操作系统----并发
《基本概述》
我们知道操作系统的功能之一是处理器管理
其是对进程与线程的管理与调度
处理器的运行状态分为核心态和用户态,为了防止操作系统或关键资源受到用户程序的破坏
核心态下执行的具有特殊功能的程序段被称为原语
进程与线程的区别?
我们知道进程是资源申请和拥有的实体,同时也是调度的实体
想要实现并发操作就要创建一个进程
如此系统会因为创建,管理,调度进程付出巨大开销
所以将进程细分为多个线程
使进程作为资源申请与拥有的单位,线程是作为调度的基本单位
注意:
线程本身不拥有系统资源
各个线程共享进程申请的资源
线程也分为内核级线程,用户级线程,混合式线程(师大书P50)
进程控制中进程阻塞和进程挂起的区别?
阻塞:正在执行的进程由于发生某时间(如I/O请求、申请缓冲区失败等)暂时无法继续执行。
此时引起进程调度,OS把处理机分配给另一个就绪进程,而让受阻进程处于暂停状态,
挂起:由于系统和用户的需要引入了挂起的操作,进程被挂起意味着该进程处于静止状态。
如果进程正在执行,它将暂停执行,若原本处于就绪状态,则该进程此时暂不接受调度。
1.对系统资源占用不同:虽然都释放了CPU,但阻塞的进程仍处于内存中,
而挂起的进程通过“对换”技术被换出到磁盘中。
2.发生时机不同:阻塞一般在进程等待资源(IO资源、信号量等)时发生;
OS为了提高内存利用率需要将暂时不能运行的进程(处于就绪或阻塞队列的进程)调出到磁盘
3.恢复时机不同:阻塞要在等待的资源得到满足(例如获得了锁)后,才会进入就绪状态,等待被调度而执行;
《多处理器编程:从入门到放弃----蒋炎岩老师》
操作系统拥有随机选择状态机执行的权力,因此也带来了并发性。
操作系统是世界上最早的并发程序。
并发带来的同时也有:
1.原子性不能保证 2.不可知的调度顺序 3.同时访问共享的数据
的主要问题
上面的问题通过如下例子来了解:

#include "thread.h"
int x=0;
void Thello (int id){
x++;
printf ("%d\n",x);
}
int main(){
for (int i=0;i<10;i++){
//只要知道spawn是创建一个新的线程的操作即可,
//参数是线程要执行的函数
spawn(Thello);
}
}
猜猜运行结果是什么?
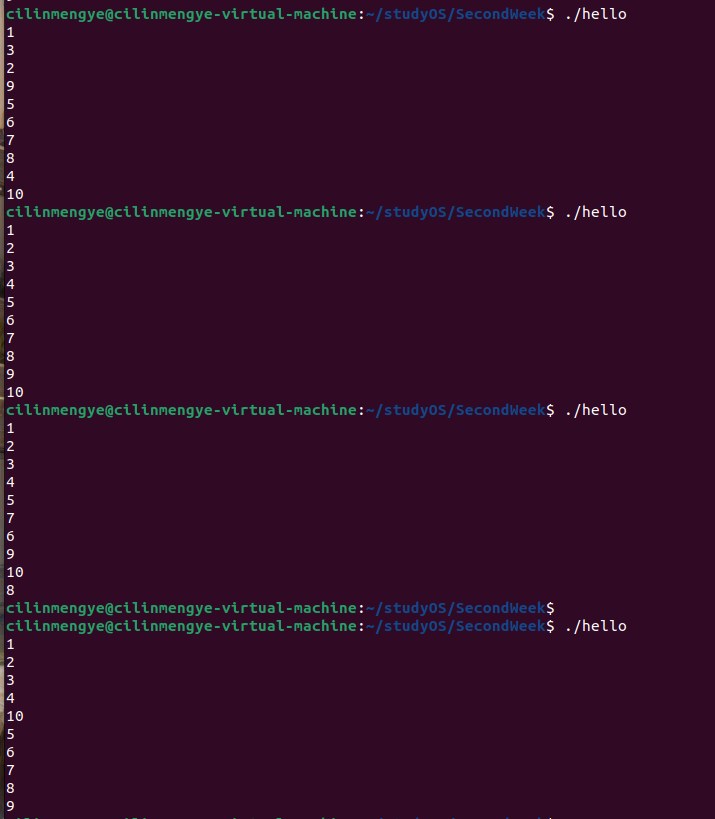
这只是一部分的运行结果,就拿如下这一段结果进行分析:
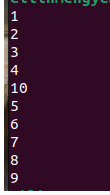
能看到10的位置不对劲,即使根据以前对并发的一点了解来想:
1~4还是正常的
到打印出10之前,CPU应该是一直在进行x++的操作,printf的操作一直都没机会
后printf的操作有机会拿到了CPU,打印出了10
但为何后面打印又变正常了?
难道不是x的结果已经确定了?难道不是后面应该一直打印10?
有上面的误区就是对应硬件(计算机组成原理)不熟悉了(没错就是我)
我们知道上面的C语句其实对应着汇编代码(好吧不全是,大概框架是这个):
mov 2000,ax
...
add &1,ax
...
mov ax,2000
我们假设2000是变量x在内存中的地址
&1是立即数1
ax是在CPU中的寄存器
即先要做加法,肯定要将内存中的内容拿到CPU的寄存器来,
再将算完的放到内存中
上面的汇编指令不是原子性的,即可能在执行时汇编语句被中断,
导致2条以上的汇编指令都有可能不能完整执行
《进程的互斥与同步》
具体看师大书P57
信号量S:
S>=0,可供并发进程使用的资源实体数
S<0,|S|表示等待使用资源实体的进程数
按用途来分,信号量分为两种:
- 公用信号量:
- 联系一组并发进程,相关进程可以在此信号量上做PV操作,初值为1,是为了实现进程的一个互斥;
- 私有信号量:
- 联系一组并发进程,仅允许此信号量所拥有的进程执行P操作,其他相关的进程可实施V操作,初值一般为0或正整数,在进程同步中常用
(概念而已)
《PV操作》
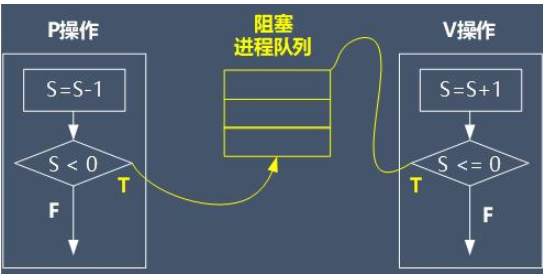
P操作,P(S):
在互斥操作时:
void P(Semaphore S){
S=S-1;
if(S<0) W(S) //W(S),表示等待
}
Semaphore 是个结构体,其中有信号量S的值和一个指向等待进程的指针
其表示需要一个资源实体,当S>=0,资源实体还够,来的线程无需等待
反之,来的线程要等待
在同步操作时:
以生产者和消费者为例
一般都是表示 调用P(S)的线程开始要消费资源S了
有就消费,没有就等待,直到有资源S为止
V操作,V(S):
在互斥操作时:
void V(Semaphore S){
S=S+1;
if (S<=0) R(S); //R(S)表示释放(生产)出一个资源实体
}
其表示当S>0时,可用资源数+1,
当S<=0时,表示有真正等待的线程,现在可以让出CPU,
让其中一个正在等待的线程运行
在同步操作时:
以生产者和消费者为例
一般都是表示 调用 V(S)的线程要开始生产一个资源S了
如果只要已经有了(或者说超过规定的数),就等待
如果已经没有了,就生产
《并发控制:互斥 (问题定义与假设;自旋锁;互斥锁) [南京大学2023操作系统-P7] (蒋炎岩)》
《问题定义与假设》

能正确处理编译优化是很重要的
编译优化会把我写出的看起来可以实现互斥的代码
给改成(优化成)明显不能互斥的代码
为了实现这样一个锁我们要如何作?
首先要进行假设
为了实现这个互斥,我们必须要有假设(可以使得我们不去理会繁琐的细节),
从而利用这个假设去实现互斥的功能
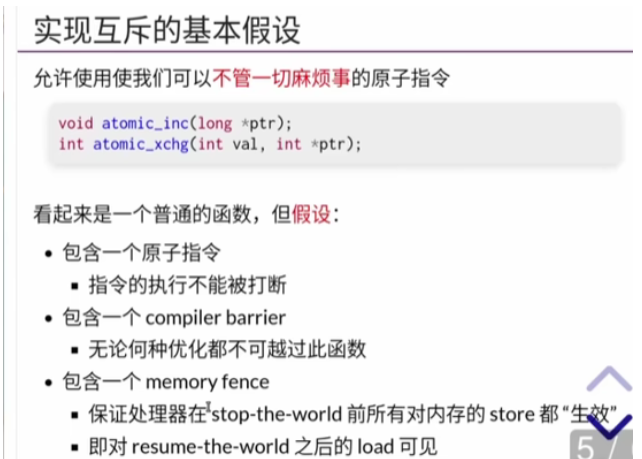
好消息是硬件可以帮助我们实现这个假设
即假设
void atomic_inc(long *ptr)
将*ptr中的值进行增操作(即++)
与
int atomic_xchg(int *ptr,int val )
将 *ptr上的旧值返回,得到新值 val(即一个交换的过程)
是一个原子操作
《自旋锁》
那么我们如何利用上述假设实现锁?
基本思路是:
我手上有世界上独一无二的物品,得到这个物品才能进入新世界
其他线程必然想用他们手上普通的线程来交换 (atomic_xchg) 我这个物品
交换成功后,成功交换的线程进入,
我手上拿的就是普通物品了
其余线程只能等那个线程将特殊物品还给我,
才能继续交换与我交换特殊物品
否则只能拿着自己手上的普通物品默默等待
atomic_xchg
实际上这操作也叫 测试与设置 (test-and-set)(也叫原子交换)
具体实现是:
1 #include<iostream>
2 #include<algorithm>
3 #include<cstring>
4 using namespace std;
5 //假设这个操作是原子的
6 int auto_xchg(int *ptr,int val)
7 {
8 int old=*ptr;
9 *ptr=val;
10 return old;
11 }
12 void init(int *ptr)
13 {
14 //开始我手上的特殊物品
15 *ptr=0;
16 }
17 void lock(int *ptr)
18 {
19 //1就相当于那个普通的物品
20 //每个线程来的时候都尝试用他们手上的物品(普通物品1)
21 //来与我的物品交换
22 //但是特殊物品被交换走了,我手上的物品当然就是一个普通物品1
23 //再交换时,线程得到的还是普通物品,那么他就会等待
24 while (auto_xchg(ptr,1)==1)
25 ;
26 }
27 void unlock(int *ptr)
28 {
29 //0就是那个特殊物品
30 auto_xchg(ptr,0);
//为啥不写*ptr=0?
//这样也可以,但是auto_xchg是原子的。用它更有保证
31 }
32 int main()
33 {
34
35 }
还有一个名为 比较并交换 的假设(即原子操作)
将其也可以用于实现锁的效果
简单来说就是:
每一次交换前检查一边上次获得的值是否还有效,
如果是就交换,不是就保持
这个不强求,当感兴趣时,再深入(操作系统导论P225)
不过这里蒋炎岩老师提供了一个很好理解这个算法的方法:
手画真值表或用程序画出真值表
从而找到规律
《互斥锁》
明显我们感受的到自旋锁会浪费时间
比如:
当获得锁的线程在unlock()之前被CPU切换掉了
然后其他线程在请求锁时都会在自旋,同时唯一有锁的线程还被
切换掉了(即在睡觉一样)
如此实现了100%资源浪费
特别是在临界区特长执行时间时,锁会迟迟不放

更好的做法是:让出来吧,宝贝(操作系统导论P229)
即在自旋的线程明知道自己不能得到锁,同时还会浪费CPU
不如让出CPU,先睡一觉,等锁好了

《同步:生产者-消费者与条件变量 (算法并行化;万能同步方法) [南京大学2023操作系统-P9] (蒋炎岩)》
《万能同步方法:》


将生成者看做是打印左括号的,将消费者看做是打印右括号的
如果生成者和消费者打印的括号能够匹配说明同步成功
解决这种同步问题有一个万能的同步方法:即条件变量
有个万能的思考方法:即状态机
首先让我们看看如何用万能的同步方法实现上的生成者和消费者问题:
#include "thread.h"
#include "thread-sync.h"
int n, count = 0;
mutex_t lk = MUTEX_INIT();
cond_t cv = COND_INIT();
#define CAN_PRODUCE (count < n)
#define CAN_CONSUME (count > 0)
void Tproduce() {
while (1) {
mutex_lock(&lk);
while (!CAN_PRODUCE) {
cond_wait(&cv, &lk);
}
printf("("); count++;
cond_broadcast(&cv);
mutex_unlock(&lk);
}
}
void Tconsume() {
while (1) {
mutex_lock(&lk);
while (!CAN_CONSUME) {
cond_wait(&cv, &lk);
}
printf(")"); count--;
cond_broadcast(&cv);
mutex_unlock(&lk);
}
}
int main(int argc, char *argv[]) {
assert(argc == 3);
n = atoi(argv[1]);
int T = atoi(argv[2]);
setbuf(stdout, NULL);
for (int i = 0; i < T; i++) {
create(Tproduce);
create(Tconsume);
}
}
可以看到,首先生成者和消费者各一个线程
同时在生成者和消费者中核心的逻辑代码都为类似:

注意这里使用cond_broadcast是用来唤醒全部睡眠的线程,相比cond_signal
其在有多个生成者和消费者时更好
(因为cond_signal只是唤醒一个,可能唤醒的并不是我们想要的那一个)
用这种感觉来做做fish的问题,同时用状态机的思想去考虑下:

考虑条件时,试试状态图:
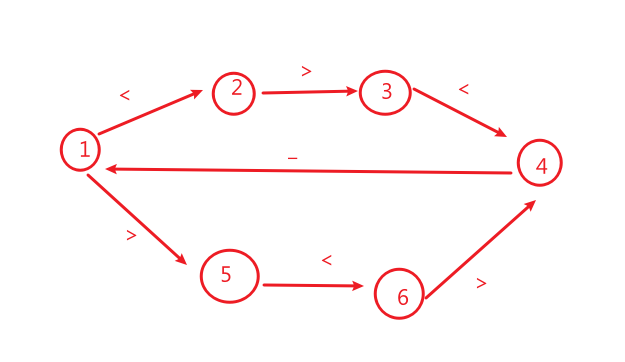
以第一个为例:打印“<”的条件?
对于打印“<”的线程,根据状态图知道,条件为
当前状态为1 或当前状态为3 或当前状态为5
然后打印完后,状态要发生变化
同时注意:
在状态1时,可以打印两个 < 或 >,
显然我们不可能让这两个都打印出来,这个时候就要用一个
条件变量(比如 int p),来使得互斥
#include <iostream>
#include <algorithm>
#include <cstring>
#include "Semaphore.h"
using namespace std;
// have from State machine diagram
struct node
{
int from, to;
char ch;
} rule[] = {
{1, 2, '<'},
{2, 3, '>'},
{3, 4, '<'},
{4, 1, '_'},
{1, 5, '>'},
{5, 6, '<'},
{6, 4, '>'}};
string id = ".<<<>>>_";
pthread_mutex_t mutex;
pthread_cond_t cond;
// promise at state 1 will only print one char
int p, current;
char next(char id)
{
for (int i = 0; i < 7; i++)
{
if (rule[i].from == current && rule[i].ch == id)
return rule[i].to;
}
return 0;
}
bool can_print(char id)
{
if (p > 0 && next(id) != 0)
return true;
else
return false;
}
void *work(void *id)
{
char cid = *(char *)id;
while (1)
{
Mutex_lock(&mutex);
while (!can_print(cid))
Cond_wait(&cond, &mutex);
p--;
Mutex_unlock(&mutex);
cout << cid;
Mutex_lock(&mutex);
current = next(cid);
p++;
// when I write this,I have mistake in there
// rememeber cond need signal:
Cond_broadcast(&cond);
Mutex_unlock(&mutex);
}
}
void fish_init()
{
Mutex_init(&mutex);
Cond_init(&cond);
p = 1;
current = 1;
}
int main()
{
fish_init();
// every id have a thread
pthread_t threads[8];
for (int i = 1; i <= (int)id.size(); i++)
Pthread_create(&threads[i], NULL, work, (void *)&id[i]);
for (int i = 1; i < (int)id.size(); i++)
Pthread_join(threads[i], NULL);
return 0;
}
《算法并行化》

即将LCS算法并行化:
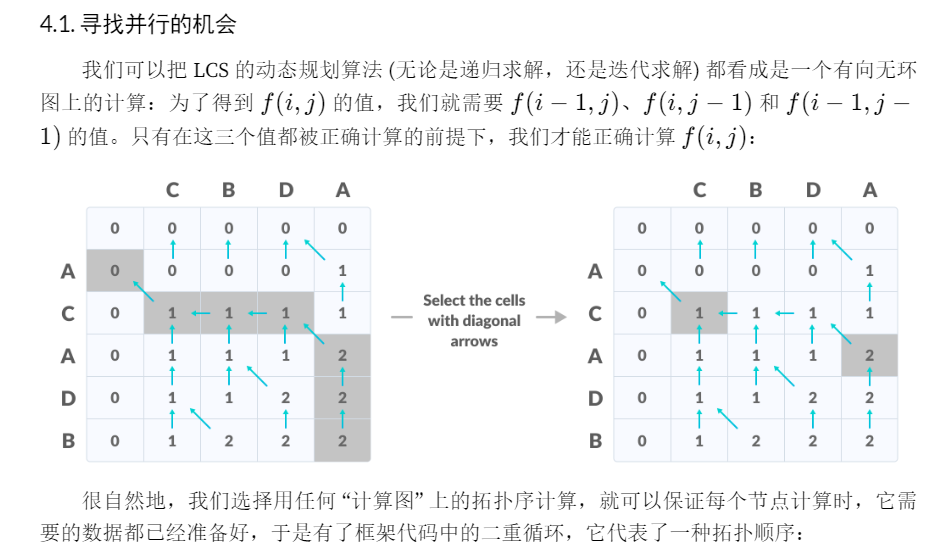
通过上面的图示可以知道,能够并行的地方在于每一斜线上的点
必须要同步的地方在于每一斜线的上斜线的点必须要全部算完
于是就有想法:
为每一斜线上计算任务分配线程,并行计算
然后等待上面的分配的线程计算完
然后进行下一轮斜线的并行计算
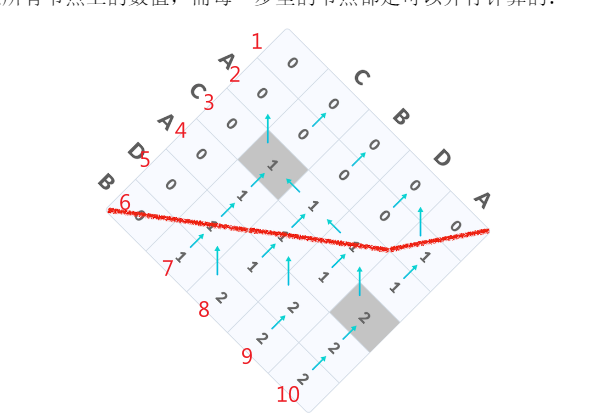
框架代码如下:

2*n-1含义为:假设两个字符串长度都为n
这必须要同步的长度为2*n-1
即如下图:
于是我写出了我错误百出的代码,对这份代码是错误的,目前我还不知道咋改:
#include <iostream>
#include <cstring>
#include <algorithm>
#include <assert.h>
#include <pthread.h>
#include "Semaphore.h"
using namespace std;
const int N = 5000;
int dp[N][N];
int t;
string a, b;
typedef struct _Pos
{
int staR, staC, g,i;
} Pos;
void *work(void *argv)
{
Pos pos = *(Pos *)argv;
cout<<"???"<<pos.g<<" "<<pos.i<<endl;
for (int staR = pos.staR, staC = pos.staC, g = pos.g; g >= 1; g--, staR--, staC++)
{
cout<<"!!!"<<g<<endl;
dp[staR][staC] = max(
max(dp[staR - 1][staC], dp[staR][staC - 1]), dp[staR - 1][staC - 1] + (a[staR - 1] == b[staC - 1] ? 1 : 0));
cout << "check: " << staR << " " << staC << " " << dp[staR][staC] << " " << a[staR - 1] << " " << b[staC - 1] << endl;
}
return NULL;
}
int main(int argc, char *argv[])
{
pthread_t threads[10*N];
int tcnt=0;
cin >> t;
cin >> a >> b;
int lena = a.size(), lenb = b.size();
// have lena row and lenb col in total
for (int round = 1; round <= (lena + lenb - 1); round++)
{
// max number of computing available:
int maxg = round <= lena ? min(lenb, round) : min((lena + lenb - round), lena);
int staR = round <= lena ? round : lena;
int staC = round <= lena ? 1 : lena + lenb - 1 - round;
int every = maxg / t;
cout << "ALL: " << maxg << " " << staR << " " << staC << " " << every << endl;
// start give task for every thread:
int stacnt=tcnt;
for (int Nthread = 1; Nthread <= t; Nthread++)
{
int give = Nthread == t ? maxg : every;
Pos pos = {staR, staC, give,Nthread};
cout << "EVERY: " << staR << " " << staC << " " << give << endl;
maxg -= every, staR -= every, staC += every;
Pthread_create(&threads[tcnt], NULL, work, (void *)&pos);
tcnt++;
}
for (; stacnt < tcnt; stacnt++)
Pthread_join(threads[stacnt], NULL);
for (int i = 1; i <= lena; i++)
{
for (int j = 1; j <= lenb; j++)
cout << dp[i][j] << " ";
cout << endl;
}
cout << endl;
}
cout << dp[lena][lenb] << endl;
return 0;
}
《并发 Bug 分类 (死锁、数据竞争、原子性/顺序违反) [南京大学2023操作系统-P12] (蒋炎岩)》
《死锁》


当调用了多次函数,很可能自己已经上了锁了
所以我们要尽可能让函数没有副作用,只进行单纯的计算
《数据竞争》


数据竞争带来的后果往往是:
数据竞争与下面讲的违反原子性和违反顺序,常常是一起发生的,导致一些BUG
《非死锁缺陷》
违反原子性:

在系统中随时都有可能会发生中断
当我们假设的一个原子性操作,突然被中断时
发生我们上面的情况(数据竞争)
那么无疑会有BUG
利用违反原子性(有中断)+数据竞争,会导致共享上许多安全问题:
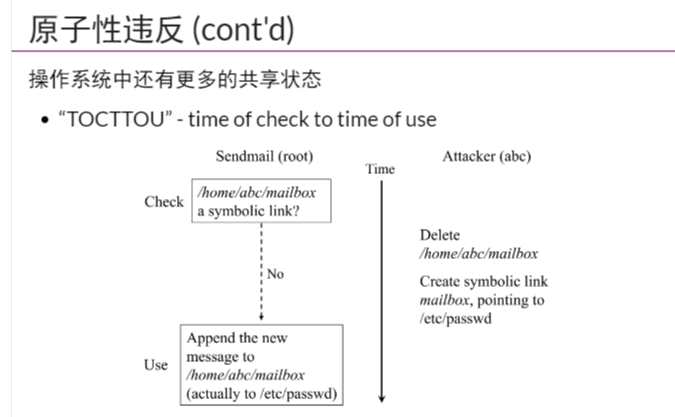
解决这个问题,其实就是解决数据竞争的问题:
即我们给共享状态加锁
违反顺序:
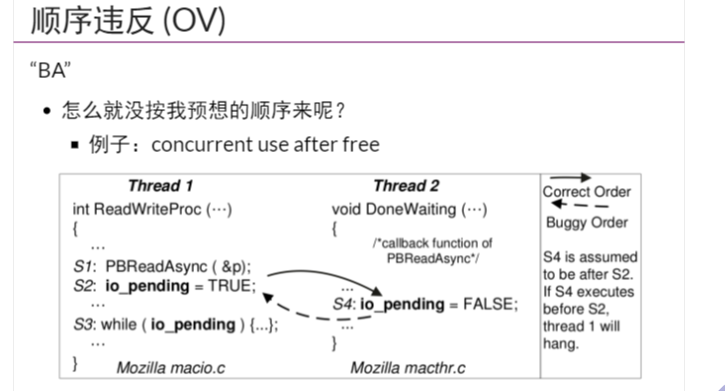
这个也是因为突然的中断(与上面不同的是我们并不要求这个操作是原子的)
然后导致对于共享状态的数据竞争,某一个本不应该出现的状态先出现了
解决方法其实也是加锁,同时为了顺序一致,还有进行同步(用条件变量)
《并发 Bug 的应对 (防御性编程、运行时检查;Sanitizers) [南京大学2023操作系统-P13] (蒋炎岩)》
《死锁和lock ordering》

破除死锁其他三条在实际中(如果是想用互斥锁来解决问题的话)是十分困难的
如:
避免互斥:如果本来就是要用互斥锁,那么不就矛盾了吗
避免 持有并等待 与 非抢占
对于封装 和 性能 (并发)来说不太友好
如破除 持有并等待 直接在强锁的时候上把大锁
性能降低 而且 由于封装 很多细节我们不知道,
可能写着写着,大锁就被写没了,或写错了
如破除 非抢占
当强不到的时候释放已经抢到的锁,然后回退到强锁之前的代码,再次尝试强锁
这个回退的过程很难,特别是在封装了函数之后,还要不断的释放已经分配的资源
在效率上偏低
但是避免循环等待可以通过我们人为地组织抢锁的顺序,让抢锁的顺序形成有向无环图
用拓扑序来得到一个可行的顺序
如哲学家吃饭问题:
我们的抢锁方式是:都先抢锁的编号最小的那个(都抢最大的也可以)
这样会形成
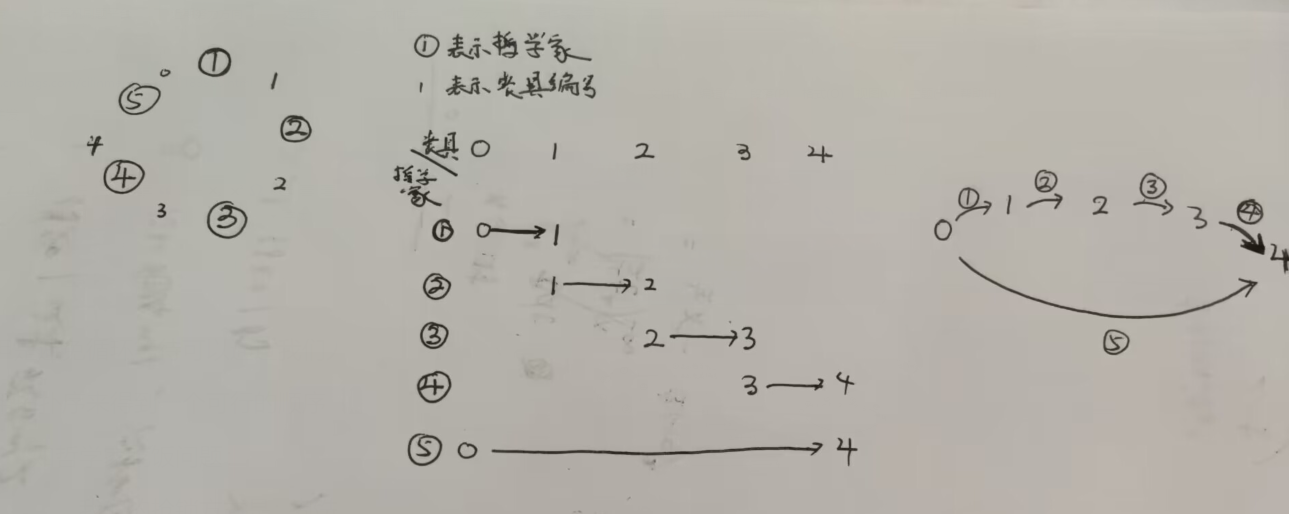
这样无论哪一个哲学家抢锁,都不会造成死锁的局面
但是:

于是有如下:
《BUG本质和防御性编程》


其实我们在代码中做出加假设是有损失的
比如在支付宝中我们定义balance变量代表剩余金钱
但是变量丢失了现实生活中金钱数不会溢出的现象
所以有以下的方法:

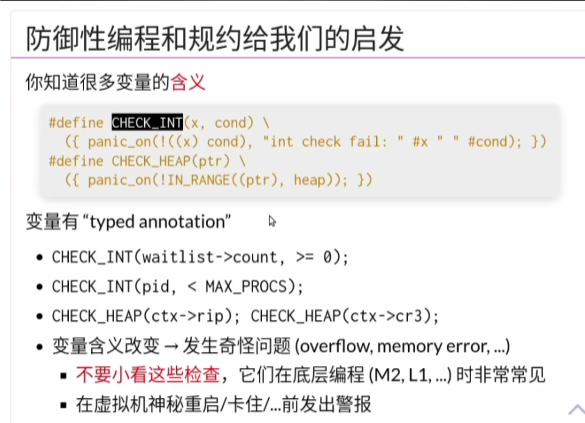
xv6 自旋锁实现,xv6 自旋锁是防御性编程的典范。
他假设锁的使用者会犯各种类型的错误,包括 AA 型死锁、double release、释放非本处理器持有的锁等。
这里AA型死锁是 某个线程在lock 后 再 lock 则自己等待自己释放锁,会死锁
#include "thread-sync.h"
#include "thread.h"
struct cpu
{
int ncli;
};
struct spinlock
{
const char *name;
int locked;
struct cpu *cpu;
};
// panic is meaning of 惶恐不安;
//__FILE__用以指示本行语句所在源文件的文件名
//__LINE__用以指示本行语句的所在行
//__VA_ARGS__可变参数列表,将...中的参数打印出来
// stderr为标准错误输出
// abort()中止程序执行,直接从调用的地方跳出。
#define panic(...) \
do \
{ \
fprintf(stderr, "Panic %s:%d", __FILE__, __LINE__); \
fprintf(stderr, __VA_ARGS__); \
fprintf(stderr, "\n"); \
abort(); \
} while (0)
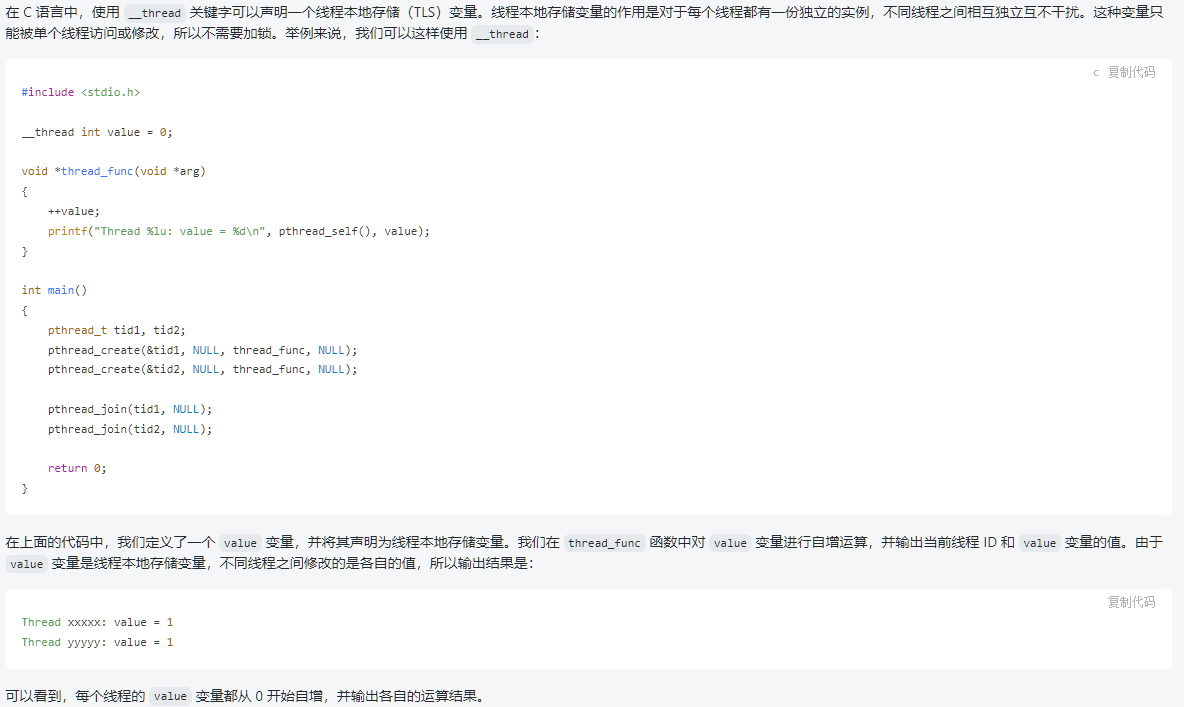
//__thread 是 C 语言中的一个关键字,可以用它来声明线程本地存储(TLS),
// 它被用于定义一个线程独有的变量。通过使用 __thread 声明的变量,我们可以保证在同一个程序中,
// 不同的线程访问该变量时,
// 每个线程所看到的变量值都是不同的。这种变量只能被单个线程访问或修改,所以不需要加锁。
__thread struct cpu lcpu;
struct cpu *mycpu()
{
return &lcpu;
}
void pushcli(void)
{
// because the __thread ,this operator is atomic
mycpu()->ncli += 1;
}
void popcli(void)
{
// the mean the thread has release more than twice
if (--mycpu()->ncli < 0)
panic("popcli");
}
int holding(struct spinlock *lock)
{
int r;
pushcli();
// lock->cpu==mycpu() is to judge this holding if is re?
// if Yes ,Then have AA dead lock promble
r = (lock->locked && lock->cpu == mycpu());
popcli();
return r;
}
void acquire(struct spinlock *lk)
{
pushcli();
if (holding(lk))
panic("acquire");
while (atomic_xchg(&lk->locked, 1) != 0)
;
__sync_synchronize();
// this mean the thread has get the lock
lk->cpu = mycpu();
}
void release(struct spinlock *lk)
{
if (!holding(lk))
panic("release");
// after release ,the lock don't know it belong to who
lk->cpu = 0;
__sync_synchronize();
// atmoicly make lk->locked=0
asm volatile("movl $0, %0"
: "+m"(lk->locked)
:);
popcli();
}
struct spinlock lk;
#define N 10000000
long long sum = 0;
void Tworker(int tid)
{
lcpu = (struct cpu){.ncli = 0};
for (int i = 0; i < N; i++)
{
acquire(&lk);
sum++;
release(&lk);
}
}
void initlock(struct spinlock *lock, char *name)
{
lock->cpu = 0;
lock->locked = 0;
lock->name = name;
}
int main()
{
initlock(&lk, "spinlock");
for (int i = 0; i < 2; i++)
{
create(Tworker);
}
join();
printf("sum = %lld \n", sum);
return 0;
}
《自动运行时检查》
所谓自动运行时检查也就是写一个程序,在另一个并发程序运行时
不断地检查是否有不合法的地方
同时也可以简单地 通过printf (上面的panic) 和 在认为不完全安全的地方加上assert
达到快速地,更早地发现BUG
《练习》
《Linux实践学习》
本次用到的命令:
在linux的系统调用中有几个API
其中比较常见的为:
fork(),wait(),exec()系列命令
(具体在操作系统导论中的P29)
如下是运用上述API的c代码:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/wait.h>
int main(int argc, char *argv[])
{
printf("hello world (pid:%d)\n", (int)getpid());
// fork()复制了一个与当前完全相同的进程,从此处开始执行
// 在子进程中fork()返回的值为0
// 在父进程中,即产生子进程的进程中,fork()返回的是子进程的PID
int rc = fork();
if (rc < 0)
{
fprintf(stderr, "fork failed\n");
exit(1);
}
else if (rc == 0)
{
printf("hello ,I am child (pid:%d)\n", (int)getpid());
char *myargs[3];
// 要执行的程序名(命令名),具体看博客
myargs[0] = strdup("wc");
// 参数,
myargs[1] = strdup("p3.c");
// 规定
myargs[2] = NULL;
// 那么上述的在linux中执行的命令为:
// 在系统中找到wc命令
// 然后执行相当于在终端输入wc p3.c 这个命令的效果
execvp(myargs[0], myargs);
// execvp相当于将执行他的当前进程给占有(即没有开启新进程)
// 然后将这个进程中的资源(代码和数据)给覆盖了,然后执行
// 当然同时execvp的成功调用永不会返回
// 下面这句话也不会被执行
printf("this shouldn't print out\n");
}
else
{
int wc = wait(NULL);
printf("hello I am parent of %d (wc:%d) (pid:%d)\n", rc, wc, (int)getpid());
}
return 0;
}
为什么这样设计API?
可能在上面的程序也有点感觉了
我们是不是可以利用这些简单的API来设计一下复杂(简单)的命令?
linux的命令正是通过调用这些API来实现的
比如,如下这个程序实现的命令:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/wait.h>
int main(int argc, char *argv[])
{
// 程序目标:
/*创建一个新的线程实现linux命令中的重定向wc p4.c > p4.output*/
printf("hello world (pid:%d)\n", (int)getpid());
// fork()复制了一个与当前完全相同的进程,从此处开始执行
// 在子进程中fork()返回的值为0
// 在父进程中,即产生子进程的进程中,fork()返回的是子进程的PID
int rc = fork();
if (rc < 0)
{
fprintf(stderr, "fork failed\n");
exit(1);
}
else if (rc == 0)
{
printf("hello ,I am child (pid:%d)\n", (int)getpid());
close(STDOUT_FILENO);
open("./p4.output", O_CREAT | O_WRONLY | O_TRUNC, S_IRWXU);
char *myargs[3];
// 要执行的程序名(命令名),具体看博客
myargs[0] = strdup("wc");
// 参数,
myargs[1] = strdup("p4.c");
// 规定
myargs[2] = NULL;
// 那么上述的在linux中执行的命令为:
// 在系统中找到wc命令
// 然后执行相当于在终端输入wc p4.c 这个命令的效果
execvp(myargs[0], myargs);
// execvp相当于将执行他的当前进程给占有(即没有开启新进程)
// 然后将这个进程中的资源(代码和数据)给覆盖了,然后执行
// 当然同时execvp的成功调用永不会返回
// 下面这句话也不会被执行
printf("this shouldn't print out\n");
}
else
{
int wc = wait(NULL);
}
return 0;
}
copy了代码运行了一下吗?跑不起来对吧,没错我也跑不起来,但是我是真是按照书上写的
没有关系
接下来我们可以很好理解:grep -o foo file | wc -l
管道| ,即是将一个进程的输出链接到内核管道上,同时一个进程的输入也被链接到了同一个管道上
上述命令等价于
grep -o foo file 的结果S
wc -l S
线程相关函数:
在POSIX(IEEEE提出的接口规范,Linux实现了这个接口)线程库中有关线程的函数:
#include<pthread.h>
线程创建:
int pthread_create(
//指向pthread类型的指针,通常是用这个指针与
//我们创建的线程进行交互
pthread_t * thread,
//指定线程可能具有的属性(栈的大小,优先级等)
const pthread_attr_t * attr
//表示线程在名为start _routine的函数上运行
//该函数返回void * ,参数有void *
void* (*start _routine)(void *)
//arg表示参数
void* arg
);
int pthread_create(
pthread_t * thread,
const pthread_attr_t * attr
void* (*start _routine)(void *)
void* arg
);
等待线程完成: int pthread_join( //表示要等待哪一个线程完成 pthread_t thread, /*一个指向 void *型的线程返回值的指针 的指针 即指向指针的指针 */ void** returned )
使用时
#include<stdio.h>
#include<pthread.h>
#include<assert.h>
#include<stdlib.h>
void * func(void * x){
return x;
}
int main()
{
pthread_t p;
int x=10;
int rc=pthread_create(&p,NULL,func,(void*)&x);
if (rc!=0){
printf ("%d\n",rc);
return rc;
}
int *re;
pthread_join(p,(void**)&re);
printf ("the return is %d\n",*re);
return 0;
}
上面的API 有返回值int,即为0则成功
失败返回的是错误号
线程的互斥与同步:
pthread_mutex_t类型代表锁
一般要初始化锁:
pthread_mutex_t lock=PTHREAD_MUTEX_INITIALIZER
或者
int rc=pthread_mutex_init(&lock,NULL);
//必须保证初始化成功
assert(rc==0);
//上锁:
int pthread_mutex_lock(
//pthread_mutex_t *mutex是一个指向锁的指针
pthread_mutex_t *mutex;
);
//释放锁:
int pthread_mutex_unlock(
pthread_mutex_t *mutex;
);
//使线程进入等待:
//cond应该是condition的缩写
int pthread_cond_wait(
pthread_cond_t *cond,
pthread_mutex_t *mutex
);
这里两个参数,第一个参数是该线程进入睡眠
第二个参数是使该线程在睡眠之前释放锁
//使线程被激活
int pthread_cond_signal(
pthread_cond_t *cond
);
具体操作看操作系统导论的P216
在看上面的代码中可能遇到的困难:
《经典线程同步互斥问题》
以下代码要求必须在linux环境下运行
《读者写者问题----读者优先》
使用linux c中的锁与条件变量API 来手动实现 信号量
#include <pthread.h>
#include <assert.h>
#include <semaphore.h>
#include <unistd.h>
// 锁的初始化
void Mutex_init(pthread_mutex_t *mutex)
{
int rc = pthread_mutex_init(mutex, NULL);
// 断言初始化必然成功:
assert(rc == 0);
}
// 条件变量的初始化
void Cond_init(pthread_cond_t *cond)
{
int rc = pthread_cond_init(cond, NULL);
assert(rc == 0);
}
// 锁操作
void Mutex_lock(pthread_mutex_t *mutex)
{
int rc = pthread_mutex_lock(mutex);
assert(rc == 0);
}
// 解锁操作
void Mutex_unlock(pthread_mutex_t *mutex)
{
int rc = pthread_mutex_unlock(mutex);
assert(rc == 0);
}
// 睡眠操作
void Cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex)
{
int rc = pthread_cond_wait(cond, mutex);
assert(rc == 0);
}
// 唤醒操作
void Cond_signal(pthread_cond_t *cond)
{
int rc = pthread_cond_signal(cond);
assert(rc == 0);
}
typedef struct _Sem_t
{
int value;
pthread_cond_t cond;
pthread_mutex_t lock;
} Sem_t;
void init(Sem_t *s, int value)
{
s->value = value;
Mutex_init(&s->lock);
Cond_init(&s->cond);
}
void P(Sem_t *s)
{
Mutex_lock(&s->lock);
if (s->value <= 0)
Cond_wait(&s->cond, &s->lock);
s->value--;
Mutex_unlock(&s->lock);
}
void V(Sem_t *s)
{
Mutex_lock(&s->lock);
s->value++;
Cond_signal(&s->cond);
Mutex_unlock(&s->lock);
}
// 创建线程操作
void Pthread_create(pthread_t *th, const pthread_attr_t *attr, void *(*func)(void *), void *arg)
{
int rc = pthread_create(th, attr, func, arg);
assert(rc == 0);
}
// 等待线程完成操作
void Pthread_join(pthread_t t, void **res)
{
int rc = pthread_join(t, res);
assert(rc == 0);
}
通过上面实现的信号量和PV操作来实现读者写者问题
#include "Semaphore.h"
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
const int N = 1e3;
// 要求:
// 运行多位读者共享资源
// 只运行一位写者在写
// 写者要写之前全部的读者和写者都要退出
// 即读者优先
// mutex用于锁的作用,即使互斥地访问临界区
// writePower用于同步,即决定写在什么时候运行写操作
// mutex要初始化为1,writePower要初始化为1
// 初始化操作的初始值是什么,具体是由Semaphore.h中P()这个函数决定的
// 我设计的P操作是当信息量的值<=0就让其睡眠,而且是在if()语句判断之后在--
Sem_t mutex, writePower;
int readerCnt;
// 假设写者是写书,写者每一次写一本书,即number++;
int number = 0;
void *reader(void *id)
{
while (1)
{
P(&mutex);
readerCnt++;
if (readerCnt == 1)
P(&writePower);
printf("读者%d 正在读书...\n", *(int *)id);
V(&mutex);
// 读书中....用sleep代替
sleep(1);
P(&mutex);
readerCnt--;
printf("读者%d 读完书了...目前还剩下%d个读者\n", *(int *)id, readerCnt);
if (readerCnt == 0)
V(&writePower);
V(&mutex);
// sleep在#include <unistd.h>上
sleep(2);
}
return NULL;
}
void *writer(void *id)
{
while (1)
{
P(&writePower);
printf("写者%d 正在写书\n", *(int *)id);
number++;
printf("写者%d 写书完毕,目前有%d本书\n", *(int *)id, number);
V(&writePower);
sleep(2);
}
return NULL;
}
// argc是描述参数的个数
// argv是参数的集合
int main(int argc, char *argv[])
{
init(&mutex, 1), init(&writePower, 1);
readerCnt = 0;
int readId[N], writeId[N];
pthread_t readPerson[N], writerPerson[N];
for (int i = 1; i <= atoi(argv[1]); i++)
{
readId[i] = i;
Pthread_create(&readPerson[i], NULL, reader, (void *)&readId[i]);
}
for (int i = 1; i <= atoi(argv[2]); i++)
{
writeId[i] = i;
Pthread_create(&writerPerson[i], NULL, writer, (void *)&writeId[i]);
}
// 将下面的代码注释掉后发现一main线程完成,那么上面的全部程序也就结束了?(不太确定)
// 总之,终端上程序会结束
for (int i = 1; i <= atoi(argv[2]); i++)
Pthread_join(writerPerson[i], NULL);
for (int i = 1; i <= atoi(argv[1]); i++)
Pthread_join(readPerson[i], NULL);
return 0;
}
这里我想重点解释一下

pthread_join的作用
在linux上man pthread_join,出现如下:
函数pthread_join()等待线程指定的线程终止。如果该线程已经终止,那么
pthread_join()立即返回。线程指定的线程必须是可连接的。
可以知道如果我们在main函数中调用了这个函数(以上面我的代码为例子)
第一次调用为Pthread_join(writerPerson[1],NULL)
那么main函数阻塞,要一直等待writerPerson[1]这个线程完成
但是可能会问了:

这里不是设计的while无限循环吗?怎么会完成的时候?
对了,所以main函数是一直阻塞的,而且后面的代码都不会得到执行
但是这就够了,能够满足我的需求
因为在这之前全部线程我都创建好了,这些线程不会阻塞
同时一旦main函数中 return 0 了,我的创建的线程也就结束了,
这是我不希望的(我希望他们无限运行下去)
《哲学家就餐问题》
使用linux中的信号量实现
#include "Semaphore.h"
#include <stdio.h>
#include <stdlib.h>
// 表示餐具
sem_t tws[5];
void Init()
{
for (int i = 0; i < 5; i++)
sem_init(&tws[i], 0, 1);
}
void thinking(int id)
{
printf("哲学家%d 正在思考...\n", id);
sleep(1);
}
void eat(int id)
{
printf("哲学家%d 正在吃饭...\n", id);
sleep(1);
printf("哲学家%d 吃饭完毕...\n", id);
}
void getTw(int id)
{
// id小于4的哲学家先拿右手边的餐具
if (id < 4)
{
sem_wait(&tws[(id + 1) % 5]);
sem_wait(&tws[id % 5]);
}
// id为4的哲学家先拿左手边的餐具,避免死锁
else
{
sem_wait(&tws[id % 5]);
sem_wait(&tws[(id + 1) % 5]);
}
}
void setTw(int id)
{
sem_post(&tws[id % 5]);
sem_post(&tws[(id + 1) % 5]);
}
void *action(void *id)
{
int myId = *(int *)id;
while (1)
{
thinking(myId);
getTw(myId);
eat(myId);
setTw(myId);
}
}
int main(int argc, char *argv[])
{
Init();
pthread_t philosopher[5];
int philosopherId[5];
for (int i = 0; i < 5; i++)
{
philosopherId[i] = i;
Pthread_create(&philosopher[i], NULL, action, (void *)&philosopherId[i]);
}
for (int i = 0; i < 5; i++)
Pthread_join(philosopher[i], NULL);
return 0;
}
信号量具体使用看操作系统导论P263
《死锁的避免之银行家算法》
在此之前首先要了解一下
安全性算法 (具体看书P94,或 博客)
现在我们将安全性算法写成 isSecure()函数
如下为代码:
bool isSecure(int id, int t[])
{
// 先检查各个申请的资源是否都小于预期的Need[id]
for (int i = 1; i <= m; i++)
if (t[i] > Need[id][i])
{
/* cout << i << " " << id << " " << t[i] << " " << Need[id][i] << endl; */
cout << "请求的资源大于系统预期!" << endl;
return false;
}
// 在检查各个申请的资源是否都小于剩余值Available[]
for (int i = 1; i <= m; i++)
if (t[i] > Available[i])
{
cout << "请求的资源大于系统剩余资源" << endl;
return false;
}
// 然后看这个申请是否会影响后面的资源分配产生系统不安全
// 即看是否能找出一个序列使得系统安全
// 双层for循环查找是否有某一个线程可以执行
// 第一层for循环保证每一个线程都被查询到
// 第二层for循环保证每一次要不选不出,要不选出一个线程
bool Finish[N];
int Work[M], cA[N][M], cN[N][M];
for (int i = 1; i <= n; i++)
Finish[i] = false;
for (int i = 1; i <= m; i++)
Work[i] = Available[i] - t[i];
// 复制,以便下面进行回溯
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++)
cA[i][j] = Allocation[i][j], cN[i][j] = Need[i][j];
for (int i = 1; i <= m; i++)
cA[id][i] += t[i], cN[id][i] -= t[i];
queue<int> q;
// 之所以可以用两层for循环解决问题是因为有单调性
// 无论先拿那个线程(无论是线程的所需资源多还是少)
// 只要能够申请到,那么都会还回来,即Work是越来越多的
/* cout << "t[i]:" << endl;
for (int i = 1; i <= m; i++)
cout << t[i] << " ";
cout << endl;
cout << "cN:" << endl;
for (int i = 1; i <= n; i++)
{
for (int j = 1; j <= m; j++)
cout << cN[i][j] << " ";
cout << endl;
} */
for (int i = 1; i <= n; i++)
{
for (int j = 1; j <= n; j++)
{
if (Finish[j])
continue;
bool flag = true;
for (int k = 1; k <= m; k++)
if (Work[k] < cN[j][k])
{
flag = false;
break;
}
if (flag)
{
// 找到了一个满足的线程:
Finish[j] = true;
for (int k = 1; k <= m; k++)
Work[k] += cA[j][k];
q.push(j);
break;
}
}
}
for (int i = 1; i <= n; i++)
if (!Finish[i])
return false;
cout << "申请成功!安全序列为:" << endl;
while (q.size())
{
int top = q.front();
q.pop();
cout << "线程" << top;
if (q.size() != 0)
cout << "-->";
}
cout << endl;
return true;
}
银行家算法描述如下:
int Max[N][M],Allocation[N][M],Available[M],Need[N][M];
Max[i][j]:表示线程i需要资源j的最大数量,这个在计算中是不变的,即开始就定好了
Allocation[i][j]: 表示线程i已经分配资源j的数量
Need[i][j]: 表示线程i还需要资源j的数量
Need[i][j]=Max[i][j]-Allocation[i][j]
Available[i]:表示资源i还剩下的数量
1.首先线程i申请资源 Request[M],Requset[j]表示资源j需要的数量
2.然后继续判断
判断是否 Requset[j]<=Need[i][j],因为如果不符,则说明与预期的申请数量不一样
判断是否 Requset[j]<=Available[i][j],如果不符说明申请的资源过多
3.然后尝试分配(用副本数据进行模拟),即开始就进行安全性算法检测
看这一次分配是否会让以后系统再进行分配时不安全
4.通过安全性算法,则真实进行分配(即改动公共数据)
否则让这次申请的线程等待
#include <iostream>
#include <algorithm>
#include <cstring>
#include <queue>
using namespace std;
const int N = 10, M = 10;
int Max[N][M], Allocation[N][M], Need[N][M], Available[M], Working[N];
int n, m;
void init()
{
cout << "请输入线程数n和资源数m:" << endl;
cin >> n >> m;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++)
Allocation[i][j] = 0;
for (int i = 1; i <= n; i++)
{
cout << "请输入第" << i << "个线程需要各个资源的最大值:" << endl;
for (int j = 1; j <= m; j++)
{
cin >> Max[i][j];
Need[i][j] = Max[i][j] - Allocation[i][j];
}
}
cout << "请输入各个资源初始值:" << endl;
for (int i = 1; i <= m; i++)
cin >> Available[i];
for (int i = 1; i <= n; i++)
Working[i] = true;
}
bool isSecure(int id, int t[])
{
// 先检查各个申请的资源是否都小于预期的Need[id]
for (int i = 1; i <= m; i++)
if (t[i] > Need[id][i])
{
/* cout << i << " " << id << " " << t[i] << " " << Need[id][i] << endl; */
cout << "请求的资源大于系统预期!" << endl;
return false;
}
// 在检查各个申请的资源是否都小于剩余值Available[]
for (int i = 1; i <= m; i++)
if (t[i] > Available[i])
{
cout << "请求的资源大于系统剩余资源" << endl;
return false;
}
// 然后看这个申请是否会影响后面的资源分配产生系统不安全
// 即看是否能找出一个序列使得系统安全
// 双层for循环查找是否有某一个线程可以执行
// 第一层for循环保证每一个线程都被查询到
// 第二层for循环保证每一次要不选不出,要不选出一个线程
bool Finish[N];
int Work[M], cA[N][M], cN[N][M];
for (int i = 1; i <= n; i++)
Finish[i] = false;
for (int i = 1; i <= m; i++)
Work[i] = Available[i] - t[i];
// 复制,以便下面进行回溯
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++)
cA[i][j] = Allocation[i][j], cN[i][j] = Need[i][j];
for (int i = 1; i <= m; i++)
cA[id][i] += t[i], cN[id][i] -= t[i];
queue<int> q;
// 之所以可以用两层for循环解决问题是因为有单调性
// 无论先拿那个线程(无论是线程的所需资源多还是少)
// 只要能够申请到,那么都会还回来,即Work是越来越多的
/* cout << "t[i]:" << endl;
for (int i = 1; i <= m; i++)
cout << t[i] << " ";
cout << endl;
cout << "cN:" << endl;
for (int i = 1; i <= n; i++)
{
for (int j = 1; j <= m; j++)
cout << cN[i][j] << " ";
cout << endl;
} */
for (int i = 1; i <= n; i++)
{
for (int j = 1; j <= n; j++)
{
if (Finish[j] || Working[j] == false)
continue;
bool flag = true;
for (int k = 1; k <= m; k++)
if (Work[k] < cN[j][k])
{
flag = false;
break;
}
if (flag)
{
// 找到了一个满足的线程:
Finish[j] = true;
for (int k = 1; k <= m; k++)
Work[k] += cA[j][k];
q.push(j);
break;
}
}
}
for (int i = 1; i <= n; i++)
if (!Finish[i] && Working[i])
return false;
cout << "申请成功!安全序列为:" << endl;
while (q.size())
{
int top = q.front();
q.pop();
cout << "线程" << top;
if (q.size() != 0)
cout << "-->";
}
cout << endl;
return true;
}
void printState()
{
cout << "进程名\t"
<< "最大需求量\t"
<< "尚需求量\t"
<< "已分配量\t"
<< "执行结束否"
<< endl;
cout << "\t";
for (int i = 1; i <= 3; i++)
{
char c = 'A';
for (int j = 1; j <= m; j++)
cout << char(c + j - 1) << " ";
cout << "\t"
<< "\t";
}
cout << endl;
for (int i = 1; i <= n; i++)
{
cout << "线程" << i << "\t";
for (int j = 1; j <= m; j++)
cout << Max[i][j] << " ";
cout << "\t";
for (int j = 1; j <= m; j++)
cout << Need[i][j] << " ";
cout << "\t";
for (int j = 1; j <= m; j++)
cout << Allocation[i][j] << " ";
cout << "\t";
if (Working[i])
cout << "working\n";
else
cout << "finished\n";
}
cout << "资源剩余数:\t" << endl;
for (int i = 1; i <= m; i++)
cout << Available[i] << " ";
cout << endl;
}
// allocate是用来每一次进行分配的函数
// 需要告知需要分配的线程的id和资源
bool allocate(int id)
{
int t[M];
cout << "线程" << id << "需要的资源:" << endl;
for (int i = 1; i <= m; i++)
cin >> t[i];
if (!isSecure(id, t))
{
cout << "无安全序列申请不成功!" << endl;
return false;
}
// 既然成功了那么就真实地改动各个数据
for (int i = 1; i <= m; i++)
Available[i] -= t[i];
for (int i = 1; i <= m; i++)
Allocation[id][i] += t[i], Need[id][i] -= t[i];
//然后去检查每一个任务是否完成,如果完成,那么标志一下
//这里是用Working[]数组来标志
for (int i = 1; i <= n; i++)
{
bool flag = true;
if (!Working[i])
continue;
for (int j = 1; j <= m; j++)
if (Allocation[i][j] != Max[i][j])
{
flag = false;
break;
}
if (flag)
{
Working[i] = false;
// 同时释放资源:
for (int j = 1; j <= m; j++)
{
Available[j] += Allocation[i][j];
Allocation[i][j] = 0;
Need[i][j] = 0;
}
}
}
/* printState(); */
return true;
}
void first()
{
cout << "请输入" << n << "个线程第一次的申请值" << endl;
for (int i = 1; i <= n; i++)
{
while (!allocate(i))
cout << "请再次输入!" << endl;
}
printState();
}
bool call()
{
cout << "还需要进行资源申请吗?(Y/N)" << endl;
char c;
cin >> c;
if (c == 'N')
return false;
else
{
while (c != 'Y')
{
cout << "输入不正确,请按照要求输入:" << endl;
cin >> c;
}
return true;
}
}
void solve()
{
init();
/* printState(); */
first();
while (1)
{
if (!call())
break;
cout << "请输入线程编号:" << endl;
int id;
cin >> id;
allocate(id);
printState();
}
}
int main()
{
solve();
return 0;
}
样例输入:
5 3
7 5 3
3 2 2
9 0 2
2 2 2
4 3 3
10 5 7
0 1 1
2 0 0
3 0 2
2 1 1
0 0 2
本文作者:次林梦叶的小屋
本文链接:https://www.cnblogs.com/cilinmengye/p/17183990.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步