

后缀数组(SA)
后缀数组(SA)
感觉会有很多写错或写不清楚的地方,读者发现问题可以评论或右侧 QQ 联系我,感谢!
约定
“ 后缀 ” 表示以第 个字符开头的后缀。
表示字符串 的第 位, 表示 中位置 的子串。
一个字符串从第 位开始,第 位结束。
两个字符串的大小关系定义如下:
-
与 为同一字符串,则 。
-
是 的真前缀,则 。
-
若不满足 1.2. 则一定存在最小的 满足 则 的大小关系由 和 的大小关系确定。
定义
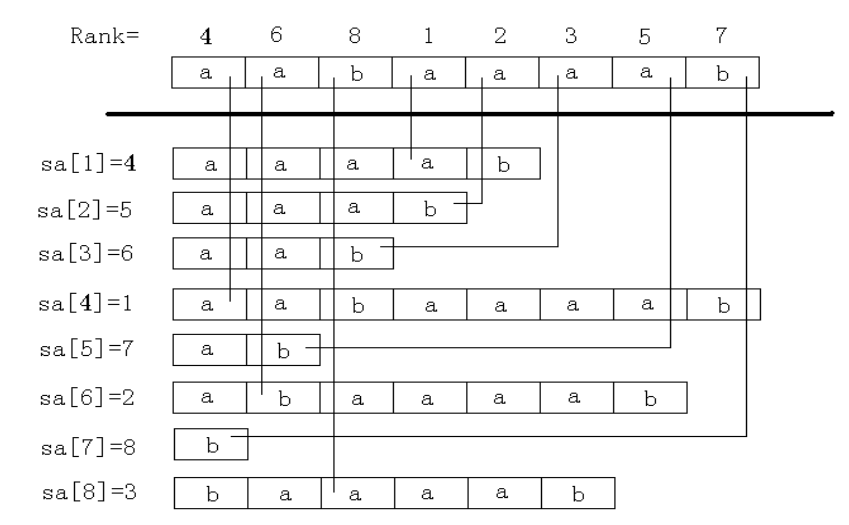
后缀数组主要求两个数组: 和 。
其中, 表示将所有后缀排序后第 小的后缀编号, 表示后缀 的排名,简单来说, 表示排名 的是谁, 表示后缀 排名第几。
显然,这两个数组满足 。以下是一个 和 的例子:
做法
做法
把所有后缀处理出来,用 sort 进行排序,每次比较为 则总时间复杂度为 。
做法
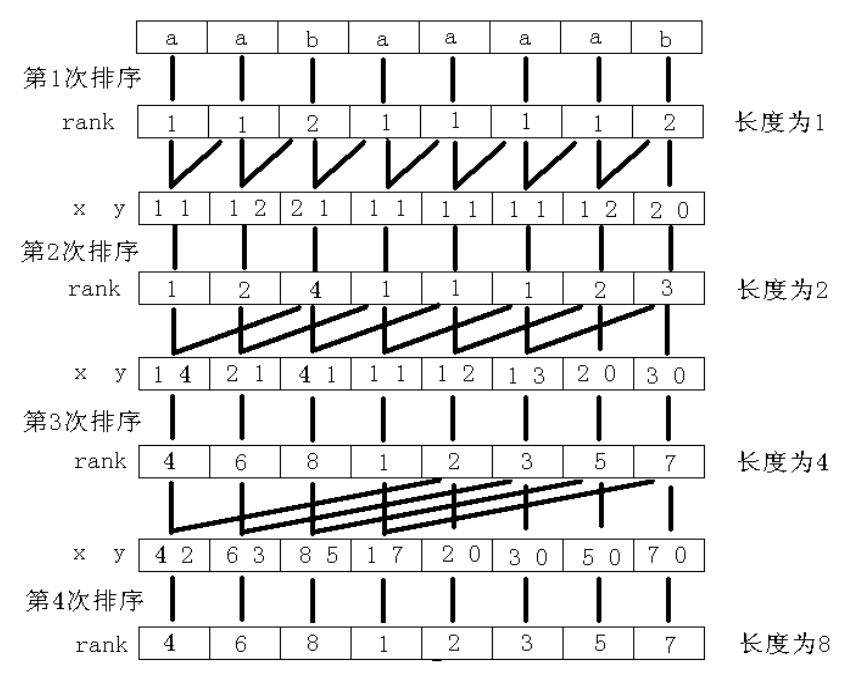
需要用到倍增思想。令 表示 中 的排名,则对于 我们可以通过以 为第一关键字, ( 则视为无穷小)为第二关键字,进行排序即可求出 的值。求出所有后缀排名会进行以上操作 次,若使用 sort 进行排序则每次排序 ,则时间复杂度为 。
以下为倍增示意图:
做法
发现瓶颈是排序,如果能做到 排序,就能做到 了,考虑到排序的值域为 ,并且是一个双关键字的排序,所以我们可以使用基数排序将排序优化到 。
这里介绍一下基数排序。
基数排序的原理是将待排序的元素拆分为 个关键字,以此以 关键字、 关键字、……、 关键字进行排序,最后就能得到排序后的结果,以下是一个例子:
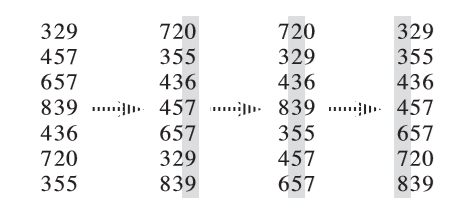
如果以计数排序为每次关键字排序的内层排序,则时间复杂度为 其中, 为第 层关键字的值域。
对应到倍增做法中的排序,, 为字符集大小,则排序复杂度则可看作 ,故最终后缀排序就可以做到 。
#include <bits/stdc++.h>
const int N = 1e6 + 10;
char s[N]; int n, m, k;
int cnt[N], sa[N], sec[N], rk[N];
inline void Csort()
{
for (int i = 1; i <= m; ++ i)
cnt[i] = 0;
// 清零桶
for (int i = 1; i <= n; ++ i)
cnt[rk[i]] ++;
// 将第一关键字压入桶中
for (int i = 2; i <= m; ++ i)
cnt[i] += cnt[i - 1];
// 记个前缀和方便求排名
for (int i = n; i >= 1; -- i)
sa[cnt[rk[sec[i]]] --] = sec[i];
// 对于第一关键字相同的数对来说
// 其排名区间已经确定,我们只需通过第二关键字来确定其特定的排名
// 我们从后到前枚举第二关键字的排名,则此时对应数对的排名就是对应排名区间的最后一个
// 再将对应排名区间的右区间 -1
// 表示接下来枚举到的 第一关键字 相同的数对的排名区间改变了
}
int main()
{
scanf("%s", s + 1);
n = strlen(s + 1), m = 'z';
// n, m 分别代表 s 长度以及字符集大小
for (int i = 1; i <= n; ++ i)
sec[i] = i, rk[i] = s[i];
// sec[i] 表示第二关键字排名为 i 的编号
// 初始时并无第二关键字,所以按照顺序排序
// rk[i] 表示第一关键字中编号为 i 的排名
// 初始时即为 s[i] 的字符大小
// sa[i] 表示排名为 i 的编号
// 需要注意,rk[i] 中相同串的排名会相同
// sa[i] 中相同的串排名不会相同,会根据位置来具体排名(越靠前排名越前)
Csort();
for (int w = 1; w <= n; w *= 2)
{
// w 为当前倍增到的长度
int num = 0;
for (int i = n - w + 1; i <= n; ++ i)
sec[++ num] = i;
// [n - w + 1, n] 无第二关键字,故令其关键字排名靠前
for (int i = 1; i <= n; ++ i)
if (sa[i] > w) sec[++ num] = sa[i] - w;
// 从小到大枚举排名,判断此时这个串是否能作为其他串的第二关键字
// 若能作为其他串的第二关键字,则对应编号为 sa[i] - w
Csort(); std::swap(sec, rk); num = 0;
// 第一第二关键字都已经求出,进行基数排序即可
// 基数排序之后,sa 数组已经求出,我们需要用其更新 rk 数组
// sec 数组已经没用,rk 数组需要更新,暂时用 sec 储存 rk 数组
for (int i = 1; i <= n; ++ i)
rk[sa[i]] = (sec[sa[i]] == sec[sa[i - 1]]
&& sec[sa[i] + w] == sec[sa[i - 1] + w]) ? num : ++ num;
// 按照第一关键字排名从小到大枚举
// 依次更新 rk 数组
m = num;
// 更新关键字值域大小
}
for (int i = 1; i <= n; ++ i)
printf("%d ", sa[i]);
return 0;
}
做法
有 SA-IS 和 DC3 做法,这里暂不介绍(一般用不到)。
应用
循环同构问题
循环同构:当字符串 中可以选定一个位置 满足: ,则称 与 循环同构,例如 ,与这个字符串循环同构的串有 、、、、,
给出一个字符串,我们需要知道与其字符串循环同构的串的排名。Link
将字符串 复制一份成 ,求其后缀数组即可。
在字符串 中找子串 (在线)
在线的含义是 给出, 只在询问时给出。
将 的后缀数组求出,在其后缀数组中二分寻找 (是否存在), 组询问,时间复杂度 ,当然,想找出 在 中所有出现的位置也是可以做的,但是 KMP 显然可以做到更优。
从字符串首尾取字符最小化字典序
给你一个字符串,每次从首或尾取一个字符组成字符串,问所有能够组成的字符串中字典序最小的一个。Link
一个简单的想法是暴力 判断选首还是选尾,这样最差是 的,我们考虑将反串拼接在原串后,中间加个从未出现过的字符,这样,就可以 判断选首还是选尾,就能 解决此题。
height 数组
LCP:两个字符串 的 LCP 表示最长相同前缀。
下文的 表示 与 的 LCP。
height 数组定义如下:
height 数组可以 求出,需要一个引理:
证明如下:
- 若 ,上述式子显然成立,因为 。
- 若 ,令后缀 为 ( 长度为 ,后面会用到),则后缀 为 ,后缀 为 ,我们可以推出后缀 ,则后缀 一定排在 之前,故 。
int LstHeight = 0;
for (int i = 1; i <= n; ++ i)
{
// 按照 rk 从小到大求
if (LstHeight) LstHeight --;
// 从上一个状态继承下来
while (s[sa[rk[i]] + LstHeight] == s[sa[rk[i] - 1] + LstHeight])
LstHeight ++; // 求出对应的 height
height[rk[i]] = LstHeight;
}
height 数组的应用
两子串最长公共前缀
给出一个定理:
要证明这个定理,我们首先证明一个引理:
对于任意的 ,
证明如下:
- 设 ,则有 ,可以得到结论 。
- 再设 ,则有 ,由于 ,故 或 ,令 ,因为 所以 ,又考虑到 与上文矛盾,故 不成立,可以得到结论 。
由 1. 2. 可得:对于任意的 ,
有了这个引理,证明上文的定理就很容易了,证明如下:
- 当 或 时,显然成立。
- 设 时成立,当 时,由引理可知 考虑到 所以有 ,根据数学归纳法,上述定理成立。
有了这个定理,求任意子串的 LCP 就可以转化为 RMQ 问题。
比较一个字符串的两个子串大小关系
需要比较的是 和 的大小关系。
- 若 ,则两者的大小关系由长度关系得到,即 。
- 否则,两者的大小关系由 数组确定,即 。
不同子串数量
考虑容斥,子串我们看作后缀的前缀(非常常见的套路),总子串个数为 ,如果按照后缀排序的顺序枚举后缀,每次新增的子串就是除了与上一个后缀的 LCP 剩下的前缀,也就是说,容斥要减去的就是当前的 height 数组。
所以,不同子串数量为:
出现至少 k 次的子串的最大长度
出现至少 也就代表着后缀排序之后,至少连续 个后缀的 LCP 含有这个子串,所以,求出 height 数组之后,找出每相邻的 个 height 数组的最小值的最大值,单调队列 即可(瓶颈在求后缀数组 ,故用线段树啥的也行)。
参考文献
- oi-wiki
- [2004]后缀数组 by. 徐智磊
- [2009]后缀数组——处理字符串的有力工具 by. 罗穗骞


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧