
IN字段查询多少个值最合适?
导读
你还记得我在《字段为NULL会影响查询性能吗?》这一章中遗留的一个悬念吗?如果不记得了可以回到这个章节,搜索关键字“IN字段查询多少个值最合适?”可以找到。
现在我们再回顾一下这个悬念,也就是查找辅助索引index_birthday得到主键6,8,2,5,这4个主键是如何到聚簇索引查找完整记录的?乍一看,这个不就是SQL中Where条件为id IN (6,8,2,5)这样的查询嘛!其实不然,MySQL对这两者查询处理的方式是完全不同的。所以,在这一章节中,我将分别讲解MySQL对这两者的查询是如何处理的。
先来看SQL中Where条件为id IN (6,8,2,5)这样的查询。
我们都知道MySQL优化器的目的是针对一条SQL,确定其最优的查询执行计划,那么,要产生这个最优的执行计划,势必要对该条SQL做一个详细的分析,那么,这样一个分析的过程,在MySQL内部,就叫做成本代价模型分析。而对于IN查询语句,其实就是问在MySQL内部,IN查询语句,它的查询成本是如何分析的,通俗的讲就是某一个字段的IN查询条件里到底写多个值,MySQL能够选择出最高效的执行计划?咦?这不就是这一章节标题问的那个问题吗?所以,我将结合id IN (6,8,2,5)这条查询,重点讲解一下IN查询语句的成本分析的过程,然后来回答本章标题的这个问题。
成本分析
方便理解,我先把id IN (6,8,2,5)这条查询转化为下面这条完整的SQL:
SELECT * FROM user WHERE id IN (6, 8, 2, 5) 在MySQL中有一个配置参数eq_range_index_dive_limit,它的作用是一个等值查询(比如:in查询),其等值条件数小于该配置参数,则查询成本分析使用扫描索引树的方式分析,如果大于等于该配置参数,则使用索引统计的方式分析。使用扫描索引树的方式分析在MySQL内部叫做index dives,使用索引统计的方式分析在MySQL内部叫做index statistics。
结合上面这条SQL,就是如果SQL中IN查询字段id的值出现的数量小于eq_range_index_dive_limit,则走索引树扫描分析查询成本,大于等于eq_range_index_dive_limit,则走索引统计的方式分析查询成本。
扫描索引树的方式分析SQL的查询成本,它的好处就是在IN查询的值数量不多时,得到的成本结果是精确的,这就意味着MySQL可以选择正确的执行计划,保证语句查询的性能。你现在一定有个疑问:为什么说是在IN查询的值数量不多时才是精确的,因为扫描性能的原因,MySQL在IN查询的值数量很多的情况下,扫描索引树成本提高,性能下降,导致查询成本分析代价也随之提高了。
而基于索引统计的方式分析SQL的查询成本,由于无需扫描索引树,所以,它的优势就是查询成本分析过程快,代价低。但是,它的缺点也很明显,由于无需扫描索引树,通过粗略统计索引使用情况,得出查询成本,导致MySQL可能选错执行计划,使得SQL查询性能下降。
关于查询成本分析的两个方案:扫描索引树 和 索引统计 两种方式,我将在《MySQL为什么选择执行计划A而不选择B?》这一章节中详细讲解。
综合两种成本分析的方案,我们一般让MySQL在分析一条SQL时,尽可能使用扫描索引树的方案分析查询成本,然后,正确选择执行计划,最终,保证该条SQL的查询性能。
所以,本章标题的那个问题,即IN字段查询多少个值最合适?结合上面的分析,我的回答是IN查询的字段,该字段的值不要超过eq_range_index_dive_limit这个参数,让MySQL能够正确选择执行计划,保证SQL查询的性能。 eq_range_index_dive_limit参数的默认值在5.7版本更新为200。
我们假设MySQL明确选择了一个最优的执行计划去执行上面这条SQL,那么,这个执行计划又是怎么执行的呢?这个我将在《MySQL执行器比我们想象的要聪明!》这一章节中详细讲解。
参数配置
关于eq_range_index_dive_limit这个参数如何查看,我们可以使用下面这条SQL查看:
SHOW VARIABLES LIKE '%dive%';现在,我们再来看本章《导读》的另一个问题,即查找辅助索引index_birthday得到主键6,8,2,5,这4个主键是如何到聚簇索引查找完整记录的?
MRR
聪明的MySQL在处理上面这个问题时,想到了一个把随机IO转换为顺序IO的办法,去提升辅助索引主键到聚簇索引查询的性能,而这个办法就是MRR。下面我就结合上面这个问题,来详细讲解一下这个MRR。
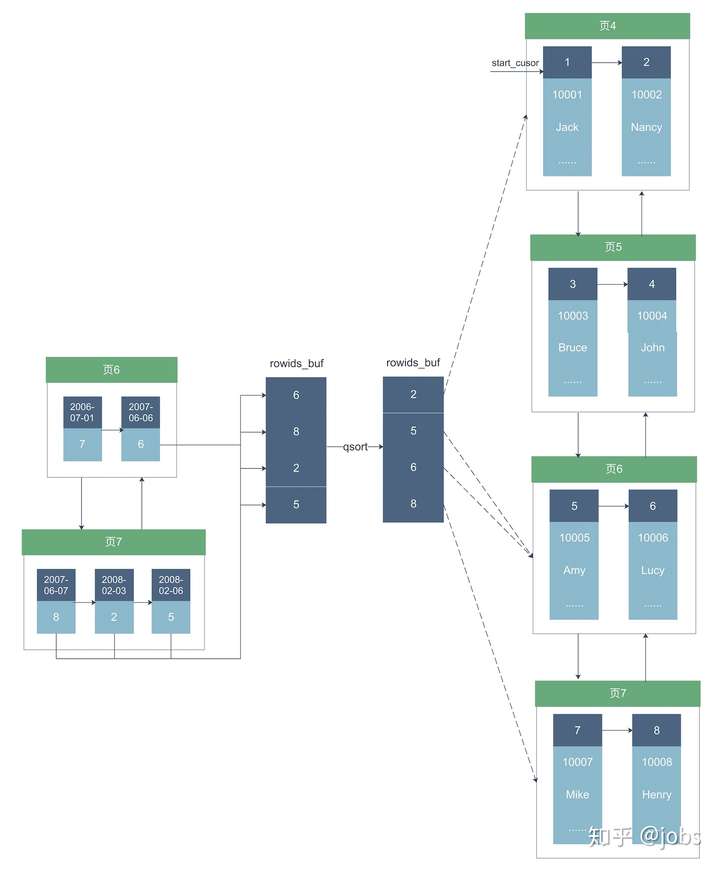
如上图,我简化了辅助索引和聚簇索引的结构,只保留了叶子节点:
- 优化器先遍历辅助索引index_birthday中的叶子节点页6和页7,按顺序读取节点内每个记录如下:
(1) 读取页6中第二条记录的主键6,将6放到一个叫做rowids_buf的缓冲区。
(2) 读取页7中第一条记录的主键8,将8放到rowids_buf的缓冲区。
(3) 读取页7中第二条记录的主键2,将2放到rowids_buf的缓冲区。
(4) 读取页7中第三条记录的主键5,将5放到rowids_buf的缓冲区。
- 优化器对rowids_buf中的6,8,2,5这四个主键做快速排序,即图中qsort,然后,rowids_buf中的主键顺序变为2,5,6,8。
- 执行器从rowids_buf中按序依次取出主键2,5,6,8,图中虚线箭头部分,然后,进行如下步骤:
(1) 根据主键2,顺序查找聚簇索引叶子节点链表,即页4 ~ 页7。
(2) 在页4中找到主键为2的记录,start_cusor游标定位到主键为2的记录上。
(3) 根据主键5,从start_cusor游标位置开始,顺序查找聚簇索引叶子节点页5 ~ 页7。
(4) 在页6中找到主键为5的记录,start_cusor游标定位到主键为5的记录上。
(5) 以此类推,最后在聚簇索引叶子节点上找到了主键6和8的两条记录。
相比原先按照主键6,8,2,5的顺序搜索聚簇索引,MRR的做法要聪明多了,因为按照6,8,2,5这个顺序搜索聚簇索引,这是一个随机查找,而转换为2,5,6,8后,搜索聚簇索引就变为顺序查找,这个性能相比前者一定会有很大提升的。
这时,你可能有个疑问:如果rowids_buf满了怎么办?这个不用担心,当rowids_buf满了,MySQL会先执行上面的步骤2和3,等rowids_buf中的主键都从聚簇索引中取出记录后,把rowids_buf清空,继续开始步骤1 ~ 3。
既然rowids_buf会满,我想一次多加载一批辅助索引主键到rowids_buf,减少查找聚簇索引的次数,那该怎么办?这个MySQL也提供了一个参数去改变rowids_buf的大小,这个参数就是read_rnd_buffer_size。调整语句:
SET read_rnd_buffer_size = 1024*1024;小结
最后,我来总结一下这一章节所讲的内容:
- IN查询的成本分析: IN查询字段值的个数受
eq_range_index_dive_limit这个参数影响,所以,建议这个个数不要超过该参数所配置的大小。 - MRR: 一个将随机查找变为顺序查找的好办法,提升了辅助索引主键到聚簇索引查找的性能。为了减少查找聚簇索引的次数,可以调整参数
read_rnd_buffer_size。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?
2016-02-14 Java NIO概述