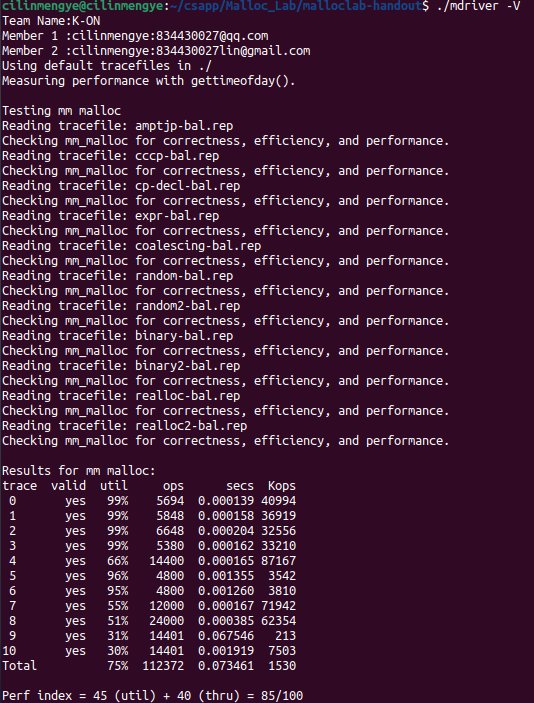
所实话,这个结果我是很满意的,因为我的方法居然比网络上一些用分离适配法实现的空闲列表分数差不多,甚至还要高
吐槽
测试文件在官网上没有给全,就给了short1,short2这两个测试文件。其他的还要自己去找...

.rep文件全部应该如上图
还需要注意下运行./mdriver -V测试全部文件的时候记得改下在mdriver.c中默认的测试路径,改成.rep文件放的位置
全部测试文件在我这个实验的github上,最后会给出
思路
我采用的思路是空闲列表通过显式空闲链表进行管理
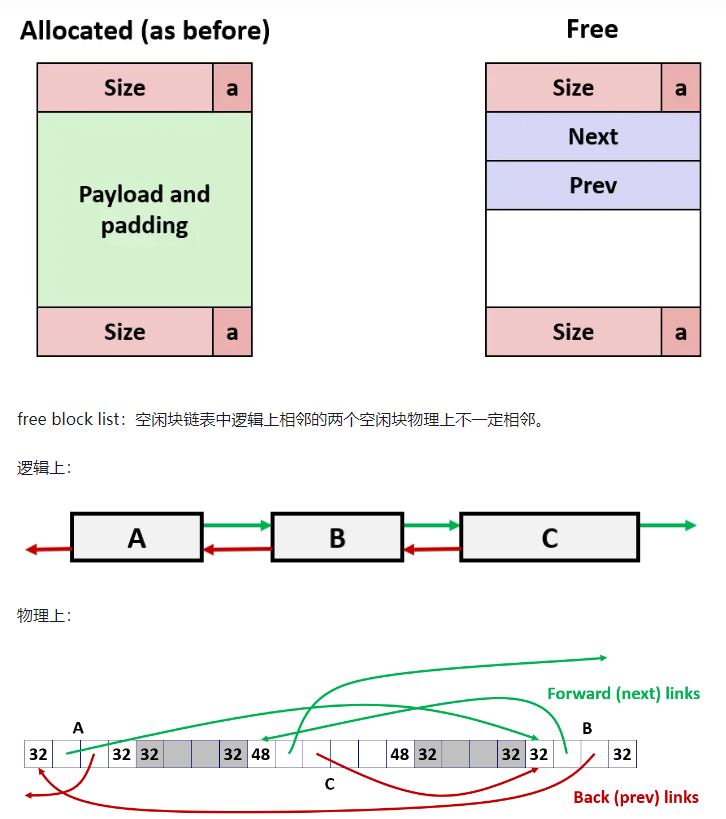
同时我的链表是按照空闲块从小到大排序的,每一次插入新的空闲块最坏要O(n/2)的时间复杂度
然后查找空闲块用的是首次匹配
想一想我既然维持空闲块在链表中从小到大排序了,首次匹配不就是最优匹配吗?
关于空闲块中Pred指针和Succ指针大小的问题
在书上P603有更容易理解的图
我看到一些博客中居然给Pred和Succ只分配一个字节的大小,他们是存放堆某个地方的地址的,地址在64位机器上应该有64位吧,那么也就是要给他们每一个分配8字节大小的空间才对。
为什么在写之前我没有考虑用分离适配法
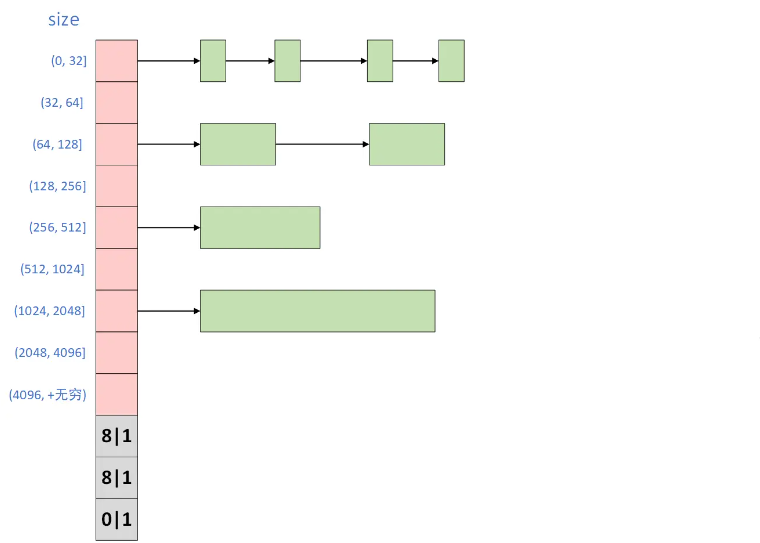
分离适配法的形象说明如上图,为每一个存放空闲块按照块大小分个区间,同时以每一个区间都用链表来管理,这样可以加速搜索空闲块
而且相比普通显式空闲链表法,每一个空闲块可以少一个Pred指针,即可以让允许是空闲块的最小空间变小,这样可以提高空间利用率
但是想一想,每一个区间我要分配一个8字节的空间用于装载地址,总共有9个区间,也就是我要预先分配9*8=72字节空间,这些空间是不能用于装载其他数据的
想想就很浪费,但是再仔细想想,当我们空闲块很多时,这点浪费就微不足道了(当时没想到测试数据有些分配的空闲块是真的多,导致后面有些测试我用显式空闲列表法有点吃亏了)
我的方法如果还有优化我会选择 分离适配法 + 每条链表维持从小到大按照空闲块大小排序 + 首次匹配
BUG
我为了提高空间利用率,我在写链表的时候是没有用传统数据结构中加两个"哨兵"的,这导致我在链表执行插入,删除时很容易遇到bug
只能说具体bug在代码中是不断调试,修改才能知道的
我的具体调试方法没有按照教程上写一个mm_check函数,但是我写了个打印链表的函数,这样当测试时如果发生了段错误或者其他错误,我就知道最容易出错的链表是否发生了错误:
//调试函数
static void printfBlock(void *bp)
{
printf("空闲列表中的块%lx: SIZE:%d, ALLOC:%d, PRED:%lx, SUCC:%lx\n", (unsigned long)bp,
GET_SIZE(HDRP(bp)), GET_ALLOC(HDRP(bp)), GETP(PREDP(bp)), GETP(SUCCP(bp)));
}
//调试函数
static void freelt_status()
{
printf("最前后指针为%lx, %lx", (unsigned long)freelt_hd, (unsigned long)freelt_ft);
if (freelt_hd == NULL || freelt_ft == NULL){
printf("空闲列表为空\n");
return ;
}
if (freelt_hd == freelt_ft){
printf("空闲列表有一个块\n");
printfBlock(freelt_hd);
return;
}
int cnt = 0;
printf("整个列表为:\n");
for (void *i = freelt_hd; i != NULL; i = TOVOID(GETP(SUCCP(i)))){
printf("%d :", cnt);
printfBlock(i);
cnt++;
}
printf("整个列表结束\n");
}
Code and TestTrace
FIN
CSAPP系列算是完成了,正好历经1个月我学完了Computer Systems A Programmer's Perspective (CSAPP)
你的网络编程和并发那章呢?
咳...在课程计算机网络和操作系统的时候已经学习过了
这里放上我平时除了课本外,其他的网络资源

