论文阅读 | FCOS: Fully Convolutional One-Stage Object Detection
论文阅读——FCOS: Fully Convolutional One-Stage Object Detection
概述
目前anchor-free大热,从DenseBoxes到CornerNet、ExtremeNet,以及最近的FSAF、FoveaBox,避免了复杂的超参数设计,而且具有很好的检测效果。本文作者提出了一种全卷积的单阶段目标检测算法,类似于语义分割的做法使用像素级预测。该检测框架简单有效,而且可以方便地用于其他任务。
简介
再啰嗦一下基于anchor的检测算法的缺陷:
1、检测效果受尺度、宽高比以及anchor box的数目影响。比如RetinaNet,改变这些超参数对COCO数据集上的AP影响高达4%;
2、泛化能力差,目标形变较大时难以检测,尤其是小目标。新任务需要重新设计anchor的超参数;
3、大量冗余anchor box导致正负样本失衡;
4、IoU计算造成运算资源和内存浪费。

FCOS回归位置的相对偏移。对于图1右侧一个重叠区域的位置应该回归哪个bbox的问题,可以通过FPN解决。远离目标中心的位置产生很多低质量的预测框,作者采用center-ness分支来预测像素与对应bbox中心的偏差,将该得分用于降低低质量bbox的权重。
方法
像素级预测;利用多层次预测来提高训练中的召回率,解决训练中重叠边框造成的歧义;使用center-ness分支抑制检测到的低质量包围盒,提高性能。

一、FCOS
回归的target就是4D向量(该位置到bbox四边的距离)。如果一个位置对应多个bbox(称作模糊样本),简单地将面积最小的bbox作为它的回归目标。充分利用了前景样本进行训练。
没有训练多类分类器,而是C个二分类器。
损失函数如下:
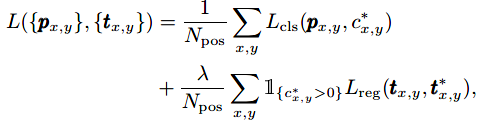
其中,Lcls是focal loss,Lreg是IoU loss,论文中λ取1.
预测过程中pxy>0.05即认为是正样本。
二、基于FPN的多层预测
问题:
1、CNN中最后的feature map的大stride会使得召回率偏低(在基于anchor的方法中可用适当降低IoU阈值来提升召回率)——可以利用多层FPN解决,召回率甚至优于RetinaNet
2、重叠区域的位置应该回归哪个bbox的问题——FPN(重叠往往发生在不同大小的目标之间)
使用5层feature map{p3,p4,p5,p6,p7},其中p3、p4、p5是由CNN的feature map c3、c4、c5通过1*1卷积层以及横向连接生成的,p6和p7是p5、p6分别通过步长为2的卷积层生成的。
每层直接限制边界框回归的范围:如果一个位置满足max(l*, t*, r*, b*)>mi或者max(l*, t*, r*, b*)<mi-1就设为负样本。其中mi是第i个特征层需要回归的最大距离。文中设置m2、m3、m4、m5、m6、m7分别为0,64,128,256,512和无穷大。
三、Center-ness
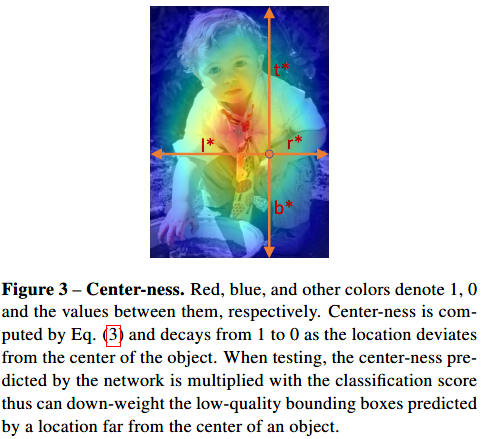
使用了FPN以后,像素级预测效果还是不行,为什么呢?远离目标中心的位置产生了大量低质量的预测框。简单地增加了一个单层分支,用于预测一个位置的center-ness(神马东西?从名字看完全不知道这是要干嘛的啊有木有。。。),也就是该位置到它负责的目标中心的距离。
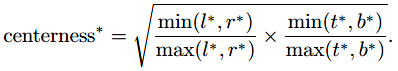
范围0-1,训练采用交叉熵损失。测试时,将centerness与类别得分相乘。再通过NMS后处理。

实验
训练细节:
backbone:ResNet-50,超参数与RetinaNet相同,使用ImageNet预训练,输入图像大小:1333*800左右
FPN的使用:

center-ness的使用:

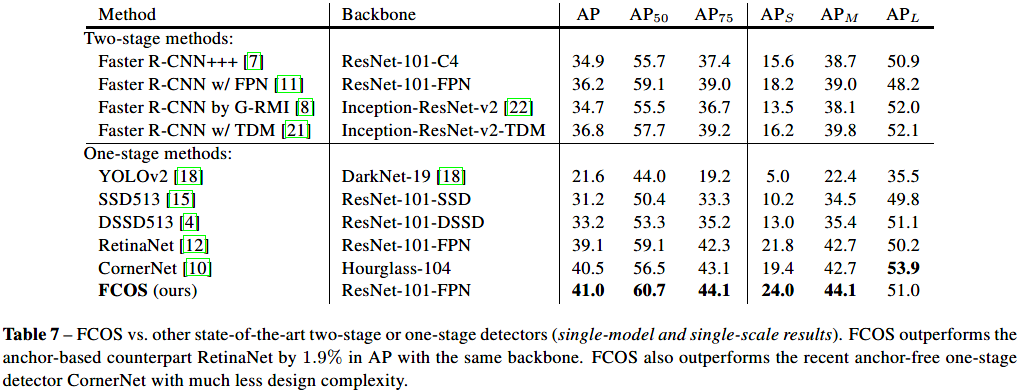
COCO数据集上的AP对比:
将FCOS用于RPN:


总结
FCOS利用语义分割的思想,逐像素做目标检测,但是远离目标中心的位置会产生大量的低置信度bbox,为了过滤掉这些框,在类别预测的分支中添加了一个支路用于预测像素点到目标中心的距离(只是一个权值度量,不是真的距离,就是说如果该位置距离中心很远,那么它的centerness就很小,而框的最终置信分是框的score*centerness所以也会很小,这样就过滤掉了)。同时注意到语义分割做目标检测的算法都用到了多层次的思想(结合FPN),将不同大小的目标划分到不同层处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号