
深度学习正则化---dropout补充
Dropout
在训练的时候,随机失活的实现方法是让神经元以超参数的概率被激活或者被设置为0。
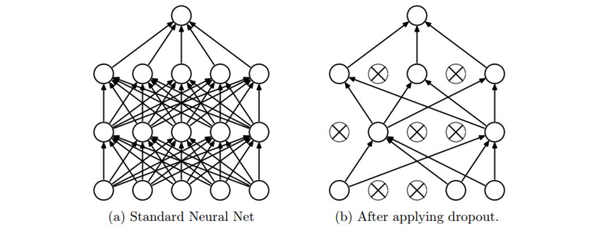
在训练过程中,随机失活可以被认为是对完整的神经网络抽样出一些子集,每次基于输入数据只更新子网络的参数(然而,数量巨大的子网络们并不是相互独立的,因为它们都共享参数)
在测试过程中不使用随机失活,可以理解为是对数量巨大的子网络们做了模型集成(model ensemble),以此来计算出一个平均的预测。
注意:在predict函数中不进行随机失活,但是对于两个隐层的输出都要乘以,调整其数值范围。以
为例,在测试时神经元必须把它们的输出减半,这是因为在训练的时候它们的输出只有一半。为了理解这点,先假设有一个神经元
的输出,那么进行随机失活的时候,该神经元的输出就是
,这是有
的概率神经元的输出为0。在测试时神经元总是激活的,就必须调整
来保持同样的预期输出。
实际更倾向使用反向随机失活(inverted dropout),它是在训练时就进行数值范围调整,从而让前向传播在测试时保持不变。这样做还有一个好处,无论你决定是否使用随机失活,预测方法的代码可以保持不变。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号