深入理解Java多线程——ThreadLocal
定义
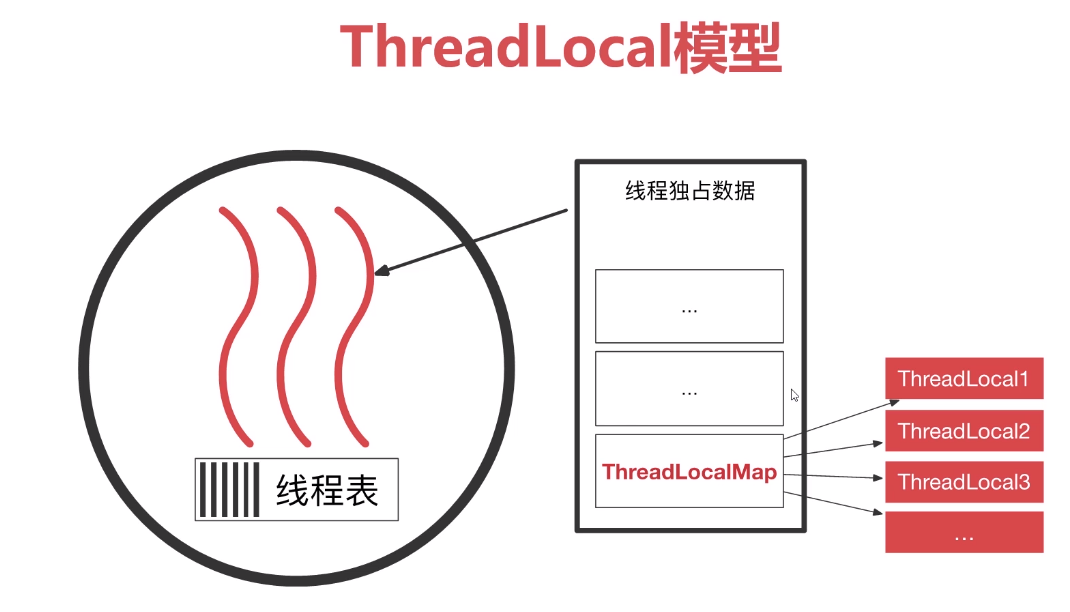
ThreadLocal是线程局部变量,不同线程的threadlocal相互独立。它是一种保存线程私有信息的机制,因为在现成的整个生命周期都有效,
所以可以方便地在一个线程关联的不同业务模块之间传递信息,比如事务ID、Cookie等上下文相关信息。
特点:
- 简单,开箱即用。
- 快速,无额外开销。
- 安全,线程安全。
threadlocal设计实现的优点:开箱即用,代码易读,符合经常阅读偶尔使用的原则
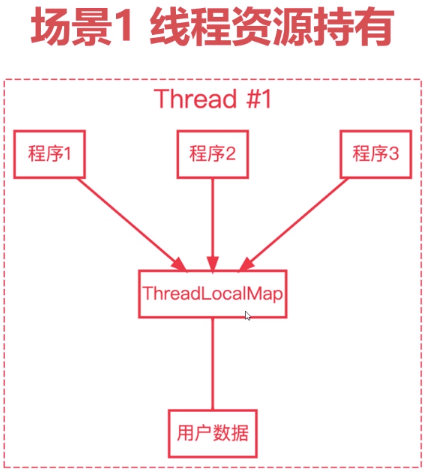
场景:资源持有、线程一致性、并发计算等多线程场景。
API

场景分析
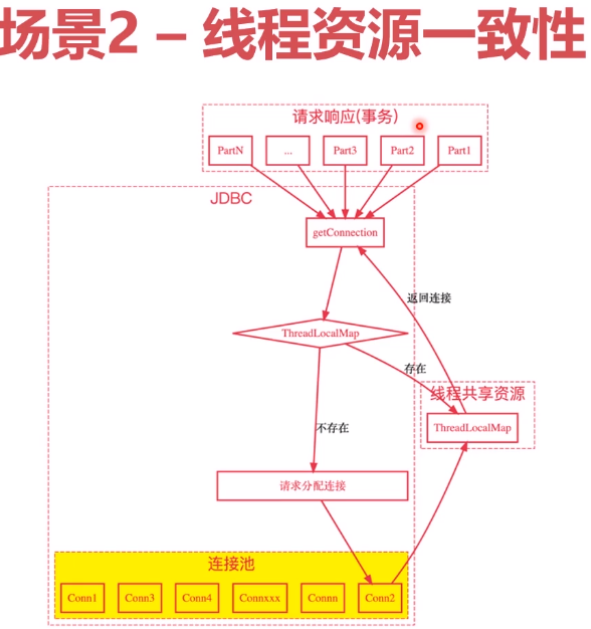
如jdbc事务的请求,part i 代表不同事务,如更新用户信息、更新订单信息等,需要保证各事务资源的一致性。
每一个事务请求连接时,先去threadlocal map里找,如果不存在,到连接池中请求分配连接,并存入map。
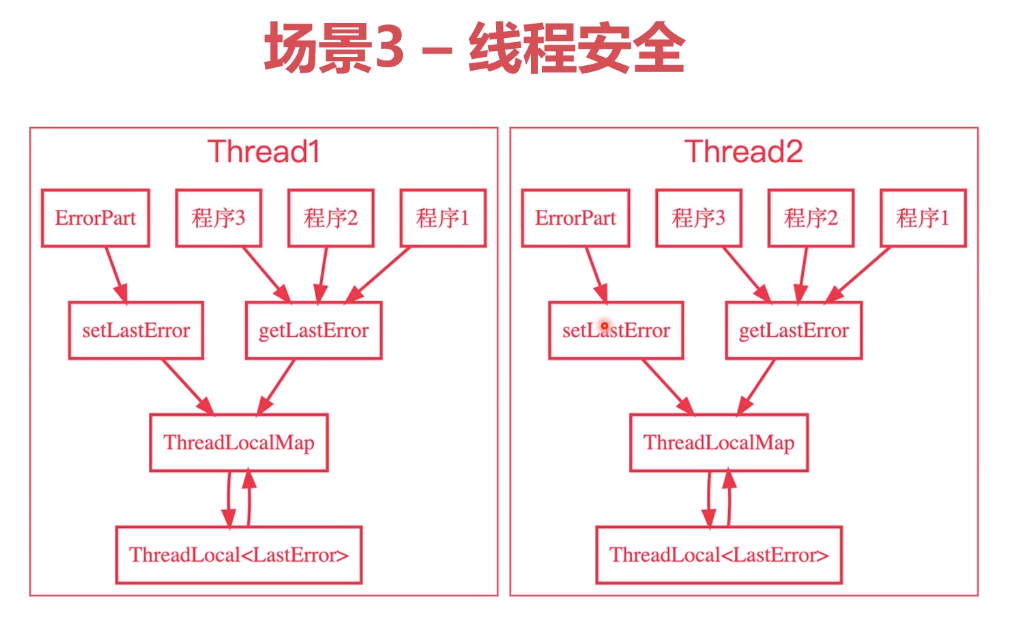
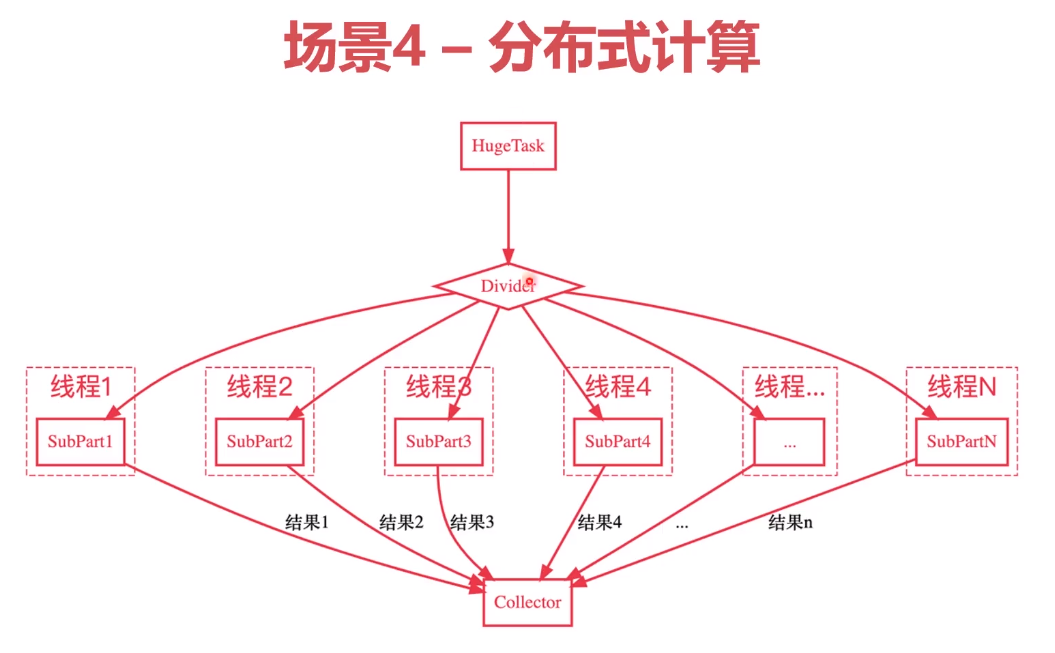
总结,ThreadLocal的主要作用是:
- 持有线程资源,供线程的各个部分使用
- 帮助维护多线程共享资源的一致性
- 线程安全的一种方案
场景实验,观察Spring框架在多线程场景的执行情况
压力测试工具,apache2-util
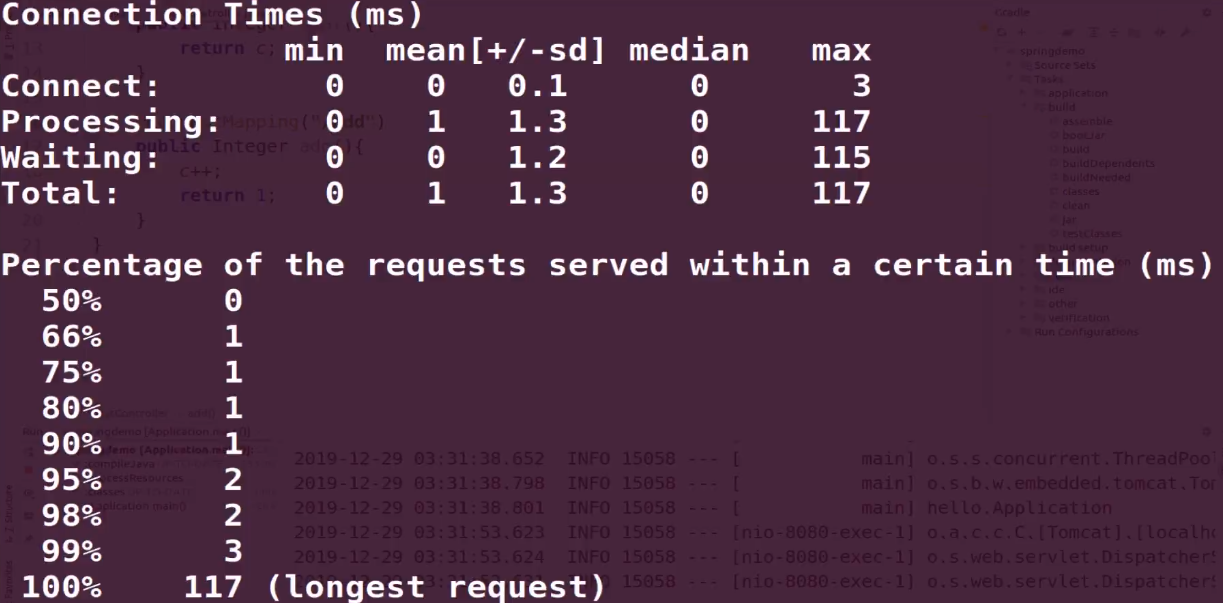
10000此请求,单线程

10000次请求,线程数加到100

虽然完成10000请求的速度变快了,但最终curl请求get到的数据会不一致。
原因是,多线程下,c是临界资源,c=c+1不具备原子性,要先读取c,在执行加1,再执行赋值。
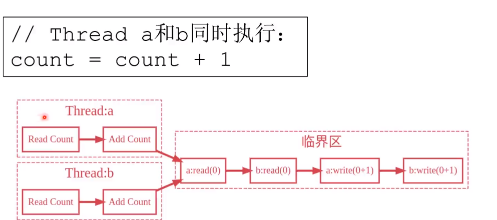
对c的访问加锁

测试发现curl get到的结果是10000,但速度会很慢,原因是加锁导致排队,并发实质上变成了串行,性能被锁卡住。
解决方法就是使用ThreadLocal,让线程在自己的局部变量资源上运行。
把c设为ThreadLocal
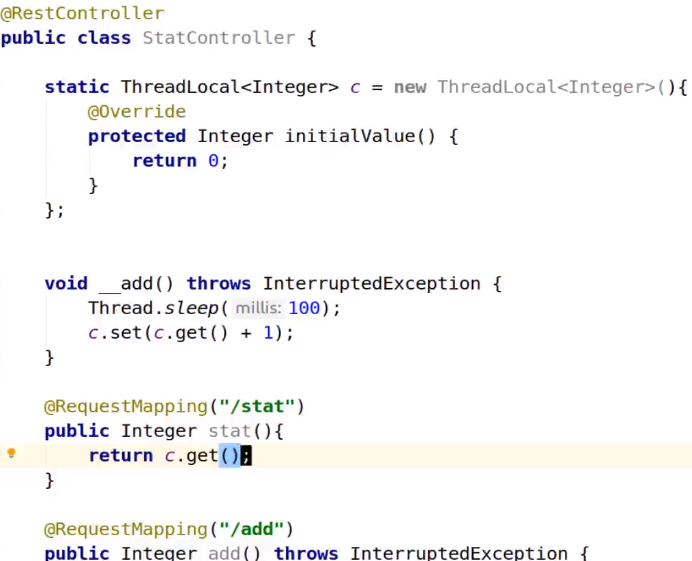
测试发现,最终统计数据依然不准确。
原因是spring默认线程池有20多个线程,这些线程每一个都有自己的局部变量c,执行10000请求后,需要收集各个线程的数据。
收集多个ThreadLocal中的数据
虽然threadlocal是各个线程独占的数据,但也是进程持有的,不过java没有提供收集数据的接口,所以可以通过hashmap或
hashset来存储threadlocal,最后一并收集。

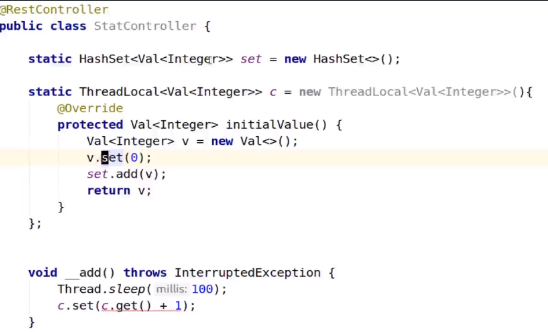

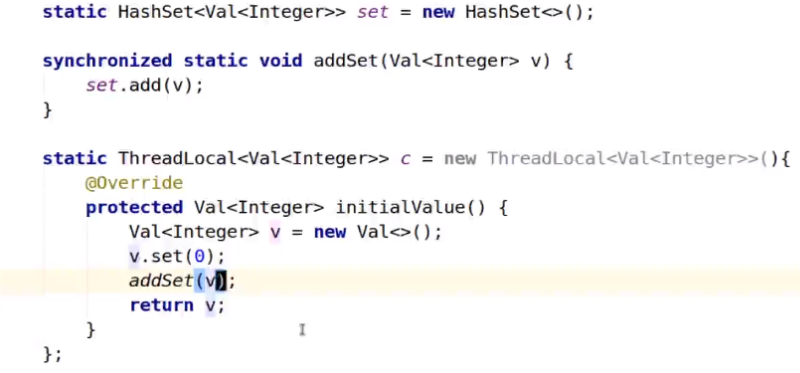
改进,因为set访问需要同步,所以addset中加入同步锁,而且set访问次数最多是线程池的线程数,相对c的访问次数要少,
属于低频访问,所以对总体性能影响小。
实验总结
- 基于线程池模型加同步锁很危险,可能因排队等锁,导致cpu使用不充分,从而严重拖慢性能。
- 虽然多线程不能完全避免同步问题,但使用ThreadLocal,可以把高频同步化为低频同步。
实现原理
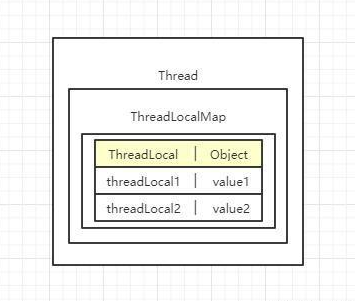
ThreadLocalMap
自定义一个类似HashMap的ThreadLocalMap存放ThreadLocal(弱引用),该map时ThreadLocal的静态内部类,延续了lazy-load模式,初始容量16,门限2/3。
ThreadLocalMap里面有个Entry数组,只有数组没有像HashMap那样有链表,因此当hash冲突的之后,ThreadLocalMap是采用线性探测的方式解决hash冲突。
Entry把ThreadLocal的弱引用作为key,让没用的ThreadLocal被GC清除。
ThreadLocal内部没有存储任何的值,它的作用只是当我们的ThreadLocalMap的key,让线程可以拿到对应的value。
satic class ThreadLocalMap {
satic class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
// …
}
回收被内存回收的弱引用所占的槽是超级复杂问题。
当Key为null时,该条目就变成“废弃条目”,相关“value”的回收,
往往依赖于几个关键点,即set、remove、rehash。当调用get()、set()方法时会去找到那个key被干掉的entry然后干掉它。
并且提供了remove()方法。虽然get()、set()会清理key为null的Entry,但是不是每次调用就会清理的,只有当get时候
直接hash没中,或者set时候也是直接hash没中,开始线性探测时候,碰到key为null的才会清理。
下面set的精简代码,具体的清理逻辑是实现在cleanSomeSlots和expungeStaleEntry之中。
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];; …) {
//…
if (k == null) {
// 替换废弃条目
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
// 扫描并清理发现的废弃条目,并检查容量是否超限
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();// 清理废弃条目,如果仍然超限,则扩容(加倍)
}
废弃项目的回收依赖于显式地触发,否则就要等待线程结束,进而回收相应ThreadLocalMap!这就是很多OOM的来源,
所以应用一定要自己负责remove,并且不要和线程池配合,因为worker线程往往是不会退出的。
hash算法
散列更均匀,减少冲突

解决冲突的方法是线形探测。这种方式解决hash冲突的效率很低,因此要注意ThreadLocal的数量。
线性探测,就是先根据初始key的hashcode值确定元素在table数组中的位置,如果这个位置上已经有其他key值的元素被占用,
则利用固定的算法寻找一定步长的下个位置,依次直至找到能够存放的位置。在ThreadLocalMap步长是1。
总结
解决一致性问题,除了排队(加锁)、投票(拜占庭将军)、CAS+voilate外,ThreadLocal不失为一个更轻量级的优选方案。
参考
https://www.imooc.com/learn/1217
《深入理解Java虚拟机》周志明
《Java核心技术36讲》杨晓峰
对ThreadLocal的理解

 浙公网安备 33010602011771号
浙公网安备 33010602011771号