操作系统----虚拟化
《中断----最初的并发》

《中断上的并发》

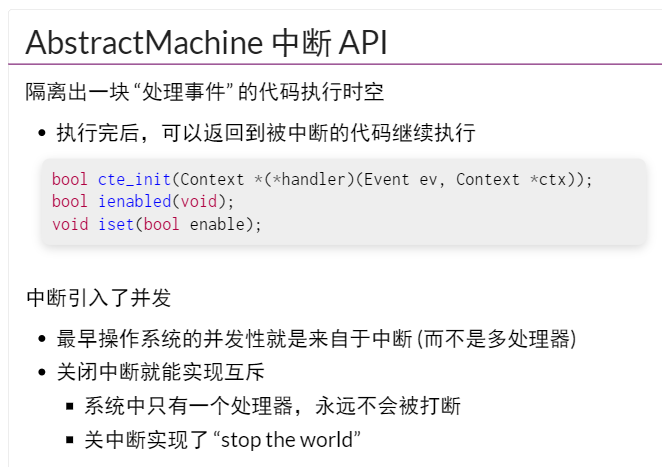
如图这一段代码上,当在os_main函数中正好lock()结束后
突然发生中断 ,执行on_interrupt中的中断处理代码
然后其中也试图lock(),但是这把锁已经被得到了
这样等待os_main中unlock()才能继续
但os_main中要unlock,必须等on_interrupt结束才行
于是死锁了
《中断中的上下文切换》

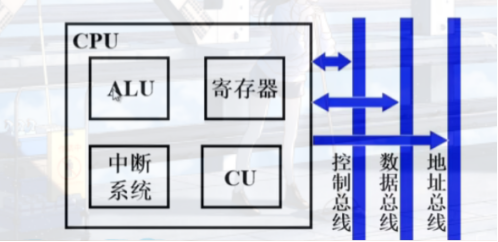

我们知道CPU长成上面这个样子
其中有许多的寄存器
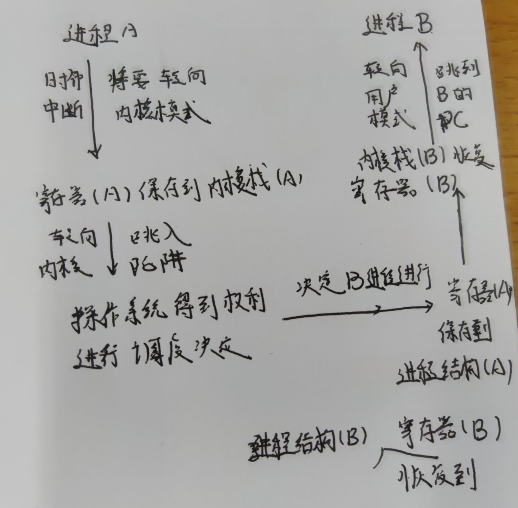
当中断发生时要切换线程,如果还想继续执行原来的程序
那么即原来的数据一个都不能变
当CPU去处理其他线程时,寄存器中的数据毫无疑问会改变
所以我们首先就要将寄存器中的数据保存下来,保存到哪呢?
内存!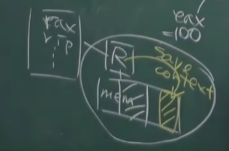
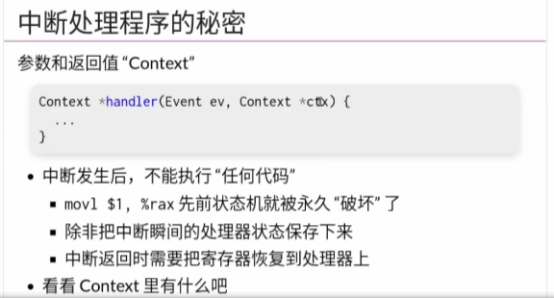
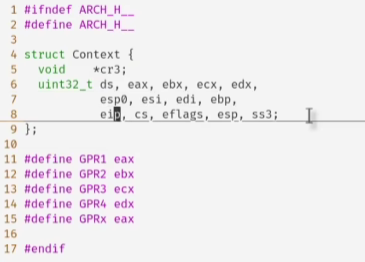
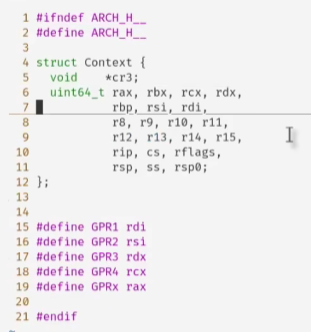

这个返回值是内存的地址,其保存了寄存器数据
寄存器 rip指向程序的代码
rsp指向程序(线程)的堆栈
程序(线程)需要的数据
上述都在内存中,代码和数据是共享的,堆栈是独用的
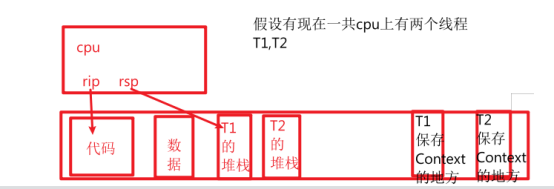
现在cpu中的寄存器是指向了内存中属于T1的部分
当中断发生,cpu中寄存器的数据保存到
然后要切换到T2时 ,从将数据Copy到cpu的寄存器中即可
,从将数据Copy到cpu的寄存器中即可
具体代码<-----

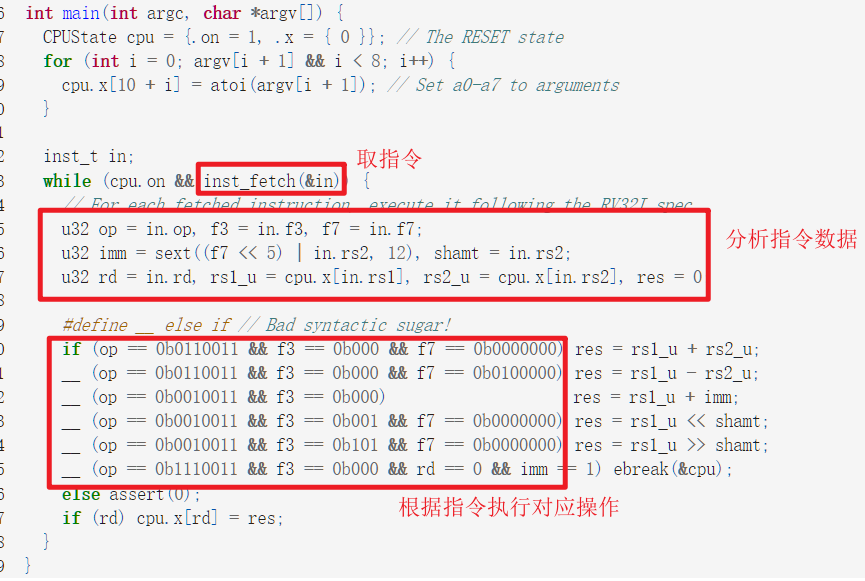
// User-defined tasks void func(void *arg) { while (1) { lock(); printf("Thread-%s on CPU #%d\n", arg, cpu_current()); unlock(); for (int volatile i = 0; i < 100000; i++) ; } } Task tasks[] = { { .name = "A", .entry = func }, { .name = "B", .entry = func }, { .name = "C", .entry = func }, { .name = "D", .entry = func }, { .name = "E", .entry = func }, };
#include <am.h>
#include <klib.h>
#include <klib-macros.h>
#define MAX_CPU 8
typedef union task {
struct {
const char *name;
union task *next;
void (*entry)(void *);
Context *context;
};
uint8_t stack[8192];
} Task; // A "state machine"
Task *currents[MAX_CPU];
#define current currents[cpu_current()]
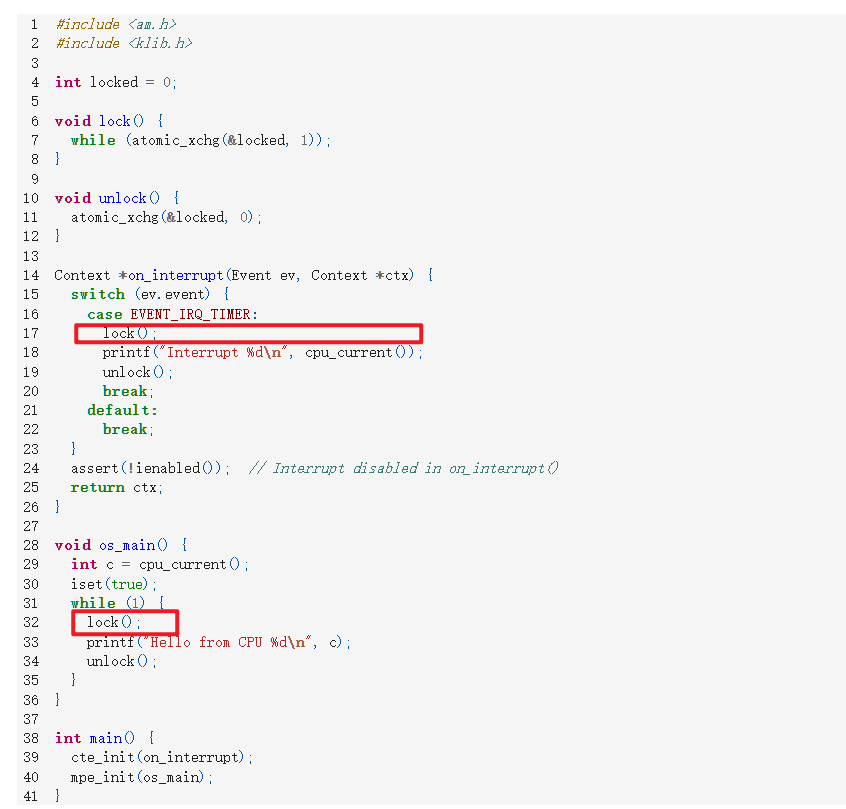
int locked = 0; // A spin lock
void lock() { while (atomic_xchg(&locked, 1)); }
void unlock() { atomic_xchg(&locked, 0); }
#include "tasks.h"
Context *on_interrupt(Event ev, Context *ctx) {
if (!current) current = &tasks[0]; // First interrupt
else current->context = ctx; // Save pointer to stack-saved context
//scheduling thread
do {
current = current->next;
} while ((current - tasks) % cpu_count() != cpu_current());
return current->context; // Restore a new context
}
void mp_entry() {
yield(); // Self-trap; never returns
}
int main() {
cte_init(on_interrupt);
for (int i = 0; i < LENGTH(tasks); i++) {
Task *task = &tasks[i];
Area stack = (Area) { &task->context + 1, task + 1 };
//kcontext is to init context
task->context = kcontext(stack, task->entry, (void *)task->name);
task->next = &tasks[(i + 1) % LENGTH(tasks)];
}
mpe_init(mp_entry);
}
如何理解上述代码?
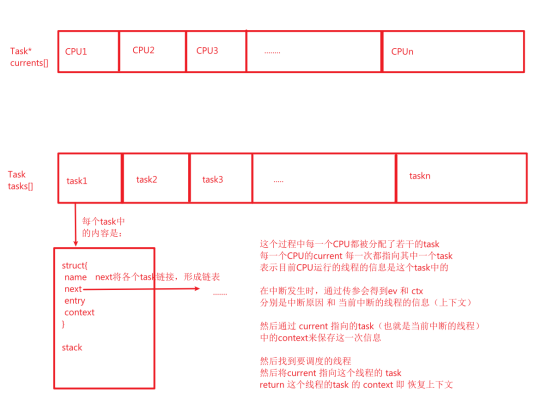


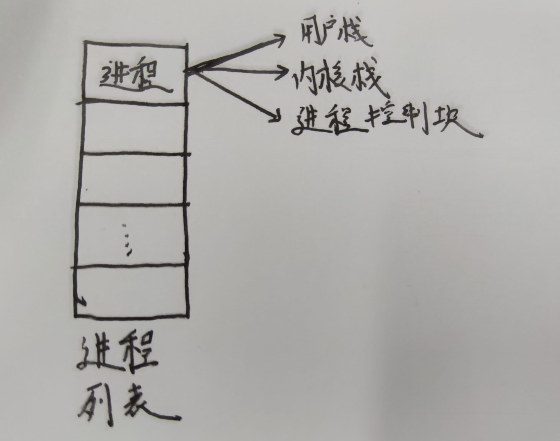
有没有发现这个数据结构与书上介绍的PCB/TCB很像?
通过其中的next构造如下队列:
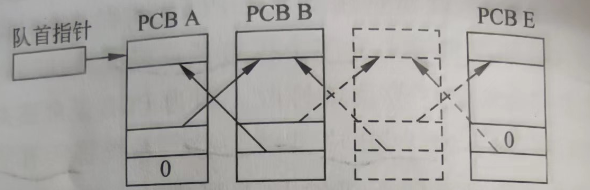
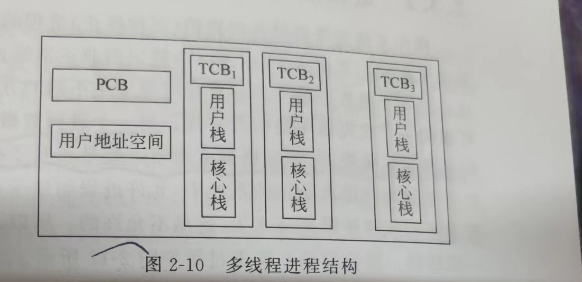
这个图展示了每一个线程都有栈 和 TCB
堆栈在线程中的作用:
当一个线程启动时,会创建一个专门的堆栈空间,用于存储该线程执行过程中产生的临时数据。
在函数调用过程中,相关的参数和返回地址也会被压入堆栈中,以便函数返回时能够恢复到之前的状态。
具体来说,当一个函数被调用时,线程会将返回地址和参数等信息压入堆栈顶部。
接着,函数将开始执行,并在堆栈中分配一段空间来存储该函数的局部变量。在函数执行过程中,如果该函数调用了其他函数,那么该函数的返回地址和参数也会被压入堆栈中。
当内层函数执行完毕后,它的返回值和其他临时数据都会从堆栈中弹出,并恢复该函数的返回地址和参数,使得程序能够回到之前的位置继续执行。
当最外层的函数执行完成后,它的返回值和其他数据也会从堆栈中弹出,堆栈空间也会被回收。
在多线程环境中,每个线程都有自己的堆栈空间,这样就能够保证每个线程的函数调用关系都是独立的,互不干扰。
《来看看没有中断的计算机是怎么样的?》
没有中断的计算机就是个while循环,从外界得到数据, 处理数据 ,输出数据
一旦这个while循环中某个地方死循环了,那么他也就完全卡住了
《加入中断,看看中断是咋实现的》

MINIRV32_DECORATE int32_t MiniRV32IMAStep( struct MiniRV32IMAState * state, uint8_t * image, uint32_t vProcAddress, uint32_t elapsedUs, int count )
{
uint32_t new_timer = CSR( timerl ) + elapsedUs;
if( new_timer < CSR( timerl ) ) CSR( timerh )++;
CSR( timerl ) = new_timer;
// Handle Timer interrupt.
if( ( CSR( timerh ) > CSR( timermatchh ) || ( CSR( timerh ) == CSR( timermatchh ) && CSR( timerl ) > CSR( timermatchl ) ) ) && ( CSR( timermatchh ) || CSR( timermatchl ) ) )
{
CSR( extraflags ) &= ~4; // Clear WFI
CSR( mip ) |= 1<<7; //MTIP of MIP // https://stackoverflow.com/a/61916199/2926815 Fire interrupt.
}
else
CSR( mip ) &= ~(1<<7);
// If WFI, don't run processor.
if( CSR( extraflags ) & 4 )
return 1;
uint32_t trap = 0;
uint32_t rval = 0;
uint32_t pc = CSR( pc );
uint32_t cycle = CSR( cyclel );
if( ( CSR( mip ) & (1<<7) ) && ( CSR( mie ) & (1<<7) /*mtie*/ ) && ( CSR( mstatus ) & 0x8 /*mie*/) )
{
// Timer interrupt.
trap = 0x80000007;
pc -= 4;
}
else // No timer interrupt? Execute a bunch of instructions.

首先查看是否有时钟中断
有:我们清除WFI(等待中断标志),并设置为接下来中断发生的标志
无:设置表明没有中断的标志

查看是否有等待中断标志
有:放回,等待中断
无:继续执行

有中断标志:陷入陷阱
无中断标志:执行用户程序
《中断中的上下文切换》

每一个进程都有类似如上的数据结构:
其中name是进程名,next是下一个进程,entry是进程执行的函数
context是这个进程上下文,其中有众多的寄存器状态
其将task设置为union,说明 struct 与 stack共享task的内存
即说明struct是在进程的stack中的

然后我们有一个currents 表明每一个CPU当前执行的进程是哪个
current指向的是task,
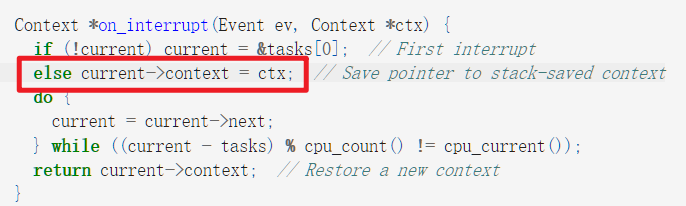
每一次产生中断时,直接操作current指向的那个task,将task中的context更新的为ctx
这个ctx是current指向的task的最新的上下文(即寄存器中的各种状态)
这个context当然是保存在这个进程中的stack,上面我们分析过
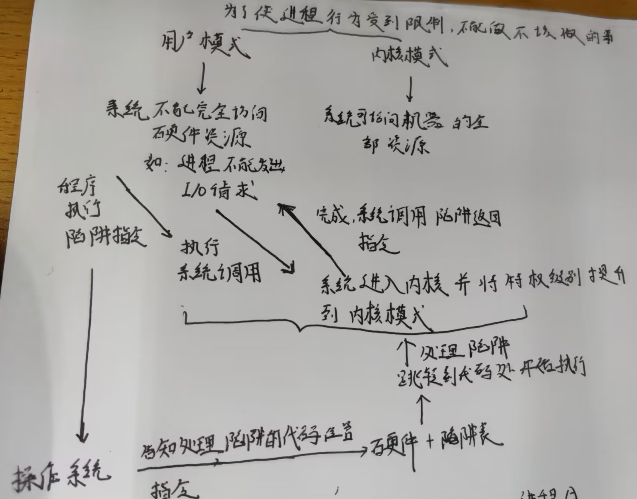
《机制:受限直接执行》
目前理解如下:
《进程管理 API (fork, execve, exit) 》
当电脑第一次开机时,可以看做只有操作系统这一个状态机
操作系统是所有状态机的管理者
那么我们如果在操作系统这个状态机中生成状态机
从而得到电脑上如此的“花花世界”?
《复制状态机:fork()》

为何叫fork()?
不觉的上面的叉子,像二叉分支吗?
即当在一个状态机中调用fork()
将得到一个与这个状态机的完美复制的状态机
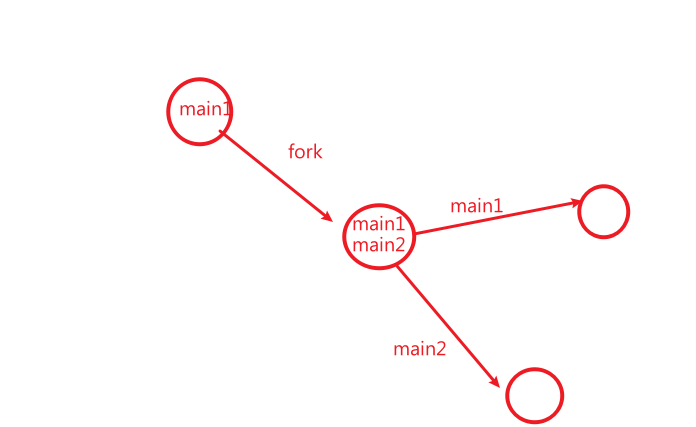
如图这种感觉:
本来只有main1这一个状态机,然后执行fork,这个状态机上多了main2这个状态机
然后并发出现了
可以选择执行main1还是main2

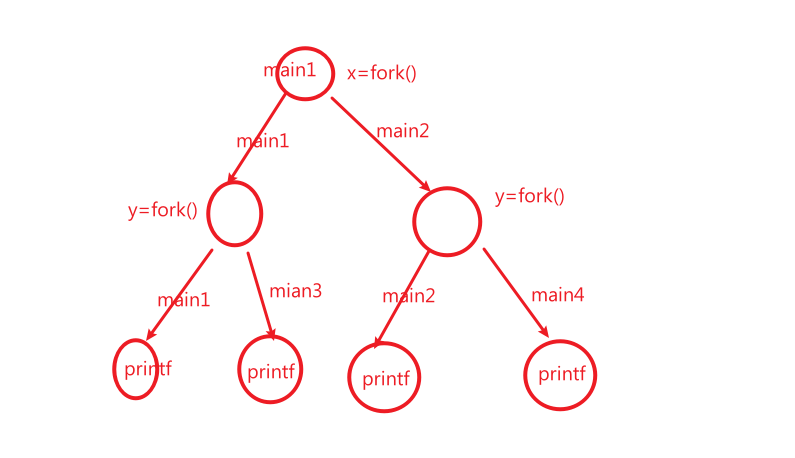
可以如图画图理解:即创建了4个状态机,每一个状态机会打印2个值
最后输出的结果因为并发会十分多样
比如当main1 在x=fork1()时
生成了main1和main2两个状态机
这个时候选择继续main1上执行还是main2上执行会导致最终的结果不同
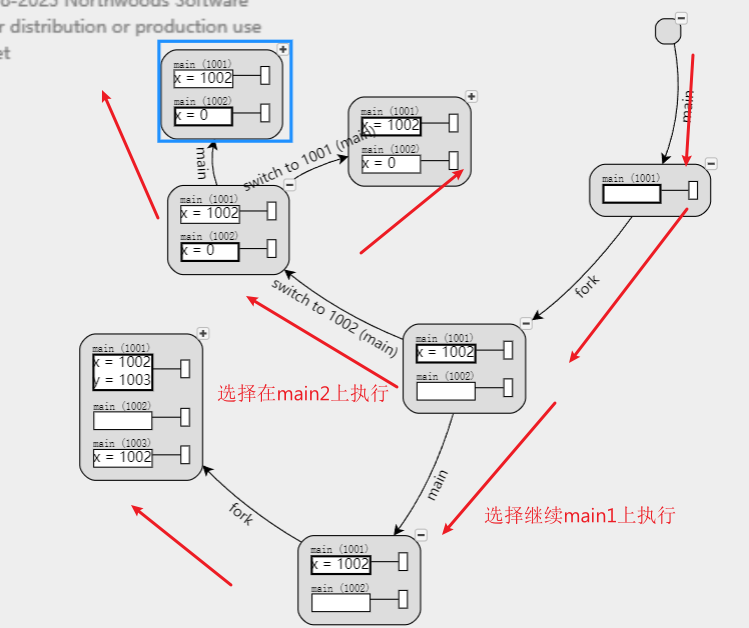
《重置状态机:execve()》

使用execve会使开启一个全新的,从初始开始运行的状态机
如果上一个状态机没运行完,调用execve后
这个状态机也不会再执行了,因为他的状态被初始化了,从新开始了
《销毁状态机:_exit()》

《理解和入侵Linux进程地址空间》
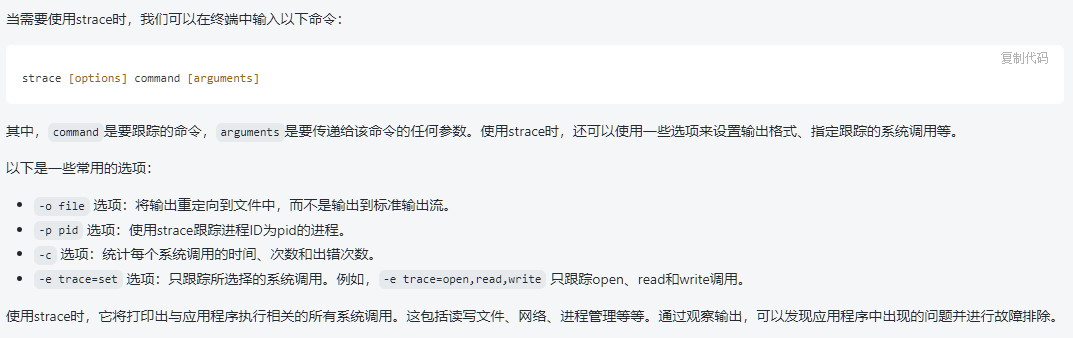
首先来看看pmap是什么:


具体来说:pmap是用来实现查看某一进程的地址空间的信息和内容
要想使用这个命令,我们就要知道我们想要查看的进程的pid,咋看?
1.ps (但是我们跑完后这个进程就消失了,再到终端上敲ps,进程就结束了)
2.gdb
在我们用gdp调试这个程序时,可以用!ps, 在gdb命令行用!中实现shell的命令
从而得知这个进程的pid
3.将这个程序写成死循环 同时ctrl+z
具体来说 ctrl+z可以将这个终端正在运行的程序给暂时终止,挂起,并放到后台
我们可以用bg命令让这个在后台的程序在后台执行
我们可以用fg命令让这个在后台挂起或执行的程序到前台执行
pmap是咋实现的?
pmap是通过阅读 /proc/[pid]/maps 这个文件中的内容实现的

如何证明上述结论?
不妨知道一下strace
strace可以帮助我们了解到一个shell命令执行时 发送的细节
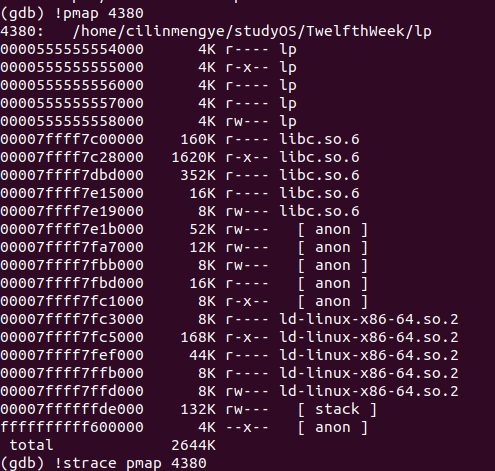
(因为有点小问题,这个程序的ip变成了4702)
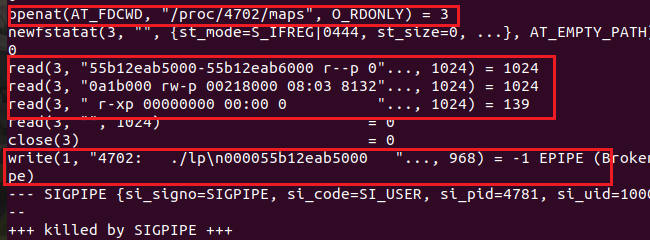
执行后也确实发现了他确实打开了/proc/4702/maps 来进行读操作
然后写操作,将在这个文件中读到的东西写出来了
或许我们要更加细致地讲讲pmap打印出来的内容:
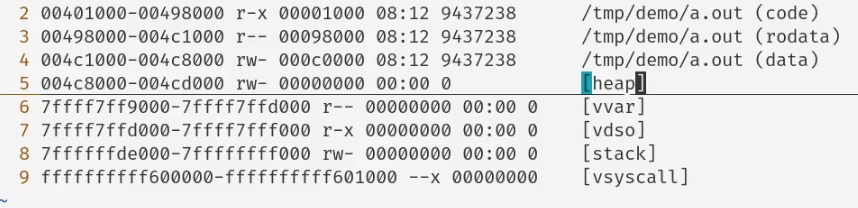
()中的不是打印出来的,而是我们根据推测来确定这是ELF文件的哪一段
可以看见这与我们在计算机系统基础上学习的链接后的ELF文件分布应该是个大致一样的
如果我们用pmap -x 呢?
会更详细地显示出一下内容:
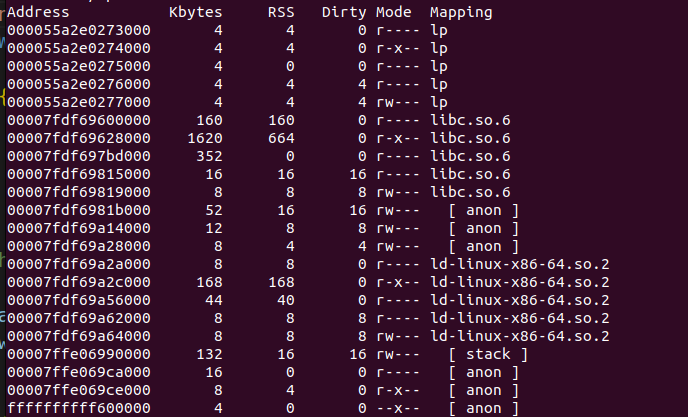
游戏外挂的实现
如何实现一个游戏外挂?比如改变自己的生命值?把自己的金币变的用不完?
有一个实现的想法
首先游戏中这些内容肯定也是用变量保存着的,这些变量也肯定最终是在内存中的
我们可不可用一些方法去访问并修改这个游戏(这个游戏进程)中的地址内容?
想一下我们在调试我们进程的程序用的gdb
是不是可以对我们程序的变量进行打印,改写等操作?
既然我们可以对我们直接的进程进行访问内存
那么实现游戏外挂就是不同进程之间的访问内存
如何实现?
我不太清楚
问问chatgpt?
简单来说就是通过pmap 来得到目标进程的地址信息,并且得到允许访问的权限
然后我们到目标进程的地址中对于每一个段
我们将其中的数据拿出来,与我们目标值(比如说这里是金钱x)进行匹配
将成功匹配到的数据地址保存下来(可能会有很多)
然后我们在游戏中改变这个金钱x,
当然这下游戏进程中的那个变量的值因为代表金钱那么肯定也会变
然后我们再次对上次保存下来的数据地址中的数据拿出来,再与现在的金钱数匹配一次
这次匹配到的地址肯定会减少
重复上述的交互过程,然后找到在游戏进程中保存金钱变量的数据地址
然后我们可以对这个地址中的数据进行改动(999999+无限金钱)
然后外挂就成了
最后提醒:不要用外挂破坏游戏平衡性(认真)
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <stdint.h>
#include <unistd.h>
#include <stdbool.h>
#include <stdarg.h>
#include <fcntl.h>
#define MAX_WATCH 65536
struct game {
const char *name; // Name of the binary
int pid; // Process ID
int memfd; // Address space of the process
int bits; // Search bit-width (16, 32, or 64)
//has_watch is just to mark whether it is the first read or not
//if it is first read,then will scan all memery,else only scan from watch[]
bool has_watch; // Watched values
uintptr_t watch[MAX_WATCH];
};
FILE* popens(const char* fmt, ...);
uint64_t mem_load(char *mem, int off, int bits);
//search for the address of the target value
//and remember it,when next time we want to search some value
//we search from it
void scan(struct game *g, uint32_t val) {
uintptr_t start, kb;
char perm[16];
//在Linux中,popen() 是一个标准库函数,
//它可以通过执行一个 shell 命令并将其输出流连接到一个文件描述符,
//从而允许我们从程序中捕获命令的输出。
FILE *fp = popens("pmap -x $(pidof %s) | tail -n +3", g->name);
int nmatch = 0;
// the function of fscanf is read from file of pointed by fp
while (fscanf(fp, "%lx", &start) == 1) {
//使用 fscanf() 函数从文件中读取数据。具体来说,
//它从文件中读取 3 个 long 类型的整数(第二和第三个整数被忽略),
//然后读取一个字符串,直到遇到换行符为止。这些数据会被存储在变量 kb 和 perm 中。
fscanf(fp, "%ld%*ld%*ld%s%*[^\n]s", &kb, perm);
if (perm[1] != 'w') continue; // Non-writable areas
uintptr_t size = kb * 1024;
//然后,代码根据变量 kb 的值,计算出要读取的内存区域的大小,
//并通过 calloc() 函数动态分配一个大小为 size + 16 的缓冲区,
//用于存储从内存中读取的数据。这里需要注意,
//calloc() 函数分配的缓冲区大小比目标大小多了 16 个字节,
//用于防止在读取数据时发生越界访问错误。
char *mem = calloc(size + 16, 1); // Ignores error handling for brevity
//代码使用 lseek() 函数将文件指针定位到从内存映射文件中读取数据的起始位置。
//这个操作相当于在内存映射文件的指针上进行了定位,它让程序能够在内存映射文件中指向任意的地址,并读取该地址处的内容。
//而在生产环境中,应该尽量避免在内存映射文件中随意定位指针,以免导致系统崩溃或不稳定。
lseek(g->memfd, start, SEEK_SET); // Don't do this in production!
size = read(g->memfd, mem, size);
printf("Scanning %lx--%lx\n", start, start + size);
if (!g->has_watch) {
// First-time search; scan all memory
for (int off = 0; off < size; off += 2) {
uint64_t v = mem_load(mem, off, g->bits);
if (v == val && nmatch < MAX_WATCH) {
g->watch[nmatch++] = start + off;
}
}
} else {
// Search in the watched values
for (int i = 0; i < MAX_WATCH; i++) {
intptr_t off = g->watch[i] - start;
if (g->watch[i] && 0 <= off && off < size) {
uint64_t v = mem_load(mem, off, g->bits);
if (v == val) nmatch++;
else g->watch[i] = 0;
}
}
}
free(mem);
}
pclose(fp);
if (nmatch > 0) {
g->has_watch = true;
}
printf("There are %d match(es).\n", nmatch);
}
void overwrite(struct game *g, uint64_t val) {
int nwrite = 0;
for (int i = 0; i < MAX_WATCH; i++)
if (g->watch[i]) {
lseek(g->memfd, g->watch[i], SEEK_SET);
write(g->memfd, &val, g->bits / 8);
nwrite++;
}
printf("%d value(s) written.\n", nwrite);
}
void reset(struct game *g) {
for (int i = 0; i < MAX_WATCH; i++) {
g->watch[i] = 0;
}
g->has_watch = false;
printf("Search for %d-bit values in %s.\n", g->bits, g->name);
}
//In simple terms,the function of load_game is to init g->watch and has_watch
//And know the game of process of address info by using pmap command
//and save it to g->memfd,finally,if success,return ret=0,else return ret=-1
int load_game(struct game *g, const char *name) {
FILE *pid_fp;
int ret = 0;
g->name = name;
g->bits = 32;
//init the g->watch and g->has_watch
reset(g);
//pidof %s in this code ,%s will be replaced by g->name
//and (pidof processName) is an shell command,
// it can knows the id of a process by its name
// In simple terms ,popens returns a pointer to the output stream of a command
pid_fp = popens("pidof %s", g->name);
//if fscanf is not success ,it will return -1
if (fscanf(pid_fp, "%d", &g->pid) != 1) {
fprintf(stderr, "Panic: fail to get pid of \"%s\".\n", g->name);
ret = -1;
goto release;
}
char buf[64];
snprintf(buf, sizeof(buf), "/proc/%d/mem", g->pid);
//O_RDWR indicates that a file is opened in read-write forn
//g->memfd is the address of process,beacuse it relate to this process of address message
//we need know everything is file and 文件描述符(File descriptor) is an explanation of everything
// /proc/xxx/mem is a file and we read it to buf
// buf is opened and return a File descriptor to g->memfd
//and then g->memfd is used to read this file
//文件描述符(File descriptor)是一个用于访问打开文件或其他 I/O资源的整数标识符。
//它是操作系统内核中的一个抽象概念,通常被视为进程与文件之间的桥梁,
//可以使用它来进行文件读写、网络通信等操作。
g->memfd = open(buf, O_RDWR);
if (g->memfd < 0) {
perror("/proc/[pid]/mem");
ret = -1;
goto release;
}
release:
if (pid_fp) pclose(pid_fp);
return ret;
}
void close_game(struct game *g) {
if (g->memfd >= 0) {
//close(g->memfd) 的作用是关闭之前打开的文件描述符 g->memfd,
//释放相关的系统资源,以及将该文件描述符从进程的文件描述符表中移除。
close(g->memfd);
}
}
int main(int argc, char *argv[]) {
long val;
char buf[64];
struct game game;
//Load the game into the game modification program
if (load_game(&game, argv[1]) < 0) {
goto release;
}
//feof() is used to test the file end of flag
//!feof(stdin) when input not end ,then return true;
//stdin is a data stream of point,it's type is FILE*
//constantly read in modified commands from keyborad
while (!feof(stdin)) {
printf("(%s %d) ", game.name, game.pid);
if (scanf("%s", buf) <= 0) goto release;
switch (buf[0]) {
case 'q': goto release; break;
case 'b': scanf("%ld", &val); game.bits = val; reset(&game); break;
case 's': scanf("%ld", &val); scan(&game, val); break;
case 'w': scanf("%ld", &val); overwrite(&game, val); break;
case 'r': reset(&game); break;
}
}
release:
close_game(&game);
return 0;
}
//这段代码的作用是通过在 C 语言中调用 popen() 函数来执行一个 shell 命令,
//并返回一个指向 FILE 结构的指针。
//具体来说,这段代码使用了可变参数函数 vsnprintf() 来将命令字符串格式化为 cmd 数组中的 C 字符串,
//然后调用 popen() 函数以读取命令的输出流。
//值得注意的是,assert(ret) 用于断言 popen() 函数成功打开了一个管道,
//如果打开失败则会终止程序的运行。此外,这段代码的 cmd 数组大小被限制为 128 个字符,
//这意味着传递给该函数的命令字符串必须小于该长度,否则格式化过程可能会出现缓冲区溢出错误。
FILE* popens(const char* fmt, ...) {
char cmd[128];
va_list args;
va_start(args, fmt);
vsnprintf(cmd, sizeof(cmd), fmt, args);
va_end(args);
FILE *ret = popen(cmd, "r");
assert(ret);
return ret;
}
uint64_t mem_load(char *mem, int off, int bits) {
uint64_t val = *(uint64_t *)(&mem[off]);
switch (bits) {
case 16: val &= 0xffff; break;
case 32: val &= 0xffffffff; break;
case 64: break;
default: assert(0);
}
return val;
}
《系统调用和 UNIX Shell》
我们可以通过打印
/proc/{pid}/fd
从而得知一个进程中打开的文件(其都用文件描述符来表示出来)
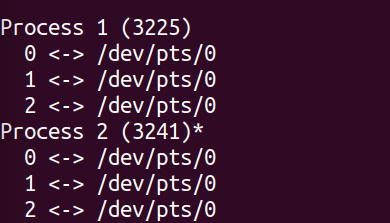
当调用fork时我们可以发现从Process 1拷贝出来的Process 2
与自己的父亲有完全一样的文件描述符
这很好的解释了:
为什么一个进程的子进程会与父进程打印到相同的终端(位置)上
通过调试jyy老师复刻经典的代码我们可以得知管道在linux中是如何实现的:
链接<-----
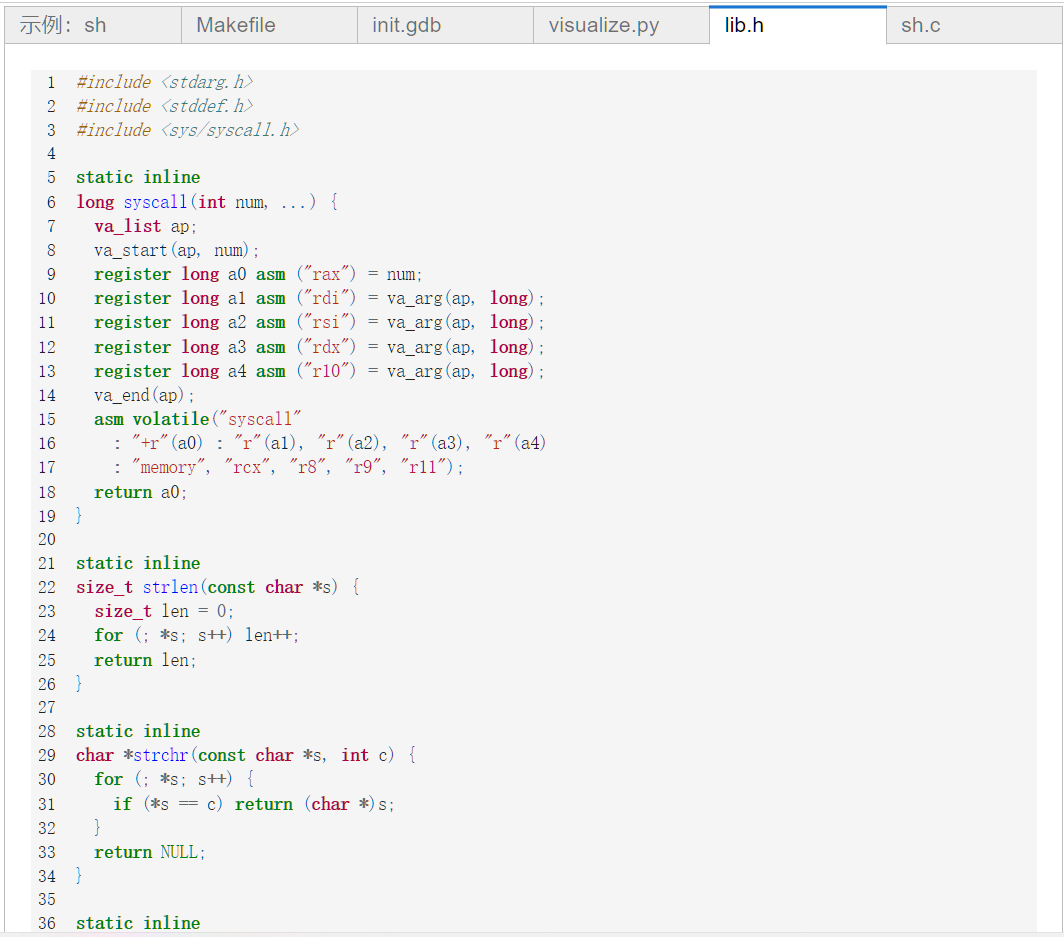
首先我们来看看这个lib.h代码:
其作用完全是用来实现我们c库中常用的API,但是这份代码没有用到C库
保证了在我们调试时的干净
其都是用内嵌asm汇编来实现系统调用
如下是几篇十分优先的文章:
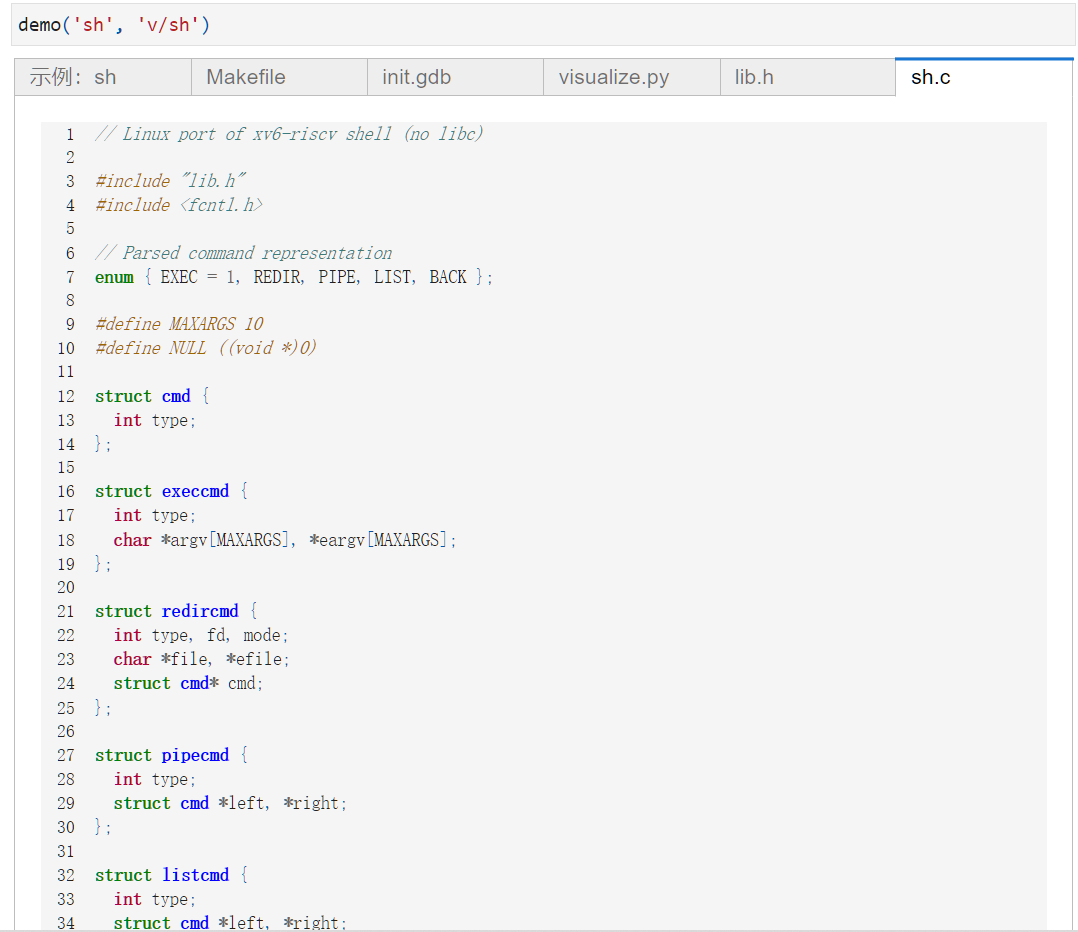
然后是老师写的这份sh.c代码,其模拟了一个shell是如何工作并且实现的
在这里面我们可以使用| > >> ls等shell命令
同时我们也利用这份代码来调试管道是如何实现的:
想一下当我们输入 /bin/ls | /bin/wc
之后程序是如何运行的?
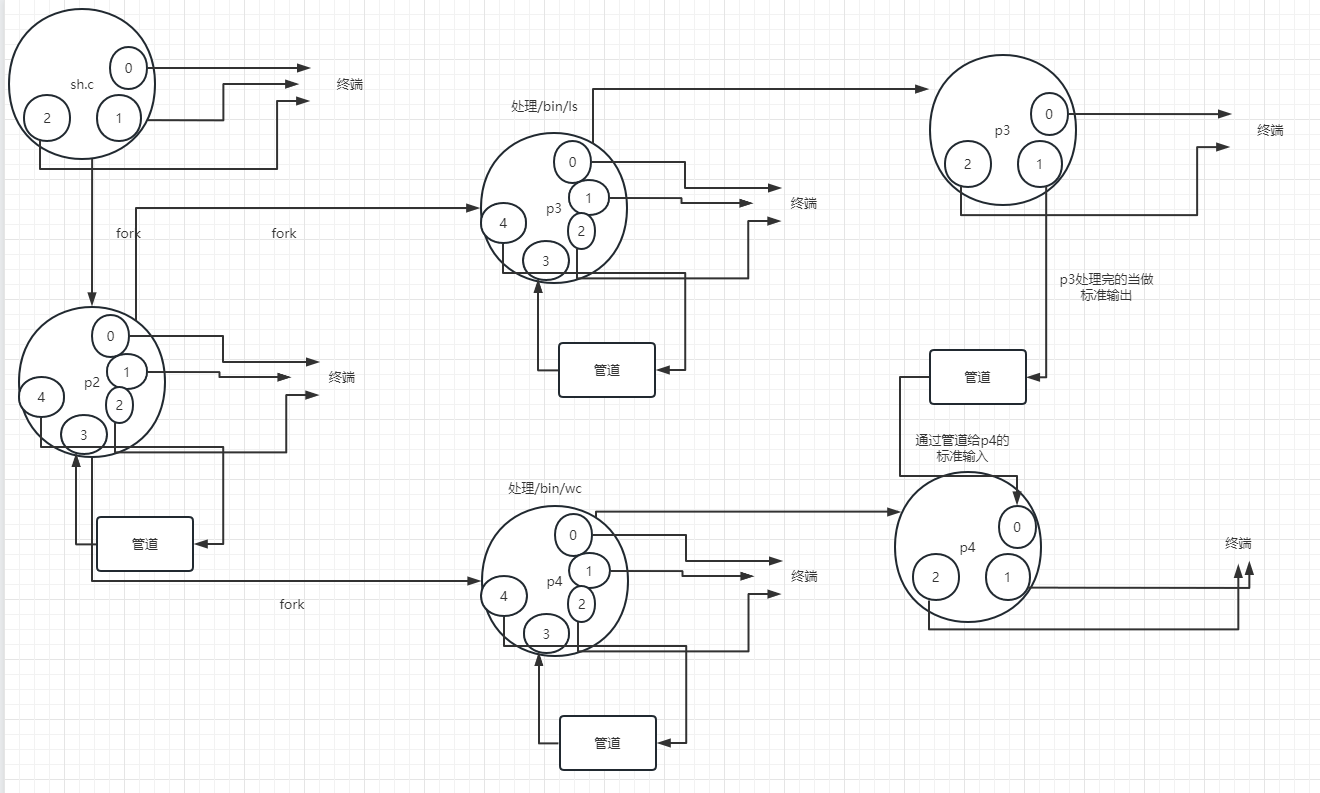
圆圈上的是文件描述符
0标准输入,1标准输出,2标准错误输出
《分页》
《补充一下书上没详细写但要考的内容》
clock替换算法的细节实现:
好博客<-----
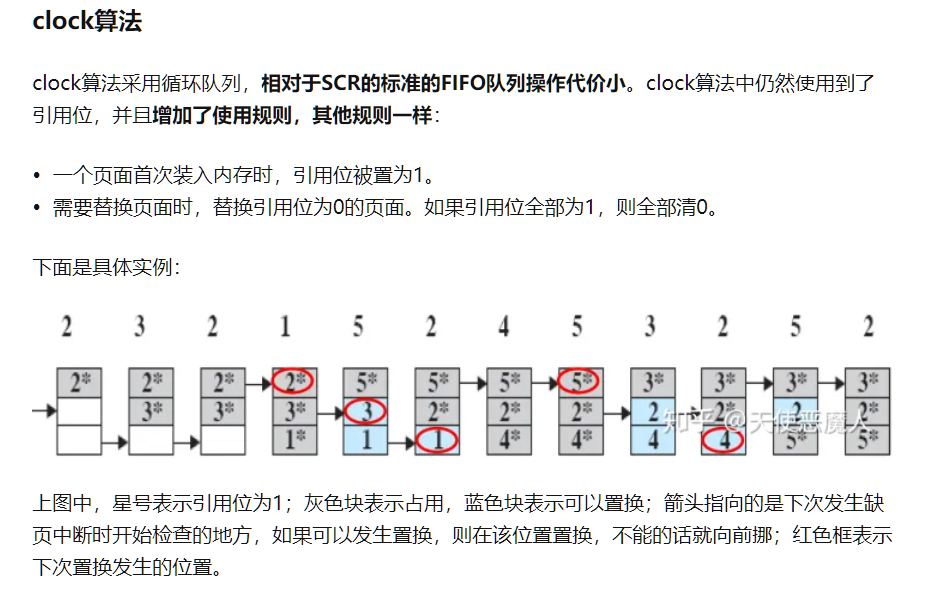
这里说明一下容易错的地方:指针的变化
(注意我们是将过大的页表进行保存到磁盘中,并在需要时交换回内存)
指针只有在(未命中)要替换掉内存中保存的某个页表时才进行移动,并循环地移动到下一个单元
(注意替换掉空的内存也算)
当命中时,指针是不变的,我们只要将命中的页表中的使用位置为1即可
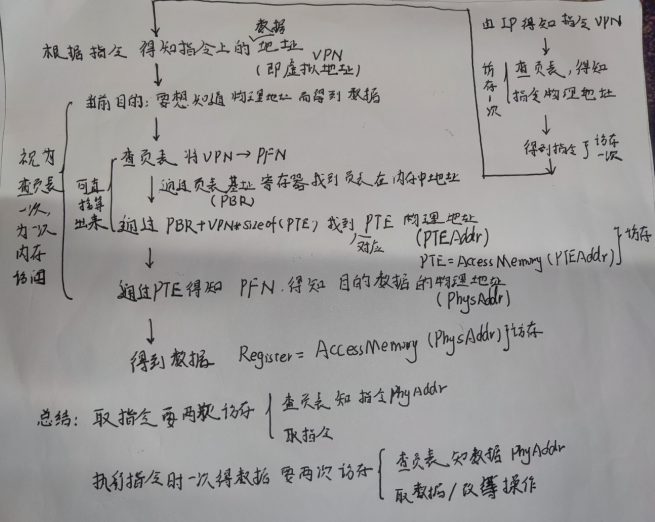
实际的虚拟地址咋转化成物理地址?

对于简单的分页,虚拟地址可以拆分成 页号+偏移地址
这里通过一个页长1KB,则我们需要10位二进制位来定位使用的是哪个字节,即偏移地址
从而知道确定页号的二进制有6位(因为这里地址给的是16进制下的,而且有4个16进制数,共16位)
(为啥不通过用户编程空间来确定页号的二进制位呢?
问的好,本来用户编程空间有32个页,我们只要5位就能确定页号的
这里我也不知道为啥)
将0AC5H 转化成二进制 0000 1010 1100 0101
取前6位为确定页号的,确定页号为2
后10位为偏移地址
页号为2,对应了物理块的4,物理块4的首地址为4KB=0001 0000 0000 0000
加上偏移地址后,物理地址为 0001 0010 1100 0101
为12C5H
虚拟地址向物理地址转化的过程,以及操作(考试适用,实际Linux上不一定适用)
虚拟地址->快表
快表命中->到物理地址(访存)
->物理地址未命中->与磁盘上进行页面置换算法->再次到物理地址(访存)
快表未命中->到页表(访存)
->到物理地址(访存)
->物理地址未命中->与磁盘上进行页面置换算法->再次到物理地址(访存)
需要注意的是:在磁盘上置换完后,我们需要再次访存
磁盘上方位的问题:
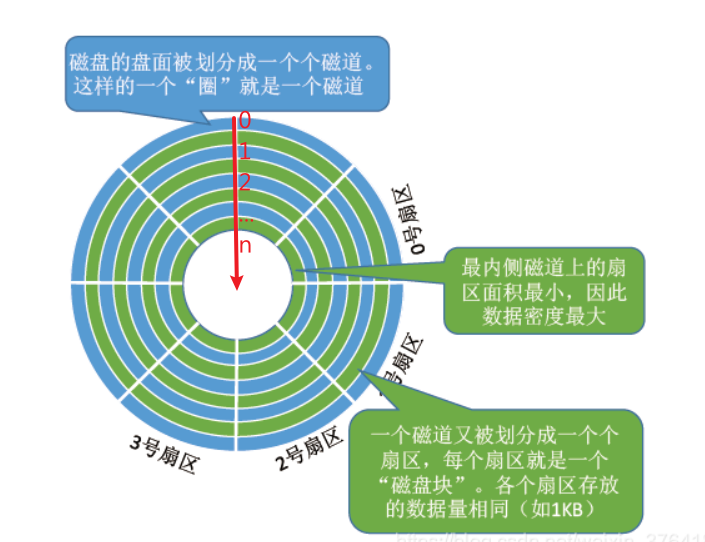
需要注意的是:
磁盘中的磁道是从最外围开始编号的,即最外围的磁道是0,然后向里面逐渐增加
我们一般说的从里到外,这个外是小编号,这个里是大编号
从里到外就是说首先从大编号->小编号
本文作者:次林梦叶的小屋
本文链接:https://www.cnblogs.com/cilinmengye/p/17294534.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步