

虚拟机系列 | 执行引擎和垃圾回收
一、执行引擎
应用程序经过编译,转换为字节码文件,字节码加载到内存空间并不能直接在操作系统上执行,执行引擎作为Java虚拟机核心的组成部分,作用就是将字节码指令解释/编译为对应系统平台上的本地机器指令。
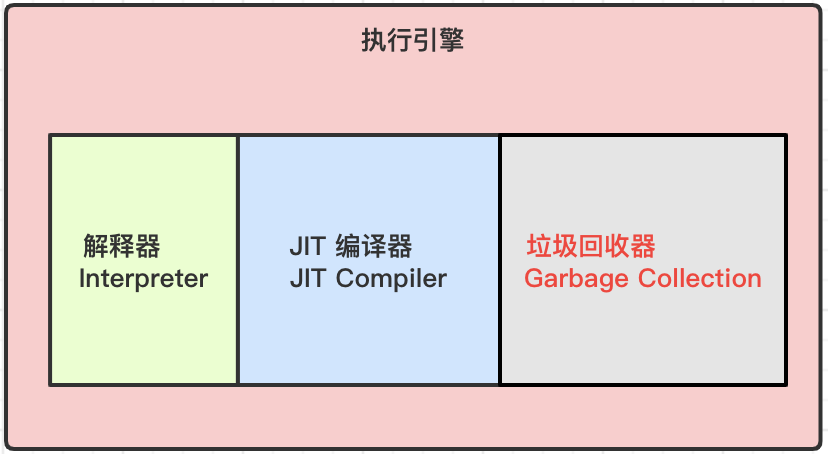
解释器:虚拟机启动时会根据预定义对字节码采用逐行解释的方式执行,将每条字节码文件中的内容解释为对应系统平台的本地机器指令执行;
JIT编译器:虚拟机将源代码编译成本地机器平台相关的机器语言,并且寻找热点高频执行的代码将其放入元空间中,即元空间中存放的JIT缓存代码;
垃圾回收:对于没有任何引用的对象标记为垃圾,会被回收释放内存空间。
二、垃圾对象标记
1、引用计数法
每个对象保存一个整型引用计数器,用来记录对象被引用的次数,当该对象被一个对象引用时,计数器加1,当失去一个引用时,计数器减1;引用计数算法就是通过判断对象的引用数量来决定对象是否可以被当做垃圾对象回收掉。
虽然引用计数法效率高,但是当两个对象互相引用时会导致这两个对象一直不会被回收,这是一个致命的缺陷。所以JVM并没有采用该标记算法。
2、可达性分析算法
可达性分析算法是基于对象到根对象的引用链是否可达来判断对象是否可以被回收;
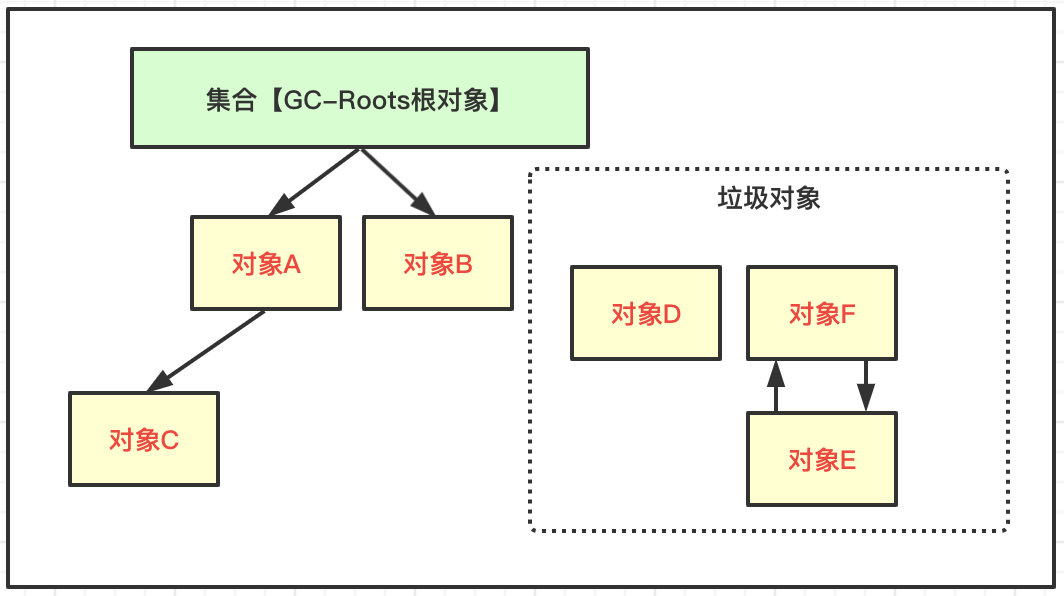
运行程序把所有的引用关系链看作一张图,通过GC-Roots根对象对象集合作为起始点,从每个根节点向下不断搜索被根对象集合所连接的对象是否可达,搜索路径称为引用链(Reference-Chain),如果对象到GC-Roots没有任何引用链存在,则说明此对象是不可用的,
- 虚拟机栈中引用的对象;
- 元空间中类静态属性引用的对象;
- 元空间中常量引用的对象;
- 本地方法栈中Native方法引用的对象;
相对于引用计数法算法,可达性分析算法则避免了循环引用导致的问题,同样具备执行高效的特点,也是JVM采用的标记算法。
三、垃圾回收机制
1、标记清除算法
标记-清除算法分为标记和清除两个阶段:
标记阶段:从根对象集合进行扫描,对存活的对象对象标记;清除阶段:再次扫描发现未被标记的对象并进行回收;
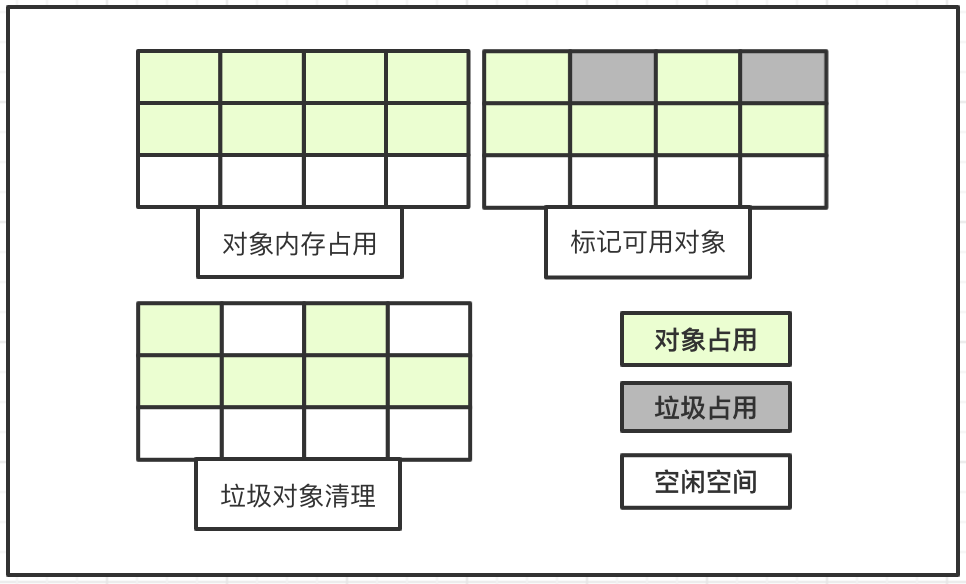
该算法效率不高,进行垃圾回收需要暂停应用程序,同时会产生大量内存碎片,后续程序运行过程中分配内存占用较大的对象时,会有连续内存不够情况,容易触发再一次垃圾收集动作。
2、标记整理算法
标记整理算法的标记过程类似标记清除算法,第一阶段:标记出垃圾对象;第二阶段:让所有存活的对象都向内存区一端移动;第三阶段:直接清理掉边界端以外的内存,类似于磁盘整理的过程;

该垃圾回收算法效率不高,对象移动过程需要暂停应用程序,适用于对象存活率高的场景(老年代)。
3、复制算法
复制算法将内存按容量划分为大小相等的两块,每次只使用其中的一块,当使用的这块的内存用完,就将还存活着的对象复制到另外一块空闲内存上,然后使用过的内存空间一次清理。
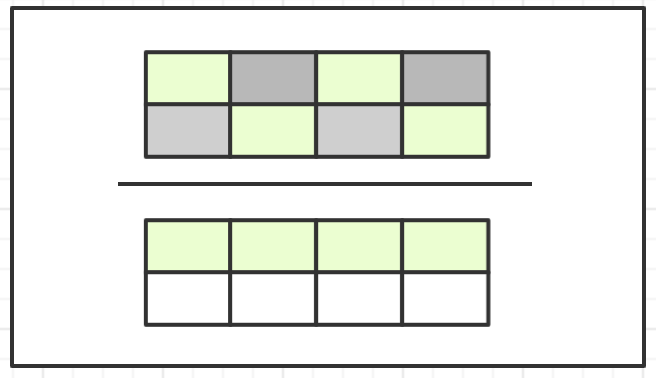
该算法实现简单,运行效率高,但是内存空间严重浪费,适用于对象存活率低的场景,比如新生代。
4、分代收集算法
当前市场上几乎所有的虚拟机都采用该回收算法,分代收集算法根据年轻代和老年代的各自特点采用不同的算法机制,不同内存区域中对象生命周期也不同,因此对堆内存不同区域采用不同的回收策略可以提高垃圾回收执行效率。通常情况新生代对象存活率低,回收频繁,就采用复制算法;老年代存对象生命周期长,活率高,就用标记清除算法或者标记整理算法。
Java堆内存一般可以分为新生代、老年代和永久代三个模块,如下图所示:
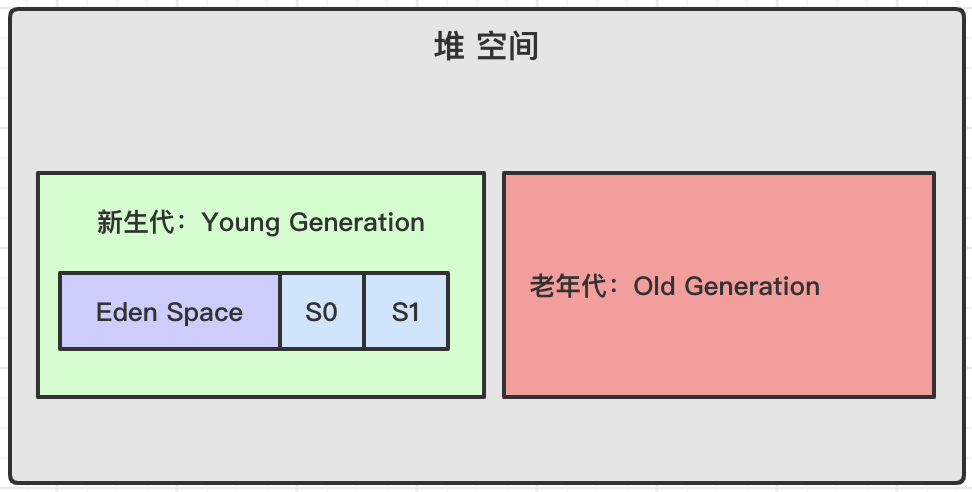
新生代
通常情况下,新创建的对象实例首先都是放在新生代空间中,所以追求快速的回收掉垃圾对象,一般情况下,新生代内存按照8:1:1的比例分为一个eden区和两个survivor(survivor0,survivor1)区,对象实例大部分在Eden区中生成;
垃圾回收时先把eden区存活对象复制到S0区,然后清空eden区,当S0区也满时,再将eden区和S0区存活对象复制到S1区,然后清空eden和S0区,之后交换S0区和S1区的角色,当S1区无法存放eden区和S0区的存活对象时,就将存活对象直接存移到老年代区,当老年代区也满了,触发一次FullGC,即新生代、老年代都进行回收。
老年代
老年代区存放一些生命周期较长的对象,对象实例在新生代中经历了多次垃圾回收仍然存活的对象,会被移动到老年代区中。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix