
PythonProgramming.net Python 金融教程(转)
PythonProgramming.net Python 金融教程(转)
一、入门和获取股票数据
您好,欢迎来到 Python 金融系列教程。在本系列中,我们将使用 Pandas 框架来介绍将金融(股票)数据导入 Python 的基础知识。从这里开始,我们将操纵数据,试图搞出一些公司的投资系统,应用一些机器学习,甚至是一些深度学习,然后学习如何回溯测试一个策略。我假设你知道 Python 基础。如果您不确定,请点击基础链接,查看系列中的一些主题,并进行判断。如果在任何时候你卡在这个系列中,或者对某个主题或概念感到困惑,请随时寻求帮助,我将尽我所能提供帮助。
我被问到的一个常见问题是,我是否使用这些技术投资或交易获利。我主要是为了娱乐,并且练习数据分析技巧而玩财务数据,但实际上这也影响了我今天的投资决策。在写这篇文章的时候,我并没有用编程来进行实时算法交易,但是我已经有了实际的盈利,但是在算法交易方面还有很多工作要做。最后,如何操作和分析财务数据,以及如何测试交易状态的知识已经为我节省了大量的金钱。
这里提出的策略都不会使你成为一个超富有的人。如果他们愿意,我可能会把它们留给自己!然而,知识本身可以为你节省金钱,甚至可以使你赚钱。
好吧,让我们开始吧。首先,我正在使用 Python 3.5,但你应该能够获取更高版本。我会假设你已经安装了Python。如果你没有 64 位的 Python,但有 64 位的操作系统,去获取 64 位的 Python,稍后会帮助你。如果你使用的是 32 位操作系统,那么我对你的情况感到抱歉,不过你应该没问题。
用于启动的所需模块:
- NumPy
- Matplotlib
- Pandas
- Pandas-datareader
- BeautifulSoup4
- scikit-learn / sklearn
这些是现在做的,我们会在其他模块出现时处理它们。 首先,让我们介绍一下如何使用 pandas,matplotlib 和 Python 处理股票数据。
如果您想了解 Matplotlib 的更多信息,请查看 Matplotlib 数据可视化系列教程。
如果您想了解 Pandas 的更多信息,请查看 Pandas 数据分析系列教程。
首先,我们将执行以下导入:
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import pandas as pd
import pandas_datareader.data as web
Datetime让我们很容易处理日期,matplotlib用于绘图,Pandas 用于操纵数据,pandas_datareader是我写这篇文章时最新的 Pandas io 库。
现在进行一些启动配置:
style.use('ggplot')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
我们正在设置一个风格,所以我们的图表看起来并不糟糕。 在金融领域,即使你亏本,你的图表也是非常重要的。 接下来,我们设置一个开始和结束datetime 对象,这将是我们要获取股票价格信息的日期范围。
现在,我们可以从这些数据中创建一个数据帧:
df = web.DataReader('TSLA', "yahoo", start, end)
如果您目前不熟悉DataFrame对象,可以查看 Pandas 的教程,或者只是将其想象为电子表格或存储器/ RAM 中的数据库表。 这只是一些行和列,并带有一个索引和列名乘。 在我们的这里,我们的索引可能是日期。 索引应该是与所有列相关的东西。
web.DataReader('TSLA', "yahoo", start, end)这一行,使用pandas_datareader包,寻找股票代码TSLA(特斯拉),从 yahoo 获取信息,从我们选择的起始和结束日期起始或结束。 以防你不知道,股票是公司所有权的一部分,代码是用来在证券交易所引用公司的“符号”。 大多数代码是 1-4 个字母。
所以现在我们有一个Pandas.DataFrame对象,它包含特斯拉的股票交易信息。 让我们看看我们在这里有啥:
print(df.head())
Open High Low Close Volume Adj Close
Date
2010-06-29 19.000000 25.00 17.540001 23.889999 18766300 23.889999
2010-06-30 25.790001 30.42 23.299999 23.830000 17187100 23.830000
2010-07-01 25.000000 25.92 20.270000 21.959999 8218800 21.959999
2010-07-02 23.000000 23.10 18.709999 19.200001 5139800 19.200001
2010-07-06 20.000000 20.00 15.830000 16.110001 6866900 16.110001
.head()是可以用Pandas DataFrames做的事情,它会输出前n行,其中n是你传递的可选参数。如果不传递参数,则默认值为 5。我们绝对会使用.head()来快速浏览一下我们的数据,以确保我们在正路上。看起来很棒!
以防你不知道:
- 开盘价 - 当股市开盘交易时,一股的价格是多少?
- 最高价 - 在交易日的过程中,那一天的最高价是多少?
- 最低价 - 在交易日的过程中,那一天的最低价是多少?
- 收盘价 - 当交易日结束时,最终的价格是多少?
- 成交量 - 那一天有多少股交易?
调整收盘价 - 这一个稍微复杂一些,但是随着时间的推移,公司可能决定做一个叫做股票拆分的事情。例如,苹果一旦股价超过 1000 美元就做了一次。由于在大多数情况下,人们不能购买股票的一小部分,股票价格 1000 美元相当限制投资者。公司可以做股票拆分,他们说每股现在是 2 股,价格是一半。任何人如果以 1,000 美元买入 1 股苹果股份,在拆分之后,苹果的股票翻倍,他们将拥有 2 股苹果(AAPL),每股价值 500 美元。调整收盘价是有帮助的,因为它解释了未来的股票分割,并给出分割的相对价格。出于这个原因,调整价格是你最有可能处理的价格。
二、处理数据和绘图
欢迎阅读 Python 金融系列教程的第 2 部分。 在本教程中,我们将使用我们的股票数据进一步拆分一些基本的数据操作和可视化。 我们将使用的起始代码(在前面的教程中已经介绍过)是:
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import pandas as pd
import pandas_datareader.data as web
style.use('ggplot')
start = dt.datetime(2000,1,1)
end = dt.datetime(2016,12,31)
df = web.DataReader('TSLA', 'yahoo', start, end)
我们可以用这些DataFrame做些什么? 首先,我们可以很容易地将它们保存到各种数据类型中。 一个选项是csv:
df.to_csv('TSLA.csv')
我们也可以将数据从 CSV 文件读取到DataFrame中,而不是将数据从 Yahoo 财经 API 读取到DataFrame中:
df = pd.read_csv('tsla.csv', parse_dates=True, index_col=0)
现在,我们可以绘制它:
df.plot()
plt.show()
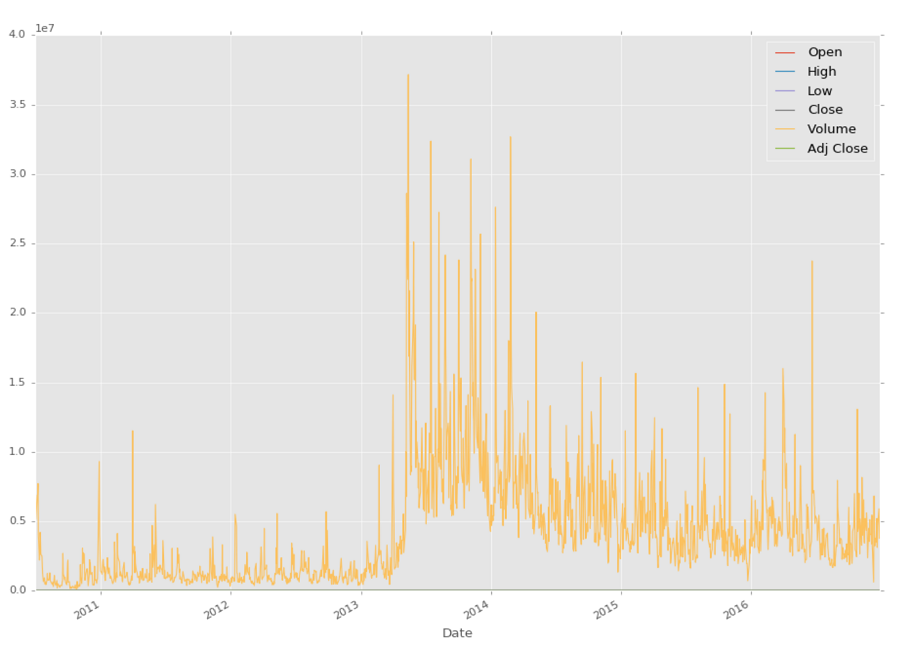
很酷,尽管我们真正能看到的唯一的东西就是成交量,因为它比股票价格大得多。 我们怎么可能仅仅绘制我们感兴趣的东西?
df['Adj Close'].plot()
plt.show()
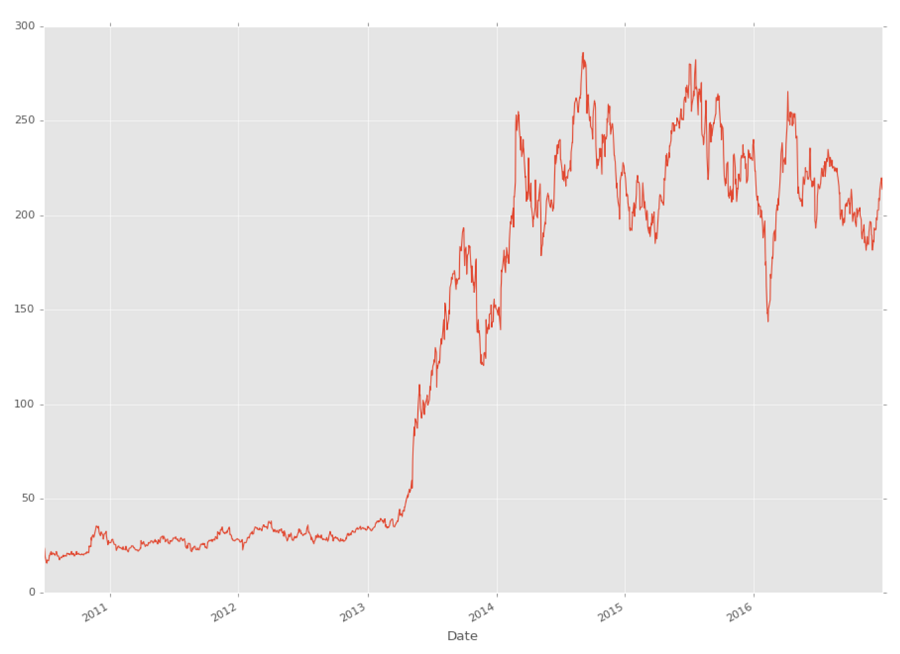
你可以看到,你可以在DataFrame中引用特定的列,如:df['Adj Close'],但是你也可以一次引用多个,如下所示:
df[['High','Low']]
在下一个教程中,我们将介绍这些数据的一些基本操作,以及一些更基本的可视化。
三、基本的股票数据操作
欢迎阅读 Python 金融系列教程的第 3 部分。 在本教程中,我们将使用我们的股票数据进一步拆分一些基本的数据操作和可视化。 我们将要使用的起始代码(在前面的教程中已经介绍过)是:
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import pandas as pd
import pandas_datareader.data as web
style.use('ggplot')
df = pd.read_csv('tsla.csv', parse_dates=True, index_col=0)
Pandas 模块配备了一堆可用的内置函数,以及创建自定义 Pandas 函数的方法。 稍后我们将介绍一些自定义函数,但现在让我们对这些数据执行一个非常常见的操作:移动均值。
简单移动均值的想法是选取时间窗口,并计算该窗口内的均值。 然后我们把这个窗口移动一个周期,然后再做一次。 在我们这里,我们将计算 100 天滚动均值。 因此,这将选取当前价格和过去 99 天的价格,加起来,除以 100,之后就是当前的 100 天移动均值。 然后我们把窗口移动一天,然后再做同样的事情。 在 Pandas 中这样做很简单:
df['100ma'] = df['Adj Close'].rolling(window=100).mean()
如果我们有一列叫做100ma,执行df['100ma']允许我们重新定义包含现有列的内容,否则创建一个新列,这就是我们在这里做的。 我们说df['100ma']列等同于应用滚动方法的df['Adj Close']列,窗口为 100,这个窗口将是 mean()(均值)操作。
现在,我们执行:
print(df.head())
Date Open High Low Close Volume \
Date
2010-06-29 2010-06-29 19.000000 25.00 17.540001 23.889999 18766300
2010-06-30 2010-06-30 25.790001 30.42 23.299999 23.830000 17187100
2010-07-01 2010-07-01 25.000000 25.92 20.270000 21.959999 8218800
2010-07-02 2010-07-02 23.000000 23.10 18.709999 19.200001 5139800
2010-07-06 2010-07-06 20.000000 20.00 15.830000 16.110001 6866900
Adj Close 100ma
Date
2010-06-29 23.889999 NaN
2010-06-30 23.830000 NaN
2010-07-01 21.959999 NaN
2010-07-02 19.200001 NaN
2010-07-06 16.110001 NaN
发生了什么? 在100ma列中,我们只看到NaN。 我们选择了 100 移动均值,理论上需要 100 个之前的数据点进行计算,所以我们在这里没有任何前 100 行的数据。 NaN的意思是“不是一个数字”。 有了 Pandas,你可以决定对缺失数据做很多事情,但现在,我们只需要改变最小周期参数:
Date Open High Low Close Volume \
Date
2010-06-29 2010-06-29 19.000000 25.00 17.540001 23.889999 18766300
2010-06-30 2010-06-30 25.790001 30.42 23.299999 23.830000 17187100
2010-07-01 2010-07-01 25.000000 25.92 20.270000 21.959999 8218800
2010-07-02 2010-07-02 23.000000 23.10 18.709999 19.200001 5139800
2010-07-06 2010-07-06 20.000000 20.00 15.830000 16.110001 6866900
Adj Close 100ma
Date
2010-06-29 23.889999 23.889999
2010-06-30 23.830000 23.860000
2010-07-01 21.959999 23.226666
2010-07-02 19.200001 22.220000
2010-07-06 16.110001 20.998000
好吧,可以用,现在我们想看看它! 但是我们已经看到了简单的图表,那么稍微复杂一些呢?
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=5, colspan=1)
ax2 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1,sharex=ax1)
如果你想了解subplot2grid的更多信息,请查看 Matplotlib 教程的子图部分。
基本上,我们说我们想要创建两个子图,而这两个子图都在6x1的网格中,我们有 6 行 1 列。 第一个子图从该网格上的(0,0)开始,跨越 5 行,并跨越 1 列。 下一个子图也在6x1网格上,但是从(5,0)开始,跨越 1 行和 1 列。 第二个子图带有sharex = ax1,这意味着ax2的x轴将始终与ax1的x轴对齐,反之亦然。 现在我们只是绘制我们的图形:
ax1.plot(df.index, df['Adj Close'])
ax1.plot(df.index, df['100ma'])
ax2.bar(df.index, df['Volume'])
plt.show()
在上面,我们在第一个子图中绘制了的close和100ma,第二个图中绘制volume。 我们的结果:
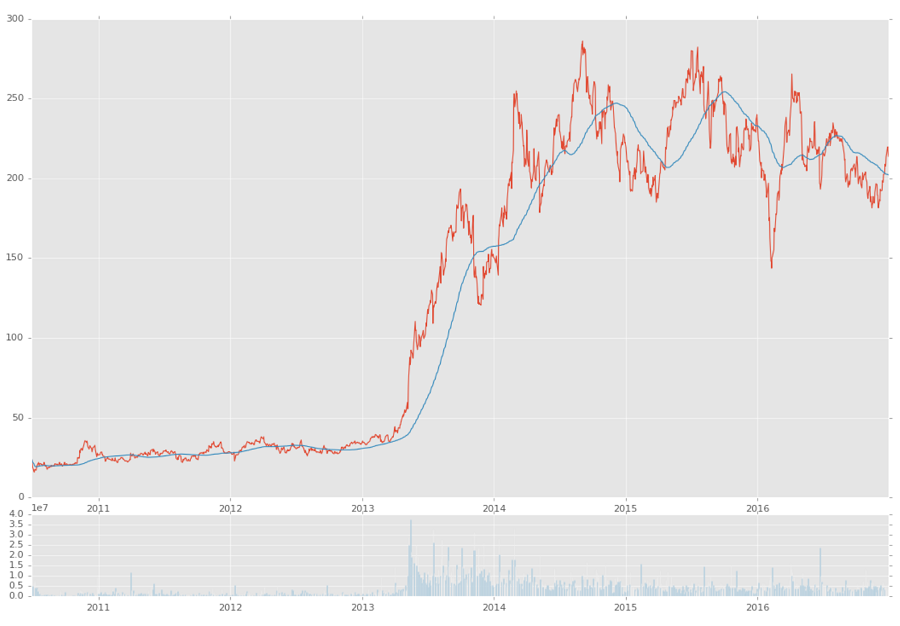
到这里的完整代码:
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import pandas as pd
import pandas_datareader.data as web
style.use('ggplot')
df = pd.read_csv('tsla.csv', parse_dates=True, index_col=0)
df['100ma'] = df['Adj Close'].rolling(window=100, min_periods=0).mean()
print(df.head())
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=5, colspan=1)
ax2 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1, sharex=ax1)
ax1.plot(df.index, df['Adj Close'])
ax1.plot(df.index, df['100ma'])
ax2.bar(df.index, df['Volume'])
plt.show()
在接下来的几个教程中,我们将学习如何通过 Pandas 数据重采样制作烛台图,并学习更多使用 Matplotlib 的知识。
四、更多股票操作
欢迎阅读 Python 金融教程系列的第 4 部分。 在本教程中,我们将基于Adj Close列创建烛台/ OHLC 图,我将介绍重新采样和其他一些数据可视化概念。
名为烛台图的 OHLC 图是一个图表,将开盘价,最高价,最低价和收盘价都汇总成很好的格式。 并且它使用漂亮的颜色,还记得我告诉你有关漂亮的图表的事情嘛?
之前的教程中,目前为止的起始代码:
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import pandas as pd
import pandas_datareader.data as web
style.use('ggplot')
df = pd.read_csv('tsla.csv', parse_dates=True, index_col=0)
不幸的是,即使创建 OHLC 数据是这样,Pandas 没有内置制作烛台图的功能。 有一天,我确信这个图表类型将会可用,但是,现在不是。 没关系,我们会实现它! 首先,我们需要做两个新的导入:
from matplotlib.finance import candlestick_ohlc
import matplotlib.dates as mdates
第一个导入是来自 matplotlib 的 OHLC 图形类型,第二个导入是特殊的mdates类型,它在对接中是个麻烦,但这是 matplotlib 图形的日期类型。 Pandas 自动为你处理,但正如我所说,我们没有那么方便的烛台。
首先,我们需要适当的 OHLC 数据。 我们目前的数据确实有 OHLC 值,除非我错了,特斯拉从未有过拆分,但是你不会总是这么幸运。 因此,我们将创建我们自己的 OHLC 数据,这也将使我们能够展示来自 Pandas 的另一个数据转换:
df_ohlc = df['Adj Close'].resample('10D').ohlc()
我们在这里所做的是,创建一个新的数据帧,基于df ['Adj Close']列,使用 10 天窗口重采样,并且重采样是一个 OHLC(开高低关)。我们也可以用.mean()或.sum()计算 10 天的均值,或 10 天的总和。请记住,这 10 天的均值是 10 天均值,而不是滚动均值。由于我们的数据是每日数据,重采样到 10 天的数据有效地缩小了我们的数据大小。这就是你规范多个数据集的方式。有时候,您可能会在每个月的第一天记录一次数据,在每个月末记录其他数据,最后每周记录一些数据。您可以将该数据帧重新采样到月底,并有效地规范化所有东西!这是一个更先进的 Padas 功能,如果你喜欢,你可以更多了解 Pandas 的序列。
我们想要绘制烛台数据以及成交量数据。我们不需要将成交量数据重采样,但是我们应该这样做,因为与我们的10D价格数据相比,这个数据太细致了。
df_volume = df['Volume'].resample('10D').sum()
我们在这里使用sum,因为我们真的想知道在这 10 天内交易总量,但也可以用平均值。 现在如果我们这样做:
print(df_ohlc.head())
open high low close
Date
2010-06-29 23.889999 23.889999 15.800000 17.459999
2010-07-09 17.400000 20.639999 17.049999 20.639999
2010-07-19 21.910000 21.910000 20.219999 20.719999
2010-07-29 20.350000 21.950001 19.590000 19.590000
2010-08-08 19.600000 19.600000 17.600000 19.150000
这是预期,但是,我们现在要将这些信息移动到 matplotlib,并将日期转换为mdates版本。 由于我们只是要在 Matplotlib 中绘制列,我们实际上不希望日期成为索引,所以我们可以这样做:
df_ohlc = df_ohlc.reset_index()
现在dates 只是一个普通的列。 接下来,我们要转换它:
df_ohlc['Date'] = df_ohlc['Date'].map(mdates.date2num)
现在我们打算配置图形:
fig = plt.figure()
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=5, colspan=1)
ax2 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1,sharex=ax1)
ax1.xaxis_date()
除了ax1.xaxis_date()之外,你已经看到了一切。 这对我们来说,是把轴从原始的mdate数字转换成日期。
现在我们可以绘制烛台图:
candlestick_ohlc(ax1, df_ohlc.values, width=2, colorup='g')
之后是成交量:
ax2.fill_between(df_volume.index.map(mdates.date2num),df_volume.values,0)
fill_between函数将绘制x,y,然后填充之间的内容。 在我们的例子中,我们选择 0。
plt.show()
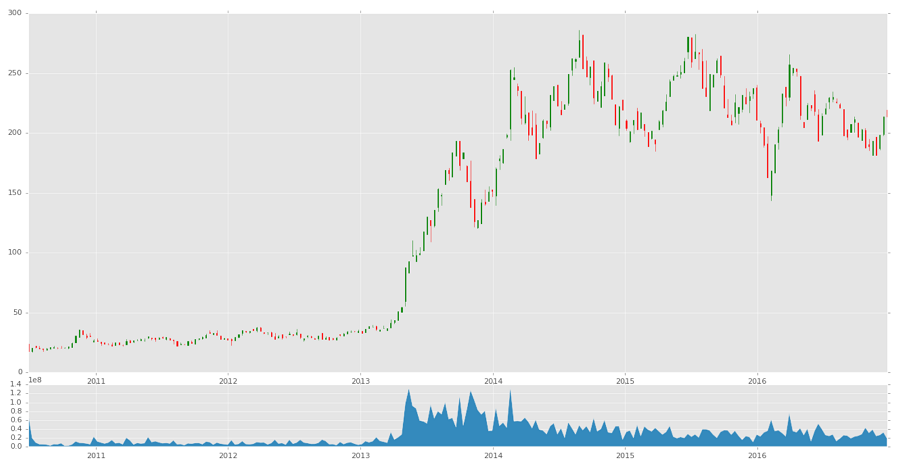
这个教程的完整代码:
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
from matplotlib.finance import candlestick_ohlc
import matplotlib.dates as mdates
import pandas as pd
import pandas_datareader.data as web
style.use('ggplot')
df = pd.read_csv('tsla.csv', parse_dates=True, index_col=0)
df_ohlc = df['Adj Close'].resample('10D').ohlc()
df_volume = df['Volume'].resample('10D').sum()
df_ohlc.reset_index(inplace=True)
df_ohlc['Date'] = df_ohlc['Date'].map(mdates.date2num)
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=5, colspan=1)
ax2 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1, sharex=ax1)
ax1.xaxis_date()
candlestick_ohlc(ax1, df_ohlc.values, width=5, colorup='g')
ax2.fill_between(df_volume.index.map(mdates.date2num), df_volume.values, 0)
plt.show()
在接下来的几个教程中,我们将把可视化留到后面一些,然后专注于获取并处理数据。
五、自动获取 SP500 列表
欢迎阅读 Python 金融教程系列的第 5 部分。在本教程和接下来的几章中,我们将着手研究如何能够获取大量价格信息,以及如何一次处理所有这些数据。
首先,我们需要一个公司名单。我可以给你一个清单,但实际上获得股票清单可能只是你可能遇到的许多挑战之一。在我们的案例中,我们需要一个 SP500 公司的 Python 列表。
无论您是在寻找道琼斯公司,SP500 指数还是罗素 3000 指数,这些公司的信息都有可能在某个地方发布。您需要确保它是最新的,但是它可能还不是完美的格式。在我们的例子中,我们将从维基百科获取这个列表:http://en.wikipedia.org/wiki/List_of_S%26P_500_companies。
维基百科中的代码/符号组织在一张表里面。为了解决这个问题,我们将使用 HTML 解析库,Beautiful Soup。如果你想了解更多,我有一个使用 Beautiful Soup 进行网页抓取的简短的四部分教程。
首先,我们从一些导入开始:
import bs4 as bs
import pickle
import requests
bs4是 Beautiful Soup,pickle 是为了我们可以很容易保存这个公司的名单,而不是每次我们运行时都访问维基百科(但要记住,你需要及时更新这个名单!),我们将使用 requests 从维基百科页面获取源代码。
这是我们函数的开始:
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
首先,我们访问维基百科页面,并获得响应,其中包含我们的源代码。 为了处理源代码,我们想要访问.text属性,我们使用 BeautifulSoup 将其转为soup。 如果您不熟悉 BeautifulSoup 为您所做的工作,它基本上将源代码转换为一个 BeautifulSoup 对象,马上就可以看做一个典型的 Python 对象。
有一次维基百科试图拒绝 Python 的访问。 目前,在我写这篇文章的时候,代码不改变协议头也能工作。 如果您发现原始源代码(resp.text)似乎不返回相同的页面,像您在家用计算机上看到的那样,请添加以下内容并更改resp var代码:
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux i686) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.27 Safari/537.17'}
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies',
headers=headers)
一旦我们有了soup,我们可以通过简单地搜索wikitable sortable类来找到股票数据表。 我知道指定这个表的唯一原因是,因为我之前在浏览器中查看了源代码。 可能会有这样的情况,你想解析一个不同的网站的股票列表,也许它是在一个表中,也可能是一个列表,或者可能是一些div标签。 这都是一个非常具体的解决方案。 从这里开始,我们仅仅遍历表格:
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
对于每一行,在标题行之后(这就是为什么我们要执行[1:]),我们说股票是“表格数据”(td),我们抓取它的.text, 将此代码添加到我们的列表中。
现在,如果我们可以保存这个列表,那就好了。 我们将使用pickle模块来为我们序列化 Python 对象。
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
我们希望继续并保存它,因此我们无需每天多次请求维基百科。 在任何时候,我们可以更新这个清单,或者我们可以编程一个月检查一次...等等。
目前为止的完整代码:
import bs4 as bs
import pickle
import requests
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
save_sp500_tickers()
现在我们已经知道了代码,我们已经准备好提取所有的信息,这是我们将在下一个教程中做的事情。
六、获取 SP500 中所有公司的价格数据
欢迎阅读 Python 金融教程系列的第 6 部分。 在之前的 Python 教程中,我们介绍了如何获取我们感兴趣的公司名单(在我们的案例中是 SP500),现在我们将获取所有这些公司的股票价格数据。
目前为止的代码:
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
我们打算添加一些新的导入:
import datetime as dt
import os
import pandas as pd
import pandas_datareader.data as web
我们将使用datetime为 Pandas datareader指定日期,os用于检查并创建目录。 你已经知道 Pandas 干什么了!
我们的新函数的开始:
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
在这里,我将展示一个简单示例,可以处理是否重新加载 SP500 列表。 如果我们让它这样,这个程序将重新抓取 SP500,否则将只使用我们的pickle。 现在我们准备抓取数据。
现在我们需要决定我们要处理的数据。 我倾向于尝试解析网站一次,并在本地存储数据。 我不会事先知道我可能用数据做的所有事情,但是我知道如果我不止一次地抓取它,我还可以保存它(除非它是一个巨大的数据集,但不是)。 因此,对于每一种股票,我们抓取所有雅虎可以返回给我们的东西,并保存下来。 为此,我们将创建一个新目录,并在那里存储每个公司的股票数据。 首先,我们需要这个初始目录:
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
您可以将这些数据集存储在与您的脚本相同的目录中,但在我看来,这会变得非常混乱。 现在我们准备好提取数据了。 你已经知道如何实现,我们在第一个教程中完成了!
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
你可能想要为这个函数传入force_data_update参数,因为现在它不会重新提取它已经访问的数据。 由于我们正在提取每日数据,所以您最好至少重新提取最新的数据。 也就是说,如果是这样的话,最好对每个公司使用数据库而不是表格,然后从 Yahoo 数据库中提取最新的值。 但是现在我们会保持简单!
目前为止的代码:
import bs4 as bs
import datetime as dt
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
#save_sp500_tickers()
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
get_data_from_yahoo()
运行它。如果雅虎阻拦你的话,你可能想添加import time和time.sleep(0.5)或一些东西。 在我写这篇文章的时候,雅虎并没有阻拦我,我能够毫无问题地完成这个任务。 但是这可能需要你一段时间,尤其取决于你的机器。 好消息是,我们不需要再做一遍! 同样在实践中,因为这是每日数据,但是您可能每天都执行一次。
另外,如果你的互联网速度很慢,你不需要获取所有的代码,即使只有 10 个就足够了,所以你可以用ticker [:10]或者类似的东西来加快速度。
在下一个教程中,一旦你下载了数据,我们将把我们感兴趣的数据编译成一个大的 PandasDataFrame。
七、将所有 SP500 价格组合到一个DataFrame
欢迎阅读 Python 金融系列教程的第 7 部分。 在之前的教程中,我们抓取了整个 SP500 公司的雅虎财经数据。 在本教程中,我们将把这些数据放在一个DataFrame中。
目前为止的代码:
import bs4 as bs
import datetime as dt
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
虽然我们拥有了所有的数据,但是我们可能要一起评估数据。 为此,我们将把所有的股票数据组合在一起。 目前的每个股票文件都带有:开盘价,最高价,最低价,收盘价,成交量和调整收盘价。 至少在最开始,我们现在几乎只对调整收盘价感兴趣。
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
首先,我们获取我们以前生成的代码,并从一个叫做main_df的空DataFrame开始。 现在,我们准备读取每个股票的数据帧:
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
您不需要在这里使用 Python 的enumerate ,我只是使用它,以便知道我们在读取所有数据的过程中的哪里。 你可以迭代代码。 到了这里,我们可以使用有趣的数据来生成额外的列,如:
df['{}_HL_pct_diff'.format(ticker)] = (df['High'] - df['Low']) / df['Low']
df['{}_daily_pct_chng'.format(ticker)] = (df['Close'] - df['Open']) / df['Open']
但是现在,我们不会因此而烦恼。 只要知道这可能是一条遵循之路。 相反,我们真的只是对Adj Close列感兴趣:
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
现在我们已经得到了这一列(或者像上面那样的额外列,但是请记住,在这个例子中,我们没有计算HL_pct_diff或daily_pct_chng)。 请注意,我们已将Adj Close列重命名为任何股票名称。 我们开始构建共享数据帧:
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
如果main_df中没有任何内容,那么我们将从当前的df开始,否则我们将使用 Pandas 的join。
仍然在这个for循环中,我们将添加两行:
if count % 10 == 0:
print(count)
这将只输出当前的股票数量,如果它可以被 10 整除。count % 10计算被除数除以 10 的余数。所以,如果我们计算count % 10 == 0,并且如果当前计数能被 10 整除,余数为零,我们只有看到if语句为真。
我们完成了for循环的时候:
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
目前为止的函数及其调用:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
compile_data()
目前为止的完整代码:
import bs4 as bs
import datetime as dt
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
compile_data()
在下一个教程中,我们将尝试查看,是否可以快速找到数据中的任何关系。
八、创建大型 SP500 公司相关性表
欢迎阅读 Python 金融教程系列的第 8 部分。 在之前的教程中,我们展示了如何组合 SP500 公司的所有每日价格数据。 在本教程中,我们将看看是否可以找到任何有趣的关联数据。 为此,我们希望将其可视化,因为它是大量数据。 我们将使用 Matplotlib,以及 Numpy。
目前为止的代码:
import bs4 as bs
import datetime as dt
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
compile_data()
现在我们打算添加下列导入并设置样式:
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
style.use('ggplot')
下面我们开始构建 Matplotlib 函数:
def visualize_data():
df = pd.read_csv('sp500_joined_closes.csv')
到了这里,我们可以绘制任何公司:
df['AAPL'].plot()
plt.show()
...但是我们没有浏览所有东西,就绘制单个公司! 相反,让我们来看看所有这些公司的相关性。 在 Pandas 中建立相关性表实际上是非常简单的:
df_corr = df.corr()
print(df_corr.head())
这就是它了。.corr()会自动查看整个DataFrame,并确定每列与每列的相关性。 我已经看到付费的网站也把它做成服务。 所以,如果你需要一些副业的话,那么你可以用它!
我们当然可以保存这个,如果我们想要的话:
df_corr.to_csv('sp500corr.csv')
相反,我们要绘制它。 为此,我们要生成一个热力图。 Matplotlib 中没有内置超级简单的热力图,但我们有工具可以制作。 为此,首先我们需要实际的数据来绘制:
data1 = df_corr.values
这会给我们这些数值的 NumPy 数组,它们是相关性的值。 接下来,我们将构建我们的图形和坐标轴:
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
现在我们使用pcolor来绘制热力图:
heatmap1 = ax1.pcolor(data1, cmap=plt.cm.RdYlGn)
这个热力图使用一系列的颜色来制作,这些颜色可以是任何东西到任何东西的范围,颜色比例由我们使用的cmap生成。 你可以在这里找到颜色映射的所有选项。 我们将使用RdYlGn,它是一个颜色映射,低端为红色,中间为黄色,较高部分为绿色,这将负相关表示为红色,正相关为绿色,无关联为黄色。 我们将添加一个边栏,是个作为“比例尺”的颜色条:
fig1.colorbar(heatmap1)
接下来,我们将设置我们的x和y轴刻度,以便我们知道哪个公司是哪个,因为现在我们只是绘制了数据:
ax1.set_xticks(np.arange(data1.shape[1]) + 0.5, minor=False)
ax1.set_yticks(np.arange(data1.shape[0]) + 0.5, minor=False)
这样做只是为我们创建刻度。 我们还没有任何标签。
现在我们添加:
ax1.invert_yaxis()
ax1.xaxis.tick_top()
这会翻转我们的yaxis,所以图形更容易阅读,因为x和y之间会有一些空格。 一般而言,matplotlib 会在图的一端留下空间,因为这往往会使图更容易阅读,但在我们的情况下,却没有。 然后我们也把xaxis翻转到图的顶部,而不是传统的底部,同样使这个更像是相关表应该的样子。 现在我们实际上将把公司名称添加到当前没有名字的刻度中:
column_labels = df_corr.columns
row_labels = df_corr.index
ax1.set_xticklabels(column_labels)
ax1.set_yticklabels(row_labels)
在这里,我们可以使用两边完全相同的列表,因为column_labels和row_lables应该是相同的列表。 但是,对于所有的热力图而言,这并不总是正确的,所以我决定将其展示为,数据帧的任何热力图的正确方法。 最后:
plt.xticks(rotation=90)
heatmap1.set_clim(-1,1)
plt.tight_layout()
#plt.savefig("correlations.png", dpi = (300))
plt.show()
我们旋转xticks,这实际上是代码本身,因为通常他们会超出区域。 我们在这里有超过 500 个标签,所以我们要将他们旋转 90 度,所以他们是垂直的。 这仍然是一个图表,它太大了而看不清所有东西,但没关系。 heatmap1.set_clim(-1,1)那一行只是告诉colormap,我们的范围将从-1变为正1。应该已经是这种情况了,但是我们想确定一下。 没有这一行,它应该仍然是你的数据集的最小值和最大值,所以它本来是非常接近的。
所以我们完成了! 到目前为止的函数:
def visualize_data():
df = pd.read_csv('sp500_joined_closes.csv')
#df['AAPL'].plot()
#plt.show()
df_corr = df.corr()
print(df_corr.head())
df_corr.to_csv('sp500corr.csv')
data1 = df_corr.values
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
heatmap1 = ax1.pcolor(data1, cmap=plt.cm.RdYlGn)
fig1.colorbar(heatmap1)
ax1.set_xticks(np.arange(data1.shape[1]) + 0.5, minor=False)
ax1.set_yticks(np.arange(data1.shape[0]) + 0.5, minor=False)
ax1.invert_yaxis()
ax1.xaxis.tick_top()
column_labels = df_corr.columns
row_labels = df_corr.index
ax1.set_xticklabels(column_labels)
ax1.set_yticklabels(row_labels)
plt.xticks(rotation=90)
heatmap1.set_clim(-1,1)
plt.tight_layout()
#plt.savefig("correlations.png", dpi = (300))
plt.show()
visualize_data()
以及目前为止的完整代码:
import bs4 as bs
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
style.use('ggplot')
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
def visualize_data():
df = pd.read_csv('sp500_joined_closes.csv')
#df['AAPL'].plot()
#plt.show()
df_corr = df.corr()
print(df_corr.head())
df_corr.to_csv('sp500corr.csv')
data1 = df_corr.values
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
heatmap1 = ax1.pcolor(data1, cmap=plt.cm.RdYlGn)
fig1.colorbar(heatmap1)
ax1.set_xticks(np.arange(data1.shape[1]) + 0.5, minor=False)
ax1.set_yticks(np.arange(data1.shape[0]) + 0.5, minor=False)
ax1.invert_yaxis()
ax1.xaxis.tick_top()
column_labels = df_corr.columns
row_labels = df_corr.index
ax1.set_xticklabels(column_labels)
ax1.set_yticklabels(row_labels)
plt.xticks(rotation=90)
heatmap1.set_clim(-1,1)
plt.tight_layout()
#plt.savefig("correlations.png", dpi = (300))
plt.show()
visualize_data()
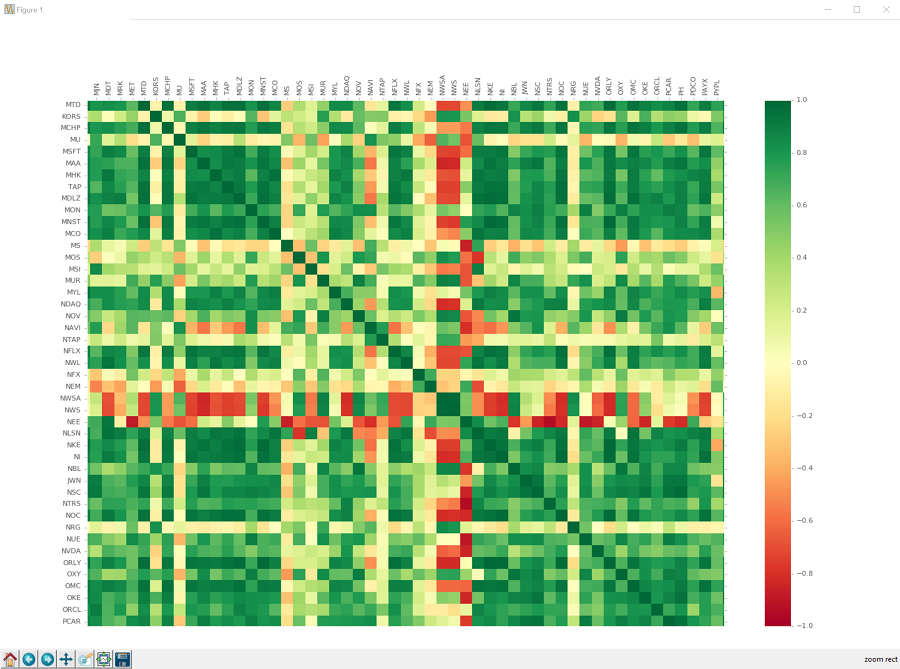
我们的劳动果实:

这是很大一个果实。
所以我们可以使用放大镜来放大:

如果你单击它,你可以单击并拖动要放大的框。 这个图表上的框很难看清楚,只知道它在那里。 点击,拖动,释放,你应该放大了,看到像这样的东西:
你可以从这里移动,使用十字箭头按钮:
您也可以通过点击主屏幕按钮返回到原始的完整图形。您也可以使用前进和后退按钮“前进”和“后退”到前一个视图。您可以通过点击软盘来保存它。我想知道我们使用软盘的图像来描绘保存东西,有多久了。多久之后人们完全不知道软盘是什么?
好吧,看看相关性,我们可以看到有很多关系。毫不奇怪,大多数公司正相关。有相当多的公司与其他公司有很强的相关性,还有相当多的公司是非常负相关的。甚至有一些公司与大多数公司呈负相关。我们也可以看到有很多公司完全没有关联。机会就是,投资于一群长期以来没有相关性的公司,将是一个多元化的合理方式,但我们现在还不知道。
不管怎样,这个数据已经有很多关系了。人们必须怀疑,一台机器是否能够纯粹依靠这些关系来识别和交易。我们可以轻松成为百万富豪吗?!我们至少可以试试!
九、处理数据,为机器学习做准备
欢迎阅读 Python 金融教程系列的第 9 部分。在之前的教程中,我们介绍了如何拉取大量公司的股票价格数据,如何将这些数据合并为一个大型数据集,以及如何直观地表示所有公司之间的一种关系。现在,我们将尝试采用这些数据,并做一些机器学习!
我们的想法是,看看如果我们获得所有当前公司的数据,并把这些数据扔给某种机器学习分类器,会发生什么。我们知道,随着时间的推移,各个公司彼此有着不同的练习,所以,如果机器能够识别并且拟合这些关系,那么我们可以从今天的价格变化中,预测明天会发生什么事情。咱们试试吧!
首先,所有机器学习都是接受“特征集”,并尝试将其映射到“标签”。无论我们是做 K 最近邻居还是深度神经网络学习,这都是一样的。因此,我们需要将现有的数据转换为特征集和标签。
我们的特征可以是其他公司的价格,但是我们要说的是,特征是所有公司当天的价格变化。我们的标签将是我们是否真的想买特定公司。假设我们正在考虑 Exxon(XOM)。我们要做的特征集是,考虑当天所有公司的百分比变化,这些都是我们的特征。我们的标签将是 Exxon(XOM)在接下来的x天内涨幅是否超过x%,我们可以为x选择任何我们想要的值。首先,假设一家公司在未来 7 天内价格上涨超过 2%,如果价格在这 7 天内下跌超过 2%,那么就卖出。
这也是我们可以比较容易做出的一个策略。如果算法说了买入,我们可以买,放置 2% 的止损(基本上告诉交易所,如果价格跌破这个数字/或者如果你做空公司,价格超过这个数字,那么退出我的位置)。否则,公司一旦涨了 2% 就卖掉,或者保守地在 1% 卖掉,等等。无论如何,你可以比较容易地从这个分类器建立一个策略。为了开始,我们需要为我们的训练数据放入未来的价格。
我将继续编写我们的脚本。如果这对您是个问题,请随时创建一个新文件并导入我们使用的函数。
目前为止的完整代码:
import bs4 as bs
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
style.use('ggplot')
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
def visualize_data():
df = pd.read_csv('sp500_joined_closes.csv')
#df['AAPL'].plot()
#plt.show()
df_corr = df.corr()
print(df_corr.head())
df_corr.to_csv('sp500corr.csv')
data1 = df_corr.values
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
heatmap1 = ax1.pcolor(data1, cmap=plt.cm.RdYlGn)
fig1.colorbar(heatmap1)
ax1.set_xticks(np.arange(data1.shape[1]) + 0.5, minor=False)
ax1.set_yticks(np.arange(data1.shape[0]) + 0.5, minor=False)
ax1.invert_yaxis()
ax1.xaxis.tick_top()
column_labels = df_corr.columns
row_labels = df_corr.index
ax1.set_xticklabels(column_labels)
ax1.set_yticklabels(row_labels)
plt.xticks(rotation=90)
heatmap1.set_clim(-1,1)
plt.tight_layout()
#plt.savefig("correlations.png", dpi = (300))
plt.show()
继续,让我们开始处理一些数据,这将帮助我们创建我们的标签:
def process_data_for_labels(ticker):
hm_days = 7
df = pd.read_csv('sp500_joined_closes.csv', index_col=0)
tickers = df.columns.values.tolist()
df.fillna(0, inplace=True)
这个函数接受一个参数:问题中的股票代码。 每个模型将在一家公司上训练。 接下来,我们想知道我们需要未来多少天的价格。 我们在这里选择 7。 现在,我们将读取我们过去保存的所有公司的收盘价的数据,获取现有的代码列表,现在我们将为缺失值数据填入 0。 这可能是你将来要改变的东西,但是现在我们将用 0 来代替。 现在,我们要抓取未来 7 天的百分比变化:
for i in range(1,hm_days+1):
df['{}_{}d'.format(ticker,i)] = (df[ticker].shift(-i) - df[ticker]) / df[ticker]
这为我们的特定股票创建新的数据帧的列,使用字符串格式化创建自定义名称。 我们获得未来值的方式是使用.shift,这基本上会使列向上或向下移动。 在这里,我们移动一个负值,这将选取该列,如果你可以看到它,它会把这个列向上移动i行。 这给了我们未来值,我们可以计算百分比变化。
最后:
df.fillna(0, inplace=True)
return tickers, df
我们在这里准备完了,我们将返回代码和数据帧,并且我们正在创建一些特征集,我们的算法可以用它来尝试拟合和发现关系。
我们的完整处理函数:
def process_data_for_labels(ticker):
hm_days = 7
df = pd.read_csv('sp500_joined_closes.csv', index_col=0)
tickers = df.columns.values.tolist()
df.fillna(0, inplace=True)
for i in range(1,hm_days+1):
df['{}_{}d'.format(ticker,i)] = (df[ticker].shift(-i) - df[ticker]) / df[ticker]
df.fillna(0, inplace=True)
return tickers, df
在下一个教程中,我们将介绍如何创建我们的“标签”。
十、十一、为机器学习标签创建目标
欢迎阅读 Python 金融系列教程的第 10 部分(和第 11 部分)。 在之前的教程中,我们开始构建我们的标签,试图使用机器学习和 Python 来投资。 在本教程中,我们将使用我们上一次教程的内容,在准备就绪时实际生成标签。
目前为止的代码:
import bs4 as bs
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
style.use('ggplot')
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
def visualize_data():
df = pd.read_csv('sp500_joined_closes.csv')
#df['AAPL'].plot()
#plt.show()
df_corr = df.corr()
print(df_corr.head())
df_corr.to_csv('sp500corr.csv')
data1 = df_corr.values
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
heatmap1 = ax1.pcolor(data1, cmap=plt.cm.RdYlGn)
fig1.colorbar(heatmap1)
ax1.set_xticks(np.arange(data1.shape[1]) + 0.5, minor=False)
ax1.set_yticks(np.arange(data1.shape[0]) + 0.5, minor=False)
ax1.invert_yaxis()
ax1.xaxis.tick_top()
column_labels = df_corr.columns
row_labels = df_corr.index
ax1.set_xticklabels(column_labels)
ax1.set_yticklabels(row_labels)
plt.xticks(rotation=90)
heatmap1.set_clim(-1,1)
plt.tight_layout()
#plt.savefig("correlations.png", dpi = (300))
plt.show()
def process_data_for_labels(ticker):
hm_days = 7
df = pd.read_csv(