ElasticSearch(七)集群的搭建
一、集群有什么用
1.1 群集的含义与产生
群集(或称为集群)是由多台主机构成,但对外,只表现为一个整体,只提供一个访问入口(域名或IP),相当于一台大型计算机。互联网应用中,随着站点对硬件性能、响应速度、服务稳定性、数据可靠性等要求越来越高,单台服务器开始无法满足负载均衡及高可用的需求,群集因此应运而生。
1.2 群集的种类
根据集群针对的目标差异,可分为三种:
- 高可用群集 (High Availability Cluster) :高可用(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。如果系统每运行100个时间单位,会有1个时间单位无法提供服务,我们说系统的可用性是99%。提高应用系统的可靠性、尽可能地减少中断时间为目标,确保服务的连续性,达到高可用(HA) 的容错效果。HA的工作方式包括双工和主从两种模式,双工即所有节点同时在线;主从则只有主节点在线,但当出现故障时从节点能自动切换为主节点。例如:“故障切换”、“双机热备” 等。
- 负载均衡群集(Load Balance Cluster) :将流量均衡的分布在不同的节点上,每个节点都可以处理一部分负载,并且可以在节点之间动态分配负载,以实现平衡。主要目的提高应用系统的响应能力、尽可能处理更多的访问请求、减少延迟为目标,获得高并发、高负载(LB)的整体性能。
- 高性能群集(High Performance Computer Cluster) :以提高应用系统的CPU运算速度、扩展硬件资源和分析能力为目标,获得相当于大型、超级计算机的高性能运算(HPC)能力。高性能依赖于"分布式运算”、“并行计算” , 通过专用硬件和软件将多个服务器的CPU、内存等资源整合在一起,实现只有大型、超级计算机才具备的计算能力。例如,“云计算”、“网格计算”等。
二、ES集群的基础概念
2.1 集群Cluster
ElasticSearch 是一个分布式的搜索引擎,所以一般由多台物理机组成。而在这些机器上通过配置一个相同的cluster name,让其互相发现从而把自己组织成一个集群。
集群的健康状态,ES集群存在三种健康状态,单节点ES也可以算是一个集群。
- green(绿色):代表所有索引的主分片和副本均已分配且可用,集群是100%可用
- yellow(黄色):主分片已分配且全部主分片可用,但所有的副本不全部可用,可能是缺失,也有可能是某个索引的副本未被分配,可以通过move cancel allocate 命令所属的API进行分配或移动分片到指定节点,使用这里要注意主分片和其副本绝不能在同一节点。此时系统容错性和集群高可用被弱化。
- red(红色):所有的主分片不全部可用,这代表很有可能存在丢失数据的风险。如果只有一个单节点Elasticsearch那么属于一种yellow状态,因为没有副本。
2.2 节点Node
ElasticSearch 是以集群的方式运行的,而节点是组成ES集群的基本单位,所以每个 ElasticSearch 实例就是一个节点,每个物理机器上可以有多个节点,使用不同的端口和节点名称。
节点按主要功能可以分为三种:主节点(Master Node),协调节点(Coordianting Node)和数据节点(Data Node)。下面简单介绍下:
- 主节点:处理创建,删除索引等请求,维护集群状态信息。可以设置一个节点不承担主节点角色
- 协调节点:负责处理请求。默认情况下,每个节点都可以是协调节点。
- 数据节点:用来保存数据。可以设置一个节点不承担数据节点角色
2.3 分片
为了将数据添加到 Elasticsearch中,我们需要索引(index)——一个存储关联数据的地方,而实际上索引只是一个用来指向一个或多个 分片(shards) 的 逻辑命名空间 (logical namespace)。在ES中所有数据都存储于索引(index) 之上,但实际索引只是维护了与多个分片之间的联系,数据则是被路由到多个分片。例如一个索引有5个分片,则该索引将会有0,1,2,3,4,这五个分片 ,起指定每个文档数据存储在哪个分片是根据路由运算公式 has(_routing)%number_of_primary_shards 指定,使数据均匀分布在集群当中。
分片分为:主分片(Primary shard)和副本分片(Replica shard) :
- 主分片Primary shard:用于解决数据水平扩展的问题,通过主分片,可以将数据分布到集群内的所有节点之上,将一份索引数据划分为多小份的能力,允许水平分割和扩展容量。多个分片可以响应请求,提高性能和吞吐量。一个节点(Node)一般会管理多个分片,分片有两种,主分片和副本分片。
- 副本分片Replica shard:副本分片只是一个主分片的拷贝。副本分片作为硬件故障时保护数据不丢失的冗余备份,从而提高整个集群的容错性,并为搜索和返回文档等读操作提供服务,且需要注意的是副本分片不能与主分片在同一个节点。。一般来说,Elasticsearch 会尽量把一个索引的不同分片存储在不同的主机上,分片的副本也尽可能存在不同的主机上,这样可以提高容错率,从而提高高可用性。
- 一个Index数据在物理上被分布在多个主分片中,每个主分片只存放部分数据,每个主分片可以有多个副本。
- 主分片的作用是对索引的扩容,使一个索引的容量可以突破单机的限制。
- 副本分片是对数据的保护,每个主分片对应一个或多个副本分片,当主分片所在节点宕机时,副本分片会被提升为对应的主分片使用。
- 一个主分片和它的副本分片,不会分配到同一个节点上。
- 一个分片就是一个Lucene实例,并且它本身就是一个完整的搜索引擎。应用程序不会和它直接通信。
- 当索引创建完成的时候,主分片的数量就固定了,如果要修改需要重建索引,代价很高,如果要修改则需Reindex,但是复制分片的数量可以随时调整。
文档路由到对应的分片的公式如下 👇
shard = hash(routing) % number_of_primary_shards
分片的设定:
- 对于生产环境中分片的设定,需要提前做好容量规划,主分片数是在索引创建的时候预先设定,事后无法修改
- 分片数设置过小
- 导致后续无法增加节点实现水平扩展
- 单个分片的数据量太大,导致数据重新分配耗时
- 分片数设置过大,7.0开始,默认主分片设置成1,解决了over-sharding的问题
- 影响搜索结果的相关性打分,影响统计结果的准确性
- 单个节点上过多的分片,会导致资源浪费,同时也会影响性能
- 分片数设置过小
用图形表示出来可能是这样子的:
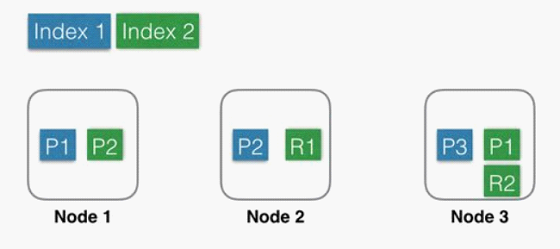
- Index 1:蓝色部分,有3个shard,分别是P1,P2,P3,位于3个不同的Node中,这里没有Replica。
- Index 2:绿色部分,有2个shard,分别是P1,P2,位于2个不同的Node中。并且每个shard有一个replica,分别是R1和R2。基于系统可用性的考虑,同一个shard的primary和replica不能位于同一个Node中。这里Shard1的P1和R1分别位于Node3和Node2中,如果某一刻Node2发生宕机,服务基本不会受影响,因为还有一个P1和R2都还是可用的。因为是主备架构,当主分片发生故障时,需要切换,这时候需要选举一个副本作为新主,这里除了会耗费一点点时间外,也会有丢失数据的风险。
三、ES集群搭建的步骤
1、下载ElasticSearch的安装包:
最新版本:https://www.elastic.co/cn/downloads/elasticsearch
过去版本:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.3-linux-x86_64.tar.gz
解压文件,将elasticsearch安装在/usr/local目录下
tar -zxvf elasticsearch-7.17.3-linux-x86_64.tar.gz -C /usr/local
cd /usr/local/
2、修改 jvm.options 配置
## 修改内存大小 ,内存小我就设置成这样了
-Xms512m
-Xmx512m
3、配置 elasticsearch.yml 文件
# 集群名称,三台集群,要配置相同的集群名称!!!
cluster.name: my-application
# 节点名称
node.name: node-1
# 是否有资格被选举为master,ES默认集群中第一台机器为主节点
node.master: true
# 是否存储数据
node.data: true
#最⼤集群节点数,为了避免脑裂,集群节点数最少为 半数+1
node.max_local_storage_nodes: 3
# 数据目录
path.data: /usr/local/node-1/data
# log目录
path.logs: /usr/local/node-1/logs
# 修改 network.host 为 0.0.0.0,表示对外开放,如对特定ip开放则改为指定ip
network.host: 0.0.0.0
# 设置对外服务http端口,默认为9200
http.port: 9200
# 内部节点之间沟通端⼝
transport.tcp.port: 9300
# 写⼊候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["localhost:9300", "localhost:9301", "localhost:9302"]
# 初始化⼀个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
# 设置集群中N个节点启动时进行数据恢复,默认为1
gateway.recover_after_nodes: 3
# 下面的两个配置在安装elasticsearch-head的时候会用到
# 开启跨域访问支持,默认为false
http.cors.enabled: true
# 跨域访问允许的域名地址,(允许所有域名)以上使用正则
http.cors.allow-origin: "*"
#关闭xpack
xpack.security.enabled: false
4、复制当前es构建其他数据节点
# 分别拷贝三份文件
cp -r /usr/local/elasticsearch-7.17.3/ /usr/local/node-1
cp -r /usr/local/elasticsearch-7.17.3/ /usr/local/node-2
cp -r /usr/local/elasticsearch-7.17.3/ /usr/local/node-3
5、修改node-2和node-3两个数据节点的配置文件,先修改node-2数据节点
# 集群名称,三台集群,要配置相同的集群名称!!!
cluster.name: my-application
# 节点名称
node.name: node-2
# 是否有资格被选举为master,ES默认集群中第一台机器为主节点
node.master: true
# 是否存储数据
node.data: true
#最⼤集群节点数,为了避免脑裂,集群节点数最少为 半数+1
node.max_local_storage_nodes: 3
# 数据目录
path.data: /usr/local/node-2/data
# log目录
path.logs: /usr/local/node-2/logs
# 修改 network.host 为 0.0.0.0,表示对外开放,如对特定ip开放则改为指定ip
network.host: 0.0.0.0
# 设置对外服务http端口,默认为9200,可更改端口不为9200
http.port: 9201
# 内部节点之间沟通端⼝
transport.tcp.port: 9301
# 写⼊候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["localhost:9300", "localhost:9301", "localhost:9302"]
# 初始化⼀个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
# 设置集群中N个节点启动时进行数据恢复,默认为1
gateway.recover_after_nodes: 3
# 下面的两个配置在安装elasticsearch-head的时候会用到
# 开启跨域访问支持,默认为false
http.cors.enabled: true
# 跨域访问允许的域名地址,(允许所有域名)以上使用正则
http.cors.allow-origin: "*"
#关闭xpack
xpack.security.enabled: false
6、再先修改node-3数据节点:
# 集群名称,三台集群,要配置相同的集群名称!!!
cluster.name: my-application
# 节点名称
node.name: node-3
# 是否有资格被选举为master,ES默认集群中第一台机器为主节点
node.master: true
# 是否存储数据
node.data: true
#最⼤集群节点数,为了避免脑裂,集群节点数最少为 半数+1
node.max_local_storage_nodes: 3
# 数据目录
path.data: /usr/local/node-3/data
# log目录
path.logs: /usr/local/node-3/logs
# 修改 network.host 为 0.0.0.0,表示对外开放,如对特定ip开放则改为指定ip
network.host: 0.0.0.0
# 设置对外服务http端口,默认为9200,可更改端口不为9200
http.port: 9202
# 内部节点之间沟通端⼝
transport.tcp.port: 9302
# 写⼊候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["localhost:9300", "localhost:9301", "localhost:9302"]
# 初始化⼀个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
# 设置集群中N个节点启动时进行数据恢复,默认为1
gateway.recover_after_nodes: 3
# 下面的两个配置在安装elasticsearch-head的时候会用到
# 开启跨域访问支持,默认为false
http.cors.enabled: true
# 跨域访问允许的域名地址,(允许所有域名)以上使用正则
http.cors.allow-origin: "*"
#关闭xpack
xpack.security.enabled: false
7、创建ES存储数据和log目录,根据之前每个节点的配置文件内配置path进行创建或修改
mkdir -p /usr/local/node-1/data
mkdir -p /usr/local/node-1/logs
mkdir -p /usr/local/node-2/data
mkdir -p /usr/local/node-2/logs
mkdir -p /usr/local/node-3/data
mkdir -p /usr/local/node-3/logs
8、创建普通用户,由于ES需要使用非root用户来启动,所以下面创建一个普通用户
#创建elasticsearch用户组
groupadd elasticsearch
#创建新用户elasticsearch ,设置用户组为elasticsearch ,密码123456
useradd elasticsearch -g elasticsearch -p 123456
#授权,更改/elasticsearch-7.17.3文件夹所属用户及用户组为elasticsearch:elasticsearch
chown -R elasticsearch:elasticsearch /usr/local/elasticsearch-7.17.3/
#切换用户elasticsearch
su elasticsearch
9、给节点文件授权:
chown -R elasticsearch:elasticsearch /usr/local/node-1
chown -R elasticsearch:elasticsearch /usr/local/node-2
chown -R elasticsearch:elasticsearch /usr/local/node-3
四、搭建遇到的错误(先解决)
问题1: 如果你之前安装过ES,并且搭建集群的ES文件是从之前的复制过来的,那么请务必将data目录清空。
问题2:
如果你目前使用的是root账户,那么启动会报下面的错误。

这是因为es不允许使用root启动,所以需要创建一个非root用户,以非root用户来启动es。创建elasticsearch 用户,或者使用其他非root用户,注意文件权限。如果你是非root用户则可以跳过这一步。
#创建elasticsearch用户组
groupadd elasticsearch
#创建新用户elasticsearch ,设置用户组为elasticsearch ,密码123456
useradd elasticsearch -g elasticsearch -p 123456
#授权,更改/elasticsearch-7.17.3文件夹所属用户及用户组为elasticsearch:elasticsearch
chown -R elasticsearch:elasticsearch /usr/local/elasticsearch-7.17.3/
#切换用户elasticsearch
su elasticsearch
问题3:

说明操作当前文件权限不够,给文件授权就好了。
chown -R elasticsearch:elasticsearch /usr/local/node-1
chown -R elasticsearch:elasticsearch /usr/local/node-2
chown -R elasticsearch:elasticsearch /usr/local/node-3
问题4:
ERROR: [1] bootstrap checks failed. You must address the points described in the following [1] lines before starting Elasticsearch.
bootstrap check failure [1] of [1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
ERROR: Elasticsearch did not exit normally - check the logs at /usr/local/node-1/logs/my-application.log
解决方案
sudo vi /etc/security/limits.conf
#添加以下内容,注意:elasticsearch是当前用户名,不一定和我一样,
elasticsearch hard nofile 65536
elasticsearch soft nofile 65536
说明:elasticsearch表示运行的用户,如果你的当用户是es,那么前缀就是es,不一定和我一样,hard与soft表示限制的类型,nofile表示max number of open file descriptors,65536表示设置的大小。改完需要重新登录才能生效,或者切换用户
su root
Password:
[root@localhost ~]# su sandwich
[root@localhost ~]# ulimit -Hn
65536
[root@localhost ~]# ulimit -Sn
65536
问题5:
解决内存权限太小错误,如果在启动时又报错了,并且是下面这个错误:
[2022-05-08T14:58:01,836][ERROR][o.e.b.Bootstrap ] [node-1] node validation exception
[1] bootstrap checks failed. You must address the points described in the following [1] lines before starting Elasticsearch.
bootstrap check failure [1] of [1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
[2022-05-08T14:58:01,840][INFO ][o.e.n.Node ] [node-1] stopping ...
[2022-05-08T14:58:01,870][INFO ][o.e.n.Node ] [node-1] stopped
[2022-05-08T14:58:01,870][INFO ][o.e.n.Node ] [node-1] closing ...
[2022-05-08T14:58:01,920][INFO ][o.e.n.Node ] [node-1] closed
这是因为elasticsearch用户拥有的内存权限太小,至少需要262144。解决方案,切换到root用户下,在/etc/sysctl.conf文件最后添加一行
vi /etc/sysctl.conf
添加的内容:
vm.max_map_count=262144
执行命令生效:
/sbin/sysctl -p
五、启动ES集群
# 需切换为elasticsearch用户
su elasticsearch
# 启动服务
cd /usr/local/
./node-1/bin/elasticsearch -d
./node-2/bin/elasticsearch -d
./node-3/bin/elasticsearch -d
# 关闭es进程:
ps -ef | grep elastic
kill -9 11597
如果开启了防火墙则还需要开放端口
参考地址:Linux(CentOS7)开放指定端口与开关防火墙 - 唐浩荣 - 博客园 (cnblogs.com)
9200、9201、9202:对外服务的http 端口
9300、9301、9302:节点间通信的tcp端口
启动成功后的截图:




六、配置kibana
打开配置kibana.yml,添加下面的配置:
#配置端口号
server.port: 5601
#配置网络访问地址
server.host: "0.0.0.0"
server.publicBaseUrl: "http://192.168.1.15:5601"
#配置es链接地址(es集群,可以用逗号分隔)
elasticsearch.hosts: ["http://192.168.1.15:9200", "http://192.168.1.15:9201", "http://192.168.1.15:9202"]
#配置中文语言界面
i18n.locale: "zh-CN"
PROPERTIES 复制 全屏
然后重启即可
然后可以通过以下命令进行验证集群的搭建状况:
GET _cat/nodes


 浙公网安备 33010602011771号
浙公网安备 33010602011771号