

大数据简介,技术体系分类整理
一、大数据简介
1、基础概念
大数据是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。大数据技术则主要用来解决海量数据的存储和分析。
2、特点分析
大数据的5V特点(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。
3、发展过程
Google在2004年前后发表的三篇论文,分别是文件系统GFS、计算框架MapReduce、NoSQL数据库系统BigTable。海量数据文件,分析计算,并存储,确立了大数据的基本原理和思路。
天才程序员DougCutting,也是Lucene、Nutch项目发起人。根据Google论文原理初步实现类似GFS和MapReduce的功能,后来发展成为大名鼎鼎的Hadoop。
再后来,Hadoop经过高速的发展,已经形成一个生态体系,基于Hadoop之上,有实时计算,离线计算,NoSQL存储,数据分析,机器学习等一系列内容。
从这一系列事情发展看技术规律:Google业务实践中创造性的提出论文作为基础,业务的成长和需求,迫使技术不断更新换代。所以业务是技术不断发展的关键。
二、Hadoop框架
1、Hadoop简介
注意这里基于Hadoop2.X版本描述。后续如果没有特别说明,都是2.7版本。
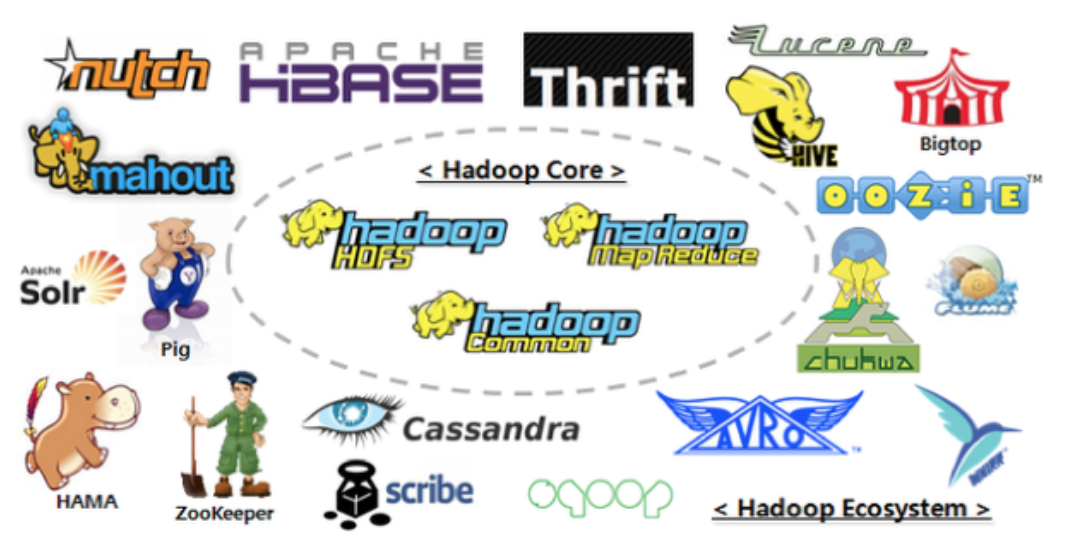
Hadoop是一个由Apache基金会所开发的分布式系统基础架构;
提供海量的数据存储能力,和分析计算能力;
作为Apache的顶级项目,包含众多子项目是一个生态圈;
2、框架特点
可靠性:Hadoop按位存储和存储多个数据副本,提供可靠服务;
扩展性:Hadoop利用计算机集群分配数据并完成计算任务,可以方便地扩展到数以千计的节点中;
高效性:基于MapReduce思想,为海量的数据提供高效的并行计算;
容错性:自动保存数据的多个副本,并且能够自动将失败的任务重新分配;
3、组成结构
HDFS存储
- NameNode
存储文件相关的元数据,例如:文件名,文件目录,创建时间,权限副本数等。
- DataNode
文件系统存储文件块数据,以及和数据块ID的映射关系。
Yarn调度
负责资源管理和作业调度,将系统资源分配给在Hadoop集群中运行的各种应用程序,并调度要在不同集群节点上执行的任务。
MapReduce计算
MapReduce将计算过程分为两个阶段:Map阶段并行处理输入数据,Reduce阶段对Map结果进行汇总。
三、大数据技术栈
1、Kafka中间件
开源组织: Apache软件
应用场景:
Kafka是一种高吞吐量的分布式发布订阅消息系统,通过磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。支持通过Kafka服务器和消费机集群来分区消息。支持Hadoop并行数据加载。
2、Flume日志系统
开源组织: Cloudera公司
应用场景:
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
3、Sqoop同步工具
开源组织: Apache软件
应用场景:
Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库例如:MySql间进行数据的传递,可以将一个关系型数据库(例如:MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
4、HBase数据库
开源组织: Apache软件
应用场景:
HBase是一个分布式的、面向列的开源数据库,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库,并且基于列的而不是基于行的存储模式。
5、Storm实时计算
开源组织: Apache软件
应用场景:
Storm用于实时计算,对数据流做连续查询,在计算时就将结果以流的形式输出给用户。Storm相对简单,可以与任何编程语言一起使用。
6、Spark计算引擎
开源组织: Apache软件
应用场景:
Spark是专为大规模数据处理而设计的快速通用的计算引擎,拥有Hadoop的MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。Spark是在Scala 语言中实现的,它将Scala用作其应用程序框架。
7、R语言
开源组织: 微软公司
应用场景:
R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
8、Hive数仓工具
开源组织: 脸书公司
应用场景:
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。
9、Oozie组件
开源组织: Apache软件
应用场景:
Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
10、Azkaban组件
开源组织: Linkedin公司
应用场景:
批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban定义了一种KV文件格式来建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪的工作流。
11、Mahout组件
开源组织: Apache软件
应用场景:
Mahout提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。
12、ZooKeeper组件
开源组织: Apache软件
应用场景:
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
四、技术栈分类
存储体系:Hadoop-HDFS、HBase、MongoDB、Cassandra
计算体系:Hadoop-MapReduce、Spark、Storm、Flink
数据同步:Sqoop、DataX
资源调度:YARN、Oozie、Zookeeper
日志收集:Flume、Logstash、Kibana
分析引擎:Hive、Impala、Presto、Phoenix、SparkSQL
集群监控:Ambari、Ganglia、Zabbix
五、源代码地址
GitHub·地址
https://github.com/cicadasmile/big-data-parent
GitEE·地址
https://gitee.com/cicadasmile/big-data-parent



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2019-09-15 Java描述设计模式(11):观察者模式