编译原理--有穷自动机

有穷自动机
我们学习完后应该能够做到一件事:
正则表达式->NFA->DFA->识别
正则表达式->NFA
教程的P55和P56,57有详细过程
其实在真正考试的时候按照这个教程上写,当正则表达式有点复杂的时候,我们的ε会有点多,同时状态也有点多,这会导致下面将NFA->DFA有点复杂
我们可以简写,比如写a*的时候不按照教程上,而是就只简单地
NFA->DFA
- 子集法
教程的P50,51,52有详细过程,但是不清楚,可以看如下两篇博客:
博客1
博客2
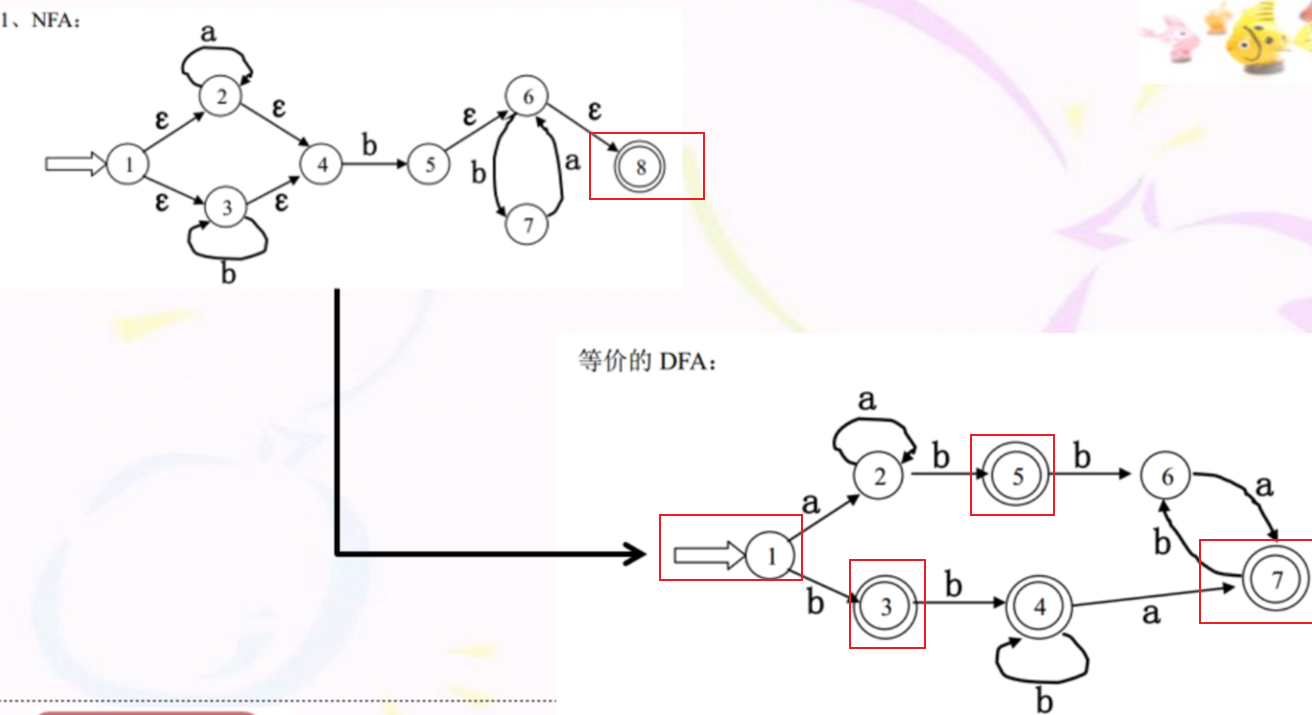
步骤一:从开始状态开始,将开始状态能够通过ε到达的所以状态加入集合,这个集合是我们DFA的开始状态A
步骤二:以开始状态A开始,对其中每一个状态元素,for 循环我们的输入集合,如{a,b,c,d....}
假设我们现在取出了状态集合A中的状态0,输入集合中的输入字符a
我们现在要看的就是0通过a到达哪些状态,同时到达的这些状态通过ε又可以到达哪些状态
注意我们可能会遇到一个情况如:状态1有两条边,1通过a到达2,1通过ε到达3(2没有ε的边,2不能到达3),如果这个时候我们有一个状态B={1},然后ε-closure(move(B,a))中是否有3呢?
答案是没有的,我们要按照书上定义的来:move(B,a)={2},然后ε-closure({2})={2}
所以是不会有3的
总的来说,我们将通过输入字符到达的状态和这些状态通过ε到达的状态 当做一个子集
我们将这个子集作为DFA的新找到状态B
然后我们将这个状态加入队列queue
每一次我们都取queue中的状态来更新出新的DFA的状态
(有点像BFS?)
总的来说,我们还是要填一个状态矩阵
| DFA状态\输入集合 | a | b | ... | z |
|---|---|---|---|---|
| A | C | D | ... | B |
| B | A | C | ... | |
| ... | ... | ... | ... | ... |
然后我们就要开始画图了,注意:要标注出开始状态和终结状态,在DFA中的终结状态是包含NFA中终结状态的集合。
即我们通过ε-closure(move(xxx,xxx)) 得到的NFA状态集合,其DFA的一个状态,如果这个NFA状态集合包含了NFA的终结符号,那么在DFA中这个状态就是终结状态。
如下:
- 分割法
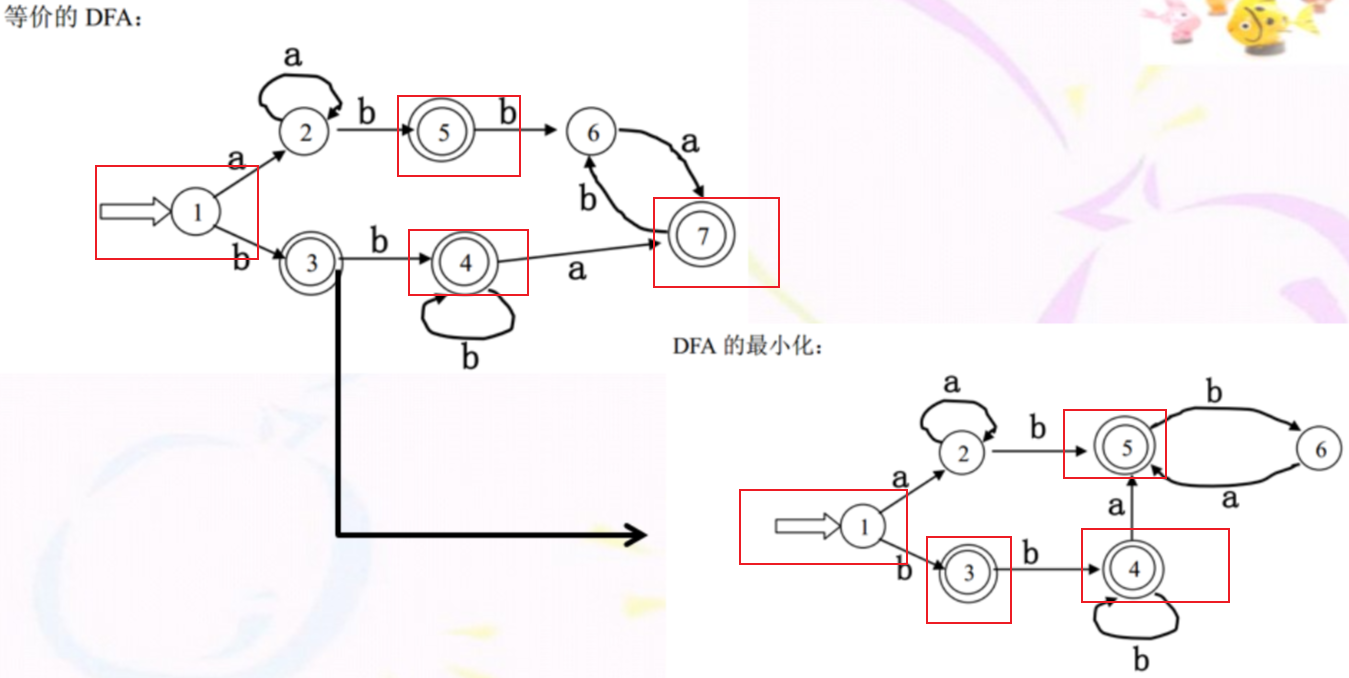
这个方法主要是用来化简DFA的图
化简包括消除无用状态和合并等价状态(教程P52)
无用状态就是从DFA开始状态无论也到达不了的状态
对于无用状态我们的做法是(从图上看)删除掉这个状态节点同时删除掉它射入和射出的边
等价状态:某两个状态s和t是否等价要根据一致性条件和蔓延性条件(教程P53)
一致性条件:状态s和状态t必须同时为可接受状态(终态)或不可接受状态(非终态和不可达的状态)
蔓延性条件:对于所有输入符号,状态s和状态t必须转换到等价的状态里
比如:假设{0,1,2}{3,4}是两个状态集合
| DFA状态\输入集合 | a | b | c |
|---|---|---|---|
| 0 | 1 | ||
| 1 | 0 | 1 | 0 |
判断一下0,1这两个状态是否等价?
答案是不等价的
0是不能通过a,c到达任何一个状态集合的,但是1可以,根据蔓延性条件,0状态和1状态通过相同的输入符合,但是不能转换到等价状态里,所以0,1状态并不等价
我们现在可以来总结一下,分割法的步骤:
-
去除不可达的状态:即我们通过NFA->DFA这个过程画出来的 状态转换表,我们查看状态转换表,看看哪个状态是不能通过任何状态到达的 P53,找到了将这个状态去除
-
将目前剩余的状态依据 是否为终态进行划分,这个时候应该得到了两个状态集。
然后我们再通过输入符号,判断集合中的状态是否能够都能够到达相同的状态集中,不能则将这个状态从这个状态集中分离,加入与之等价的状态集中(没有则新开个状态集)。 -
最后我们得到若干个状态集,将这些状态集重新编号,按照原始的状态转换表再画出一副新的状态转换表出来
-
然后我们要开始画出DFA图来了,注意:要标注好终态和开始状态,与NFA->DFA一样的上,如果新的DFA状态包含原来DFA状态终态,那么这个DFA状态也是终态,包含原来DFA开始状态的为开始状态
如:
DFA->识别
教程P48有详细过程,其实就是根据DFA画出状态矩阵图,然后有手就行
有穷自动机(finite state automata)是一个识别器,它对每个输入的字符做识别和判断,以确定其能到达的最终状态或状态集和路径,有穷自动机分为两类,即不确定的有穷自动机NFA和确定的有穷自动机DFA.


首先要重点区别一下DFA和NFA:
- DFA的初态是唯一的,而NFA不唯一
- DFA和NFA的终止状态集都可以为空
- DFA无法接受空串,但是NFA可以

还需要注意的是:有穷自动机可识别的语言是无穷的,但是状态却是有穷的
关于DFA和NFA的终止状态集都可以为空的讨论

结合上面解释举一个例子:
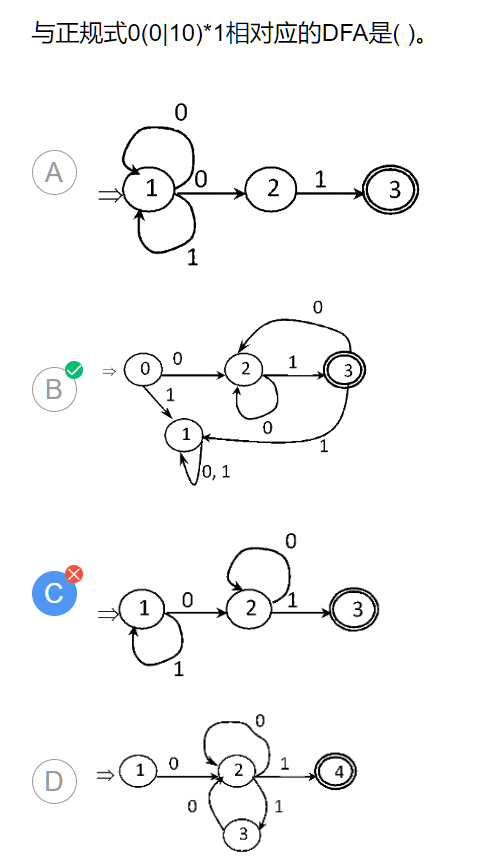
可以看到答案B中状态1是一个"死路",即进去了就出不来了,也就是说这条路走不通,不能往这里走

这里写错了,按照教程上的说法应该是到S的幂集
所谓幂集是:

举一个例子:
f(0,a)={0,3} f是转换函数,这种情况只有NFA才存在
因为DFA是经过转换函数后到原来的S集合元素中,只有NFA才有可能通过转换函数到原来的S集合元素组成的子集中去(教材P49)
读书随记
下面我们来到了词法分析这里,回顾下上次我们看的应该是文法。
我们说过一般涉及到语法树的,用的是上下文无关文法(即2型文法),因为语法树是下面我们进行语法分析时常常用的,所以在语法分析中我们用的基本是上下文无关文法
这里词法分析,我们用的是正规文法,他是单词形式化的描述工具,因为通过正规文法很容易地得到正规式(正则表达式),通过正则表达式我们可以构造出NFA和DFA出来。
通过正规文法得到的正规式也被称为正则表达式
然后的内容就是正规文法和正则表达式之间进行相互转换了(记得看看PTA上作错的作业)
DFA和NFA M是一个五元组:
M=(K,∑,f,S,Z)
K是有穷集,即表示状态机的状态
∑是输入符号集合
f是状态转换方式,如f(S,a)=U 表示状态S通过a到达状态U
S是初态,在DFA这里只要一个初态,在NFA是个集合
Z是终态,在DFA和NFA都是个集合
DFA的某个状态通过某个输入符号到达的状态是唯一的,但是NFA不是这样的
想下文法 G=(Vn,Vt,f,E),是四元组
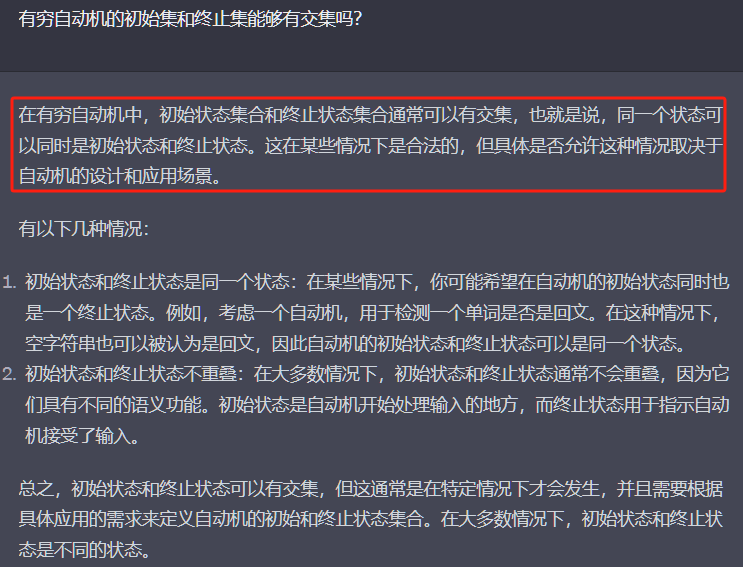
对于这种题目我的建议是先通过NFA求出正规式来,再通过正规式求出正规文法
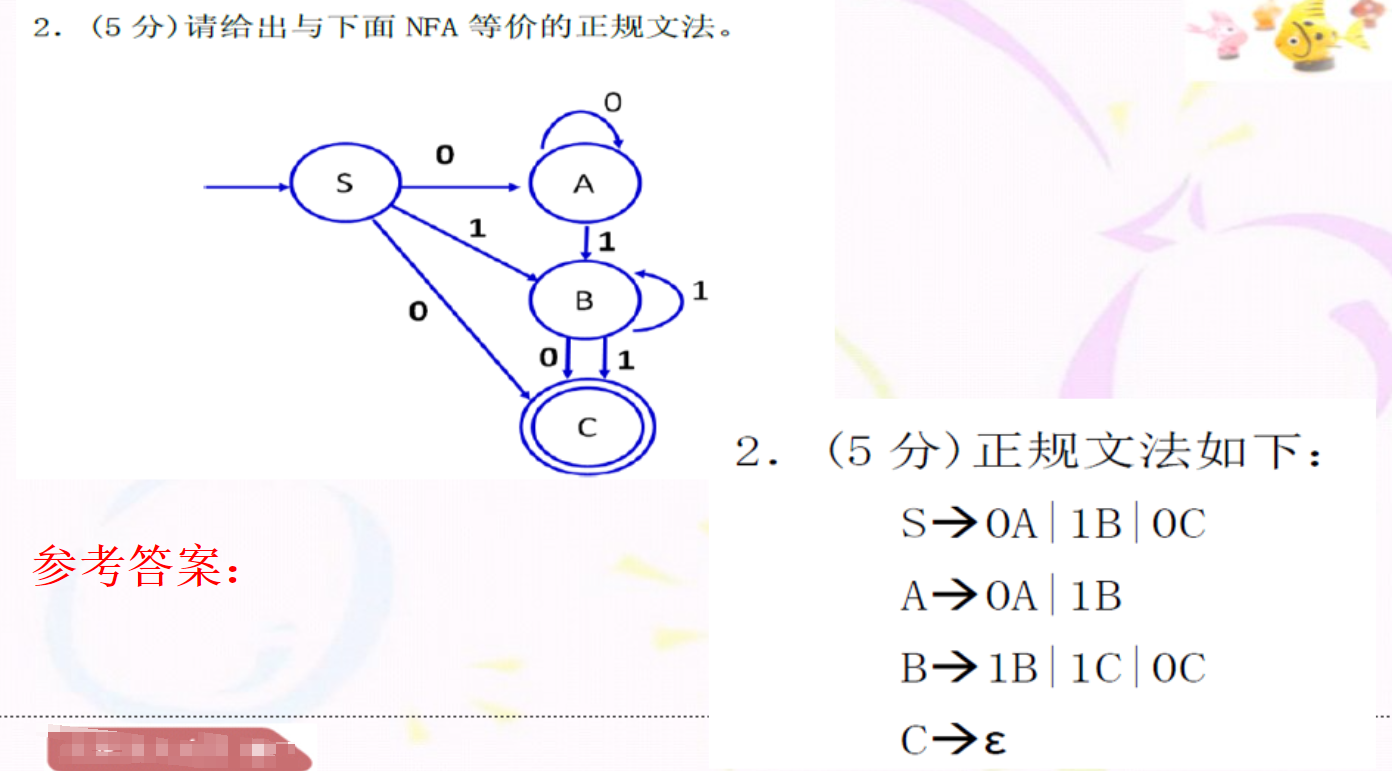
关于构造NFA时的简写方式
我们知道当我们通过正规式得到NFA时,如果NFA按照书上的方式构造,则状态太多,空也会很多,这将给我们再NFA->DFA时造成十分大的麻烦
下面一道例题给出简写方式:
可以看到,这里他将1,变成了自旋
将(01) 变成了两个节点之间相互转换的方式
这样节点非常少,很好些
同时需要注意下第3问,可以发现在第2问的DFA中A,B,C,D都是终结状态,A还是开始状态
根据书上P53,两个状态是等价则两个状态必须同时为可接受状态(终结状态)和不可接受状态;
根据上述这点,我们可以首先将{A,B,C,D}放在一个集合中
然后我们再根据 对于所有输入符号,两个状态必须转换到等价的状态里来进一步划分集合
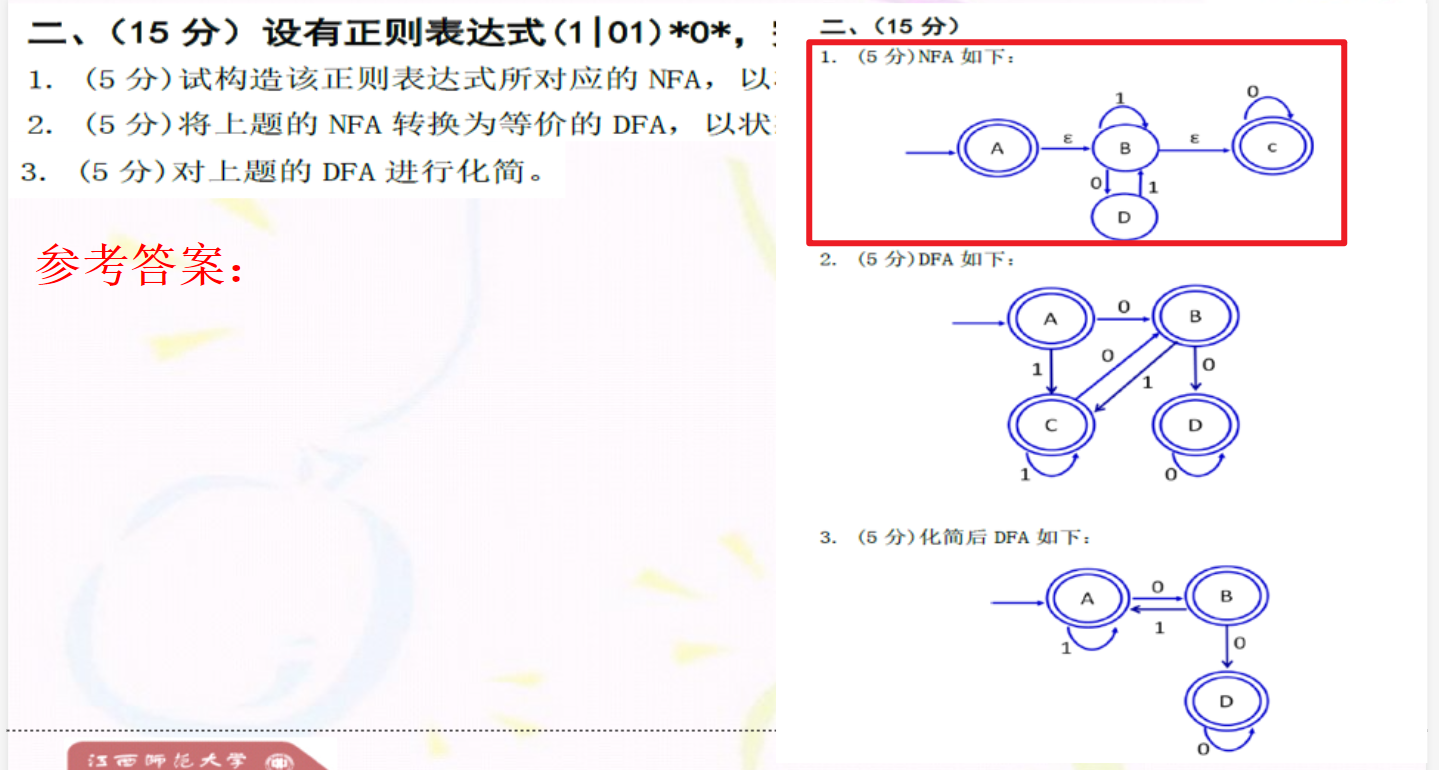
一个比较神奇的地方:
我们知道在NFA->DFA时,我们需要将NFA的状态“打包”成集合当做DFA的状态,如果这个集合中含有NFA的终结状态,那么DFA也为终结状态,但是如果含有NFA的开始状态,那么DFA不一定是开始状态,DFA的开始状态是NFA的开始状态求ε-闭包 得到的。
比如下面这个题目:
像这种可以重复到开始符的NFA,一定到后面转化为DFA时,有较多个NFA的集合是包含NFA开始状态1的,但是DFA的开始符只有一个,即NFA的开始状态求ε-闭包 得到的。
本文作者:次林梦叶的小屋
本文链接:https://www.cnblogs.com/cilinmengye/p/17773718.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步