

深度学习正则化---dropout
本文转自:https://www.cnblogs.com/dupuleng/articles/4341265.html
dropout的提出是为了防止在训练过程中的过拟合现象,那就有人想了,能不能对每一个输入样本训练一个模型,然后在test阶段将每个模型取均值,这样通过所有模型共同作用,可以将样本最有用的信息提取出来,而把一些噪声过滤掉。
那如何来实现这种想法呢?在每一轮训练过程中,我们对隐含层的每个神经元以一定的概率p舍弃掉,这样相当于每一个样本都训练出一个模型。假设有H个神经元,那么就有2H种可能性,对应2H模型,训练起来时间复杂度太高。我们通过权重
共享(weights sharing)的方法来简化训练过程,每个样本所对应模型是部分权重共享的,只有被舍弃掉那部分权重不同。
使用dropout可以使用使一个隐含结点不能与其它隐含结点完全协同合作,因此其它的隐含结点可能被舍弃,这样就不能通过所有的隐含结点共同作用训练出复杂的模型(只针对某一个训练样本),我们不能确定其它隐含结点此时是否被激活,这样
就有效的防止了过拟合现象。
如下图所示,在训练过程中神经元以概率p出现,而在测试阶段它一直都存在。
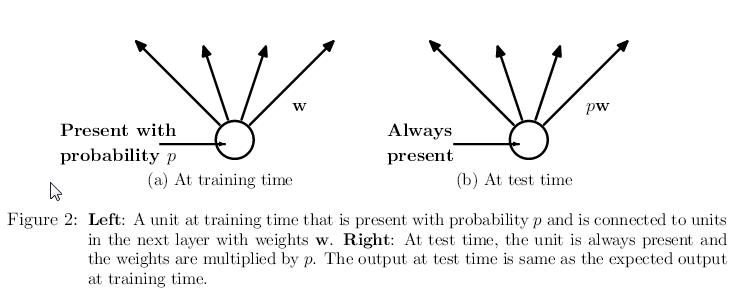
注:如果有多个隐含层,那么对每一个隐含层分别使用dropout策略
1.1 训练阶段
forward propagation
在前向传播过程中,使用掩模m(k)将部分隐含层结点舍弃。
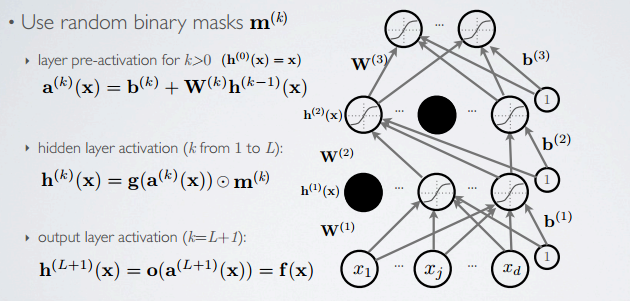
backpropagation
反向传播阶段,即权重调整阶段,通过掩模只调整那些未被舍弃的结点的权重。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号