【算法】堆排序
1991年的计算机先驱奖获得者、斯坦福大学计算机科学系教授罗伯特·弗洛伊德(Robert W.Floyd) 和威廉姆斯(J.Williams)在1964年共同发明了著名的堆排序算法(Heap Sort).
堆的定义如下:\(n\)个元素的序列\({k_1,k_2,···,k_n}\)当且仅当满足下关系时,称之为堆。
把此序列对应的二维数组看成一个完全二叉树。那么堆的含义就是:完全二叉树中任何一个非叶子节点的值均不大于(或不小于)其左,右孩子节点的值。由上述性质可知大顶堆的堆顶的关键字肯定是所有关键字中最大的,小顶堆的堆顶的关键字是所有关键字中最小的。因此我们可使用大顶堆进行升序排序,使用小顶堆进行降序排序。
一、基本思想
此处以大顶堆为例,堆排序的过程就是将待排序的序列构造成一个堆,选出堆中最大的移走,再把剩余的元素调整成堆,找出最大的再移走,重复直至有序。
二、算法描述
①. 先将初始序列\(K[1..n]\)建成一个大顶堆,那么此时第一个元素\(K_1\)最大,此堆为初始的无序区。
②. 再将关键字最大的记录\(K_1\)(即堆顶,第一个元素)和无序区的最后一个记录\(K_n\)交换,由此得到新的无序区\(K[1..n−1]\)和有序区\(K[n]\),且满足\(K[1..n−1].keys⩽K[n].key\)
③. 交换\(K_1\)和\(K_n\)后,堆顶可能违反堆性质,因此需将\(K[1..n−1]\)调整为堆。然后重复步骤②,直到无序区只有一个元素时停止。
动图效果如下所示:
 堆排序过程
堆排序过程
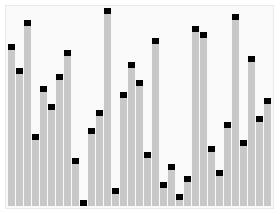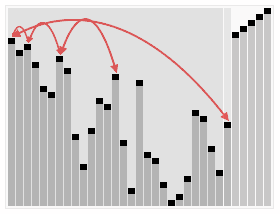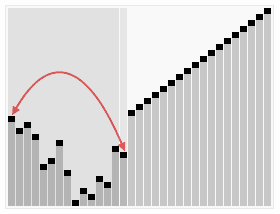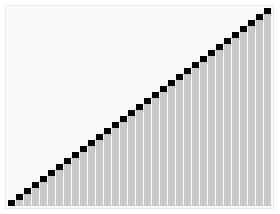 堆排序算法的演示。首先,将元素进行重排,以匹配堆的条件。图中排序过程之前简单的绘出了堆树的结构。
堆排序算法的演示。首先,将元素进行重排,以匹配堆的条件。图中排序过程之前简单的绘出了堆树的结构。
三、代码实现
从算法描述来看,堆排序需要两个过程,一是建立堆,二是堆顶与堆的最后一个元素交换位置。所以堆排序有两个函数组成。一是建堆函数,二是反复调用建堆函数以选择出剩余未排元素中最大的数来实现排序的函数。
总结起来就是定义了以下几种操作:
- 最大堆调整(Max_Heapify):将堆的末端子节点作调整,使得子节点永远小于父节点
- 创建最大堆(Build_Max_Heap):将堆所有数据重新排序
- 堆排序(HeapSort):移除位在第一个数据的根节点,并做最大堆调整的递归运算
对于堆节点的访问:
- 父节点i的左子节点在位置:
(2*i+1); - 父节点i的右子节点在位置:
(2*i+2); - 子节点i的父节点在位置:
floor((i-1)/2);
/**
* 堆排序
*
* 1. 先将初始序列K[1..n]建成一个大顶堆,那么此时第一个元素K1最大,此堆为初始的无序区.
* 2. 再将关键字最大的记录K1(即堆顶,第一个元素)和无序区的最后一个记录Kn交换,由此得到新的无序区K[1..n−1]和有序区K[n],且满足K[1..n−1].keys⩽K[n].key
* 3. 交换K1和Kn后,堆顶可能违反堆性质,因此需将K[1..n−1]调整为堆.然后重复步骤②,直到无序区只有一个元素时停止.
* @param arr 待排序数组
*/
public static void heapSort(int[] arr){
for(int i = arr.length; i > 0; i--){
max_heapify(arr, i);
int temp = arr[0]; //堆顶元素(第一个元素)与Kn交换
arr[0] = arr[i-1];
arr[i-1] = temp;
}
}
private static void max_heapify(int[] arr, int limit){
if(arr.length <= 0 || arr.length < limit) return;
int parentIdx = limit / 2;
for(; parentIdx >= 0; parentIdx--){
if(parentIdx * 2 >= limit){
continue;
}
int left = parentIdx * 2; //左子节点位置
int right = (left + 1) >= limit ? left : (left + 1); //右子节点位置,如果没有右节点,默认为左节点位置
int maxChildId = arr[left] >= arr[right] ? left : right;
if(arr[maxChildId] > arr[parentIdx]){ //交换父节点与左右子节点中的最大值
int temp = arr[parentIdx];
arr[parentIdx] = arr[maxChildId];
arr[maxChildId] = temp;
}
}
System.out.println("Max_Heapify: " + Arrays.toString(arr));
}
注: x>>1 是位运算中的右移运算,表示右移一位,等同于x除以2再取整,即x>>1 == Math.floor(x/2)。
以上,
①. 建立堆的过程,从length/2 一直处理到0,时间复杂度为O(n);
②. 调整堆的过程是沿着堆的父子节点进行调整,执行次数为堆的深度,时间复杂度为O(lgn);
③. 堆排序的过程由n次第②步完成,时间复杂度为O(nlgn)。
| 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
|---|---|---|---|
| O(n log₂n) | O(nlog₂n) | $O(nlog₂n) | O(1) |
Tips: 由于堆排序中初始化堆的过程比较次数较多,因此它不太适用于小序列。同时由于多次任意下标相互交换位置,相同元素之间原本相对的顺序被破坏了,因此,它是不稳定的排序。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号