JXNU数据库_数据库基本SQL操作

基本表的定义,删除和修改
1. 定义基本表(CREATE TABLE):
要在数据库中定义一个新的基本表,你可以使用 CREATE TABLE 语句。以下是一个创建名为 "Employees" 的基本表的示例:
CREATE TABLE Employees ( EmployeeID INT PRIMARY KEY, FirstName VARCHAR(50), LastName VARCHAR(50), Department VARCHAR(50), Salary DECIMAL(10, 2) );
在上述示例中,我们创建了一个名为 "Employees" 的基本表,它包含了 EmployeeID、FirstName、LastName、Department 和 Salary 等列。
约束
在关系数据库中,主键约束、外键约束、UNIQUE约束和CHECK约束是用于维护数据完整性和约束的重要工具。以下是它们的创建和应用的基本概念:
1. 主键约束(Primary Key Constraint):
- 主键约束用于唯一标识表中的每一行数据,并确保每个值都是唯一的。
- 主键约束可以由一个或多个列组成,这取决于表的设计。
- 主键列的值不能为 NULL。
- 主键约束通常用于连接表之间的关系,以及快速查找和定位表中的特定行。
- 创建主键约束的SQL语句示例:
CREATE TABLE Students ( StudentID INT PRIMARY KEY, StudentName VARCHAR(50) );
复合主键
主键约束可以由一个或多个列组成,这被称为复合主键(Composite Primary Key)。复合主键在表中唯一标识每一行,而不仅仅是一个单一的列。下面是一个示例,展示了如何创建一个由多个列组成的主键约束:
假设我们有一个名为 "Orders" 的表,用于跟踪订单信息,其中一个订单可以由多个产品组成。在这种情况下,我们可以使用 "OrderID" 和 "ProductID" 两个列组成复合主键,以唯一标识每个订单中的每个产品。
CREATE TABLE Orders ( OrderID INT, ProductID INT, Quantity INT, PRIMARY KEY (OrderID, ProductID) );
在上面的示例中,我们通过在 PRIMARY KEY 约束中列出多个列(OrderID 和 ProductID)来创建复合主键。这意味着组合了这两列的值必须在表中唯一,确保每个订单中的每个产品都有一个唯一的标识。
2. 外键约束(Foreign Key Constraint):
外键约束(Foreign Key Constraint)用于定义表与其他表之间的关系,并确保引用表中的值在目标表中存在。外键通常引用目标表的主键列,以确保数据的完整性和一致性。下面以一个具体的例子来说明外键约束的用法和作用:
假设我们有两个表:Customers 表和 Orders 表。Customers 表包含客户信息,而 Orders 表包含订单信息。每个订单都与一个客户关联,这个关系可以用外键约束来表示。
首先,我们创建 Customers 表:
CREATE TABLE Customers ( CustomerID INT PRIMARY KEY, CustomerName VARCHAR(50) );
然后,我们创建 Orders 表,并在其中定义一个外键约束,将 CustomerID 列引用到 Customers 表的主键 CustomerID 上:
CREATE TABLE Orders ( OrderID INT PRIMARY KEY, OrderDate DATE, CustomerID INT, FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID) );
在上述示例中,我们创建了一个名为 CustomerID 的外键列,它引用了 Customers 表的主键列 CustomerID。这表示在 Orders 表中的每个订单记录都必须引用 Customers 表中已经存在的客户记录。
3. UNIQUE约束:
- UNIQUE约束用于确保表中的某列或列组合中的值是唯一的,但不一定是主键。
- 与主键不同,唯一约束允许列中的某些值为空。
- UNIQUE约束通常用于需要唯一性但不需要主键约束的情况。
- 创建UNIQUE约束的SQL语句示例:
CREATE TABLE Employees ( EmployeeID INT UNIQUE, EmployeeName VARCHAR(50) );
4. CHECK约束:
- CHECK约束用于定义列中的值必须满足的条件,以确保数据的有效性。
- CHECK约束可以应用于单个列或多个列。
- CHECK约束可以包括比较运算、逻辑运算、函数等。
- 创建CHECK约束的SQL语句示例:
CREATE TABLE Products ( ProductID INT PRIMARY KEY, ProductName VARCHAR(50), Price DECIMAL(10, 2) CHECK (Price >= 0) );
2. 删除基本表(DROP TABLE):
要删除数据库中的基本表及其所有数据,可以使用 DROP TABLE 语句。请注意,这是一个危险的操作,会永久删除表和数据。示例如下:
DROP TABLE Employees;
上述语句将删除名为 "Employees" 的基本表。
3. 修改基本表(ALTER TABLE):
要修改现有的基本表,你可以使用 ALTER TABLE 语句,它允许你执行多种操作,包括添加、删除和修改列,添加和删除约束等。以下是一些示例:
-
添加列:
ALTER TABLE Employees ADD Email VARCHAR(100); -
删除列:
ALTER TABLE Employees DROP COLUMN Department; -
修改列(例如,修改列名):
ALTER TABLE Employees ALTER COLUMN FirstName First_Name VARCHAR(50);
修改表一列中某些数据,而不是对整列数据进行操作
SQL 中的 UPDATE 操作用于修改数据库表中现有行的数据。它是 SQL 中的数据操作命令之一,常用于更新表中的记录,使其反映实际的数据变化。以下是关于 UPDATE 操作的详细说明:
语法:
UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;
table_name:要更新数据的表的名称。SET子句:指定要更新的列和它们的新值。column1,column2, ...:要更新的列的名称。value1,value2, ...:要设置的新值。WHERE子句(可选):用于指定要更新的行的筛选条件。如果省略WHERE子句,则将更新表中的所有行。
示例:
假设我们有一个名为 "Employees" 的表,其中包含员工的信息,并且我们想要将特定员工的薪水提高:
UPDATE Employees SET Salary = 60000 WHERE EmployeeID = 101;
上述示例中,我们更新了 "Employees" 表中 EmployeeID 为 101 的员工的薪水,将其从原来的值提高到 60000。
我们甚至可以在set中嵌套子查询
UPDATE SC A SET GRADE= (Selct max(grade) from SC B where A.cno=B.cno)
修改表中一行数据
- 添加一行数据:
要使用SQL语句向数据表中添加一行数据,你可以使用INSERT INTO语句。以下是一个示例,演示如何将一行数据添加到名为"Employees"的表中:
INSERT INTO Employees (EmployeeID, FirstName, LastName, Department, Salary) VALUES (101, 'John', 'Doe', 'HR', 55000.00);
- 删除一行数据:
要使用 SQL 语句删除表中的一行数据,你可以使用 DELETE FROM 语句。以下是一个示例,演示如何删除名为 "Employees" 的表中的一行数据:
DELETE FROM Employees WHERE EmployeeID = 101;
- 修改一行数据:
要使用 SQL 语句修改表中的一行数据,可以使用 UPDATE 语句。以下是一个示例,演示如何修改名为 "Employees" 的表中的一行数据:
假设我们要修改员工编号(EmployeeID)为 101 的员工的部门(Department)信息。
UPDATE Employees SET Department = 'IT' WHERE EmployeeID = 101;
索引的建立与删除
在教科书P88~89有集中且详细的教程
数据查询
SELECT DISTINCT Sname NAME,'Year of Birth:' BIRTH,YEAR(GETDATE())-Sage AGE,LOWER(Sdept) DEPARTMENT FROM Student where Sname is not NULL ORDER BY AGE DESC
上述代码中有几个重点:
-
DISTINCT
其是用来去重的关键字,需要注意的是这个关键字需要放到最开头的地方,表示接下来的查找的字段组合不会有重复 -
别名
别名是放在表达式的右边,我们知道每一列都有一个字段名称,当我们写字段用的是表达式的时候,我们需要给其一个别名,其就是这列的字段名。 -
NULL
NULL 是不能用如<=>这一类的运算符进行计算的,我们需要用IS NOT这样的进行处理NULL
如:where name=NULL 是错误的
where name is NULL 才是正确的 -
DESC
降序排序的关键字,默认是升序 -
x BEWTEEN a1 AND a2
这个要顺便说明一下其表示的范围是 a1<=x<=a2
x NOT BEWTEEN a1 AND a2 表示的范围是 x>a2 AND x<a1
一般不用,不如用>=< 这些运算符
LINE 模糊查询与字符匹配
在 SQL 中,LIKE 是一个用于模糊匹配字符串的操作符。它通常与通配符一起使用,以查找与指定模式匹配的文本。LIKE 操作符对于在字符串列中查找包含特定字符或模式的数据非常有用。以下是关于 SQL 中的 LIKE 以及字符匹配的详细介绍:
基本的 LIKE 语法:
SELECT column1, column2 FROM table_name WHERE column_name LIKE pattern;
column1,column2:要选择的列。table_name:要查询的表。column_name:要进行模糊匹配的列。pattern:要匹配的模式,可以包含通配符。
通配符:
-
%:代表零个或多个字符。例如,'a%'匹配以 'a' 开头的任何字符串。 -
_:代表一个字符。例如,'_pple'匹配以任何字符开头,然后是 "pple" 的字符串。 -
where Cname LIKE 'DB_Design' ESCAPE'';
这里ESCAPE是定义转义字符用的
示例:
假设有一个名为 Products 的表,其中包含产品名称(ProductName)列,以下是一些示例用法:
-
查找以 "Apple" 开头的产品:
SELECT ProductName FROM Products WHERE ProductName LIKE 'Apple%'; -
查找包含 "berry" 的产品:
SELECT ProductName FROM Products WHERE ProductName LIKE '%berry%'; -
查找以 "Banana" 结尾的产品:
SELECT ProductName FROM Products WHERE ProductName LIKE '%Banana'; -
查找产品名称的第三个字符是 "a" 的产品:
SELECT ProductName FROM Products WHERE ProductName LIKE '__a%';
注意事项:
-
LIKE是大小写敏感的,这意味着它会区分大小写。如果你想要进行大小写不敏感的匹配,需要使用相应的函数或设置。 -
LIKE操作符的性能可能受到影响,特别是在处理大量数据时。要谨慎使用它,以免影响查询性能。
同时需要注意的是LIKE更加模糊查询的方式可能会导致设置的索引不起作用
如:SELECT sname from student where sname LIKE '_明%'
如果在sname上建立了过了索引,因为索引其实是按照某种排序的方式对数据进行存储,而'_明%'这种查找方式与排序是毫无关系,不能用索引加快速度
如果是这么写:SELECT sname from student where sname LIKE '刘%'
这样到是索引还能够加快速度,因为其可以根据排序快速知道第一个字刘在索引建立的数据结构中哪个地方
聚集函数与GROUP BY分组
聚集函数和GROUP BY 子句是 SQL 中用于对数据进行分组和计算聚合值的重要工具。聚集函数用于计算一组数据的统计信息,例如总和、平均值、最大值和最小值,而GROUP BY 子句用于将数据分成多个组,并在每个组上应用聚集函数。以下是一个详细的案例,说明如何使用这些功能:
假设我们有一个名为 "Orders" 的表,其中包含订单信息,包括订单号(OrderID)、客户ID(CustomerID)、订单日期(OrderDate)和订单金额(Amount)。我们想要分析每个客户的订单总金额以及平均订单金额。
示例数据:
| OrderID | CustomerID | OrderDate | Amount | |---------|------------|-----------|--------| | 1 | 101 | 2022-01-15| 100.00 | | 2 | 102 | 2022-02-20| 150.00 | | 3 | 101 | 2022-03-10| 75.00 | | 4 | 103 | 2022-04-05| 200.00 | | 5 | 101 | 2022-05-20| 125.00 |
使用 GROUP BY 和聚集函数的查询:
SELECT CustomerID, SUM(Amount) AS TotalAmount, AVG(Amount) AS AvgAmount FROM Orders GROUP BY CustomerID;
在上述查询中:
- 我们使用
GROUP BY CustomerID将数据按客户ID分组,这意味着每个客户将形成一个分组。 - 然后,我们使用
SUM(Amount)计算每个分组中订单金额的总和,以及AVG(Amount)计算每个分组中订单金额的平均值。 - 最后,我们选择
CustomerID、总金额TotalAmount和平均金额AvgAmount作为结果列。
查询的结果将是每个客户的订单总金额和平均订单金额:
| CustomerID | TotalAmount | AvgAmount | |------------|-------------|-----------| | 101 | 300.00 | 100.00 | | 102 | 150.00 | 150.00 | | 103 | 200.00 | 200.00 |
如上所示,GROUP BY 子句将数据分成三个组(每个客户一个组),并对每个组应用聚集函数以计算总金额和平均金额。这使得我们能够从原始订单数据中提取有用的汇总信息,以便进行分析和决策。
我们可以使用having 对group by后的聚合函数进行筛选
如筛选出全部学科的平均成绩<80分的学生id与学生姓名
select sca.sno,sa.sname,AVG(sca.grade) meanGrade from sc sca,s sa where sca.sno=sa.sno group by sca.sno,sa.sname having AVG(sca.grade) < 80
需要注意的是having 这里的聚合函数不能用别名
这主要是与数据库实现的不同而不同,有些数据库(如MYSQL较新的版本)可以
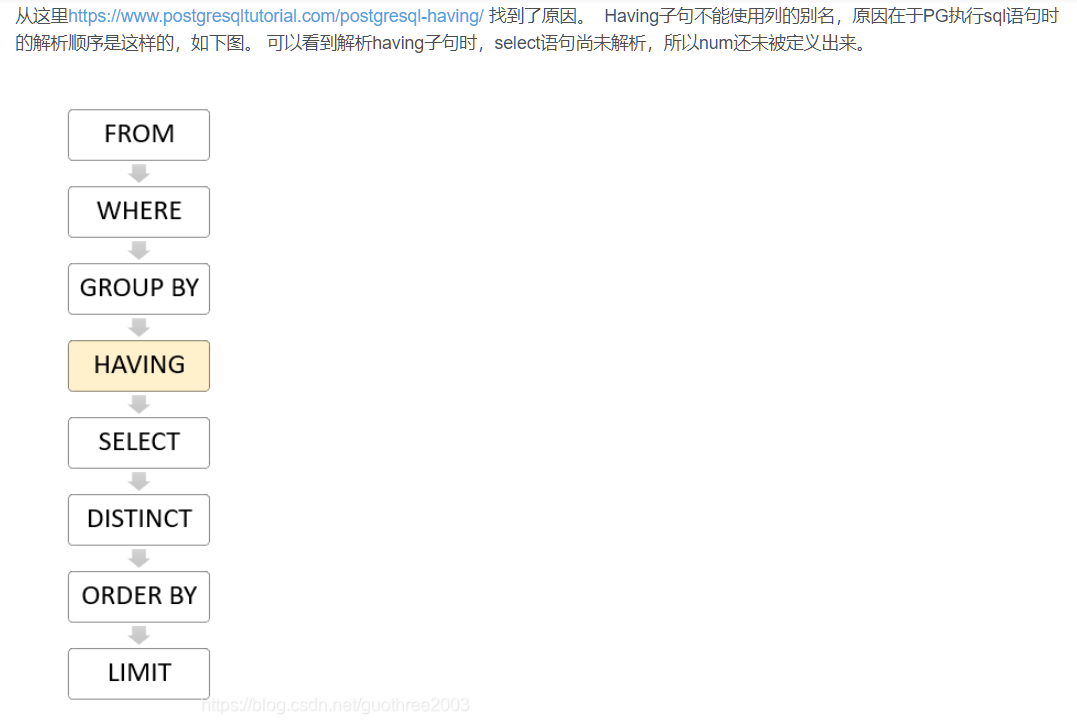
连接查询
连接是SQL中用于联合两个或多个表以检索相关数据的关键操作。以下是对不同类型连接的概念和使用的解释:
-
内连接(INNER JOIN):
- 内连接是最常见的连接类型。它返回两个表中共有的行,基于连接条件。
- 默认情况下使用的就是内连接
-
左外连接(LEFT OUTER JOIN):
- 左外连接返回左表中的所有行和右表中与左表匹配的行。
- 如果右表没有匹配的行,结果集中将包含 NULL 值。
- 左外连接使用
LEFT JOIN关键字。 - 例如,如果你想获取所有员工和他们的部门信息,包括没有分配到部门的员工,你可以执行左外连接,如下所示:
SELECT Employees.*, Departments.* FROM Employees LEFT JOIN Departments ON Employees.DepartmentID = Departments.ID;
-
右外连接(RIGHT OUTER JOIN):
- 右外连接与左外连接类似,但返回右表中的所有行和左表中与右表匹配的行。
- 如果左表没有匹配的行,结果集中将包含 NULL 值。
- 右外连接使用
RIGHT JOIN关键字。 - 例如,如果你希望获取所有部门和他们的员工信息,包括没有员工的部门,你可以执行右外连接。
-
全外连接(FULL OUTER JOIN):
- 全外连接返回两个表中的所有行,包括左表和右表中的匹配行,以及不匹配的行。
- 如果没有匹配的行,结果集中将包含 NULL 值。
- 全外连接通常不是所有数据库系统都支持,但可以使用UNION操作模拟。
- 例如,如果你想获取所有员工和部门的信息,包括没有分配到部门的员工和没有员工的部门,你可以执行全外连接。
-
自身连接:
- 自身连接是连接表中的两个不同行,通常用于在同一表中查找相关的数据。
- 自身连接使用表的别名,以区分两个相同表的不同实例。
- 例如,如果你有一个表存储员工信息,每行包含员工和他们的上级领导的关系,你可以使用自身连接来查找员工及其直接领导的信息。
嵌套查询
NOT EXISTS
在关系代数中我们一般查询全部用÷
在SQL中没有除,我们用双层否定表肯定的形式查询全部
比如:查询选修了全部课程的同学姓名
可以用如下描述:
选择一个同学
对于这位同学不存在某一个课程
对于这个课程不存在这位同学的课表中
即我们这里双层否定了,表示的含义就是这个同学选择了全部课程
不存在,可以用SQL中NOT EXIST表示
我们来看下NOT EXIST的工作过程:


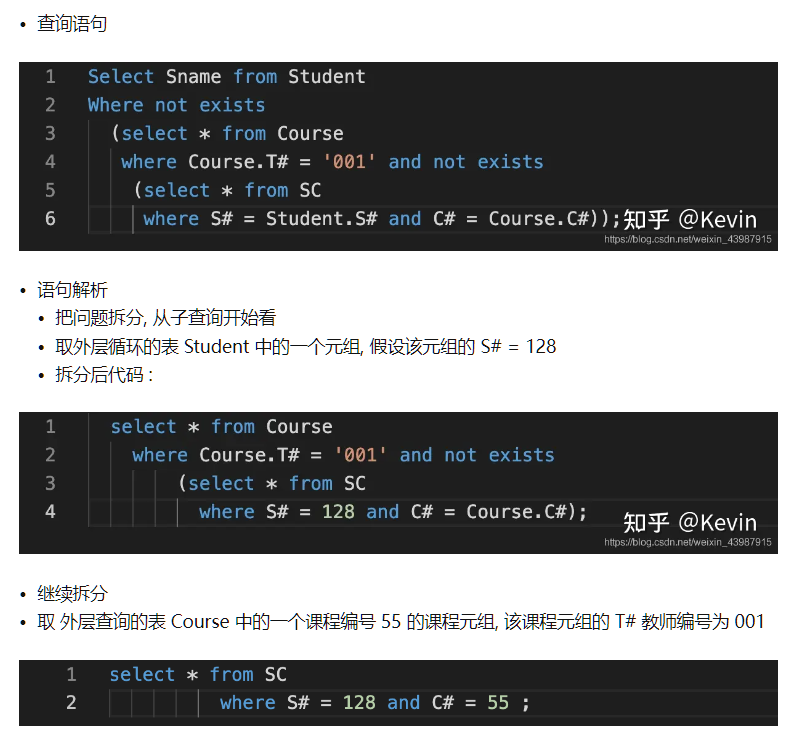
对比
Table 和 View
对于insert into ,Table 和 View操作是一样的
insert into 后不用写Table或View
insert into bname [(...)] values ("常量"...) insert into bname [(...)] select ....
对于Create
在写Create View时
Create View viewName [(...)] AS Select ...
但是Create Table时
Create Table tableName( ... ... )
练习
如何用SQL选择出数值的前k大?
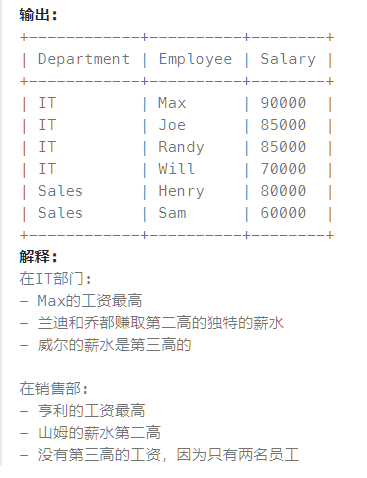
SELECT e1.Salary FROM Employee AS e1 WHERE 3 > (SELECT count(DISTINCT e2.Salary) FROM Employee AS e2 WHERE e1.Salary < e2.Salary AND e1.DepartmentId = e2.DepartmentId) ;
其实可以将嵌套查询看做是for循环
这里有两层嵌套,每一次我们都有相当于从e1中选择一个Salary,for循环地与e2中的Salary进行比较
用count进行计数,结果数值表示若在e2.Salary中比e1.Salary大的个数小于3,那么这个e1.Salary即是前3大
表的多次连接

现在我有如上两张表,我希望将以Trips中的client_id和Users中的user_id一一对应上,同时将banned也对应在应该在的位置
同时对于drive_id也有这个要求
同时还要求banned都是No的,Yes的要删除
最后是一张表上面有client_id,client_banned,drived_id,client_banned这些信息应该如何做?
SELECT * FROM Trips AS T JOIN Users AS U1 ON (T.client_id = U1.users_id AND U1.banned ='No') JOIN Users AS U2 ON (T.driver_id = U2.users_id AND U2.banned ='No')

这个就是JOIN的强大之处了,不但可以进行多次JOIN,还可以加上条件进行连接
关于使用not in需要警惕的地方

解决方法是:
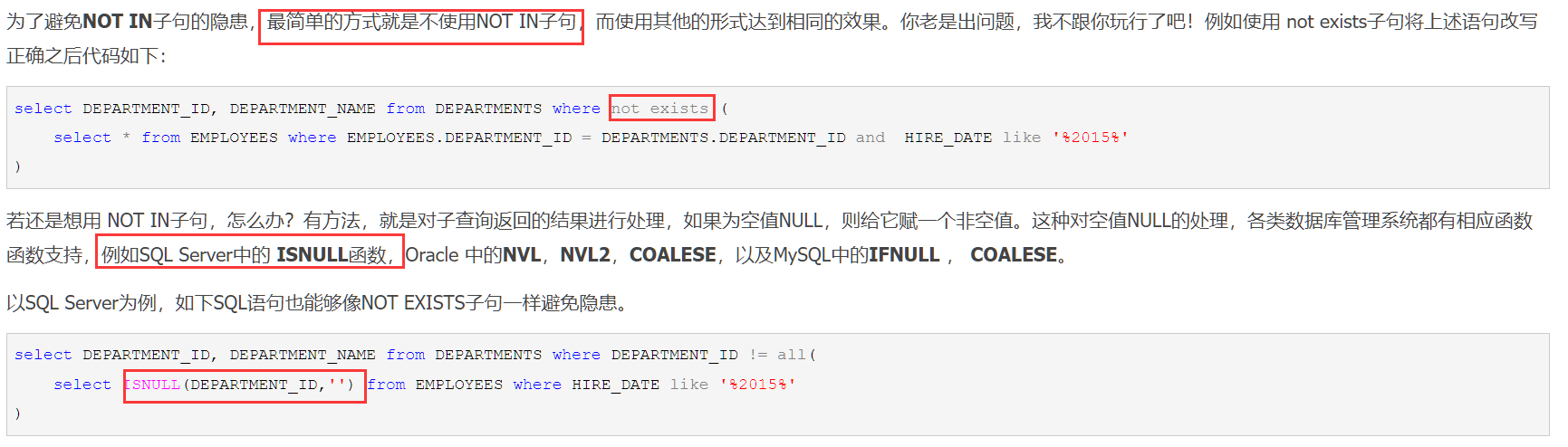
关于使用子查询 需要警惕的地方
子查询的步骤
首先我们要了解一下子查询的步骤:
select Sno,Cno from SC x where Grade>=(select AVG(Grade) from SC y Where y.Sno=x.Sno)
对应上面的SQL代码执行可能步骤是:
- 首先取外循环中的x.Sno,进入内循环
- 在内循环根据以及取出来确定的x.Sno进行查询,得到AVG结果
- 外循环根据结果在进行查询,得到结果保存起来
- 再取外循环下一个x.Sno,重复上述步骤
子查询的引用问题
select v4.id,v4.num from (select v3.id,count(v3.id) num from (select v1.rid id from (select distinct ra1.requester_id rid,ra1.accepter_id aid from RequestAccepted ra1) as v1 UNION ALL select v2.aid id from (select distinct ra1.requester_id rid,ra1.accepter_id aid from RequestAccepted ra1) as v2) as v3 group by v3.id) as v4 where v4.num=(select max(v5.num) from v4 as v5)
上述SQL语句是错误的,会报如下错误:

原因是因为如下代码地方:

这里我在子查询的from中引用了其他子查询结果的别称,这是错误的
解决方法是:
WITH v4 AS ( SELECT v3.id, COUNT(v3.id) AS num FROM ( SELECT v1.rid AS id FROM ( SELECT DISTINCT ra1.requester_id AS rid, ra1.accepter_id AS aid FROM RequestAccepted ra1 ) AS v1 UNION ALL SELECT v2.aid AS id FROM ( SELECT DISTINCT ra1.requester_id AS rid, ra1.accepter_id AS aid FROM RequestAccepted ra1 ) AS v2 ) AS v3 GROUP BY v3.id ) SELECT v4.id, v4.num FROM v4 WHERE v4.num = (SELECT MAX(v4.num) FROM v4);
这里我随便再说一下一次错误点吧:

像这里as Ttable是必须的,否则会报错
关于not in
SQL server中不能使用(in1.lat,in1.log)not in (xxx)这样的写法
但是MYSQL可以,SQL server中只能用not exists代替
SELECT ROUND(SUM(in1.tiv_2016), 2) AS tiv_2016 FROM Insurance in1 WHERE tiv_2015 IN ( SELECT in2.tiv_2015 FROM Insurance in2 WHERE in1.pid != in2.pid ) AND NOT EXISTS ( SELECT in3.lat, in3.lon FROM Insurance in3 WHERE in1.pid != in3.pid AND in1.lat=in3.lat AND in1.lon=in3.lon );
关于having
我们知道当使用Group by的时候后面的字段一定要在Select后出现:
select sno,AVG(Grade) from sc group by sno
但是在使用having的时候后面的字段不一定要在Select后出现
select sno from sc group by sno having AVG(Grade)>=90
一般having都是对聚合函数形成的结果进行筛选的,一般不能够将其对其他字段进行筛选处理,否则会出现不好的结果
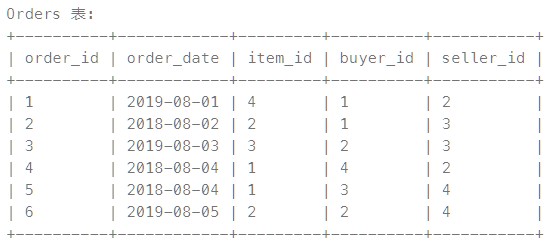
如上我有一张Order表,现在我希望找出在 2019 年作为买家的订单总数。
select od1.buyer_id as buyer_id, count(od1.buyer_id) as buynum,od1.order_date from Orders od1 group by od1.buyer_id having YEAR(od1.order_date)=2019
上述这么写对吗?乍一看挺对的,用having筛选出分组后日期是2019年进行买的buyer_id
但是结果是错误的

发生了什么?buyer_id为1的买家不是在2019年只买了一个物品吗?
原因就出现在

有没有发现od1.order_date是不唯一的,比如buyer_id为2的买家,他在2019年有两个日期进行了购买,但是我们筛选处理的结果上只显示出了一个,这本身从我们的逻辑上就感觉有问题了
所以我们不应该用having 对非聚合函数进行筛选
关于Update利用子查询更新
- 请将‘008’的每门课程的分数都改成该门课程当前的最低分。
对于这个问题,Update SC Set SC.Grade= ?
其实不管是Select 还是 Update 我们都可将最外层当做一个for循环,子查询就是再加一层for循环
Update SC Set SC.Grade=( Select MIN(sc1.Grade) From SC as sc1 Where sc1.Cno=SC.Cno ) Where SC.Sno='008'
我们首先固定最外层的SC,然后在 子查询中 这轮外循环的SC.CNO为定值,然后我们查找这门课程中的最小值,然后进行更新
本文作者:次林梦叶
本文链接:https://www.cnblogs.com/cilinmengye/p/17752659.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步