谷歌、微软等大企业AI面经(转)
更新谷歌、微软等大企业AI面经,附开发者面试前的准备工作(转)
编者按:此前,论智发表了一篇面试了10家公司,这是我能记住的所有问题的文章,在各平台受到了广泛关注。在评论区,许多读者都表达了自己的惊讶之情,认为这些国外(印度)的面试题太基础了,其中的一部分甚至可以用过于简单来形容,但也有不少人认可面试官的专业程度,指出他们的问题虽然浅显,但的确能反映应聘者的知识水平和实践经验。本文是前文的续作,主要分两个部分,其中第一部分是Uber、Google、Facebook等大型公司的面试题,第二部分则是开发者在面试前的十个准备步骤,希望能给大家带来帮助。
注:坑挖得太深,目前还没处理完微软、苹果两家公司的面试经历,小编会在本周内填完。
本文作者Vimarsh Karbhari是独角兽公司Okta的Engineering Manager,今年2月,为了写点文章发表在Medium上,他特意花一个月准备面试,并在3月面遍了硅谷的大公司。


Uber AI面试题
面试过程
Uber的AI面试流程是标准的技术面,它分为电话面试和现场面试(oniste)两场,其中电话面试每轮持续约1小时(1—2轮),可能是面试官视频问答,也可能是视频通话+在线编码练习。第二场现场面试由五六轮面谈构成,应聘者可能要连续面对五六个不同职位的面试官,因此准备好一份灵活的自我介绍十分必要。
面前必看
机器学习平台Michelangelo
1.Uber论文Scaling Machine Learning as a Service:Uber开发了一个供内部团队的使用的机器学习平台——Michelangelo,这篇论文解释了这个平台的系统架构、搭建原理和功能设计,应聘者在面试前应该对它有一定的了解。
2.**Uber的技术博客:AI Labs、ATG Research、Machine Learning。**Uber有很多技术博客,而这些是其中和AI联系最紧密的三个,它们详细展示了公司研究的体系结构、技术发展和工作流程。
3.**Uber Horovod:**Uber开源的TensorFlow分布式深度学习框架。
人工智能/数据科学相关的面试题
- 描述什么是二元分类。
- 计算ROC曲线的AUC。
- 你怎么做A/B测试?
- 在随机伯努利生成器中写一个函数,使它生成一组服从正态分布的样本。
- 什么是P值?
- 解释线性回归的定义、前提假设和数学公式。
- 什么是CLT?它和Uber有什么关系?
- 解释Logistic回归的定义、前提假设和数学公式。
- 用一批街景车拍下美国各大城市街景照片需要花多少钱?
- 如何建模以反映租车成本和司机数量之间的关系?
- 解释Uber动态定价算法的原理,如何测试哪种定价策略更好?
- 什么是交叉验证?
- 网络效应是如何影响实验选择和测试结果的?
- 异常检测方法有哪些?
- 驾驶状况和拥堵对Uber收入有什么影响?
- 驾驶状况和拥堵如何影响Uber的收入以及司机体验?
- 缓存是什么?在数据科学中,你怎么使用缓存?
- 如何优化各种营销渠道之间的营销支出?
- 如何计算一个城市的Uber Pool半径?
- 如何决定一个地点是否应该包含在Uber Pool中?
- 什么是时间序列预测技术?
- 解释PCA的定义、前提假设和数学公式。
- Uber会导致交通堵塞吗?
对问题的反思
1.基于真实产品的问题:这些问题包含Uber运营过程中的一些真实问题场景,应聘者需要对他们的产品和市场有一定了解。
2.技术层面的AI问题偏向基础:面试题中有不少基础问题,但这些问题都是解决某些相关数据问题所需的必要技术。
3.模型训练和评估:这些问题都旨在从不同视角建立不同模型来探索人工智能研究。
Google AI面试题
面试过程
和Uber一样,Google的AI面试流程也是标准的技术面,它分为电话面试和现场面试(oniste)两场,其中电话面试由招聘部门的员工负责,应聘者需要先在视频中回答一个开放式问题,然后写代码、优化代码,整体耗时约30—60分钟。现场面试则会安排四位Google员工,由他们分别考验应聘者的认知水平、领导力水平、专业能力水平和Googleyness。
面前必看


TensorFlow
1.Google论文TensorFlow: A system for large-scale machine learning:谷歌基于DistBelief进行研发的第二代人工智能学习系统。
2.Google Tools:一些重要的AI研究工具,如Cloud TPU、TensorFlow、Cloud Machine Learning和Kaggle。
3.The Unofficial Google Data Science Blog:一个由谷歌员工运营的、非官方的技术博客,学术性较弱,更偏向工程领域。
人工智能/数据科学相关的面试题
- 1/x的导数是什么?
- 画出y=log(x+10)的曲线图?
- 如何设计一份客户满意度调查?
- 抛硬币10次,其中8次正面朝上,2次反面朝上,你会怎么说服自己这是一枚均匀的硬币?什么是P值?
- 你有10枚硬币,如果对每个硬币抛10次(共100次),最终你可以获得一个可用于判断硬币均匀与否的观察结果。如果要换一种方法,你会怎么做?
- 什么是非正态概率分布?你会怎么对它做统计分析?
- 为什么要做特征选择?如果两个预测因子高度相关,它们会对Logistic回归的系数产生什么影响?系数的置信区间是多少?
- K-mean和高斯混合模型:K-means和EM算法的区别是什么?
- 当使用高斯混合模型时,你怎么判断它是合适的?(正态分布)
- 如果在聚类问题中,标签是已知的,你会怎么评估模型的性能?
- 假设你有一个Google的APP,并做了一些修改,你会如何测试指标是否增加?
- 描述数据分析的过程。
- 什么时候不用Logistic回归?什么时候选择GBM?
- 推导GMM方程。
- 你会如何衡量喜欢视频的用户的数量?
- 模拟一个二元正态分布。
- 导出分布的方差。
- 每年有多少人申请Google岗位?
- 你怎么估计中位数?
- 在回归模型中,如果两个参数的估计值都具有统计显著性,你是否认为把它们放一起同时测试还是很重要?
对问题的反思
Google面试的一个突出特色就是问题很多、提问密集。从实践角度看,他们的面试中混合了不少ML基础知识和理论观点,因此运气比较好、学术又搞得好的人进入这家世家上最负盛名AI公司的可能性会更高一些。
Facebook AI面试题
面试过程
非常常规的技术面,两轮电面,之后是oniste,整体流程和上述两家公司差不多。
面前必看


1.Facebook的视觉应用AI框架:开放神经网络交换格式(ONNX)。
2.下载他们项目/软件包的库:research.fb.com/downloads/。
人工智能/数据科学相关的面试题
- 这是一幢100层的高楼,现在你有两个母鸡下的普通鸡蛋,你会怎么用这两个蛋找出它们可以安全落下的最高位置?
- 从100枚硬币里随机挑选一枚硬币,已知其中有1个假硬币(两面都是人头),99个真硬币(一面人头)。抽10次,如果10枚硬币都是人头朝上,那其中包含假硬币的概率是多少?
- 在Python中为数值数据集编写排序算法。
- Facebook想要开发一种无需用户提供生日信息就能估算他们的出生月份和日期的算法,如果你是开发者,你会用什么方法和数据来帮助完成这项任务?
- 用python内置包来处理’csv’数据。
- 你会如何比较两种不同后端引擎自动生成的Facebook“朋友”建议的相对表现?
- 给定KPI,选择正确的指标,执行ETL。(使用SQL /代码)
- 假设你马上要动身去西雅图,但不知道该不该带一把伞。为了得知当地天气情况,你可以分别给3位好友打电话提问。已知这三个朋友中的任何一个都有2/3的概率说真话,1/3的概率说假话。最后他们的答案都是“正在下雨”,你觉得西雅图下雨的概率有多大?
- A和B正在玩游戏,A有8颗宝石,B有6颗宝石。游戏规则是:首先A投掷骰子(均匀、公平),骰子正面朝上的数字是几,A就从B那儿拿多少宝石;其次B投掷骰子,并根据数字从A处拿取宝石。这样的来回构成一轮比赛。对于每一轮比赛,谁手里的宝石多,谁就获胜;如果这一轮结束后A和B的宝石数量相同,则判定为平局。请问,B在第1,2,3…,n轮获胜的概率分别是多少?
- 你会如何计数一个句子中每个字母出现的次数?
- 给你一些性别和身高数据,你会怎么证明男性的平均身高高于女性?
- 什么叫猴补丁/鸭子双关(monkey patch)?
- 给定一个对象列表A,以及一个和A一模一样但移除了一个对象的列表B,你会怎么找到那个被删除的对象?
- 给定一个整数列表(正数和负数),你会怎么编写算法来从中找出和为0的至少一对整数?在这个算法基础上,你会怎么提高它的性能?
- 制作一个包含两个变量的直方图。
- 在SQL中构建回帖计数的直方图(有x个回帖的帖子数、有x+1个回帖的帖子数等)。
- 如何构建一个Facebook功能使用情况表格(跟踪每个用户每天的操作并每日汇总)?
- 赌桌上有两个骰子,如果你扔出了一个5,你就能马上获得10美元奖金。你参加赌局的预期支出是多少?如果你铁了心了要扔出一个5(无论多久),你的预期支出又是多久?
- 如果你想劝说小型企业在Facebook上登广告,你会向他们展示什么指标?
- 给定一个发送好友请求列表和收到好友请求列表,你怎么从中找出拥有好友最多的用户?
- 用户们在Facebook上花的时间变多了,点赞的数量也变多了,但平台的用户总数却正在减少。你认为其中的根本原因是什么?
- 许多用户会在Facebook的个人介绍中列出自己曾就读的高中,你认为其中有多少是真实的?如果我们想大规模筛查、确认其中的虚假学校,你有什么好方法?
- 给你一些网络昵称:Pete、Andy、Nick、Rob等,你会怎么把它们和用户的真实姓名联系起来?
- 去年Facebook上的点赞数较前年同期增长了10%,你认为其中的原因是什么?
- 如果一名高管希望把Newsfeed里的新闻源广告数量翻番,你会怎么确定这不是个好提议?
对问题的反思
在Facebook的面试中,我发现面试官们非常喜欢基于概率情景提出各种问题。其中大多数问题需要应聘者对Facebook产品有较深的理解,同时公司对个人编码能力的要求也很高。想想也是,Facebook拥有世界上最顶尖的计算机视觉研究人员和人工智能团队,其中也不乏Google学者,如果一个人既有优秀的编码能力,又具备扎实的数据科学功底,相信他被这个全球最大社交媒体平台录用的概率会很高。
亚马逊AI面试题
面试过程
亚马逊的面试流程和之前提到的公司大体类似,但不同的是,当onsite进行了几轮后,应聘者会面对一次bar raiser面试。bar raiser是面试小组中最有经验的人,他要决断的是你是否真正满足这个岗位的需求,以及你是否比亚马逊50%的员工更有能力和潜力。无论其他面试官有多喜欢你,bar raiser拥有一票否决权。
面前必看
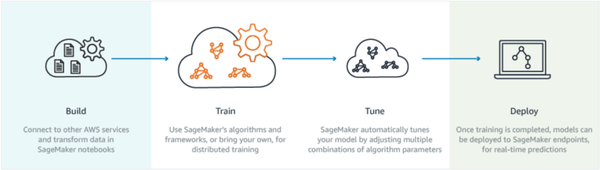
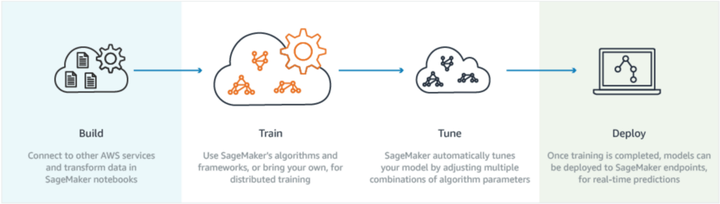
Sagemaker Courtesy
1.AWS Sagemaker:构建、训练和部署ML模型。
2.Deep Learning AMI:在AWS上使用AMI的教程。
3.亚马逊AWS博客:AWS Machine Learning Blog,上面有许多数据学习相关问题的解决方案。
人工智能/数据科学相关的面试题
- Logistic回归模型怎么校正系数?
- 把凸函数、非凸函数作为代价函数的区别是什么?如果代价函数是一个非凸函数,它意味着什么?
- 随机权重分配是否比为隐藏层中的每个神经元分配同一权重更优?
- Given a bar plot and imagine you are pouring water from the top, how to qualify how much water can be kept in the bar chart?
- 什么是过拟合?
- 亚马逊商城的会员费对交易有什么影响?
- 为什么梯度检查很重要?
- 解释什么是树、SVM、随机森林和boosting,并谈谈他们的优缺点。
- 如何用天平只称3次就找出9颗弹珠中最终的那颗?
- 如何找出西雅图客户过去6个月中利润最高的10种产品,并计算它们的的总利润?
- 介绍一个选择特定模型的标准。为什么数据降维很重要?
- Logistic回归和线性回归的假设是什么?
- 如果你训练出了一个准确度100%的预测顾客行为的模型,那它在实际部署中会有什么问题?
- 已知在条目A处找到目标条目的概率是0.6,在条目B处的概率则是0.8,那么在整个亚马逊网站上找到该条目的概率是多少?
- 给定一个包含5000万条记录的带有ID和数量列的“csv”文件,大小约2GB,请用任何语言编写一个程序来聚合QUANTITY列。
- 用Circular List实现Queue。
- 如果你有每月的时间序列数据,它们包含大量的数据记录,你会怎么比较本月和上月的数据差异?
- Lasso回归和岭回归有什么区别?
- MLE和MAP推断有什么区别?
- 给定一个带有输入的函数——包含N个数的数组(随机排序),int K,返回一个K个数最大的数组。
- 当顾客们在浏览亚马逊网站时,他们会做很多操作,如果要预测他们的下一个操作是付款,你会怎么建立最佳模型?
- 详细介绍一下SVM。
- K-means的原理是什么?你更倾向于选择哪类K-means矩阵?如果不同的函数有不同的动态范围,你会怎么办?
- 详细介绍一下boosting。
对问题的反思
亚马逊的面试问题包含很多编码/计算元素,它们中有不少实际问题,但也有不少基础知识问题。这些问题确实需要人们通过数据模型和数据集才能找到解决方案。亚马逊正在招聘很多数据科学人员,它也在数据领域展示了卓越的表现。如果想在这家野心不止于电商的公司工作,大量的数据练习和辛勤学习会有巨大帮助。
AI面试前的准备工作
如果说2000年开启了软件工程时代,那2020年将属于人工智能和数据科学。之前我写了大量顶级公司的面经,受到了大家的欢迎。结合读者给我的反馈,我也觉得是时候该和大家分享一下自己的面试准备过程了。
综合以上几家公司的问题可知,掌握AI / ML和数据科学领域的基础知识是面试成功的一大关键。这是一个新兴领域,这也意味着它是一个与众不同的学科——它是计算机科学、数学、统计学及其他相关领域专业知识的交叉,是高度跨学科的。因此,如果你的理想是成为一名数据科学家、ML算法工程师,你就要保证自己能精通三个领域的知识。
以下是我的复习安排:
1.从基本Python开始(计划:2天)
从事AI/ML工作的人也许不用Python,但如果要进入这个领域,你必须学会使用Python。无论是工业界还是学术界,所有的数据操作、模型构建都要用到python。使用python的环境应该是Jupyter Notebook。Jupyter Notebook的新替代品是Google Colaboratory。为了更好地分配和管理项目,我建议使用Anaconda。
2.描述性统计和推论统计(计划:1天)
描述性统计就是描述样本的统计特征,并不深入了解其内部规律,比如求平均数、分布、中位数等。 推论统计就是研究如何根据样本数据去推断总体数量特征的方法,它是将数据分解成样本进行AI模型训练、验证和测试的基础。
- 推论统计简介:UD-201
- Youtube视频系列:Brandon Foltz
- Python中的统计信息:Statsmodel
3.使用Pandas和其他库(计划:1天)
Pandas是一个Python数据分析库,它包含所有可以使用的数据以及处理它的所有方法。根据第2步中讨论的统计知识,你可以学会数据分成样本。NumPy是一个Python软件包,可用作Python数据科学生态系统的基础。Scipy是另一个Python库,它将用于不同的数据操作。
- Kaggle数据科学学习:学习Pandas和其他库
- 学习Pandas:如何学习Pandas
- 在http://Python.org上学习:Pandas基础知识
4.了解数据表达和可视化(计划:2天)
如果要进入这个领域,你就不可避免地要把自己的想法展示给业务/产品团队看。也许在你眼里,数据本身就能表示下一步该做什么,哪些数据起作用了,哪些没有——但不是每个人都看得懂图表并理解它们所揭示的内容的。正确的数据需要用正确的方式来呈现,它要让人看得懂,更要让人易于理解。这就是数据可视化,一项非常重要但常常被忽视的技能。
对于这项技能,没有人能教你怎么做,你只能自己学。
- Stichfix算法之旅:algorithms-tour.stitchfix.com/
5.概率 - 回归模型(计划:2天)
概率是事件发生的可能性。人们在线购买产品、点击链接或使用功能,如果AI要解决这些所有问题,它就要基于某种基本概率。简而言之,概率构成了构建数据消耗型算法所需的逻辑基础。
这个领域的很大一部分工作内容是准备不同的模型来适应数据或从中推断。线性回归、Logistic回归、梯度下降是几乎是建模过程中无法避免的,它们非常重要,一个合理的回归模型将帮你准确预测数据的走向或接下来会发生的情况。
- 论文Practical recommendations for gradient-based training of deep architectures:arxiv.org/abs/1206.5533
- 在线统计教材(概率部分):Probability Deep Dive
- 一文学会回归模型:Multiple Regression
6.机器学习基础(计划:4天)
机器学习可被用于预测用户的行为、自动驾驶汽车等诸多领域。它结合了廉价的计算能力与便宜的数据存储,已经成为整个AI行业的风潮。
- 机器学习算法(重要算法列表):ML Algorithms
- 背景(ML中的背景技术):Understanding Backdrop by Andrej Karpathy
- TensorFlow教程:Tensorflow Tutorials
7.Advanced ML(计划:3天)
Advanced ML包含了各种处理复杂数据问题的算法和技术。比如时间序列数据可能很复杂,传统ML算法解决不了这个问题,但LSTM (长期短期记忆网络)在这里就很适合。
- LSTM(理解LSTM的最简单方法):Understanding LSTMs
- 时间序列的Kaggle示例:用于时间序列分析的机器学习
- Advanced ML(布鲁塞尔大学):时间序列预测的机器学习策略
8.现实世界/非结构化数据处理(计划:3天)
谷歌先进的语音识别能力是众所周知的。他们使用循环神经网络(RNN)来实现这一目标。由于数据是非结构化的,网络没有足够的信息进行处理,因此我们就需要提取有关字符或数据序列的信息并将其提供给网络。这种RNN适用于语音识别,这也是一个广泛的研究领域。
- 使用RNN的实用指南:Time-Series Prediction using RNNs
- 了解反向传播算法:Stanford’s Back propagation Class
机器学习研究的数据集列表:en.wikipedia.org/wiki/List_of_datasets_for_machine_learning_research
一旦掌握了这些技巧,你就可以使用上面的链接来使用数据,并熟悉数据的大小和工作类型。
9.深度学习 - 神经网络(计划:3天)
深度学习在许多方面与ML重叠。它包括GAN、半监督学习等概念。CNN(卷积神经网络)在图像识别和分类领域具有广泛的影响。如果你要去相关公司,那CNN绝对是你需要重点复习和练习的知识点。
- 卷积神经网络:CS-231(Stanford Class Notes)
- 深度学习(书):neuralnetworksanddeeplearning.com/
- 先进的深度学习(书):www.deeplearningbook.org/
以上就是我的AI/ML/DS面试准备工作。如果你想参考使用,请根据你自己所在的区域和目标岗位做一些调整。比起专业研究人员和数据工程师,想转行的普通计算机工程师可能要花更多的时间,具体视个人知识水平、时间限制和公司特定的要求而定。一般来说,应聘者准备时间应该保证在20-22天以上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号