论文阅读 | FoveaBox: Beyond Anchor-based Object Detector
论文阅读——FoveaBox: Beyond Anchor-based Object Detector
概述
这是一篇ArXiv 2019的文章,作者提出了一种新的anchor-free的目标检测框架FoveaBox,直接学习目标存在的可能性(预测类别敏感的语义map)和bbox的坐标(为可能存在目标的每个位置生成无类别的bbox)。该算法的单模型(基于ResNeXt-101-FPN )在COCO数据集上的AP达到42.1%。代码尚未开源。
介绍
anchor弊端:额外的超参数设计很复杂;设计的anchor泛化能力差;密集的anchor采样使得正负样本严重失衡。
受人眼的启发,视觉区域(目标)的中心有着最高的视觉灵敏度。FoveaBox联合预测对象的中心区域可能存在的位置以及每个有效位置的边界框。
FoveaBox
FoveaBox的框架:
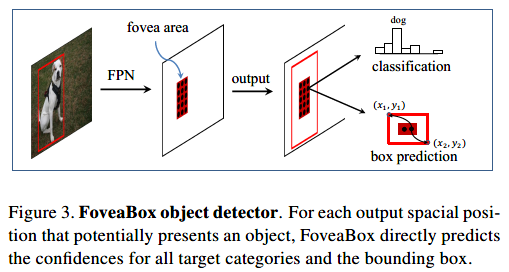
FoveaBox包括一个backbone和两个子网。第一个子网对主干网的输出执行每个像素的分类,第二个子网预测相应位置的bbox。
FPN的使用:
每层金字塔用于检测不同大小的目标,论文中作者设计的金字塔{Pl},其中l=3,4,5,6,7,Pl的分辨率是输入的1/2^l。金字塔所有层的通道数都是256。

每层特征金字塔的box的有效尺度范围:
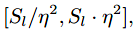

S0取16,η取2.
Object Fovea
从gt box到特征金字塔Pl的映射:
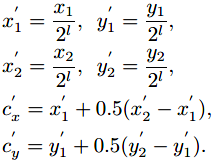
正样本区域(fovea):

正样本区域相比于原始区域有一定程度的缩小。σ1是收缩因子(文中取0.3)。同样使用上面的公式,因子记为σ2(文中取0.4),产生负样本区域。训练时类别损失采用focal loss。
Box Prediction
位置回归则是学习一个变换:

其中z=sqrt(Sl)是归一化因子,将输出空间投影到以1为中心的空间,使学习过程更稳定。函数首先将feature map的坐标(x,y)映射到输入图像,然后计算归一化的偏移,最后正则化到log空间。回归损失采用Smooth L1损失。
优化
4GPUs,SGD,8 imgs/minibatch
训练细节:270k次迭代(180k前:lr=0.005,180k-240k:lr=0.0005,240k后:lr=5e-5)
使用权值衰减(0.0001),momentum(0.9)
ignore区域的location不参与类别训练,但参与回归训练(标注为对应的位置目标)。
推理
置信度阈值:0.05,NMS阈值:0.5,没有使用bbox voting、Soft-NMS、测试阶段图像扩增等策略。
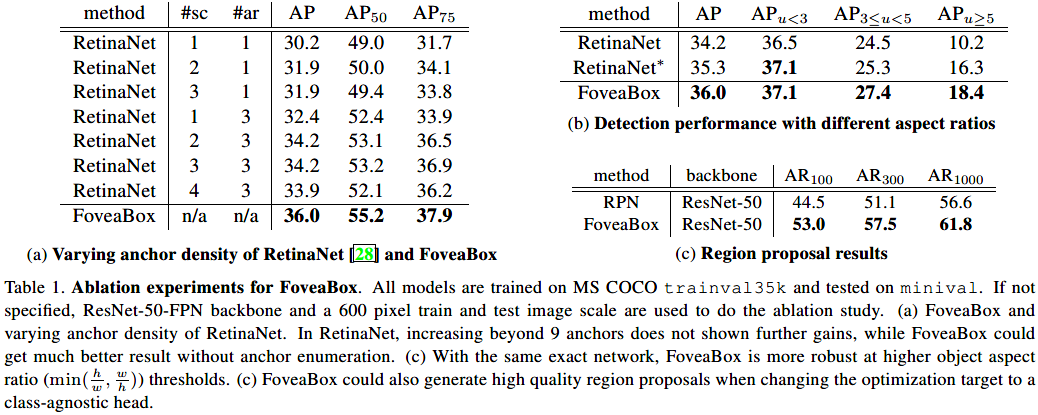
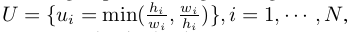
RetinaNet与FoveaBox检测对比:

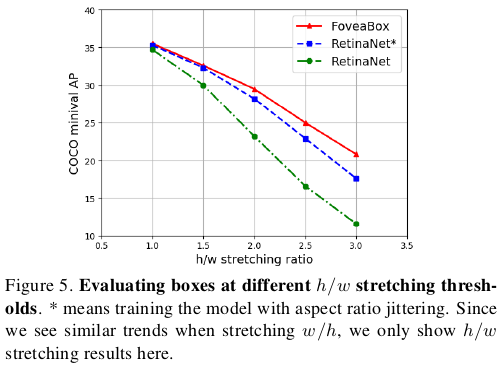
FoveaBox检测结果:
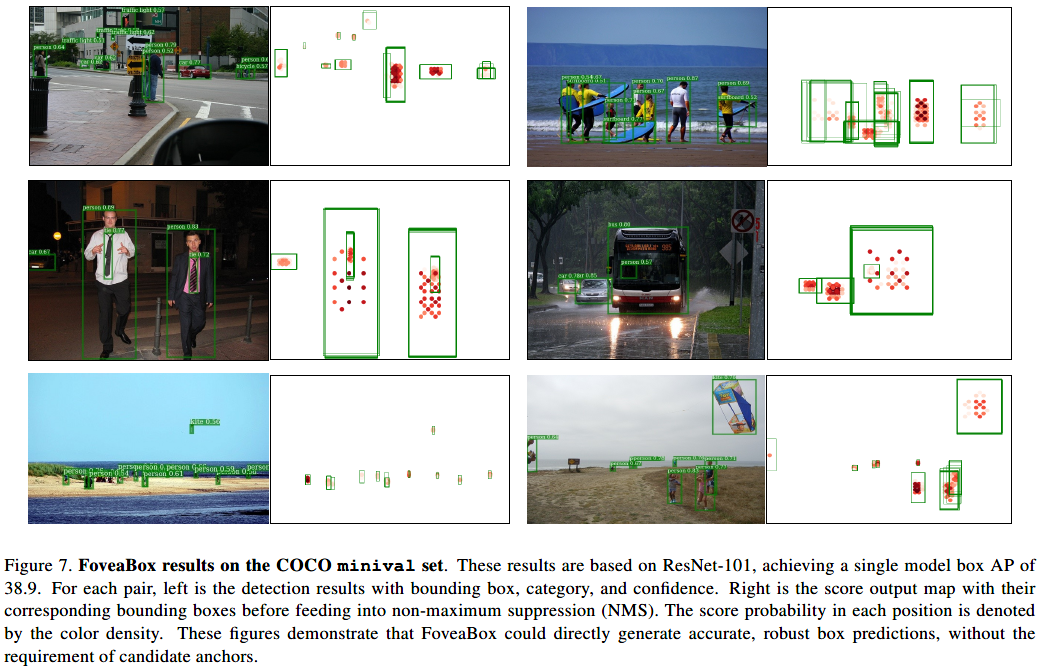
SOTA对比:
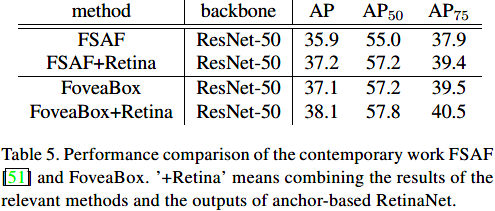
与FSAF的对比:
总的来说,这是一篇利用语义分割的思想来做目标检测的文章,通过定义fovea区域(也就是正样本区域)来限制类别学习和预测的大致范围,所以没有出现类似于FCOS算法中远离目标中心的位置会产生大量低置信度bbox的情况。

