

数据源管理 | OLAP查询引擎,ClickHouse集群化管理
一、列式库简介
ClickHouse是俄罗斯的Yandex公司于2016年开源的列式存储数据库(DBMS),主要用于OLAP在线分析处理查询,能够使用SQL查询实时生成分析数据报告。
列式存储
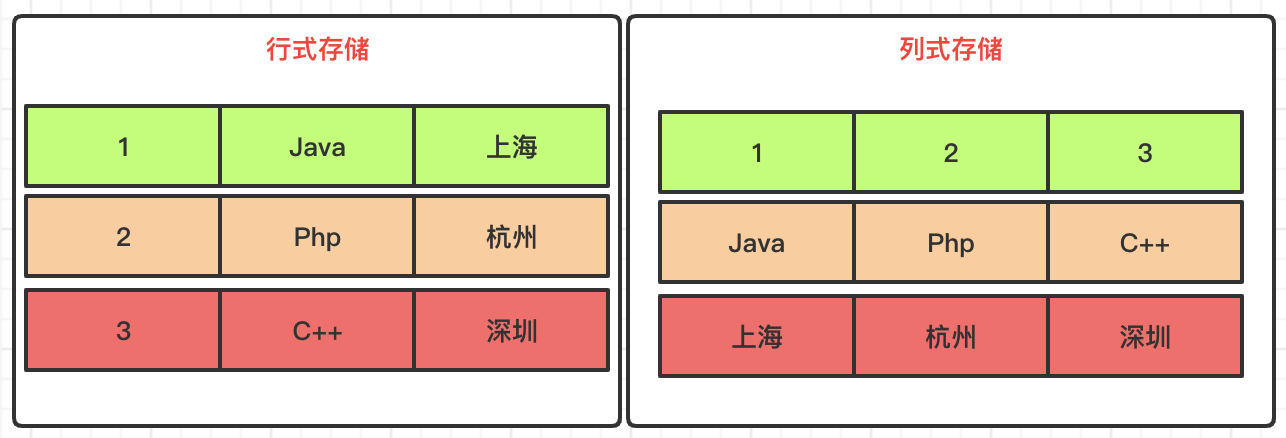
行式存储和列式存储,数据在磁盘上的组织结构有着根本不同,数据分析计算时,行式存储需要遍历整表,列式存储只需要遍历单个列,所以列式库更适合做大宽表,用来做数据分析计算。
絮叨一句:注意这里比较的场景,是数据分析计算的场景。
二、集群配置
1、基础环境
ClickHouse单服务默认已经安装完毕
2、取消文件限制
vim /etc/security/limits.conf
vim /etc/security/limits.d/90-nproc.conf
文件末尾追加
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
3、取消SELINUX
修改/etc/selinux/config中的SELINUX=disabled后重启
4、集群配置文件
服务分别添加集群配置:vim /etc/metrika.xml
<yandex>
<clickhouse_remote_servers>
<clickhouse_cluster>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>192.168.72.133</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<internal_replication>true</internal_replication>
<host>192.168.72.136</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>192.168.72.137</host>
<port>9000</port>
</replica>
</shard>
</clickhouse_cluster>
</clickhouse_remote_servers>
<zookeeper-servers>
<node index="1">
<host>192.168.72.133</host>
<port>2181</port>
</node>
<node index="2">
<host>192.168.72.136</host>
<port>2181</port>
</node>
<node index="3">
<host>192.168.72.137</host>
<port>2181</port>
</node>
</zookeeper-servers>
<macros>
<replica>192.168.72.133</replica>
</macros>
<networks>
<ip>::/0</ip>
</networks>
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
注意这里
<macros>
<replica>192.168.72.133</replica>
</macros>
配置各自服务的IP地址。
5、启动集群
分别启动三台服务
service clickhouse-server start
6、登录客户端查看
这里登录任意一台服务就好
clickhouse-client
en-master :) select * from system.clusters
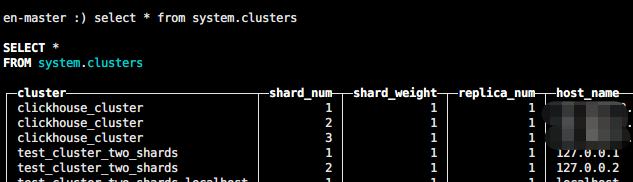
这里这里集群名称:clickhouse_cluster,后续使用。
7、基本环境测试
三台服务上同时创建表结构。
CREATE TABLE ontime_local (FlightDate Date,Year UInt16) ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192);
133环境创建分布表
CREATE TABLE ontime_all AS ontime_local ENGINE = Distributed(clickhouse_cluster, default, ontime_local, rand());
随便写入一台服务数据
insert into ontime_local (FlightDate,Year) values ('2020-03-12',2020);
查询总表
select * from ontime_all;
写入总表,数据会分布到各个单表中
insert into ontime_all (FlightDate,Year)values('2001-10-12',2001);
insert into ontime_all (FlightDate,Year)values('2002-10-12',2002);
insert into ontime_all (FlightDate,Year)values('2003-10-12',2003);
任意关闭一台服务,集群查询直接挂掉
三、集群环境整合
1、基础配置
url:配置全部的服务列表,主要用来管理表结构,批量处理;
cluster:集群连接服务,可以基于Nginx代理服务配置;
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
click:
driverClassName: ru.yandex.clickhouse.ClickHouseDriver
url: jdbc:clickhouse://127.0.0.1:8123/default,jdbc:clickhouse://127.0.0.1:8123/default,jdbc:clickhouse://127.0.0.1:8123/default
cluster: jdbc:clickhouse://127.0.0.1:8123/default
initialSize: 10
maxActive: 100
minIdle: 10
maxWait: 6000
2、管理接口
分别向每个单节点服务创建表和写入数据:
data_shard(单节点数据)
data_all(分布数据)
@RestController
public class DataShardWeb {
@Resource
private JdbcFactory jdbcFactory ;
/**
* 基础表结构创建
*/
@GetMapping("/createTable")
public String createTable (){
List<JdbcTemplate> jdbcTemplateList = jdbcFactory.getJdbcList();
for (JdbcTemplate jdbcTemplate:jdbcTemplateList){
jdbcTemplate.execute("CREATE TABLE data_shard (FlightDate Date,Year UInt16) ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192)");
jdbcTemplate.execute("CREATE TABLE data_all AS data_shard ENGINE = Distributed(clickhouse_cluster, default, data_shard, rand())");
}
return "success" ;
}
/**
* 节点表写入数据
*/
@GetMapping("/insertData")
public String insertData (){
List<JdbcTemplate> jdbcTemplateList = jdbcFactory.getJdbcList();
for (JdbcTemplate jdbcTemplate:jdbcTemplateList){
jdbcTemplate.execute("insert into data_shard (FlightDate,Year) values ('2020-04-12',2020)");
}
return "success" ;
}
}
3、集群查询
上述步骤执行完成后,可以连接集群服务查询分布总表和单表的数据。
基于Druid连接
@Configuration
public class DruidConfig {
@Resource
private JdbcParamConfig jdbcParamConfig ;
@Bean
public DataSource dataSource() {
DruidDataSource datasource = new DruidDataSource();
datasource.setUrl(jdbcParamConfig.getCluster());
datasource.setDriverClassName(jdbcParamConfig.getDriverClassName());
datasource.setInitialSize(jdbcParamConfig.getInitialSize());
datasource.setMinIdle(jdbcParamConfig.getMinIdle());
datasource.setMaxActive(jdbcParamConfig.getMaxActive());
datasource.setMaxWait(jdbcParamConfig.getMaxWait());
return datasource;
}
}
基于mapper查询
<mapper namespace="com.ckhouse.cluster.mapper.DataAllMapper">
<resultMap id="BaseResultMap" type="com.ckhouse.cluster.entity.DataAllEntity">
<result column="FlightDate" jdbcType="VARCHAR" property="flightDate" />
<result column="Year" jdbcType="INTEGER" property="year" />
</resultMap>
<select id="getList" resultMap="BaseResultMap" >
select * from data_all where Year=2020
</select>
</mapper>
四、源代码地址
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent
分类:
业务.架构.方案



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix