

Spark学习笔记------CentOS环境spark安装
上一篇写了Hadoop分布式集群的安装以及配置过程,这一篇来继续spark的安装与配置,具体步骤如下:
一、准备工作
spark官网下载地址:http://spark.apache.org/downloads.html,选择spark版本和对应的hadoop版本,然后点击下面对应的下载链接。
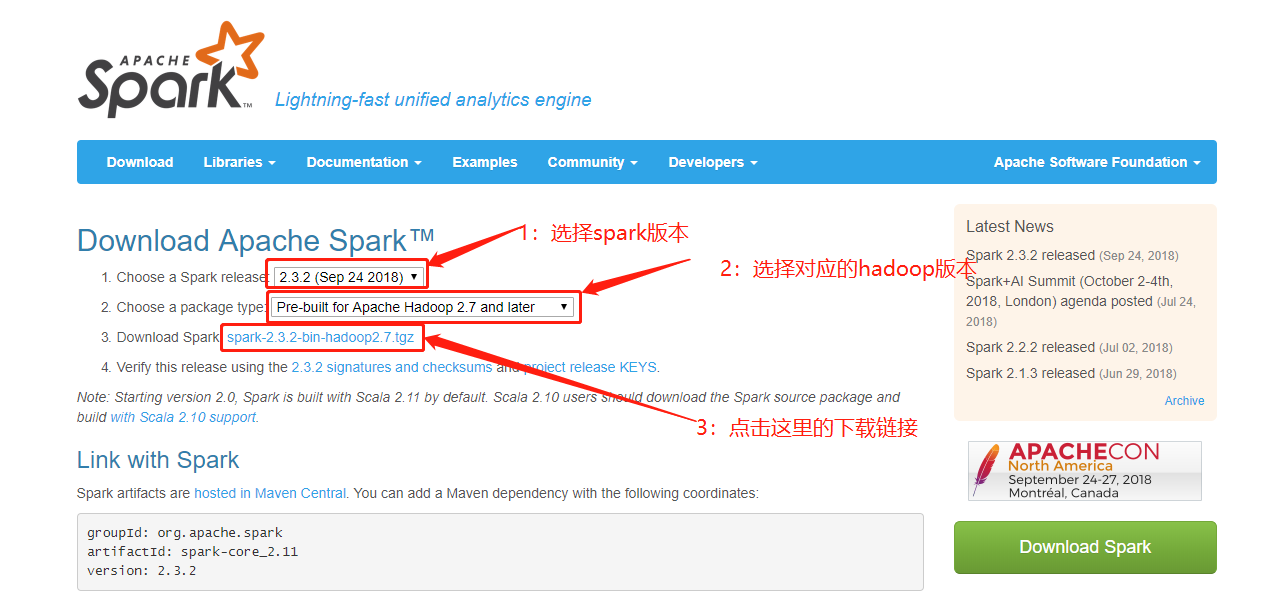
我这里由于安装的hadoop版本是2.8.5,所以选择了Pre-built for Apache Hadoop 2.7 and later,然后默认给我下载spark-2.3.2-bin-hadoop2.7.tgz版本.
配置环境变量并进行刷新,之后对slave1和slave2进行修改
#编辑profile文件 [root@spark-master ~]# vi /etc/profile #在文件的最后面添加下面的内容,SPARK-HOME以实际安装为准 export SPARK_HOME=/opt/spark/spark-2.3.2-bin-hadoop2.7 export PATH=$PATH:$SPARK_HOME/bin #刷新配置使环境变量生效 [root@spark-master ~]# source /etc/profile
二、hadoop分布式安装与配置
1.安装与配置
把下载的安装包拷贝到服务器上,并解压到安装目录,通常应该对解压出来的文件夹重命名的,便于后面配置,我这里就偷懒直接用解压后的文件名。
然后切换到conf目录下看到有一些模板文件,我们把其中带spark-env.sh.template 、spark-defaults.conf.template和slaves.template的文件进行复制并重命名(主要是把后面的template后缀去掉),然后修改里面的内容。
#解压安装包到安装目录
[root@spark-master ~]# tar -xvf /opt/spark/spark-2.3.2-bin-hadoop2.7.tgz -C /opt/spark/ [root@spark-master ~]# cd /opt/spark/spark-2.3.2-bin-hadoop2.7/ [root@spark-master spark-2.3.2-bin-hadoop2.7]# cd conf
#拷贝slaves和spark-env.sh文件 [root@spark-master conf]# cp slaves.template slaves [root@spark-master conf]# cp spark-env.sh.template spark-env.sh [root@spark-master conf]# vim slaves
#修改slaves配置文件如下
spark-slave1
spark-slave2
[root@spark-master conf]# vim spark-env.sh
#修改spark-env.sh配置文件如下
export JAVA_HOME=/usr/java/jdk1.8.0_152
export SCALA_HOME=/opt/scala/scala-2.12.7
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.5
export HADOOP_CONF_DIR=/opt/hadoop/hadoop-2.8.5/etc/hadoop
#定义管理端口
export SPARK_MASTER_WEBUI_PORT=8066
#定义master域名和端口
export SPARK_MASTER_HOST=spark-master
export SPARK_MASTER_PORT=7077
#定义master的地址slave节点使用
export SPARK_MASTER_IP=spark-master
#定义work节点的管理端口.work节点使用
export SPARK_WORKER_WEBUI_PORT=8077
#每个worker节点能够最大分配给exectors的内存大小
export SPARK_WORKER_MEMORY=4g
#拷贝spark-defaults.conf配置文件
[root@spark-master conf]# cp spark-defaults.conf.template spark-defaults.conf
[root@spark-master conf]# vim spark-defaults.conf
#修改spark-default.conf配置文件如下
spark.eventLog.enabled=true
spark.eventLog.compress=true
#保存在本地
#spark.eventLog.dir=file://usr/local/hadoop-2.8.5/logs/userlogs
#spark.history.fs.logDirectory=file://usr/local/hadoop-2.8.5/logs/userlogs
#保存在hdfs上
spark.eventLog.dir=hdfs://spark-master:9000/tmp/logs/root/logs
spark.history.fs.logDirectory=hdfs://spark-master:9000/tmp/logs/root/logs
spark.yarn.historyServer.address=spark-master:18080
注意:在修改slaves文件的时候里面默认有个localhost项要去掉,不然启动的时候会提示Permanently added 'localhost' (ECDSA) to the list of known hosts.
以上都修改完成后把安装目录分别拷贝到slave1和slave2服务器上。
[root@spark-master conf]# scp -r /opt/spark/spark-2.3.2-bin-hadoop2.7 root@spark-slave1:/opt/spark/ [root@spark-master conf]# scp -r /opt/spark/spark-2.3.2-bin-hadoop2.7 root@spark-slave2:/opt/spark/
三、启动与测试
切换到spark安装目录下的sbin目录,这里可以看到spark为我们贴心的准备了很多命令执行脚本,我们执行start-all.sh启动集群。
[root@spark-master conf]# cd ../sbin/ [root@spark-master sbin]# ./start-all.sh starting org.apache.spark.deploy.master.Master, logging to /opt/spark/spark-2.3.2-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-VM_10_45_centos.out spark-slave2: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/spark-2.3.2-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-VM_21_17_centos.out spark-slave1: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/spark-2.3.2-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-VM_20_8_centos.out
查看web管理界面,地址:http://10.10.10.88:8066/
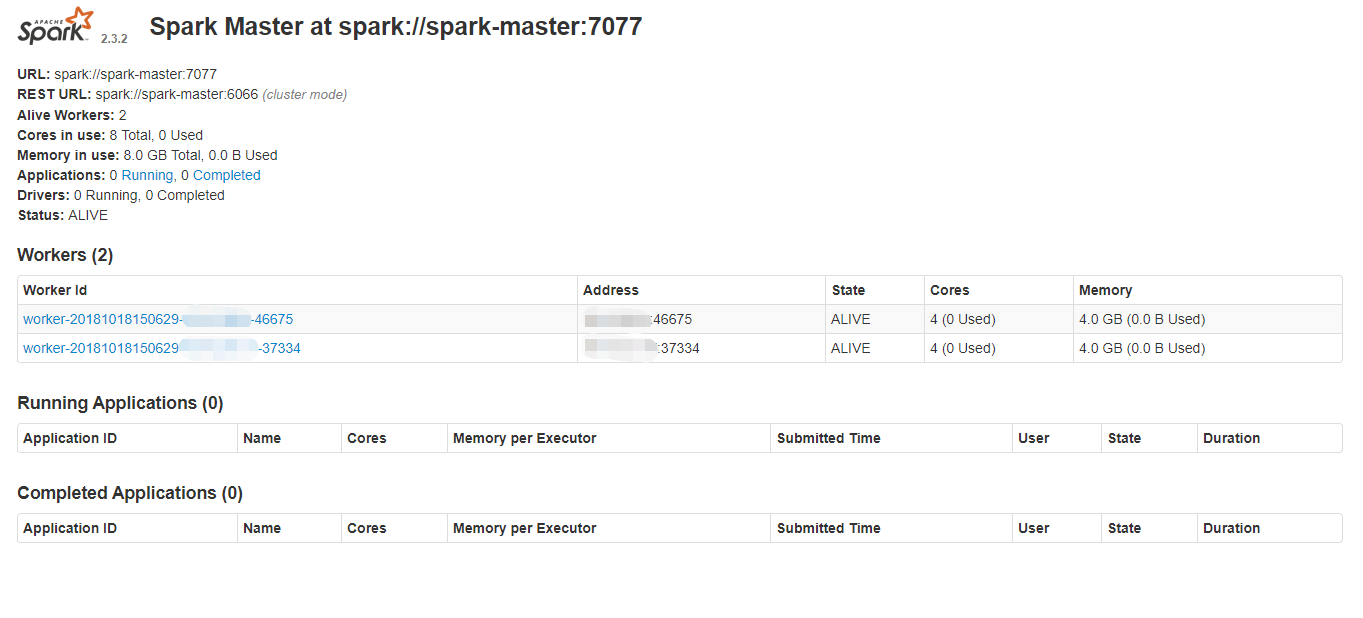
以上就是spark完全分布式集群的安装及配置过程,接下来开始继续探索spark的神奇功能。
