JAVA ThreadPoolExecutor(转)
原文链接:http://blog.csdn.net/historyasamirror/article/details/5961368
基础
在我看来,java比C++的一个大好处就是提供了对多线程的支持(C++只有多线程的库,语言本身不包含线程的概念)。而其中我最爱用的就是ThreadPoolExecutor这个类,它实现了一个非常棒的thread pool。
thread pool一般被用来解决两个问题:当处理大量的同步task的时候,它能够避免thread不断创建销毁的开销;而另外一个也许更重要的含义是,它其实表示了一个boundary,通过使用thread pool可以限制这些任务所消耗的资源,比如最大线程数,比如最大的消息缓冲池。
需要指出的是,ThreadPoolExecutor不仅仅是简单的多个thread的集合,它还带有一个消息队列。
在Java中,如果只是需要一个简单的thread pool,ExecuteService可能更为合适,这是一个Interface。可以通过调用Executor的静态方法来获得一些简单的threadpool,如:
- ExecuteService pool = Executors.newFixedThreadPool(poolSize);
但如果要用定制的thread pool,则要使用ThreadPoolExecutor类,这是一个高度可定制的线程池类,下面是一些重要的参数和方法:
corePoolSize 和 maxPoolSize
这两个参数其实和threadpool的调度策略密切相关:
如果poolsize小于coresize,那么只要来了一个request,就新创建一个thread来执行;
如果poolsize已经大于或等于coresize,那么来了一个request后,就放进queue中,等来线程执行;
一旦且只有queue满了,才会又创建新的thread来执行;
当然,coresize和maxpoolsize可以在运行时通过set方法来动态的调节;
(queue如果是一个确定size的队列,那么很有可能发生reject request的事情(因为队列满了)。很多人会认为这样的系统不好。但其实,reject request很多时候是个好事,因为当负载大于系统的capacity的时候,如果不reject request,系统会出问题的。)
ThreadFactory
可以通过设置默认的ThreadFactory来改变threadpool如何创建thread
keep-alive time
如果实际的线程数大于coresize,那么这些超额的thread过了keep-alive的时间之后,就会被kill掉。这个时间是可以动态设定的;
queue
任何一个BlockingQueue都可以做为threadpool中的队列,又可以分为三种:
AsynchronousQueue,采用这种queue,任何的task会被直接交到thread手中,queue本身不缓存任何的task,所以如果所有的线程在忙的话,新进入的task是会被拒绝的;
LinkedBlockingQueue,queue的size是无限的,根据前面的调度策略可知,thread的size永远也不会大于coresize;
ArrayBlockingQueue,这其实是需要仔细调整参数的一种方式。因为通过设定maxsize和queuesize,其实就是设定这个threadpool所能使用的resource,然后试图达到一种性能的最优;(Queue sizes and maximum pool sizes may be traded off for each other: Using large queues and small pools minimizes CPU usage, OS resources, and context-switching overhead, but can lead to artificially low throughput. If tasks frequently block (for example if they are I/O bound), a system may be able to schedule time for more threads than you otherwise allow. Use of small queues generally requires larger pool sizes, which keeps CPUs busier but may encounter unacceptable scheduling overhead, which also decreases throughput. )
此外,还有诸如beforeExecute,afterExecute等方法可以被重写。以上的这些内容其实都可以在ThreadPoolExecutor的javadoc中找到。应该说,ThreadPoolExecutor是可以非常灵活的被设置的,只除了一点,你没办法改变它的调度策略。
一个实例
通过分析一个特殊的ThreadPoolExeuctor的源代码,能够更好的理解它的内部机制和灵活性。
Mina中有一个特殊的ThreadPoolExecutor--org.apache.mina.filter.executor.OrderedThreadPoolExecutor。
这个executor是用来处理从网络中来的请求。它的不同之处在于,对于同一个session来的请求,它能够按照请求到达的时间顺序的执行。举个例子,在一个session中,如果先接收到request A,然后再接收到request B,那么,OrderedThreadPoolExecutor能够保证一定处理完A之后再处理B。而一般的thread pool,会将A和B传递给不同的thread处理,很有可能request B会先于request A完成。
先看看它的构造函数:
public OrderedThreadPoolExecutor( int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, ThreadFactory threadFactory, IoEventQueueHandler eventQueueHandler) { // We have to initialize the pool with default values (0 and 1) in order to // handle the exception in a better way. We can't add a try {} catch() {} // around the super() call. super(DEFAULT_INITIAL_THREAD_POOL_SIZE, 1, keepAliveTime, unit, new SynchronousQueue<Runnable>(), threadFactory, new AbortPolicy()); if (corePoolSize < DEFAULT_INITIAL_THREAD_POOL_SIZE) { throw new IllegalArgumentException("corePoolSize: " + corePoolSize); } if ((maximumPoolSize == 0) || (maximumPoolSize < corePoolSize)) { throw new IllegalArgumentException("maximumPoolSize: " + maximumPoolSize); } // Now, we can setup the pool sizes super.setCorePoolSize( corePoolSize ); super.setMaximumPoolSize( maximumPoolSize ); // The queueHandler might be null. if (eventQueueHandler == null) { this.eventQueueHandler = IoEventQueueHandler.NOOP; } else { this.eventQueueHandler = eventQueueHandler; } }
这里比较意外的是,它竟然用的是SynchronousQueue?! 也就是说,来了一个task,不会被放入Queue中,而是直接送给某个thread。这和一般的threadpoolExecutor是非常不一样的,因为一旦thread全用满了,task就不能再被接受了。后面我们会看到为什么使用SynchronousQueue。
再看看它的execute函数:
public void execute(Runnable task) { if (shutdown) { rejectTask(task); } // Check that it's a IoEvent task checkTaskType(task); IoEvent event = (IoEvent) task; // Get the associated session IoSession session = event.getSession(); // Get the session's queue of events SessionTasksQueue sessionTasksQueue = getSessionTasksQueue(session); Queue<Runnable> tasksQueue = sessionTasksQueue.tasksQueue; boolean offerSession; boolean offerEvent = eventQueueHandler.accept(this, event); if (offerEvent) { // Ok, the message has been accepted synchronized (tasksQueue) { // Inject the event into the executor taskQueue tasksQueue.offer(event); if (sessionTasksQueue.processingCompleted) { sessionTasksQueue.processingCompleted = false; offerSession = true; } else { offerSession = false; } //....... } } else { offerSession = false; } if (offerSession) { waitingSessions.offer(session); } addWorkerIfNecessary(); //.............. }
这里有几点需要解释的:
首先是getSessionTaskQueue函数。从这个函数可以看出,对于每一个session,都创建了一个queue来存储它的task。也就是说,同一个session的task被放在了同一个queue中。这是非常关键的地方,后面会看到,正是这个queue保证了同一个session的task能够按照顺序来执行;
其次是waitingSessions.offer(session)这条语句。waitingSessions是OrderedThreadPoolExecutor的一个私有成员,它也是一个queue: BlockingQueue<IoSession> waitingSessions ...;
这个queue里面放的是该threadpool所接收到的每个task所对应的Session,并且,如果两个task对应的是同一个session,那么这个session只会被放进waitingSessions中一次。waitingSession.offer(session)这条语句就是要将session放进queue。而offerSession这个变量和前面的十几行代码就是在判断task所对应的session是否要放入到queue中;
最后一行代码addWorkerIfNecessary();字面上很容易理解,就是判断是否添加worker。可是,worker又是什么呢?
看看Worker这个类:
private class Worker implements Runnable { private volatile long completedTaskCount; private Thread thread; public void run() { thread = Thread.currentThread(); try { for (;;) { IoSession session = fetchSession(); //.......... try { if (session != null) { runTasks(getSessionTasksQueue(session)); } } finally { idleWorkers.incrementAndGet(); } } } finally { //....... } } private IoSession fetchSession() { //........ for (;;) { try { try { session = waitingSessions.poll(waitTime, TimeUnit.MILLISECONDS); break; } finally { //.............. } } catch (InterruptedException e) { //........ } } return session; } private void runTasks(SessionTasksQueue sessionTasksQueue) { for (;;) { //...... runTask(task); } } private void runTask(Runnable task) { beforeExecute(thread, task); boolean ran = false; try { task.run(); ran = true; afterExecute(task, null); completedTaskCount ++; } catch (RuntimeException e) { if (!ran) { afterExecute(task, e); } throw e; } } }
在Worker.run()中,一开始就调用fetchSession(),这个函数从WaitingSessions这个queue中拿出一个Session。然后又调用了runTasks,这个函数会将Session中的那个TaskQueue中的每个Task挨个执行一遍。
OK,现在OrderedThreadPoolExecutor的整体设计就清晰了:
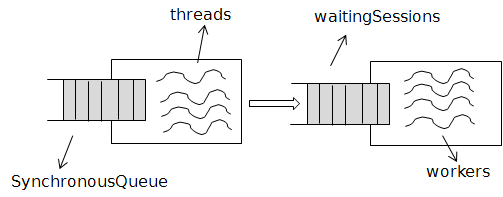
从外面看上去,OrderedThreadPoolExecutor只是一个thread pool,但本质上,它是有由两个thread pool拼接而成, 只不过后一个thread pool被隐藏在了类的内部实现中。第一个thread pool中的thread只需要完成很简单的一个任务,即将接收到的task对应的session添加到waitingSessions中(如果需要的话)。正因为如此,所以第一个threadpool的queue被设置成了SynchronousQueue。而后一个thread pool中的那些worker(也是一些thread)才真正的执行task。并且,后一个thread pool所能创建的thread的数量也受到了coreSize和MaxSize的限制。所以,整个OrderedThreadPoolExecutor实际上创建了2 * coreSize的thread。
前面的解释可能有些乱,再重新梳理整个OrderedThreadPoolExecutor的执行流程:
1. 当一个task被接收,前一个thread pool中的某个thread被指定负责处理这个task;
2. thread会找到task所对应的session,将这个task放入该session的TaskQueue中;
3. 如果该session已经被放入了waitingSessions,那么什么都不做,否则,将该session放入waitingSessions中;
4. 后一个threadpool中的某一个worker从waitingSessions中将该Session取出;
5. 找到该Session中的TaskQueue,依次执行queue中的task;
总结
总的来说,Java的TheadPoolExecutor整体架构设计的很具有扩展性,可以通过继承改写来实现不同的各具功能的threadpool,唯一的缺点就是它的调度策略是不能够改变的,但很多时候一个threadpool的调度策略会对系统性能产生很大的影响。所以,如果ThreadPoolExecutor的调度策略不适合你的话,就只能手工再造个“轮子”了。
另外,如果读过SOSP01年的“SEDA: An Architecture for Well-Conditioned, Scalable Internet Services”,那么会发现Java中的ThreadPoolExecutor非常类似于SEDA中的Stage概念。虽然我没有找到总够的证据,但是从时间的顺序看,java1.5版才加入的ThreadPoolExecutor很可能受到了01年这篇论文的启发。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号