

Hadoop框架:NameNode工作机制详解
一、存储机制
1、基础描述
NameNode运行时元数据需要存放在内存中,同时在磁盘中备份元数据的fsImage,当元数据有更新或者添加元数据时,修改内存中的元数据会把操作记录追加到edits日志文件中,这里不包括查询操作。如果NameNode节点发生故障,可以通过FsImage和Edits的合并,重新把元数据加载到内存中,此时SecondaryNameNode专门用于fsImage和edits的合并。
2、工作流程
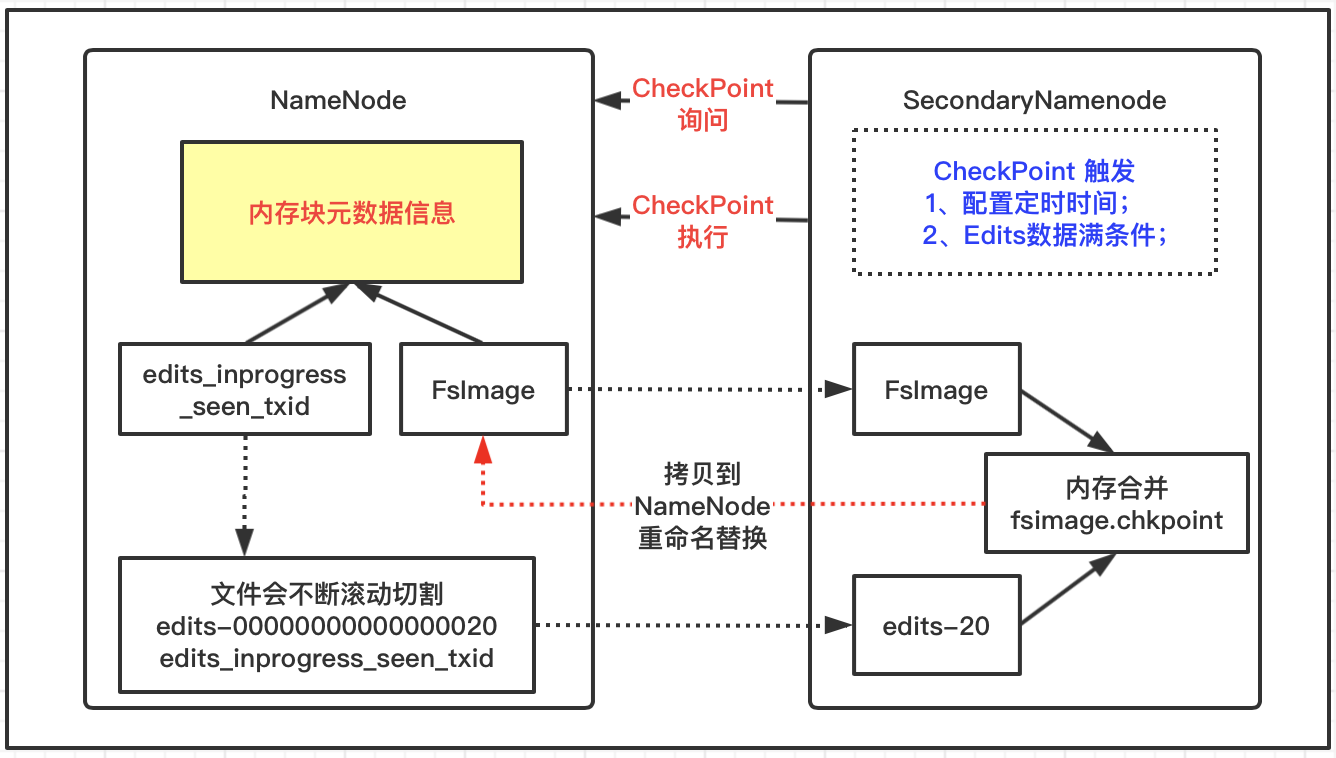
NameNode机制
- NameNode格式化启动之后,首次会创建Fsimage和Edits文件;
- 非首次启动直接加载FsImage镜像文件和Edits日志到内存中;
- 客户端对元数据执行增删改操作会记录到Edits文件;
- 然后请求的相关操作会修改内存中的元数据;
SecondaryNameNode机制
- 询问NameNode是否需要CheckPoint,NameNode返回信息;
- 如果需要SecondaryNameNode请求执行CheckPoint;
- NameNode切割现有日志文件,新记录滚动写入新Edits文件;
- 滚动前的编辑日志和镜像文件拷贝到SecondaryNameNode;
- SecondaryNameNode加载Edits日志和FsImage镜像文件到内存合并;
- 生成新的镜像文件fsimage.chkpoint后拷贝到NameNode;
- NameNode将fsimage.chkpoint重新命名成fsimage;
3、CheckPoint设置
通过修改hdfs-default.xml文件的相关配置,设置一些SecondaryNameNode的机制,例如每隔一小时执行一次。
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>文件满1000000记录数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次文件记录数</description>
</property >
二、文件信息
1、FsImage文件
NameNode内存中元数据序列化备份信息;
生成路径:基于NameNode节点
cd /opt/hadoop2.7/data/tmp/dfs/name/current/
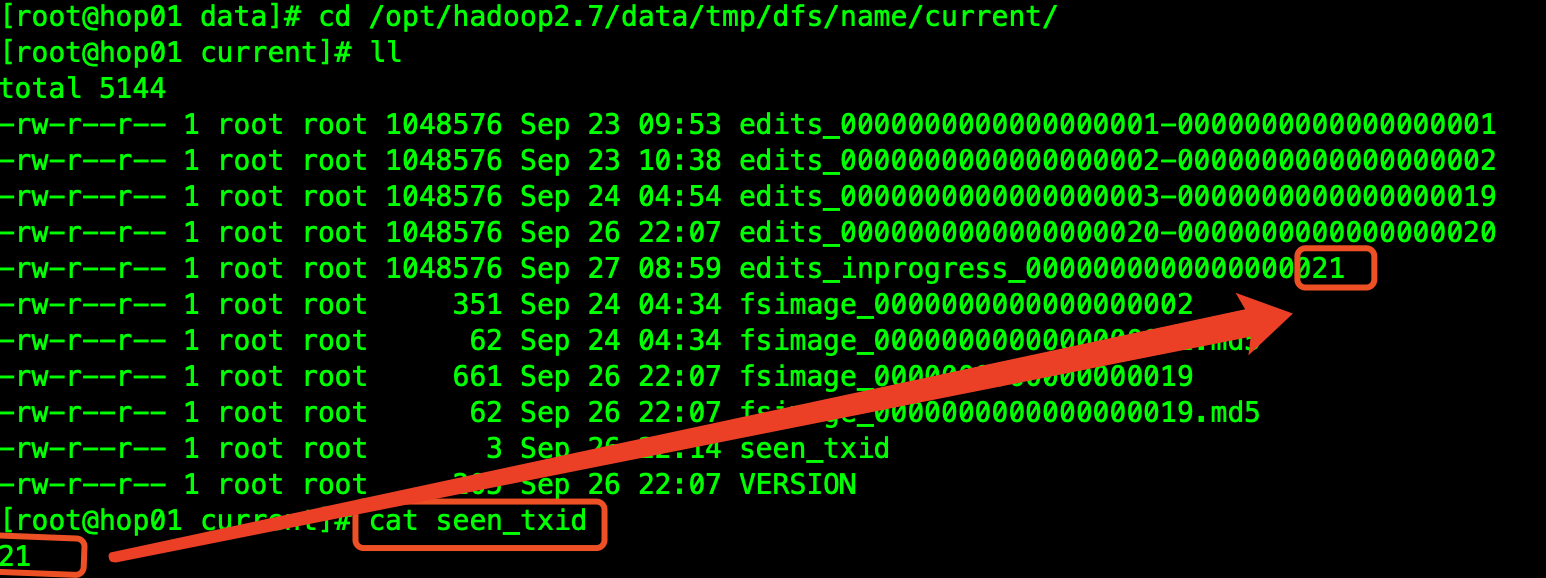
查看文件
# 基本语法
hdfs oiv -p 转换文件类型 -i 镜像文件 -o 转换后文件输出路径
基于语法格式,操作上图中的文件:
# 转换文件
hdfs oiv -p XML -i fsimage_0000000000000000019 -o /data/fsimage.xml
# 查看
cat /data/fsimage.xml
这样就可以看到一些元数据的信息。
2、Edits文件
存放HDFS文件的所有增删改操作的路径,会记录在Edits文件中。
基本语法
hdfs oev -p 转换文件类型 -i 日志文件 -o 转换后文件输出路径
查看文件
# 转换文件
hdfs oev -p XML -i edits_0000000000000000020-0000000000000000020 -o /data/edits.xml
# 查看
cat /data/edits.xml
三、故障恢复
1、拷贝SecondaryNameNode数据
首先结束NameNode进程;
删除NameNode存储的数据;
[root@hop01 /] rm -rf /opt/hadoop2.7/data/tmp/dfs/name/*
拷贝SecondaryNameNode中数据到NameNode数据存储目录下;
# 注意SecondaryNameNode服务配置在hop03上
[root@hop01 /] scp -r root@hop03:/opt/hadoop2.7/data/tmp/dfs/namesecondary/* /opt/hadoop2.7/data/tmp/dfs/name/
重新启动NameNode进程;
2、基于Checkpoint机制
修改hdfs-site.xml配置,同步到集群相关服务下,重启HDFS进程;
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>120</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop2.7/data/tmp/dfs/name</value>
</property>
结束NameNode进程;
删除NameNode存储的数据;
[root@hop01 /] rm -rf /opt/hadoop2.7/data/tmp/dfs/name/*
由于集群中SecondaryNameNode(在hop03)不和NameNode(在hop01)在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件;
[root@hop01 /]scp -r root@hop03:/opt/hadoop2.7/data/tmp/dfs/namesecondary /opt/hadoop2.7/data/tmp/dfs/
[root@hop01 namesecondary/] rm -rf in_use.lock
[root@hop01 dfs]$ ls
data name namesecondary
导入检查点数据
[root@hop01 hadoop2.7] bin/hdfs namenode -importCheckpoint
重新启动NameNode
[root@hop01 hadoop2.7] sbin/hadoop-daemon.sh start namenode
四、多个目录配置
NameNode可以配置多本地目录,每个目录存放内容相同,增加运行的可靠性;
1、添加配置
# vim /opt/hadoop2.7/etc/hadoop/hdfs-site.xml
# 添加内容如下
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/name01,file:///${hadoop.tmp.dir}/dfs/name02</value>
</property>
该配置需要同步集群下所有服务;
2、删除原有数据
集群下所有服务都需要执行该操作;
[root@hop01 hadoop2.7]# rm -rf data/ logs/
格式化NameNode之后重启集群服务。
五、安全模式
1、基本描述
NameNode刚启动时,会基于镜像文件和编辑日志在内存中加载文件系统元数据的映像,然后开始监听DataNode请求,该过程期间处于一个只读的安全模式下,客户端无法上传文件,在该安全模式下DataNode会发送最新的数据块列表信息到NameNode,如果满足最小副本条件,NameNode在指定时间后就会退出安全模式。
2、安全模式
- 安全模式状态
/opt/hadoop2.7/bin/hdfs dfsadmin -safemode get
- 进入安全模式
/opt/hadoop2.7/bin/hdfs dfsadmin -safemode enter
- 退出安全模式
/opt/hadoop2.7/bin/hdfs dfsadmin -safemode leave
- 等待安全模式
/opt/hadoop2.7/bin/hdfs dfsadmin -safemode wait



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix